《从零开始DeepSeek R1搭建本地知识库问答系统》四:FastApi 框架搭建本地知识库问答Web Server端
上一章我们实现了 RAG 的核心代码逻辑,本章我们就围绕核心代码来慢慢做大做强。既然是本地知识库问答,文档管理是必不可少的。对话聊天记录总不能一直放内存里,刷新就没了。1.**实现文档管理 API 接口**,有上传,更新,删除的操作。2.**添加会话管理 API 接口**,每一个会话都对应着相关的聊天历史记录,有 CRUD 操作。所以就不需要用到 LangChain 的 `Conversation
前言
最近推出的 DeepSeek R1 异常火爆,我也想趁此机会捣鼓一下,实现 DeepSeek R1 本地化部署并搭建本地知识库问答系统,其中实现的思路如下:
- 使用 windows 11 WSL2,创建子系统Linux,并使用 Anaconda 创建 pythn 环境。
- 下载 DeepSeek R1 蒸馏模型,使用 Ollama 框架作为服务载体部署运行。
- 基于 LangChain 构建本地知识库问答 RAG 应用。
- 利用 FastApi 框架,搭建后端服务系统。(本章内容)
- 使用 vue3 + ElementPlus 作为前端ui框架,实现问答系统前端功能。
- 不依赖于 Langchain 框架,而选择 LightRAG 架构,构建 RAG 应用。
上一章完成了 rag 应用核心代码的编写,本章准备利用 FastAPI 框架开始搭建后端服务系统。
下面有些小节会省略一些不必要的代码部分,请结合源代码搭配享用:
源代码 GitHub 地址:https://github.com/YuiGod/py-doc-qa-deepseek-server
文章打开,悠哉悠哉,赶快去拿纸,蹲下就开始 👇
一、思路整理
上一章我们实现了 RAG 的核心代码逻辑,本章我们就围绕核心代码来慢慢做大做强。
既然是本地知识库问答,文档管理是必不可少的。对话聊天记录总不能一直放内存里,刷新就没了。
- 实现文档管理 API 接口,有上传,更新,删除的操作。
- 添加会话管理 API 接口,每一个会话都对应着相关的聊天历史记录,有 CRUD 操作。所以就不需要用到 LangChain 的
ConversationBufferMemory函数了。 - 提供文档向量化 API 接口,目前只是简单的对所有文档全量向量化。后续我会更新,支持单个文档的向量化与去除向量化。
- 聊天交互流式响应 API 接口,符合 OpenAI 规范。
为了让大家有一个直观的感受,这里给出最终的前端效果预览:
-
文档管理和向量化
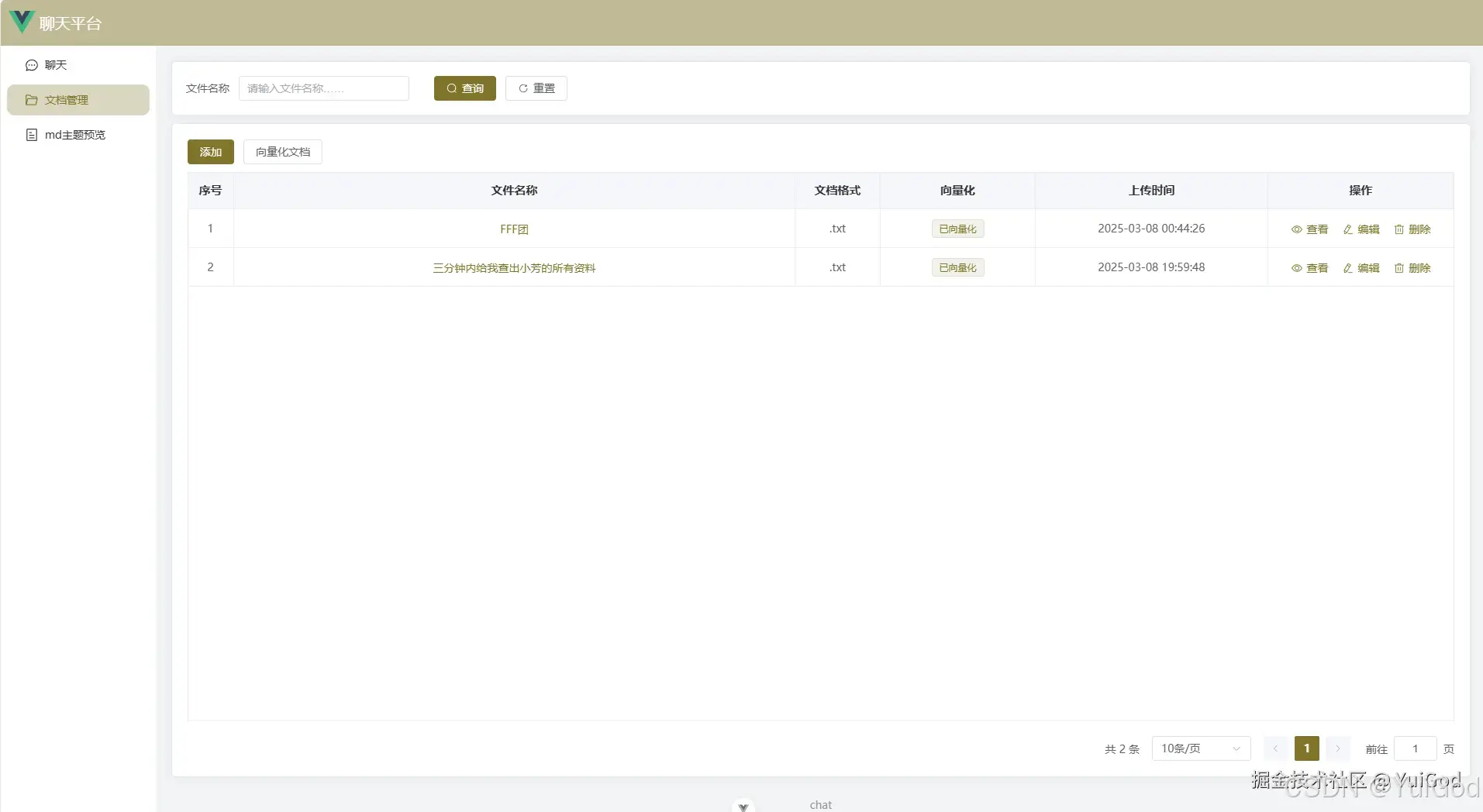
-
会话管理和聊天历史
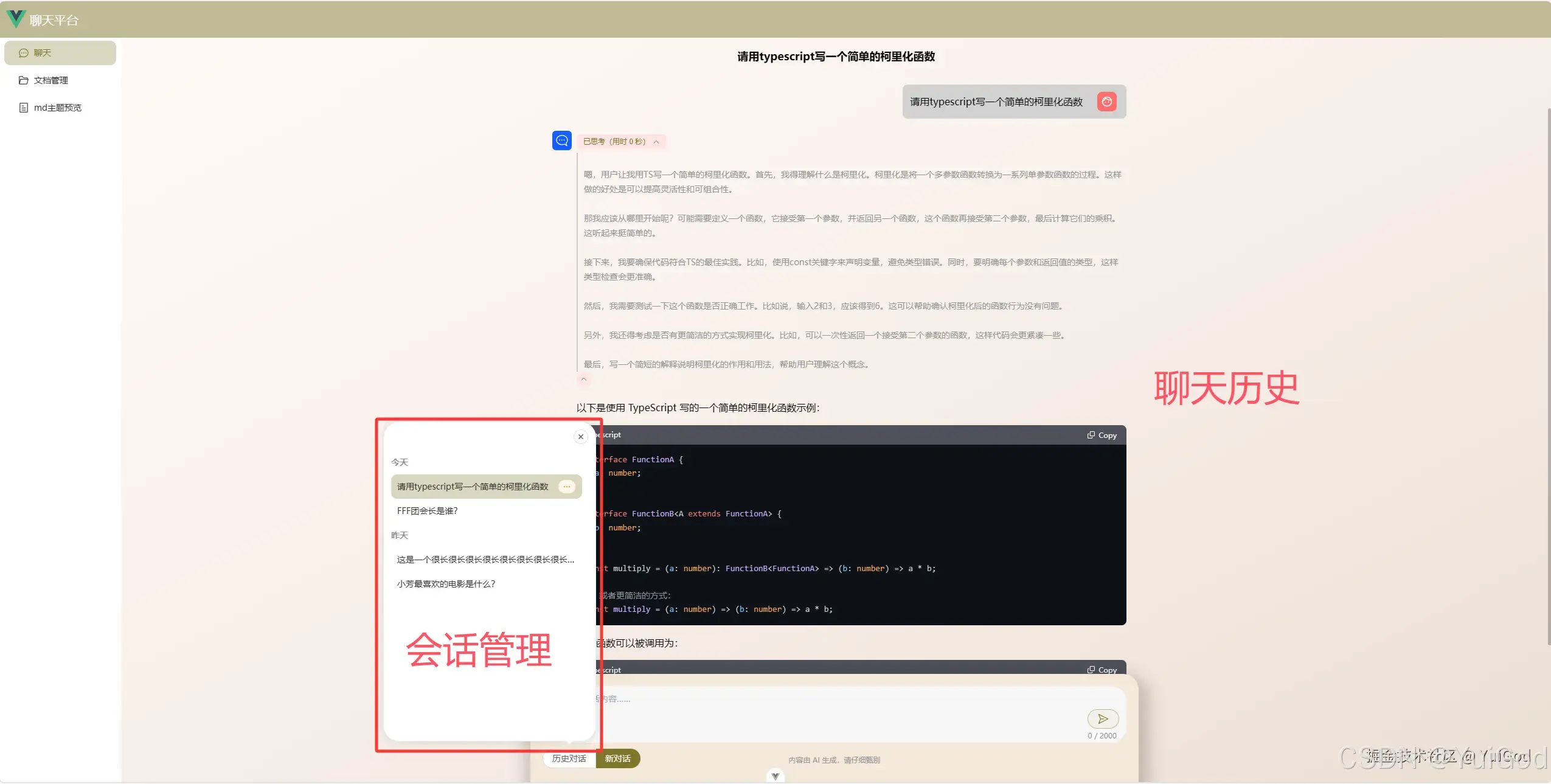
二、准备工作
- 要使用 FastAPI 框架一般还会需要一个基于 ASGI 服务器的框架来搭配使用,在官方教程中,推荐使用 FastAPI + Uvicorn 。
- 关系型数据库方面用 SQLite 轻量型数据库,并且 FastAPI 推荐 使用 SQLModel 与 SQL 进行 CRUD 交互。
- 上传文档保存还需要 OS 操作,这里用异步 OS 操作库 aiofiles。
1. 安装依赖
打开 Ubuntu 终端,切换 r1 环境,安装依赖:
# 切换 r1 环境
conda activate r1
# 安装 FastAPI
pip install fastapi
# 安装 Uvicorn
pip install "uvicorn[standard]"
# 安装 SQLModel
pip install sqlmodel
# 安装 aiofiles
pip install aiofiles
依赖库查漏补缺:requirements.txt
2. 安装 VSCode 插件 SQLite Viewer
安装这个插件,就可以直接在 VScode 预览和操作 SQLite 数据库。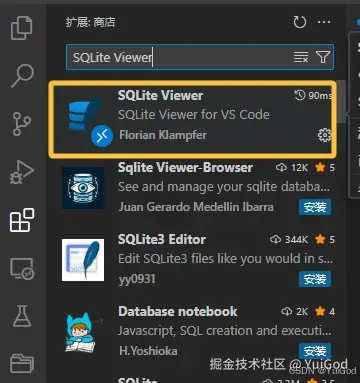
三、项目目录结构规范
创建项目 py-doc-qa-deepseek-server
- 文件资源管理器打开Linux,并进入到
home/ly/Project中。 - 右键新建文件夹,名为:
py-doc-qa-deepseek-server作为 python 服务端项目。 - 用 vscode 打开项目。
作为一个不大型企业级的项目,肯定要规范一下目录结构,如下:
app # 主目录
├── core # LangChan 核心代码
│ ├── base.py # LangChan 常量配置
