VLM-r1:结合DeepSeek R1强化学习的多模态AI突破
VLM-R1(Vision-Language Model for Reasoning 1)结合了DeepSeek R1强化学习算法,推动多模态AI领域向前迈进。通过深度学习与强化学习的完美融合,VLM-R1不仅在视觉和语言处理上表现出色,还在跨模态推理和决策能力上展现出强大的潜力。
VLM-r1:结合DeepSeek R1强化学习的多模态AI突破
VLM-R1(Vision-Language Model for Reasoning 1)结合了DeepSeek R1强化学习算法,推动多模态AI领域向前迈进。通过深度学习与强化学习的完美融合,VLM-R1不仅在视觉和语言处理上表现出色,还在跨模态推理和决策能力上展现出强大的潜力。本文将深入介绍VLM-R1的架构与DeepSeek R1如何为其强化学习提供支持,探索这一创新模型如何引领人工智能走向更加智能和自主的未来。
项目地址:VLM-R1
该项目主要是使用VLM模型处理Referring Expression Comprehension (REC)任务同时使用 R1 和 SFT 方法训练了Qwen2.5-VL 。结果发现,在域内测试数据上,SFT 模型的性能略低于 R1 模型。但在域外测试数据上,随着步数的增加,SFT 模型的性能明显下降,而 R1 模型的性能则稳步提升。
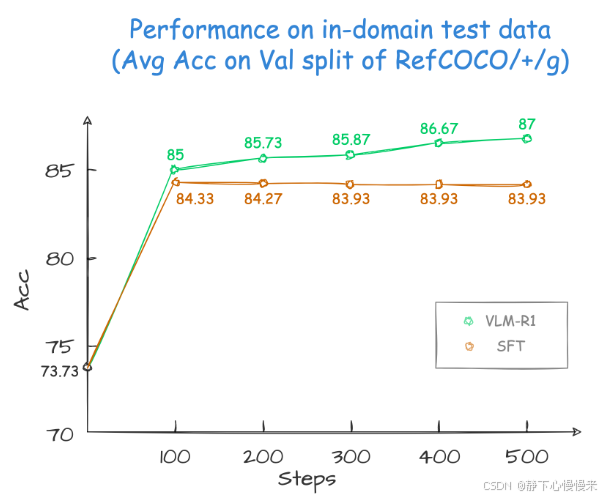
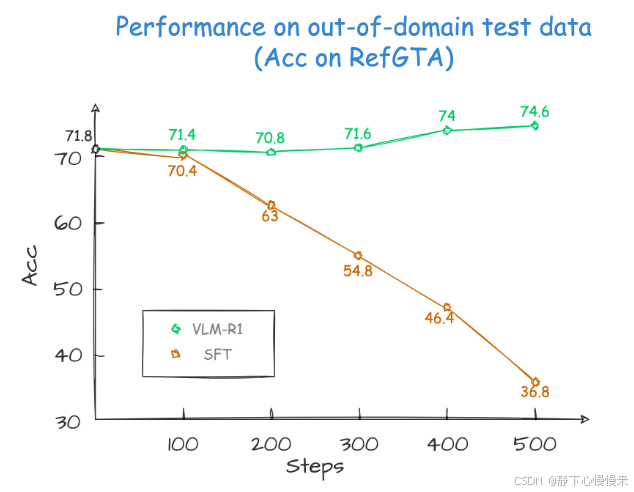
使用训练得到的VLM r1在相关场景人物下具有很好的表现性能:
VLM r1如何结合Deep Seek R1的GRPO强化学习算法
因为vlm-r1中使用了Deep seek R1的GRPO强化学习算法,本文会详细介绍一下VLM-r1是如何将GRPO强化学习算法引入VLM这种视觉语言模型的。
