99行代码!教会你用Doris+DeepSeek实现AI舆情分析
随着Doris和大模型技术的进步,未来的舆情分析系统将更加智能化。我们可以期待这些趋势:1️⃣ 多模态分析:不仅分析文字,还能识别图片、视频中的情绪和内容2️⃣ 预测性分析:不只是被动应对,而是预测可能出现的舆情风险3️⃣ 个性化回应:根据不同用户的特点,生成个性化的回应策略舆情分析不再是简单的数据统计,而是企业和组织必备的社会雷达。Doris+DeepSeek的组合将成为这个领域的有力工具。AI
免费领取 DeepSeek➕数据AI知识库 🔗 一起共建共进
❝
你是否曾经历过这样的场景:公司号突然被喷,评论区一片狼藉,客服电话被打爆,老板紧急召集会议,大家手忙脚乱却不知从何入手?
舆情危机好比一场没有预警的暴风雨,瞬间就能让企业陷入困境。对处在风口浪尖的企业来说,拥有一套高效的舆情分析系统简直就是救命稻草。
正巧,一位Doris小伙伴:“WX!!! 急需AI舆情分析。”
“好滴,安排”

舆情分析中的痛点
小华是某政务中心的舆情分析师,每天需要处理上千条网络评论。
传统的舆情分析流程繁琐又耗时:手动筛选关键信息,分析情绪趋势,生成报告,往往一天下来只能处理几百条数据。
"如果系统能自动识别高风险言论就好了,我也不用天天熬夜加班。"小华经常这样感叹。

张总是一家快消品企业的公关部负责人,公司刚上市新产品就遭遇了全网吐槽。面对铺天盖地的负面评论,张总的团队只能疲于奔命地一条条回复。
“我们需要知道舆情的源头在哪里,是质量问题还是营销策略出了错。可现在的分析速度远跟不上网络传播速度。”
…
Doris+DeepSeek:舆情分析的黄金组合
Apache Doris是一款基于 MPP 架构的高性能、实时分析型数据库,能够处理海量数据并提供毫秒级查询性能。
DeepSeek则是一款强大的大语言模型,拥有出色的语义理解和情感分析能力。
两者结合,好比给数据分析插上了AI的翅膀。
Doris负责数据存储和快速检索,DeepSeek负责深度解读文本背后的情感和意图。
这套组合的工作流程:
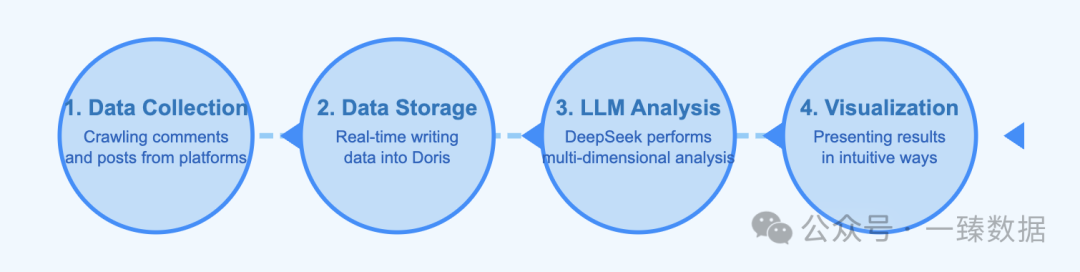
1️⃣ 数据采集:通过爬虫收集平台的评论和帖子等内容
2️⃣ 数据入库:将收集到的数据实时写入Doris
3️⃣ 大模型分析:DeepSeek对文本进行多维度分析
4️⃣ 可视化展示:将分析结果以直观的方式呈现
确认好组合思路,接下来就开始撕代码 ⬇️
99行代码速通AI舆情分析
环境准备
本文demo环境相对简易,参考DorisAi前文环境即可:
[3步!教会你用Doris+DeepSeek搭建ChatBI系统(保姆级教程)](https://mp.weixin.qq.com/s?__biz=MzI3NjA1MTcyMQ==&mid=2650487577&idx=1&sn=6e7c50529a2c42cf3955570180b8a5d2&scene=21#wechat_redirect)
代码实现
经过一臻和老崔七七四十九秒的编写调试,完整的99行示例代码如下:
import pymysql from dbutils.pooled_db import PooledDB import requests from langchain.agents import initialize_agent, Tool from langchain_openai import ChatOpenAI """ AI舆情分析|自动投诉处理系统 v1.0 Description: 基于LangChain Agent的智能流程自动化系统,替代硬编码方式处理投诉数据 """ # 定义Apache Doris数据库查询的Agent Tool def dorisTool(query): POOL_DORIS_OFF = PooledDB( user='{user}',password='{password}',host='{host}',port={port},database='{database}', charset='utf8',creator=pymysql,blocking=True,maxusage=None,setsession=[],maxconnections=30,mincached=10,ping=0, ) cursor = POOL_DORIS_OFF.connection().cursor() cursor.execute(query) columns = [col[0] for col in cursor.description] rs = [dict(zip(columns, row)) for row in cursor.fetchall()] return rs # 定义发送钉钉消息的Agent Tool def dingdingTool(msg): markdown_message = f""" {msg} """ webhook_url = ( "{webhook_url}") headers = {'Content-Type': 'application/json'} payload = { "msgtype": "markdown", "markdown": { "title": "投诉数据明细", "text": markdown_message } } try: response = requests.post(webhook_url, headers=headers, json=payload) response.raise_for_status() print("钉钉消息推送成功") except requests.exceptions.RequestException as e: print(f"钉钉消息推送失败: {e}") # 定义LangChain Agent工具列表 tools = [ Tool( name="执行sql查询doris数据", func=dorisTool, description="根据传入的doris sql直接执行,返回结果集,返回格式为list" ), Tool( name="推送钉钉消息", func=dingdingTool, description="根据传入的msg通过钉钉机器人的形式推送msg到钉钉群" ) ] # 初始化LLM llm = ChatOpenAI(base_url='https://ark.cn-beijing.volces.com/api/v3', api_key="{api_key}", model='{model}') # 初始化LangChain Agent agent = initialize_agent( tools, llm, agent="zero-shot-react-description", verbose=True, handle_parsing_errors=True ) # 提示模板,指导AI代理如何处理查询 question = "请问近30天有关于一臻数据的投诉信息吗" promptTemplate = """ 你是“一臻数据”平台的投诉识别以及处理员,需完成以下任务: 1. 根据用户的问题,生成一个 SQL 查询,具体查询时间范围以用用户实际问题为准。 2. 从查询结果中筛选出与“一臻数据”相关的投诉信息。 3. 将筛选结果汇总为易读的格式,并给出处理建议以及将命中的投诉信息根据你的建议排出一个紧急程度来,尽可能多的挖掘一些信息返回给客户,做专家指导,如“舆情分类”、“定义分类”、“紧急程度”等。 4. 如果存在与“一臻数据”相关的投诉,将汇总信息和你的处理建议通过钉钉机器人推送到指定群组。 5. 在推送内容中添加表情符号,增强可读性。 注意: -如需调用工具,根据工具的作用在该任务里调用合适的工具,并根据工具的要求传入需要的参数,要求参数传入格式准确 -只能从获得的doris库中的数据中做分析,不允许自己fake数据。 