│ ├── langchain_retrieval.py # 构建检索连
│ └── langchain_vector.py # 读取文档,分割文档,向量化文档
├── crud # 数据库 crud 操作目录
│ ├── __init__.py
│ ├── base.py # 数据库配置
│ ├── chat_history_crud.py # 对话聊天历史 crud
│ ├── chat_session_crud.py # 会话管理 crud
│ └── document_crud.py # 文档管理 crud
├── models # 数据库模型,基本模型目录
│ ├── __init__.py
│ ├── chat_history_model.py # 聊天历史记录管理数据库模型
│ ├── chat_model.py # 聊天模型,基本模型
│ ├── chat_session_model.py # 会话管理数据库模型
│ └── document_model.py # 文档挂你数据库模型
└── routers # api 路由分类
│ ├── __init__.py
│ ├── base.py # 基础配置,配置成功和失败返回模型
│ ├── chat_router.py # 聊天 Api
│ ├── chat_session_router.py # 会话管理 Api
│ └── document_router.py # 文档管理 Api
├── document_qa.db # SQLite数据库
├── main.py # 主程序启动服务入口
四、实现步骤
1. 初始化 FastApi Web 项目
1.1. 初始化 FastApi
成为 FastApi 项目,特别的简单,在 main.py 中,导入 FastApi 即可,使用 uvicorn 函数启动 web 服务。
如果所有的 url 都放在一个文件下,可能这个文件代码量会非常非常多,而且大型项目很少会将所有的内容都放在一个文件中。所以需要用到 FastApi APIRouter,将不同业务功能的 url 分离出去成单独的文件,最后再统一在 mian.py 中整合。
router 部分,在 /app/routers 中。我顺便重写了一下fastApi 错误返回信息。
main.py 代码如下:
import uvicorn
from fastapi import FastAPI
from fastapi.responses import JSONResponse
from starlette.exceptions import HTTPException as StarletteHTTPException
from routers.base import failure
# 导入 fastApi 子模块
from routers import chat_router
from routers import chat_session_router
from routers import document_router
# FastAPI 主入口
app = FastAPI()
# 将 fastApi 子模块整合到 app 中
app.include_router(chat_router.router)
app.include_router(chat_session_router.router)
app.include_router(document_router.router)
@app.exception_handler(StarletteHTTPException)
async def http_exception_handler(request, exc):
"""
重写 fastApi 错误信息
"""
return JSONResponse(
failure(exc.status_code, exc.detail), status_code=exc.status_code
)
if __name__ == "__main__":
# 启动 uvicorn 服务
uvicorn.run("main:app", port=8082, log_level="info", reload=True)
以后,直接命令行行就可以启动 serve 服务了。
cd app
python mian.py
1.2. FastApi APIRouter
APIRouter 的使用也很简单,导入该 APIRouter,并在函数使用 @router 注解即可。
例如 document_router.py 部分代码如下:
# document_router.py 部分代码
from fastapi import APIRouter