在语言模型的应用中,例如解决数学题或符合人类对话偏好的需求(如避免不良内容或提供更详细的解释),通常首先通过大规模的无监督或自监督训练建立基础。然后,通过“监督微调”(SFT)来进一步使模型符合初步要求。然而,SFT 有时难以直接将人类或某些高级目标的偏好有效地融入模型中。这时,“强化学习微调”便显得尤为重要。PPO 是这一方法中的代表性算法,但它也存在一些局限性,特别是需要维护额外的大型价值网络,这对大模型的内存和计算能力提出了较高的要求。在这种背景下,GRPO 算法应运而生,提供了一个更为高效的解决方案。
格式化规范输出:
SYSTEM_PROMPT = (
"A conversation between User and Assistant. The user asks a question, and the Assistant solves it. The assistant "
"first thinks about the reasoning process in the mind and then provides the user with the answer. The reasoning "
"process and answer are enclosed within <think> </think> and <answer> </answer> tags, respectively, i.e., "
"<think> reasoning process here </think><answer> answer here </answer>"
)这段系统提示词的功能是确保模型的输出符合规范,包含思考过程与回答答案两个部分,其中思考过程被<think> </think>包裹,答案部分被<answer> </answer>包裹
在VLM r1在训练过程中中主要包含两个奖励函数,分别是通过两段关键代码解析如何通过IoU精度奖励与格式规范性奖励的双重机制,引导模型同时满足内容准确性和格式规范性的需求。
IoU精度奖励
通过计算预测边界框(Bounding Box)与真实标注框的IoU(交并比),量化模型检测的位置精度,给予符合阈值的结果正向激励。
