对比分析QwQ和DeepSeek-R1的强化学习方法
就在刚刚(2025年3月6日),阿里云Qwen团队发布了其最新研究成果QwQ-32B推理模型,该成果通过大规模强化学习技术突破性地提升了语言模型的智能水平。这款拥有32B参数的模型性能远超同样在QWen32B上训练出来的DeepSeek-R1-Distill-Qwen32B。展现出与DeepSeek-R1(激活参数37B/总参数671B)相匹敌的性能,标志着强化学习在预训练模型优化中的显著成效。
就在刚刚(2025年3月6日),阿里云Qwen团队发布了其最新研究成果QwQ-32B推理模型,该成果通过大规模强化学习技术突破性地提升了语言模型的智能水平。
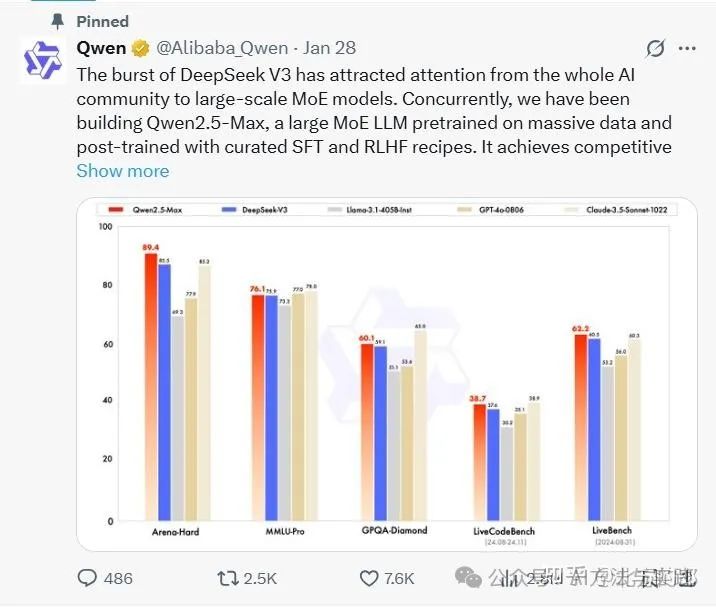
这款拥有32B参数的模型性能远超同样在QWen32B上训练出来的DeepSeek-R1-Distill-Qwen32B。展现出与DeepSeek-R1(激活参数37B/总参数671B)相匹敌的性能,标志着强化学习在预训练模型优化中的显著成效。