from typing import Annotated
router = APIRouter(
prefix="/documents",
tags=["documents"],
responses={404: {"message": "您所访问的资源不存在!"}},
)
@router.post("/add")
async def add_doc(data: Annotated[UploadFormData, Form()]):
await document_crud.add(data)
return success(None, "添加成功!")
这里配置了 prefix="/documents" 统一 url 路径前缀。在注解 @router 中最后会自动添加 "/documents" 路径。
最终,rul 的路径将会是 http://localhost:8082/documents/add。
2. 配置和连接数据库
2.1. 创建 SQLModel 模型
使用 SQLModel 结构。在当前目录 /app/models 下,新建如下文件。
app
├── models
│ ├── __init__.py
│ ├── chat_history_model.py # chathistory表模型
│ ├── chat_session_model.py # chatsession表模型
│ └── document_model.py # document表模型
重点是 class 继承 SQLModel,并加上参数 table=True,成为一个 SQLModel 模型。
2.1.1. document_model.py
from sqlmodel import Field, SQLModel
from datetime import datetime
import uuid
class Document(SQLModel, table=True):
"""document表"""
id: uuid.UUID = Field(default_factory=uuid.uuid4, primary_key=True) # id
name: str # 文档名称
file_name: str = Field(index=True) # 服务器文档名称,为了避免名称重复,一般使用 uuid
file_path: str | None = None # 服务器文档保存路径
suffix: str | None = None # 文档后缀格式
vector: str | None = None # 是否已经向量化
date: datetime = Field(default_factory=datetime.now) # 创建时间
2.1.2. chat_session_model.py
from sqlmodel import Field, SQLModel
from datetime import datetime
import uuid
class ChatSession(SQLModel, table=True):
"""chatsession表"""
id: uuid.UUID = Field(default_factory=uuid.uuid4, primary_key=True) # id
title: str | None = None # 会话标题
date: datetime = Field(default_factory=datetime.now) # 创建时间
2.1.3. chat_history_model.py
from sqlmodel import Field, SQLModel
from datetime import datetime
import uuid
class ChatHistory(SQLModel, table=True):
"""chathistory表"""
id: uuid.UUID = Field(default_factory=uuid.uuid4, primary_key=True) # id
role: str # 角色
content: str # 正文内容
think: str | None = None # 思考内容
chat_session_id: uuid.UUID | None = None # 会话 id
date: datetime = Field(default_factory=datetime.now) # 创建时间
2.2. 配置数据库
在当前项目目录 /app/curd,新建一个 base.py 文件。