-
IoU超过0.5即视为有效检测(reward=1.0),符合目标检测常规标准
# 定义 iou_reward 函数,接受 completions(生成的答案)、solution(期望的结果框)和其他参数
def iou_reward(completions, solution, **kwargs):
# 定义 IOU(交并比)计算函数
def iou(box1, box2):
# 计算两个框交集区域的左上角坐标(x1, y1)
inter_x1 = max(box1[0], box2[0])
inter_y1 = max(box1[1], box2[1])
# 计算两个框交集区域的右下角坐标(x2, y2)
inter_x2 = min(box1[2]-1, box2[2]-1)
inter_y2 = min(box1[3]-1, box2[3]-1)
# 如果交集的区域是有效的(即交集存在)
if inter_x1 < inter_x2 and inter_y1 < inter_y2:
# 计算交集的面积
inter = (inter_x2-inter_x1+1)*(inter_y2-inter_y1+1)
else:
# 如果没有交集,则交集面积为0
inter = 0
# 计算两个框的并集面积
union = (box1[2]-box1[0])*(box1[3]-box1[1]) + (box2[2]-box2[0])*(box2[3]-box2[1]) - inter
# 返回交并比(交集面积 / 并集面积)
return float(inter)/union
# 提取所有生成答案的内容
contents = [completion[0]["content"] for completion in completions]
# 初始化奖励列表
rewards = []
# 获取当前时间,格式为日-时-分-秒-微秒
current_time = datetime.now().strftime("%d-%H-%M-%S-%f")