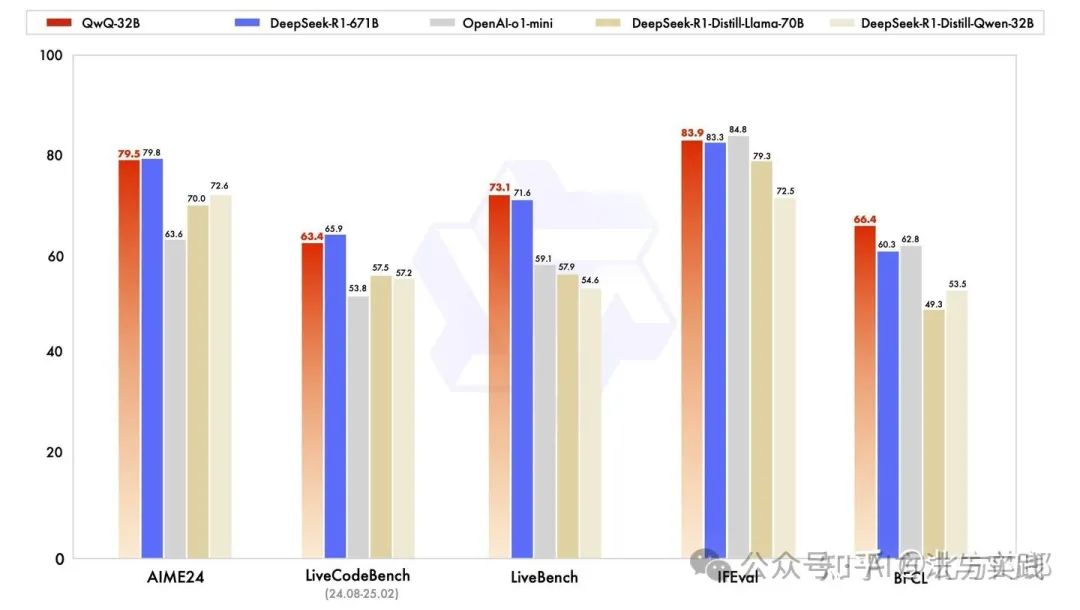
QwQ 和 DeepSeek-R1都是使用强化学习方法训练出来的推理大模型,那么它们的训练方法有什么差别呢,在这里简单分析一下。
1、DeepSeek-R1-Zero & DeepSeek-R1
DeepSeek-R1是第一个纯强化学习现的推理大模型,后续的很多推理大模型多多少少都借鉴了它的惊艳。QwQ在发布博客里面提到了DeepSeek-R1,原话”例如,DeepSeek R1 通过整合冷启动数据和多阶段训练,实现了最先进的性能,使其能够进行深度思考和复杂推理。“ ,所以我门就先分析一下它的方法。
这部分内容取自"A Visual Guide to Reasoning LLMs",详见北方的郎:图解推理大模型(Reasoning LLMs),DeepSeek-R1与测试时计算的革命性突破。