重点是导入所有数据库表这里,一定记得导入刚才创建的表。否则 SQLModel 不知道 SQLModel 模型在哪里。
并且创建一个全局且唯一 engine,engine 是所有关于数据库操作代码共享的单个对象,它负责与数据库通信,处理连接。在其他需要 crud 操作的文件,都需要导入这个 engine 。
from typing import Annotated
from fastapi import Depends
from sqlmodel import SQLModel, Session, create_engine
# 导入 所有数据库表
from models import document_model, chat_session_model, chat_history_model
# 创建数据库
sqlite_file_name = "document_qa.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
# 创建全局 engine,database 的所有操作都需要导入这个 engine 来连接数据库
engine = create_engine(sqlite_url, echo=True)
def create_db_and_tables():
"""创建数据库和所有表"""
SQLModel.metadata.create_all(engine)
def get_session():
"""依赖注入,将engine注册到FastApi session中"""
with Session(engine) as session:
yield session
# FastApi 注入
SessionDep = Annotated[Session, Depends(get_session)]
2.3. 在 main.py 中导入
from crud.base import create_db_and_tables
if __name__ == "__main__":
# 创建或启动数据库
create_db_and_tables()
3. 数据库 crud 操作
所有有关数据库操作的文件都在 /app/crud 包下,文件中需要导入 engine 连接数据库,并 使用 Session与数据库交互。代码比较简单,我这里不过多的赘述了。
大家可以在我的项目源代码里查看,或者查阅 SQLModel - 用户指南。
app
├── crud # 数据库 crud 操作目录
│ ├── __init__.py
│ ├── base.py # 数据库配置
│ ├── chat_history_crud.py # 对话聊天历史 crud
│ ├── chat_session_crud.py # 会话管理 crud
│ └── document_crud.py # 文档管理 crud
五、 核心 Api
1. 文档向量化 Api
文档向量化 Api 在 /app/routers/document_router.py 文件中
app
└── routers # api 路由分类
│ └── document_router.py # 文档管理 Api
代码如下:
# document_router.py
from fastapi import APIRouter
from routers.base import success
router = APIRouter(
prefix="/documents",
tags=["documents"],
responses={404: {"message": "您所访问的资源不存在!"}},
)
@router.get("/vector-all")
async def vector_docs():
vector_documents()
document_crud.vector_all_docs()
return success(None, "已全部向量化。")
还记得 vector_documents() 这个函数吗?没错,就是上一章写的核心代码,文档向量化函数。
我将文件放到了路径 /app/core/langchain_vector.py 中。
app
├── core
│ ├── base.py # LangChan 常量配置
│ └── langchain_vector.py # 读取文档,分割文档,向量化文档
其中修改了 create_vector_store() 部分代码:
# langchain_vector.py
def create_vector_store(split_docs, persist_dir=VECTOR_DIR):
"""
创建持久化向量数据库
- split_docs: 经过分割的文档列表