数据库信息: - 表名:yz_complaint_detail - 字段:complaint_time(投诉时间), detail(具体投诉内容) - SQL 查询示例:SELECT detail FROM yz_complaint_detail WHERE complaint_time >= NOW() - INTERVAL 60 DAY; """ prompt = f"{question}\n{promptTemplate}" # 运行Agent try: result = agent.run(prompt) print("Final Result:") print(result) except Exception as e: print(f"代理执行出错: {e}")
代码解析
代码经过精简,很多block没有进行过多地细化深入。主要是为了让大家能够快速熟悉Doris+DeepSeek V3体验AI舆情分析的完整流程,后续可以结合自己需求,按模块进行调整应用。
代码主流程如下:
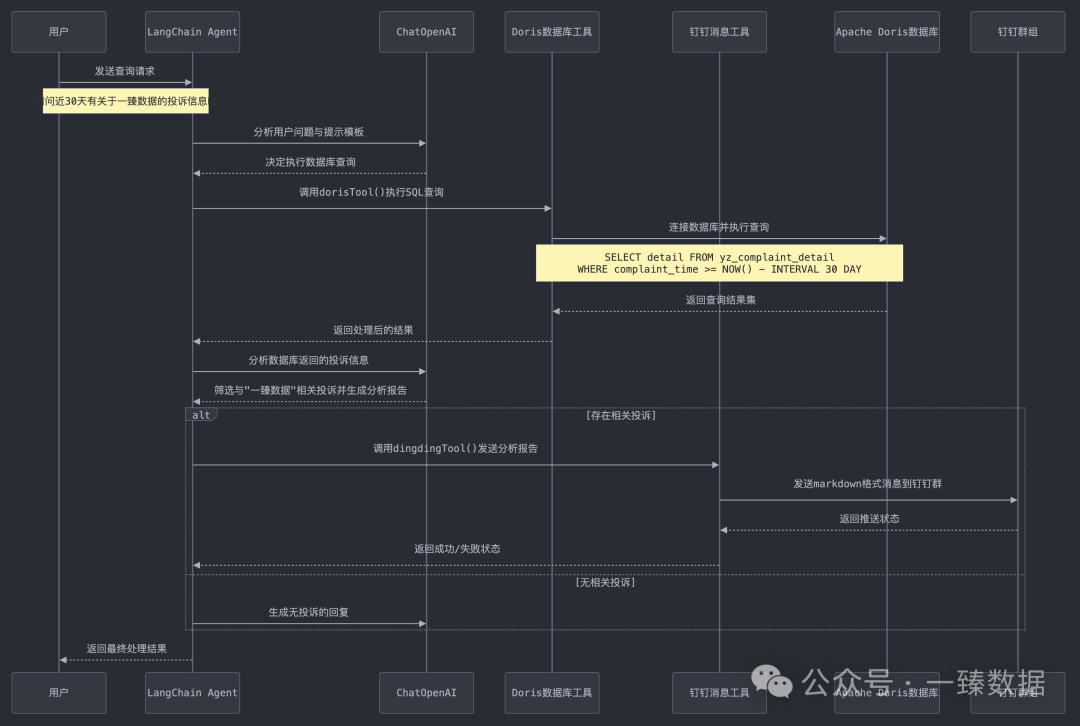
1️⃣ 用户查询:用户向系统提问,例如请问近30天有关于一臻数据的投诉信息吗
2️⃣ 任务分析:LangChain Agent接收问题和提示模板prompt,将其发送给大语言模型(DeepSeek V3)分析。语言模型理解问题意图,确定需要查询近30天的投诉数据
3️⃣ Doris数据库查询:Agent决定需要查询数据库,调用dorisTool函数,生成对应SQL进行查询并返回查询结果
4️⃣ 投诉分析:Agent将Doris查询结果发送给DeepSeek进行分析,DeepSeek筛选出与"一臻数据"相关的投诉,生成分析报告,包括舆情分类、紧急程度等信息
5️⃣ 结果处理:系统根据分析结果分两种情况处理:
无投诉:DeepSeek生成一个表明没有发现相关投诉的回复
有投诉:Agent调用dingdingTool函数,函数将分析报告格式化为Markdown,通过钉钉webhook发送到指定群组,返回发送状态给Agent
其它说明
1. 钉钉告警配置
🔗 钉钉自定义机器人安全设置:https://open.dingtalk.com/document/robots/customize-robot-security-settings#title-7fs-kgs-36x
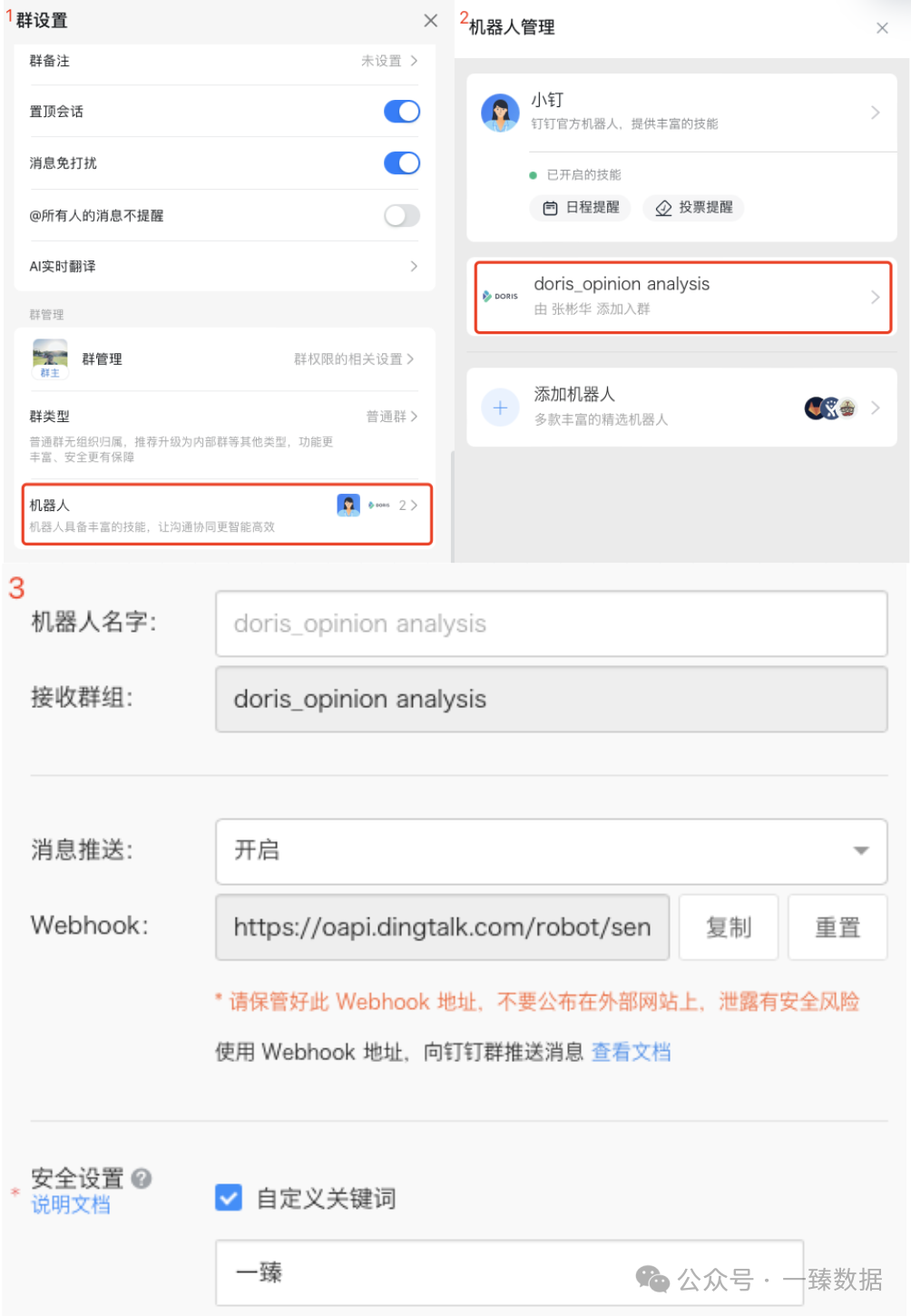
1️⃣ 创建一个至少3人行的钉钉群组
2️⃣ 创建一个机器人
3️⃣ 初始化机器人信息,并获取Webhook
2. 缺省参数补齐
1️⃣ 补齐dorisTool的连接信息
2️⃣ 补齐dingdingTool的Webhook
3️⃣ 补齐LLM的api_key和model,可以参考DorisAi前文获取
3. 测试表和数据
代码所使用的Doris表和测试数据如下:
`-- 测试表 CREATETABLE`yz_complaint_detail` ( `complaint_time` datetime NULLCOMMENT'投诉时间', `detail`textNULLCOMMENT'具体投诉内容', INDEX index_complaint_time (`complaint_time`) USING INVERTED ) ENGINE = OLAP DUPLICATEKEY(`complaint_time`) COMMENT'一臻数据投诉信息表' DISTRIBUTEDBYHASH(`complaint_time`) BUCKETS 30 PROPERTIES ( "replication_allocation" = "tag.location.default: 1" ); -- 测试数据 insertinto yz_complaint_detail values ('2025-03-11 15:30:30','一臻数据真垃圾,总是拖稿'), ('2025-03-10 13:30:30','一臻数据真不错'), ('2025-03-09 15:30:30','一臻数据真垃圾,严重拖稿'), ('2025-02-08 15:30:30','一臻数据服务很好'), ('2025-02-07 15:30:30','一臻数据不处理问题,客服被投诉!'), ('2025-02-06 15:30:30','一臻数据断更被暴利催更'), ('2025-02-05 15:30:30','投诉一臻数据,严重拖稿'), ('2025-03-00 18:30:30','一臻数据真好') `
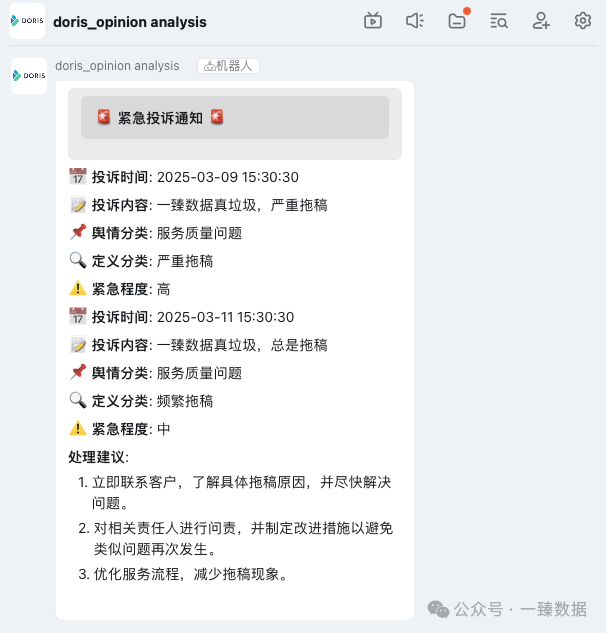
结果验证
配置好钉钉告警->补齐缺省参数->初始化完Doris相关表和测试数据后,直接Run,就会在钉钉收到对应的AI舆情分析通知:
结语

随着Doris和大模型技术的进步,未来的舆情分析系统将更加智能化。
我们可以期待这些趋势:
1️⃣ 多模态分析:不仅分析文字,还能识别图片、视频中的情绪和内容
2️⃣ 预测性分析:不只是被动应对,而是预测可能出现的舆情风险
3️⃣ 个性化回应:根据不同用户的特点,生成个性化的回应策略
舆情分析不再是简单的数据统计,而是企业和组织必备的社会雷达。Doris+DeepSeek的组合将成为这个领域的有力工具。
AI赋能舆情分析,让危机变成机遇。你的99行代码,可能就是阻挡舆情风暴的最后一道防线。
感兴趣的话,下期我们将深入探讨如何使用Doris+AI处理更复杂的多维数据分析场景,敬请期待!


如何学习AI大模型?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 20
20 0
0- 0



 已为社区贡献273条内容
已为社区贡献273条内容

所有评论(0)