# 定义用来匹配<answer>标签内容的正则表达式模式
answer_tag_pattern = r'<answer>(.*?)</answer>'
# 定义用于匹配坐标框的正则表达式模式(格式:[x1, y1, x2, y2])
bbox_pattern = r'\[(\d+),\s*(\d+),\s*(\d+),\s*(\d+)]'
# 遍历生成的答案内容和期望的框(solution)
for content, sol in zip(contents, solution):
# 初始奖励设置为0
reward = 0.0
# 尝试进行符号验证(验证<answer>标签中的内容)
try:
# 查找答案中的<answer>标签内容
content_answer_match = re.search(answer_tag_pattern, content, re.DOTALL)
# 如果找到了<answer>标签
if content_answer_match:
# 提取<answer>标签中的内容
content_answer = content_answer_match.group(1).strip()
# 使用正则表达式匹配坐标框
bbox_match = re.search(bbox_pattern, content_answer)
# 如果找到了坐标框
if bbox_match:
# 提取框的四个坐标值
bbox = [int(bbox_match.group(1)), int(bbox_match.group(2)), int(bbox_match.group(3)), int(bbox_match.group(4))]
# 计算当前框和期望框的IOU值,如果IOU值大于0.5,则奖励为1
if iou(bbox, sol) > 0.5:
reward = 1.0
except Exception:
# 如果上述步骤出现异常,则跳过(继续验证其他方法)
pass
# 将当前奖励加入奖励列表
rewards.append(reward)