- persist_dir: 向量数据库存储路径(建议使用WSL原生路径)
"""
# 初始化 Chroma 向量数据库
vector_store = Chroma(
persist_directory=persist_dir,
collection_name=COLLECTION_NAME,
embedding_function=OllamaEmbeddings(model=MODEL_NAME),
)
# 向量化文档之前,先把原来集合里的数据清空
ids = vector_store._collection.get()["ids"]
if len(ids):
vector_store.delete(ids=vector_store._collection.get()["ids"])
# 如果分割文档为空,不做向量化操作
if not split_docs or len(split_docs) == 0:
return
try:
start_time = time.time()
print(f"\n开始向量化====>")
# vector_store = Chroma.from_documents(
# client=chroma_client,
# collection_name="documents_qa",
# documents=split_docs,
# embedding=OllamaEmbeddings(model=MODEL_NAME),
# )
# 向量化文档到向量数据库
vector_store.add_documents(split_docs)
print(f"\n向量化完成!耗时 {time.time()-start_time:.2f} 秒")
print(f"数据库存储路径:{persist_dir}")
print(f"总文档块数:{vector_store._collection.count()}")
except Exception as e:
print(f"向量化失败:{str(e)}")
raise HTTPException(status_code=500, detail=f"向量化失败:{str(e)}")
def vector_documents():
"""
启动文档向量化,并保存数据库
"""
# 加载本地文档
documents = load_documents()
# 执行分割
split_docs = split_documents(documents)
# 执行向量化(使用之前分割好的split_docs)
create_vector_store(split_docs)
我目前的执行向量化是对 /fileStorage 的所有文件向量化。 为 Chroma 添加collection_name 集合,该集合下保存所有上传文档的向量化后的数据。
其实,即使不手动不添加 collection_name属性,你看 langchain_chroma 源码,它也会自动加上 collection_name="langchain"。

每次在向量化之前,先把向量数据库里的集合下的所有文档向量数据删除,再重新对文档向量化:
# 向量化文档之前,先把原来集合里的数据清空
ids = vector_store._collection.get()["ids"]
if len(ids):
vector_store.delete(ids=vector_store._collection.get()["ids"])
# 如果分割文档为空,不做向量化操作
if not split_docs or len(split_docs) == 0:
return
下面这两个 Chroma 代码函数,执行结果是一样的:
# 方式一:初始化 Chroma 向量数据库
# vector_store = Chroma.from_documents(
# persist_directory=persist_dir,
# collection_name="documents_qa",
# documents=split_docs, # 向量化文档到向量数据库
# embedding=OllamaEmbeddings(model=MODEL_NAME),
# )
# Chroma.from_documents()同等与以下代码
# 方式二:初始化 Chroma 向量数据库
vector_store = Chroma(
persist_directory=persist_dir,
collection_name=COLLECTION_NAME,
embedding_function=OllamaEmbeddings(model=MODEL_NAME),