DeepSeek-R1-Zero
导致 DeepSeek-R1 的一个重大突破是一个名为 DeepSeek-R1 Zero 的实验模型。
从 DeepSeek-V3-Base 开始,他们没有对一堆推理数据使用监督微调,而是只使用强化学习 (RL) 来实现推理行为。
为此,他们从一个非常简单的提示(类似于系统提示)开始,贯穿于整个Pipeline:

可以看到,虽然提示中明确要求在 标签内写出推理过程,但并未对推理过程的具体形式做任何规定。
在强化学习阶段,他们基于规则设计了两类奖励:
-
准确度奖励(Accuracy rewards)
-
通过测试答案的正确性来给予奖励。
-
格式奖励(Format rewards)
-
对使用 和 标签的行为给予奖励。
他们所使用的 RL 算法名为 Group Relative Policy Optimization (GRPO) 。其核心思路是:
对于那些导致答案正确的所有决策——无论是特定的 token 序列还是推理步骤——都会在训练中获得使其更有可能被采纳的权重调整。
而对于那些导致答案错误的所有决策,则会在训练中获得使其更不可能被采纳的权重调整。
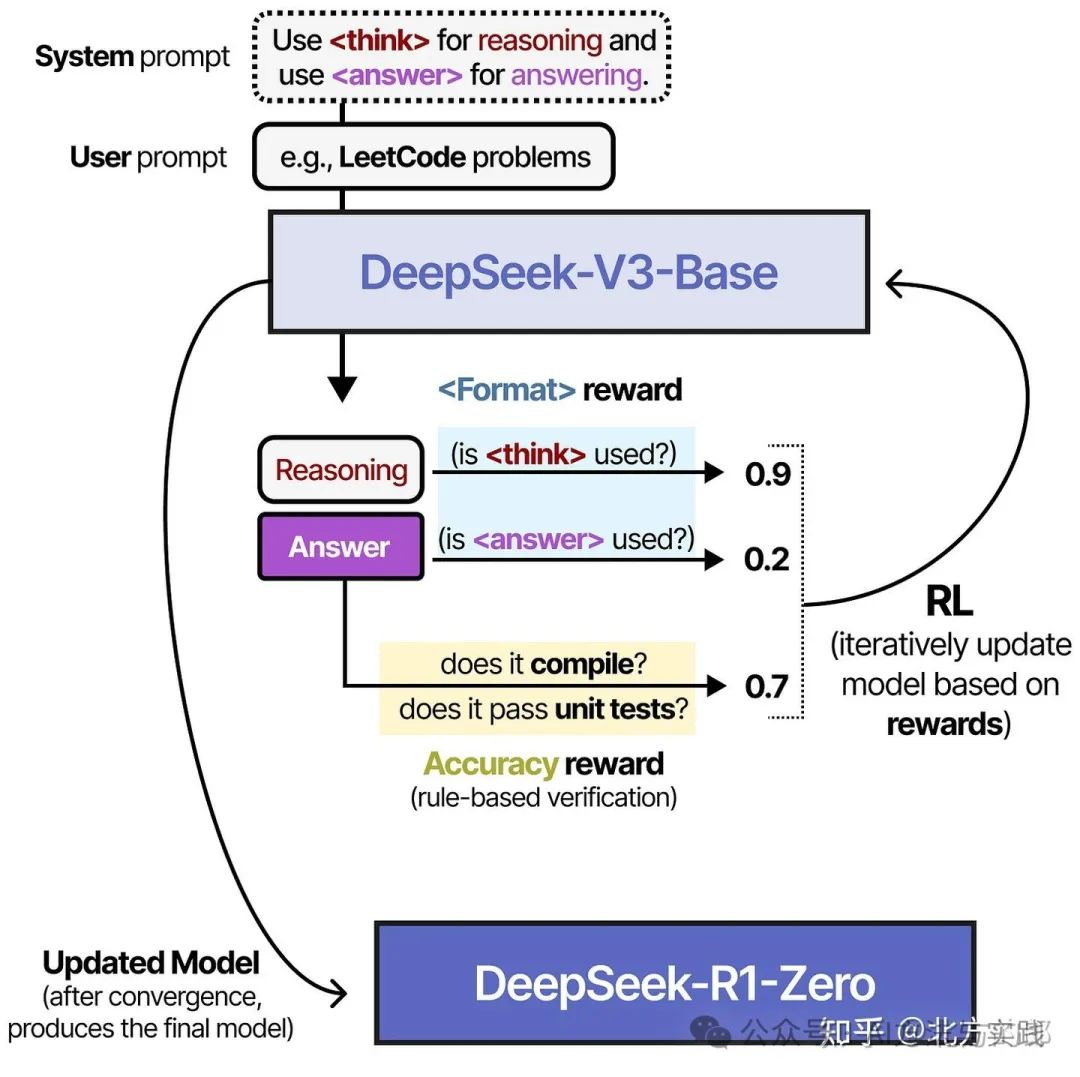
有趣的是,没有给出关于过程应该是什么样子的例子。它只是声明它应该使用 标签,仅此而已!
通过提供这些与思维链(Chain-of-Thought)行为相关的间接奖励,该模型自身了解到,推理过程越长、越复杂,答案正确的可能性就越大。
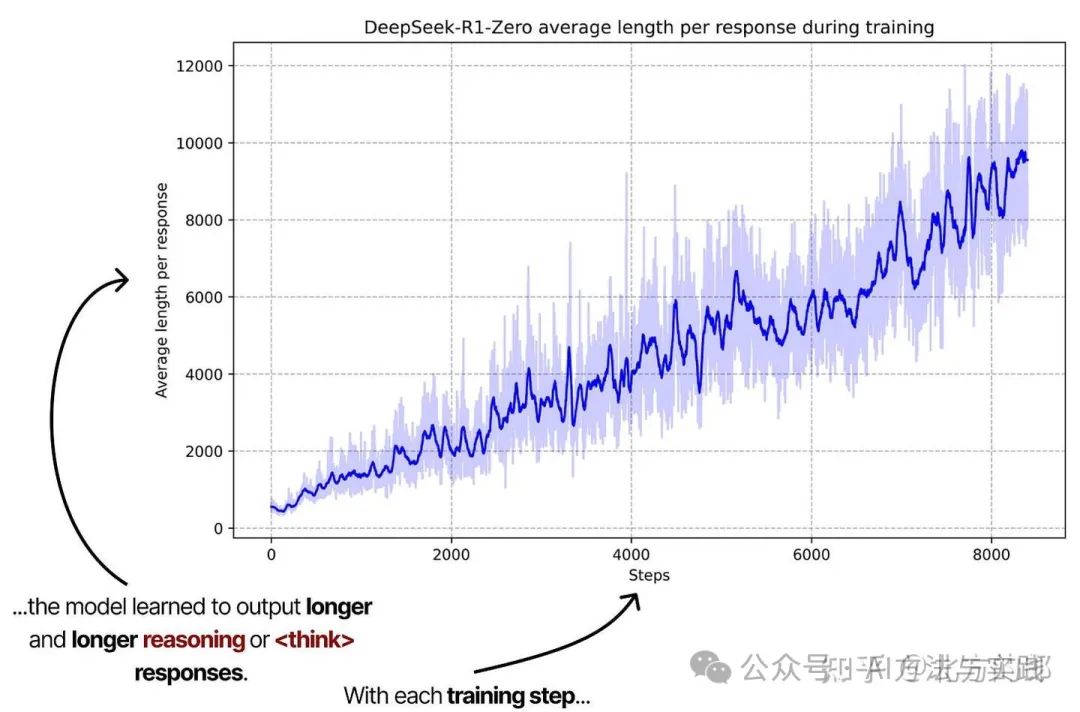
注释图来自 “DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning”通过使用间接 RL 奖励,该模型通过不断增加的推理步骤自由探索最佳的类似思维链的行为。