# 如果启用了调试模式,则记录日志
if os.getenv("DEBUG_MODE") == "true":
log_path = os.getenv("LOG_PATH")
# 以追加模式打开日志文件
with open(log_path, "a", encoding='utf-8') as f:
# 写入当前时间和奖励信息
f.write(f"------------- {current_time} Accuracy reward: {reward} -------------\n")
# 写入生成的答案内容
f.write(f"Content: {content}\n")
# 写入期望的答案框(solution)
f.write(f"Solution: {sol}\n")
# 返回所有的奖励值列表
return rewards
格式规范性奖励
强制模型遵循指定的输出格式规范,确保结果可被后续流程解析,提升系统鲁棒性。
-
多标签联合校验:要求同时存在
<think>推理过程和<answer>结果输出 -
严格结构验证:检测边界框的坐标格式
[x1,y1,x2,y2]是否符合规范 -
完全匹配预设格式时给予满分奖励(1.0)
-
任何格式偏差直接返回0奖励,强化格式意识
# 定义格式奖励函数,检查生成的答案是否符合特定的格式
def format_reward(completions, **kwargs):
"""奖励函数,用于检查生成的答案是否具有特定格式。"""
# 定义一个正则表达式模式,检查内容是否符合以下格式:
# 1. <think> 标签包裹的内容
# 2. <answer> 标签包裹的内容,其中包括一个花括号内嵌有一个矩形框的坐标 [x1, y1, x2, y2]
# 注意:使用非贪婪匹配,确保仅匹配最内层的 <think> 和 <answer> 标签。
pattern = r"<think>.*?</think>\s*<answer>.*?\{.*\[\d+,\s*\d+,\s*\d+,\s*\d+\].*\}.*?</answer>"