)
# 向量化文档到向量数据库
vector_store.add_documents(split_docs)
对目录下的所有文档进行全量向量化,多少会有点不优雅。
既然已经有了文档管理,当然也可以指定哪些文档向量化,哪些文档不向量化,也可以将某个文档从向量数据库中删除或更新。这样就可以节省向量化资源和针对某些文档进行向量化了。
后续我会更新指定文档向量化和去除向量化的功能。
2. 聊天流式响应 Api
调用 LLM 模型与大模型聊天,总不能用控制台交互吧?
想要大语言模型回答更生动形象,总得就像人打字一样的聊天交互效果吧?
这时候就需要用到流式响应输出了。利用 application/x-ndjson 来实现流式输出。
2.1. chat Api 接口文档
我们需要实现这样的 Api 接口:
- 接口 url:
/chat - 请求类型:POST
- Request data 请求体:
{
"model": "deepseek-r1:7b", // 模型名称
"stream": true, // 开启流式响应
"messages": {
"role": "user", // 角色
"content": "FFF团会长是谁?" // 内容
}
}
- Responses 响应体:返回 JSON 对象字符串二进制流。
content-type: application/x-ndjson
// json 流未完成时
{
"model": "deepseek-r1:7b", // 模型名称
"created_at": 1741384731918, // 时间戳
"message": {
"role": "assistant", // 角色
"content": "首先" // 内容
},
"done": false // 流式未完成标记
}
{……}
...
// json 流完成时
{
"model": "deepseek-r1:7b", // 模型名称
"created_at": 1741384734349, // 时间戳
"message": {
"role": "assistant", // 角色
"content": "" // 内容,为空
},
"done": true, // 流式是已完成标记
"done_reason": "stop" // 完成信息
}
2.2. 代码实现逻辑
用户请求并携带问题参数,FastApi 接收到参数后。
- 从数据库中获取当前会话的历史聊天记录(等会会将历史记录传入 LangChain 检索链中);
- 等拿了聊天记录信息后,再保存 user 问题到历史记录中;
- 构建 LangChain 检索链;
- 聊天历史记录转成 LancChain 提示词模板数组;
- 将用户问题和历史记录提示词模板数组,传入到 LangChain 检索链中;
- 调用检索链管道,流式返回大模型回答的文本;
- 流式输出的同时,收集大模型思考和回答的文本;
- 将回答的文本包装一些json数据,以流式响应输出返回给前端。
- 流式输出完成后,收集到 assistant 的文本保存到历史记录中。
简化逻辑就是:
user 消息 → 查找历史记录 → 保存 user 消息到历史记录 → 调用检索链回答问题 → 流式响应给前端 → 流式完成后保存 assistant 消息到历史记录。
数据库查询出来的历史记录列表,转成提示词模板数组。
user聊天信息转成HumanMessage();assistant聊天信息转成AIMessage()。
代码路径:
app
├── core
│ ├── base.py # LangChan 常量配置
│ └── langchain_retrieval.py # 构建检索连
└── routers
│ ├── __init__.py
│ ├── base.py # 基础配置,配置成功和失败返回模型
│ └── chat_router.py # 聊天 Api
下面将结合代码细化流程说明,请看代码中的注释的流程。
2.2.1 用户请求聊天
# chat_router.py
router = APIRouter(
prefix="/chat",
tags=["chat"],
responses={404: {"message": "您所访问的资源不存在!"}},
)
chat_history_crud = ChatHistoryCrud()
@router.post("")
async def chatting(data: ChatParams):
if not data.messages:
raise HTTPException(status_code=500, detail="网络异常,请稍后重试!")