这张图非常重要,因为它进一步印证了从训练时计算到测试时计算的范式转变。当这些模型生成更长的思考序列时,实际上就加大了测试时计算的投入。
通过这样的训练流程,研究人员发现,模型能够自发地探索出最优的链式推理模式,并展现出如自我反思、自我验证等高级推理能力。
不过,这种做法仍存在一个显著缺陷:其输出的可读性不佳,而且有时会混用多种语言。为了解决这个问题,团队转而研究另一种思路,也就是 DeepSeek-R1。
DeepSeek-R1
DeepSeek-R1 的训练大体可以概括为以下五个阶段:
- 冷启动(Cold Start)
- 面向推理的强化学习(Reasoning-oriented Reinforcement Learning)
- 拒绝采样(Rejection Sampling)
- 监督微调(Supervised Fine-Tuning)
- 适用于所有场景的强化学习(Reinforcement Learning for all Scenarios)
以下是各个阶段的具体流程:
冷启动(Cold Start):在第一步中,研究人员使用一个小型的高质量推理数据集(约 5000 个tokens)对 DeepSeek-V3-Base 进行微调。这样做是为了避免“冷启动”问题导致的可读性不佳。
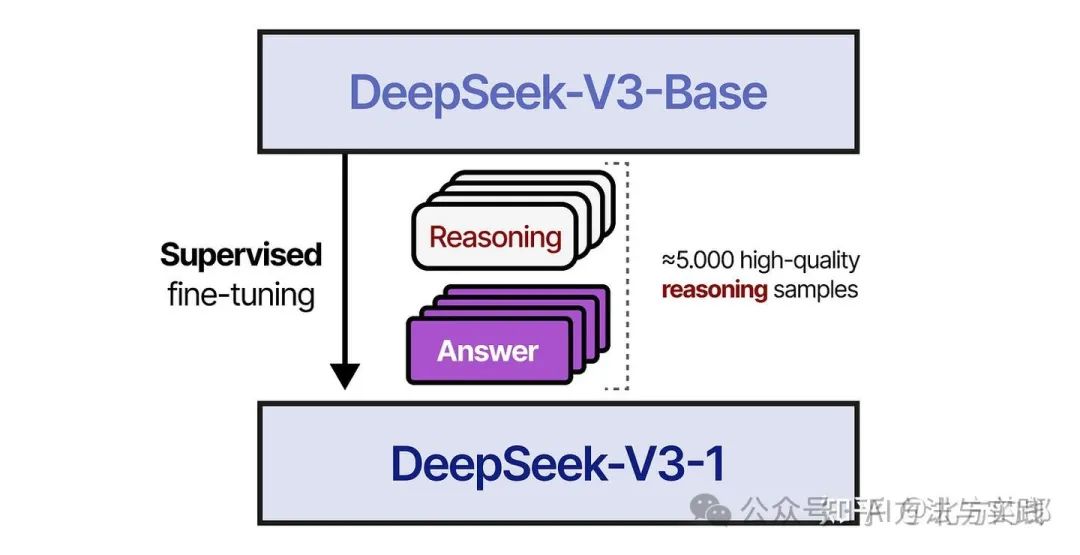
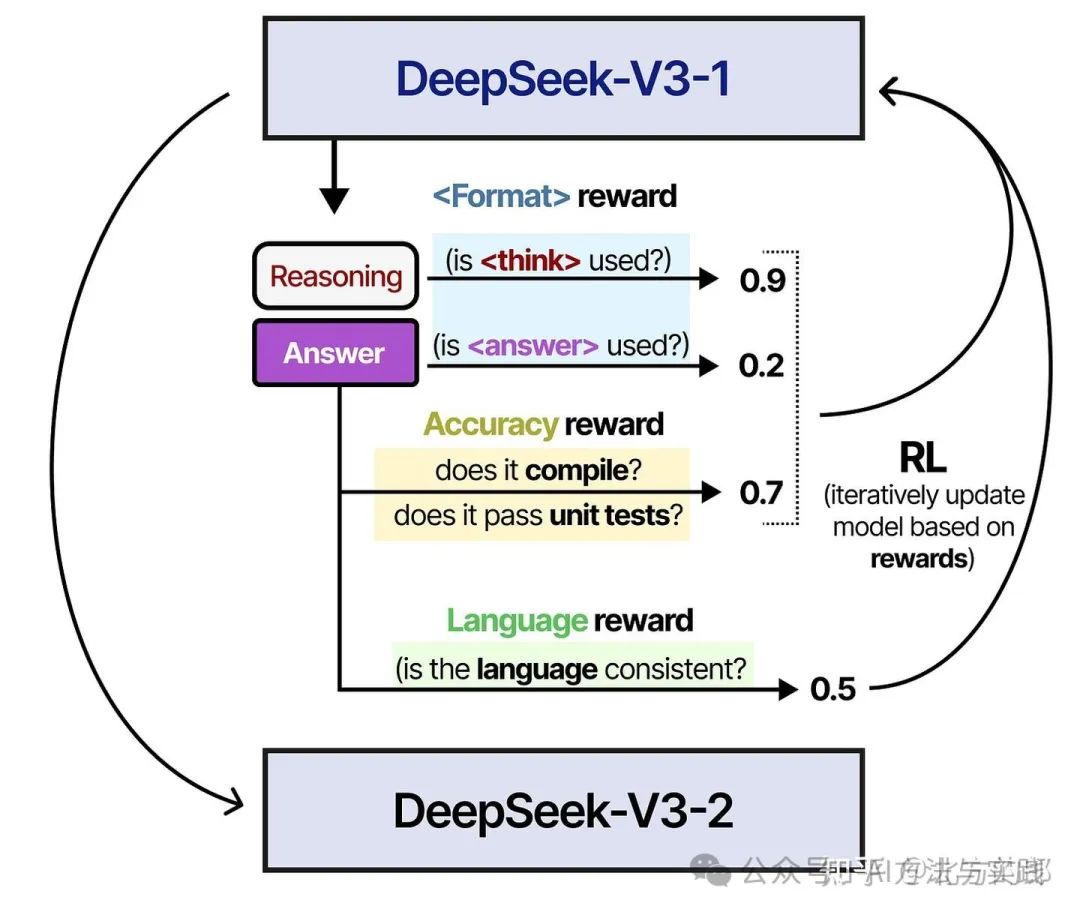
在第 2 步中,使用与训练 DeepSeek-V3-Zero 类似的 RL 过程对生成的模型进行训练。但是,添加了另一个奖励措施,以确保目标语言保持一致。
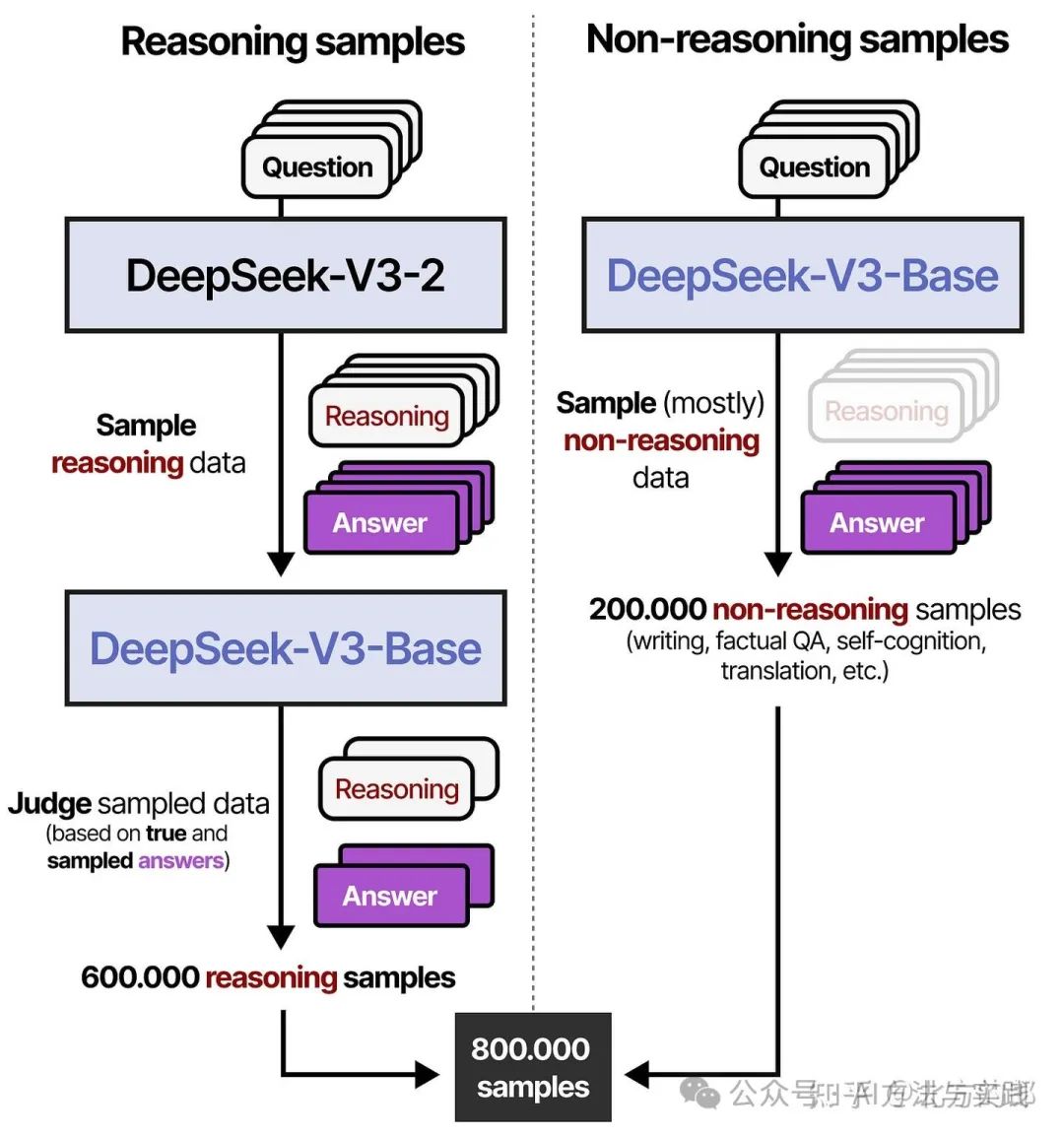
在第 3 步中,生成的 RL 训练模型用于生成合成推理数据,用于后期的监督微调。通过拒绝采样(基于规则的奖励)和奖励模型 (DeepSeek-V3-Base),创建了 600,000 个高质量的推理样本。