深入理解DeepSeek-R1
深入学习DeepSeek笔记
·
本文是个人学习笔记,仅用于学习AI相关知识。内容主要是本人经过学习,在原有的文本基础上加入了一些自己的理解, 且在学习中进行着不断完善,非常欢迎各位大佬指出错误,一起交流。
学习内容主要来自:腾讯云社区各位大佬博客,公众号ChallengeHub,腾讯元宝,DeepSeek等。
一、简介
DeepSeek-R1是由中国公司深度求索(DeepSeek)开发的开源大型语言模型,以其创新的架构设计、高效的推理能力和显著的成本优势,成为当前AI领域的重要突破。
二、架构
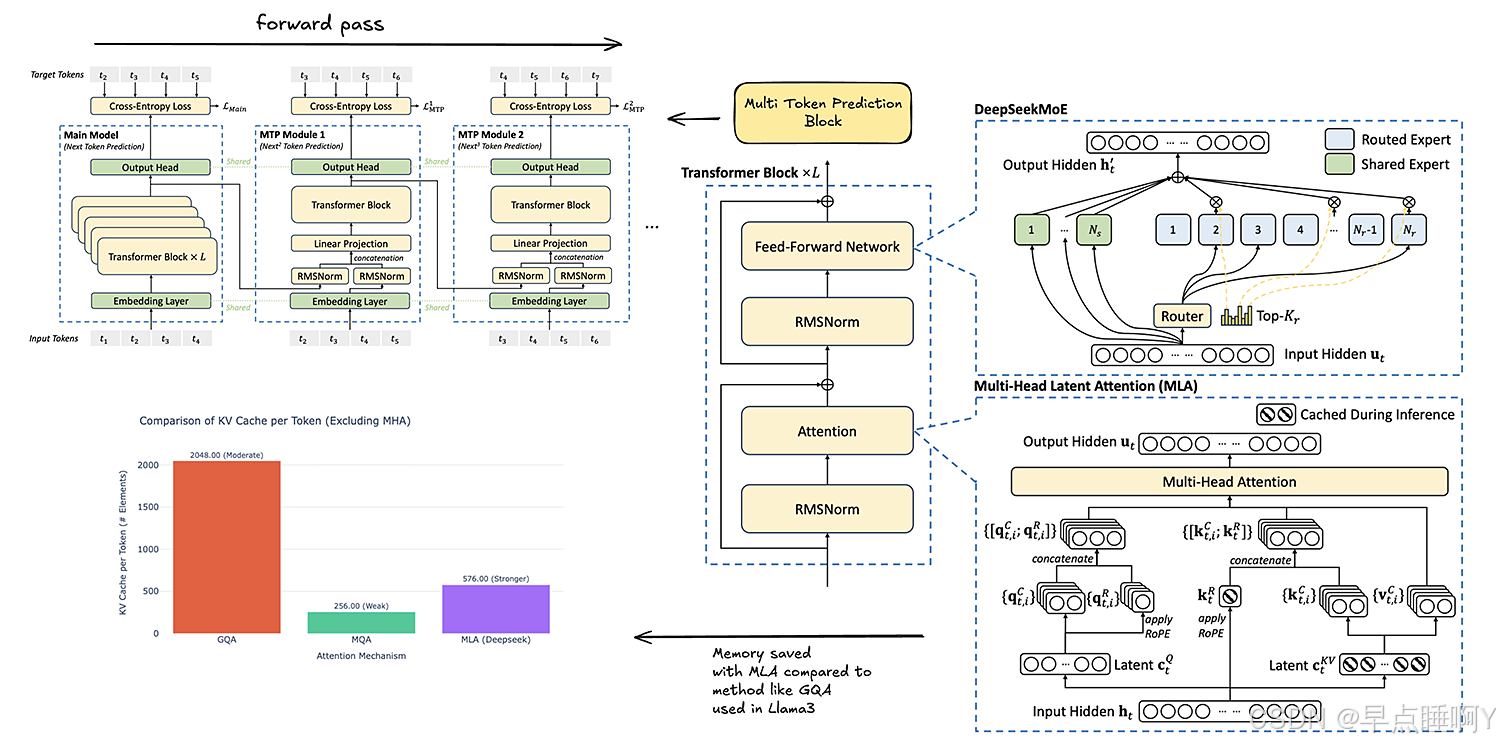
-
1. 专家混合模型:
- DeepSeek-R1 使用专家混合模型(MoE)架构,该架构将模型划分为多个“专家”子网络,每个子网络都擅长处理输入数据的子集。使用动态激活机制,这意味着在执行任务时,只有模型的相关部分会被激活,每个输入 token 仅激活 8 个专家(共 256 个),实际激活参数量为 370 亿(总参数 6710 亿),显著降低计算成本。
-
采用分层专家结构,前3层为密集层,模型底层(Embedding后的前3层)采用标准前馈网络(FFN),避免过早稀疏化导致基础语义特征丢失。4-61层为MoE层,从第4层开始,每层包含 256个专家,每个专家为独立的前馈网络(FFN),总参数量达 671B,但每个输入Token仅激活 8个专家(约37B参数),实现 稀疏计算。
-
2. 门控和无损负载均衡:
- DeepSeek 的 6710 亿参数的这种选择性激活是通过一种门控机制实现的,该机制动态地将输入定向到适当的专家,从而提高计算效率,而不会妨碍性能或可扩展性。对于每个 token,在单个前向传递中仅激活 370 亿个参数,并采用无损负载均衡等技术,这有助于确保所有专家子网络的使用均匀分布,以防止瓶颈。
-
3. 上下文长度:
- DeepSeek-R1 基于 DeepSeek-V3 的基础模型架构构建。两者都具有 128K 的上下文长度,该长度通过一种称为 YaRN(Yet another RoPE extensioN)的技术进行扩展,该技术扩展了 LLM 的上下文窗口。YaRN 是 Rotary Positional Embeddings(RoPE)的改进版本,RoPE 是一种位置嵌入类型,它使用旋转矩阵对绝对位置信息进行编码,YaRN 有效地插值矩阵中这些旋转频率的缩放方式。这是一种实用的方法,可以提高模型上下文长度并增强更长上下文的泛化能力,而无需进行昂贵的重新训练。
-
4. 层:
- DeepSeek-R1 具有一个嵌入层以及 61 个 Transformer 层。前三层由创新的 Multi-Head Latent Attention (MLA) 层和一个标准的 Feed Forward Network (FFN) 层组成,而不是 Transformer 层上典型的多头注意力 (MHA) 机制。
-
5. 多头注意力:
- 据该团队称,MLA 配备了低秩键值联合压缩,这在推理期间需要更少量的键值 (KV) 缓存,因此与传统方法相比,内存开销减少了 5% 到 13%,并且提供了比 MHA 更好的性能。专家混合层取代了第 4 层到第 61 层的 Feed Forward Network (FFN) 层,以便于扩展、高效学习并降低计算成本。
-
6. 多 token 预测:
- 这是一种先进的语言建模方法,可以并行预测序列中的多个未来 token,而不是一次预测一个后续单词。最初由 Meta 引入,多 token 预测 (MTP) 使模型能够利用多个预测路径(也称为“头”),从而可以更好地预测 token 表示,并提高模型在基准测试中的效率和性能。
显著优势:
- 基于群体相对策略优化的强化学习: DeepSeek-R1 基于之前的模型 DeepSeek-V3-Base 构建,采用多阶段训练,包括监督微调和基于 群体相对策略优化 的强化学习。GRPO 专为增强推理能力和降低计算开销而设计,它无需外部“评论家”模型;而是相对评估各组响应。此功能意味着模型可以随着时间的推移逐步提高其推理能力,以获得奖励更高的输出,而无需大量标记数据。
- 奖励建模:这种试错学习方法激励模型给出既正确又合理的答案。它通过在任务完成后分配“奖励信号”的形式反馈来实现这一点,从而帮助改进强化学习过程。
- 冷启动数据:DeepSeek-R1 使用“冷启动”数据进行训练,这指的是一个最小标记、高质量的监督数据集,它可以“启动”模型的训练,使其快速获得对任务的一般理解。
- 思维链:DeepSeek-R1 使用 思维链 (CoT) 提示来处理推理任务并进行自我评估。这通过指导模型以结构化的方式分解复杂问题来模拟类人的推理,从而使其能够逻辑地推导出连贯的答案,并最终提高其答案的可读性。
- 拒绝采样:该模型还使用拒绝采样来剔除低质量数据,这意味着在生成不同的输出后,模型只选择满足特定标准的输出,用于进一步的微调和训练。
- 蒸馏:使用精选的数据集,DeepSeek-R1已被蒸馏成更小、更开放的版本,这些版本性能相对较高,但运行成本更低,最值得注意的是使用了 Qwen 和 Llama 架构。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 28
28 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)