# 提取所有生成答案的内容
completion_contents = [completion[0]["content"] for completion in completions]
# 使用正则表达式对每个生成的答案内容进行匹配
# re.fullmatch 确保整个内容符合正则表达式的要求
# re.DOTALL 使得点号(.)匹配包括换行符在内的所有字符
matches = [re.fullmatch(pattern, content, re.DOTALL) for content in completion_contents]
# 根据是否匹配正则表达式,为每个生成的答案分配奖励
# 如果匹配,则奖励为1.0,否则奖励为0.0
return [1.0 if match else 0.0 for match in matches]
双奖励机制的协同效应
-
精度导向:
iou_reward确保检测结果与真实标注高度吻合 -
格式约束:
format_reward保障输出结果的结构可解析性
模型实机演示
模型输入是Description Text,为任务语句,输出包含思考过程以及标注框。
演示地址:https://huggingface.co/spaces/omlab/VLM-R1-Referral-Expression
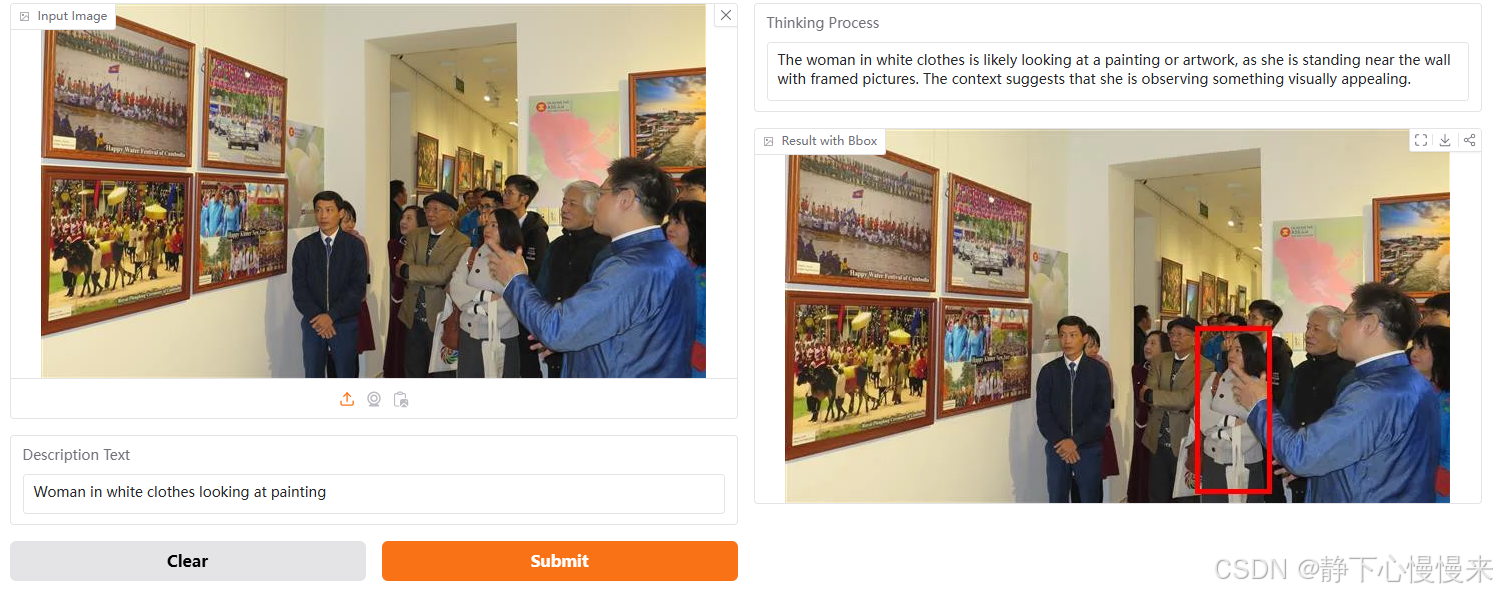
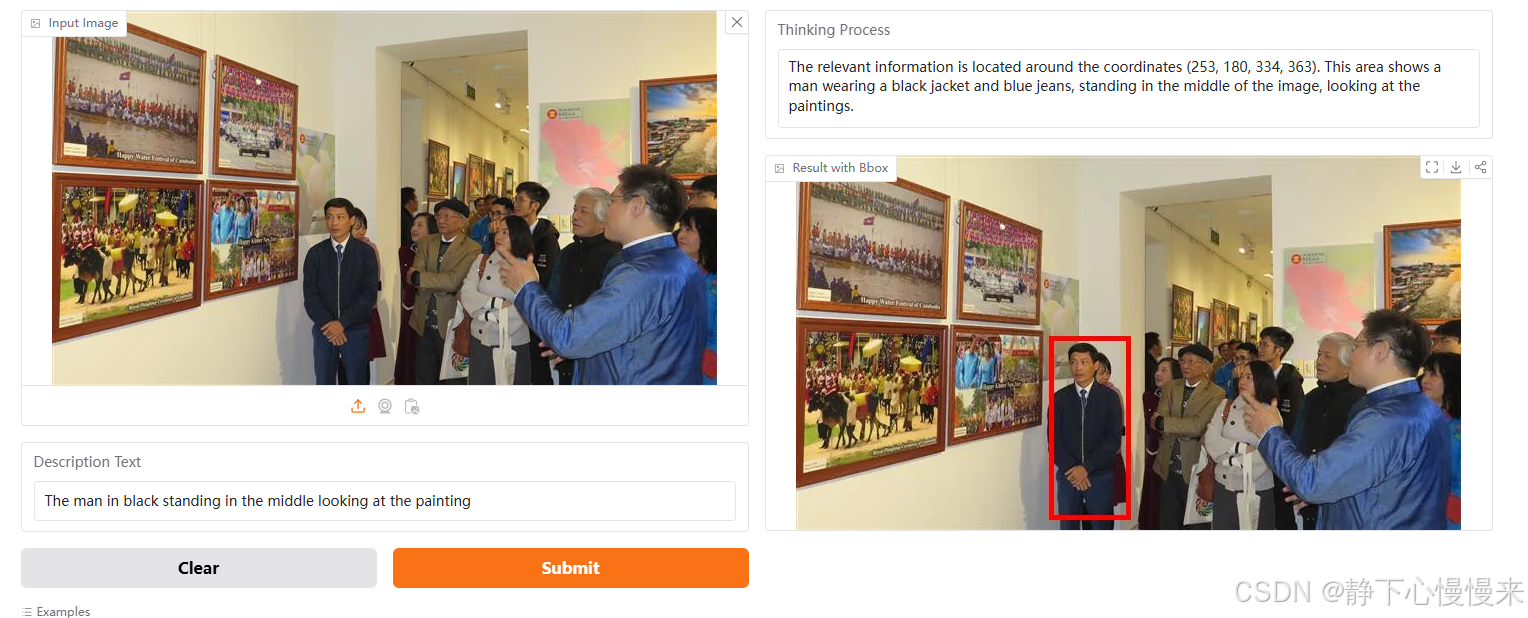
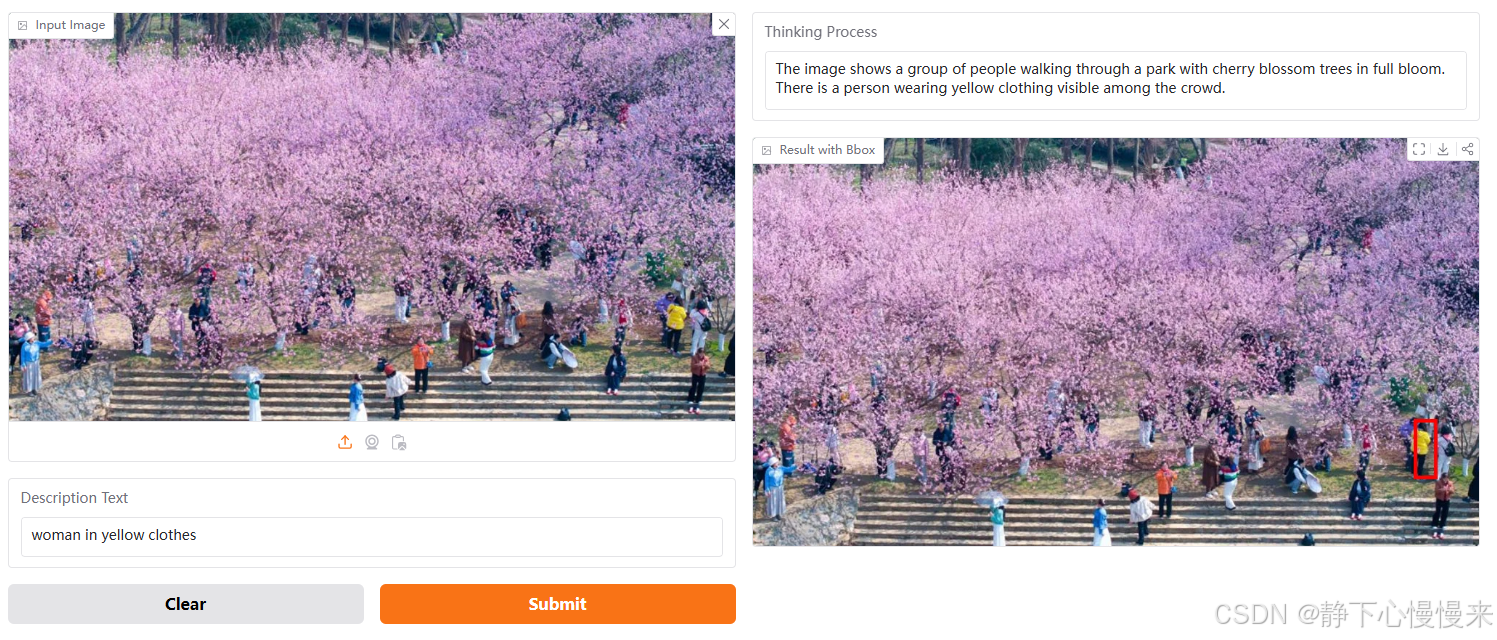
问句提问: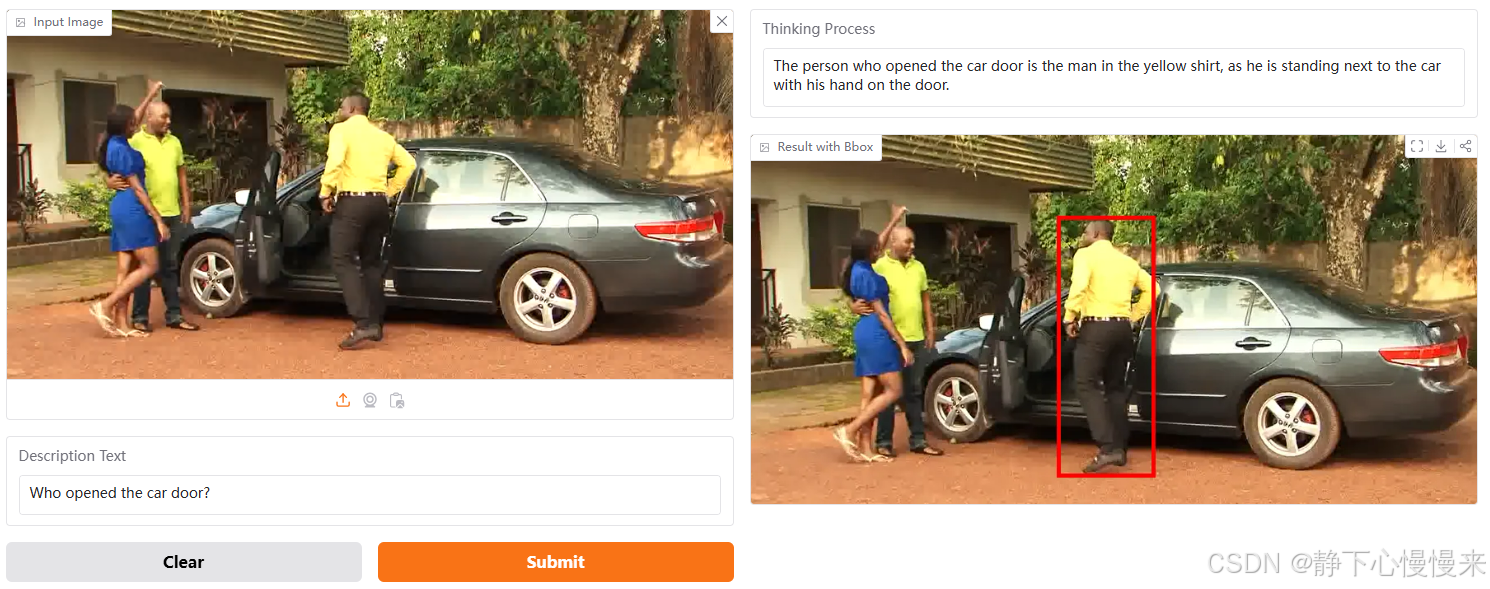


欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 28
28 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)