此外,使用 DeepSeek-V3 创建了 200,000 个非推理样本,其中部分数据是其(V3)的训练数据。
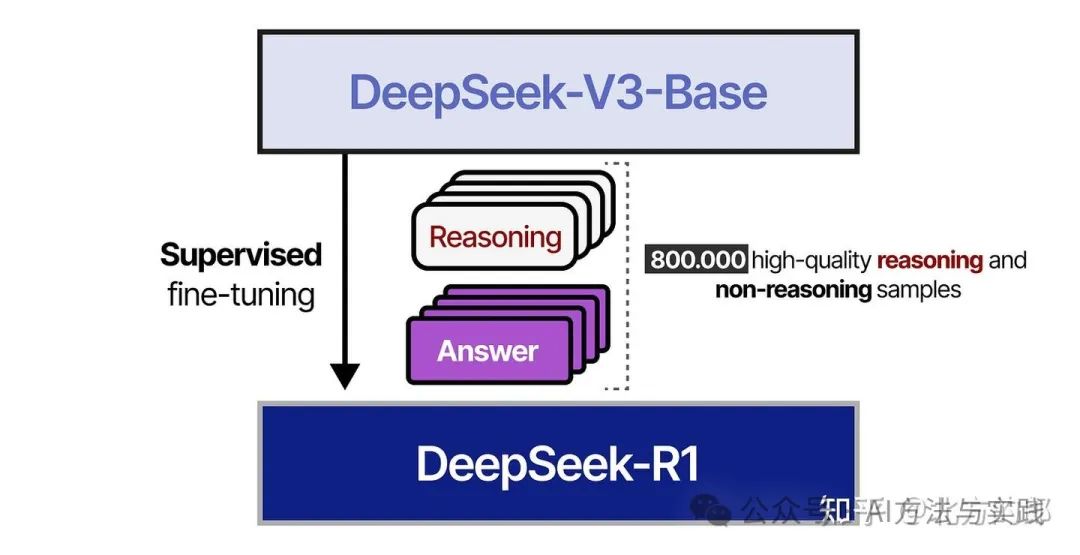
在第 4 步中,使用 800,000 个样本的结果数据集对 DeepSeek-V3-Base 模型进行监督微调。
在第 5 步中,使用 DeepSeek-R1-Zero 中使用的类似方法对结果模型执行基于 RL 的训练。
同时,为了对齐人类偏好(Human Preferences),他们添加了额外的奖励信号,专注于有用性和无害性。
该模型还被要求总结推理过程以防止可读性问题。
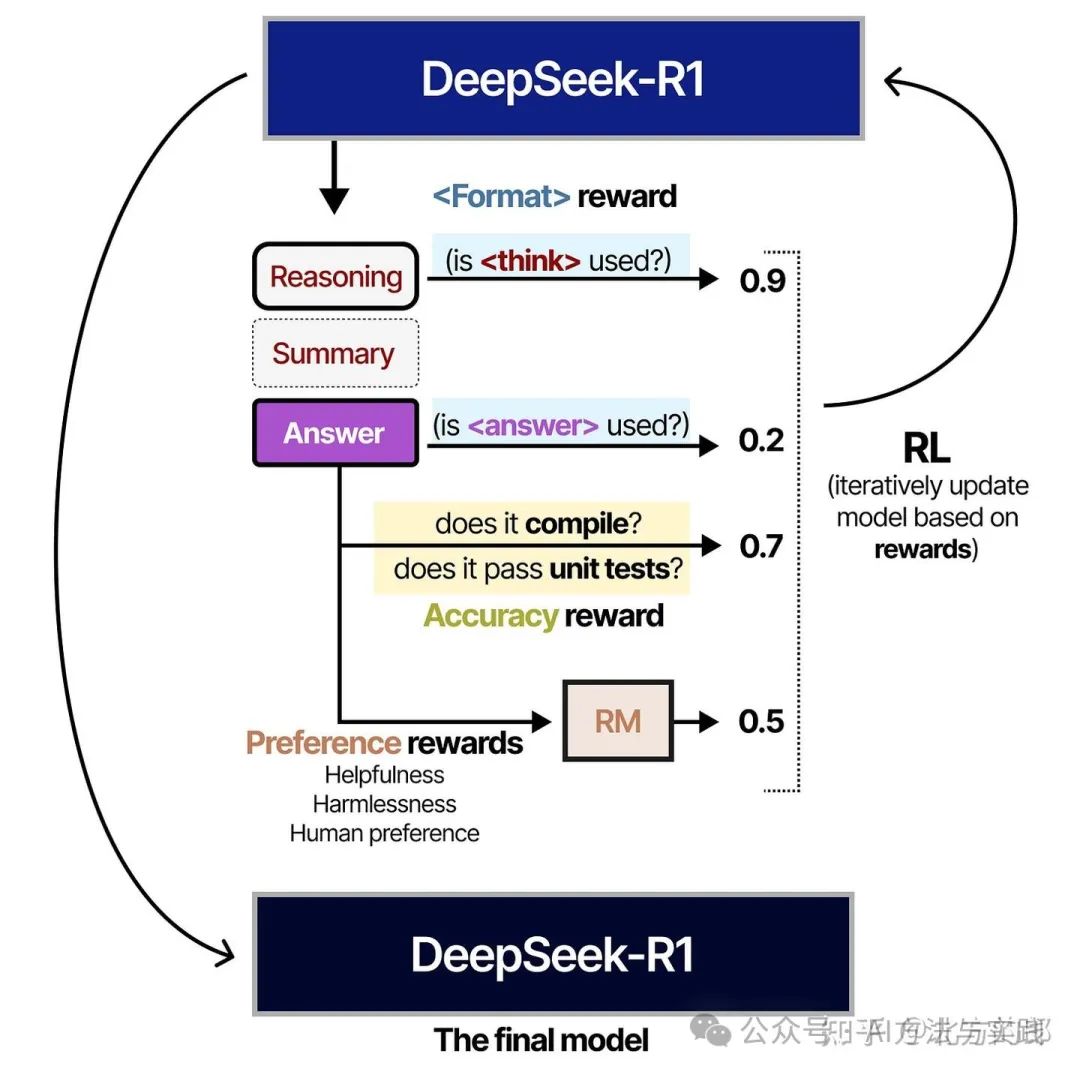
就是这样!这意味着 DeepSeek-R1 实际上是 DeepSeek-V3-Base 通过监督微调和强化学习进行的微调。 大部分工作是确保生成高质量的样本!
2、QwQ
QwQ技术报告中关于强化学习的篇幅很大,但实际内容并不多(其实这个报告就是非常短),摘录如下:
大规模强化学习(RL)有潜力超越传统的预训练和后训练方法来提升模型性能。近期的研究表明,强化学习可以显著提高模型的推理能力。例如,DeepSeek R1 通过整合冷启动数据和多阶段训练,实现了最先进的性能,使其能够进行深度思考和复杂推理。这一次,我们探讨了大规模强化学习(RL)对大语言模型的智能的提升作用,同时很高兴推出我们最新的推理模型 QwQ-32B。这是一款拥有 320 亿参数的模型,其性能可与具备 6710 亿参数(其中 370 亿被激活)的 DeepSeek-R1 媲美。这一成果突显了将强化学习应用于经过大规模预训练的强大基础模型的有效性。
我们在冷启动的基础上开展了大规模强化学习。在初始阶段,我们特别针对数学和编程任务进行了 RL 训练。与依赖传统的奖励模型(reward model)不同,我们通过校验生成答案的正确性来为数学问题提供反馈,并通过代码执行服务器评估生成的代码是否成功通过测试用例来提供代码的反馈。随着训练轮次的推进,这两个领域中的性能均表现出持续的提升。在第一阶段的 RL 过后,我们增加了另一个针对通用能力的 RL。此阶段使用通用奖励模型和一些基于规则的验证器进行训练。我们发现,通过少量步骤的通用 RL,可以提升其他通用能力,同时在数学和编程任务上的性能没有显著下降。
这是Qwen在大规模强化学习(RL)以增强推理能力方面的第一步。通过这一旅程,我们不仅见证了扩展RL的巨大潜力,还认识到预训练语言模型中尚未开发的可能性。在致力于开发下一代Qwen的过程中,我们相信将更强大的基础模型与依托规模化计算资源的RL相结合,将会使我们更接近实现人工通用智能(AGI)。
根据这些内容,我理解的QwQ的强化学习方法步骤:
冷启动, 首先是一个类似DeepSeek-R1的冷启动阶段,即通过收集少量高质量长思维链(CoT)数据(如少样本提示生成、人工优化输出),微调基础模型作为强化学习的初始策略。这样做的好处是提升回答可读性(结构化输出+摘要),增强模型表现稳定性,并为后续训练提供更优起点。
初始阶段 聚焦数学与编程领域(因为这两个好验证),创新性地采用答案验证机制替代传统奖励模型——数学问题通过结果正确性反馈,编程任务则通过测试用例执行服务器实时评估。
后续阶段 扩展至通用能力训练,结合奖励模型与规则验证器的混合方法,在保持专业领域优势的同时全面提升综合智能。实验数据显示,模型在各训练阶段均呈现持续的性能增长曲线。
通过这些步骤QwQ以32B的体量取得了媲美671B(激活37B)的DeepSeek-R1的成绩。
3、分析
通过分析我们发现其实前几步QwQ其实和DeepSeek-R1差不多,都有冷启动和针对编程和数学的强化学习步骤。
最后一步有差别,也就是:”在第一阶段的 RL 过后,我们增加了另一个针对通用能力的 RL。此阶段使用通用奖励模型和一些基于规则的验证器进行训练。“ 。而对应的DeepSeek-R1,则是格式,人类偏好混合。
是否是因为QwQ采用了更加精细的”通用奖励模型和一些基于规则的验证器“设计提升了整体的训练效果?取得了远超同样在QWen32B上训练出来的DeepSeek-R1-Distill-Qwen32B,媲美满血DeepSeek-R1的好成绩?需要等待后续QwQ进一步的技术细节。
不过QwQ其实是全面发展,数学推理和编程能力是它的强项,这方面其实它和DeepSeek-R1的方法应该是区别不大。难道是因为这两个模型在这方面训练的已经充分训练了,DeepSeek-R1参数多的优势发挥不出来?
我的DeepSeek部署资料已打包好(自取↓)
https://pan.quark.cn/s/7e0fa45596e4
但如果你想知道这个工具为什么能“听懂人话”、写出代码 甚至预测市场趋势——答案就藏在大模型技术里!
❗️为什么你必须了解大模型?
1️⃣ 薪资爆炸:应届大模型工程师年薪40万起步,懂“Prompt调教”的带货主播收入翻3倍
2️⃣ 行业重构:金融、医疗、教育正在被AI重塑,不用大模型的公司3年内必淘汰
3️⃣ 零门槛上车:90%的进阶技巧不需写代码!会说话就能指挥AI
(附深度求索BOSS招聘信息)
⚠️警惕:当同事用DeepSeek 3小时干完你3天的工作时,淘汰倒计时就开始了。
那么,如何系统的去学习大模型LLM?
作为一名从业五年的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?老师啊,我自学没有方向怎么办?老师,这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!当然这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~
👉大模型学习指南+路线汇总👈
我们这套资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。

👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。
👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。
👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。
👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐
 8
8 0
0- 0



 已为社区贡献122条内容
已为社区贡献122条内容

所有评论(0)