# 1. 从数据库中获取当前会话的历史聊天记录(等会会将历史记录传入 LangChain 检索链中);
history_list = chat_history_crud.list_by_chat_session_id(data.chat_session_id)
# 2. 再保存 user 问题到历史记录中
user_chat = ChatHistoryCreate(
role=data.messages.role,
content=data.messages.content,
chat_session_id=data.chat_session_id,
)
chat_history_crud.add_item(user_chat)
try:
# 3. 构建 LangChain 检索链
chain = build_qa_chain()
# 4. 聊天历史记录转成 LancChain 提示词模板数组
history_message = build_history_template(history_list)
# 5. 用户问题和历史记录提示词
invoke_params = {"question": data.messages.content, "chat_history": history_message}
# 返回 response 流式响应
return StreamingResponse(
# 6. 用户问题和历史记录提示词,传入到 LangChain 检索链中
generate_stream(chain, invoke_params, data.chat_session_id),
media_type="application/x-ndjson",
)
except Exception as e:
raise HTTPException(status_code=500, detail=f"流式响应失败:{str(e)}")
2.2.2. 流式响应输出
利用 yield 返回一个可迭代的 generator,循环遍历 LangChain 输出的文本流,并使用 StreamingResponse() 函数输出 Response。
有个特别重要的点是,调用检索链
chain.astream(invoke_params)一定要使用异步 astream() 函数。
# chat_router.py
async def generate_stream(chain, invoke_params, chat_session_id):
"""LangChain 流响应转 JSON 字符串流响应"""
think = ""
content = ""
isThinking = False
# 一个跳过本次循环的标记,目的是剔除think标签
loop_continue = False
# 6. 调用检索链管道,流式返回大模型回答的文本,一定要使用异步函数,astream()
async for chunk in chain.astream(invoke_params):
# 7. 流式输出的同时,收集大模型思考和回答的文本
loop_continue = False
if "<think>" in chunk:
isThinking = True
loop_continue = True
if "</think>" in chunk:
isThinking = False
loop_continue = True
if not loop_continue:
if isThinking:
think += chunk
else:
content += chunk
# 8. 将回答的文本包装一些 json 数据,转换成 json 字符串,以流式响应输出返回给前端
json_chunk = json.dumps(
jsonable_encoder(
ChatStreamResponse(
model="deepseek-r1:7b",
created_at=int(round(time.time() * 1000)),
message=Chatting(role="assistant", content=chunk),
done=False,
).model_dump(exclude_none=True)
),
ensure_ascii=False,
)
# 换行符分隔 JSON 行
yield f"{json_chunk}\n"
# 流结束后发送完成,再输出一行,标记已完成
done = json.dumps(
jsonable_encoder(
ChatStreamResponse(
model="deepseek-r1:7b",
created_at=int(round(time.time() * 1000)),
message=Chatting(role="assistant", content=""),
done=True,
done_reason="stop",
)
),
ensure_ascii=False,
)
yield f"{done}\n"
# 9. 流式响应完成后,assistant 消息保存到历史消息记录中
assistantChat = ChatHistoryCreate(
role="assistant",
content=content,
think=think,
chat_session_id=chat_session_id,
)
chat_history_crud.add_item(assistantChat)
2.2.3. 转换提示词模板与检索链
langchain_retrieval.py 的代码就是上一章的构建检索连核心代码部分。
代码里我删除了 ConversationBufferMemory() 聊天历史记忆缓冲区函数,原本这个函数是将历史记录缓存在内存中,现在已经不需要了。并改写了检索链的管道传递数据参数。
# langchain_retrieval.py
def build_history_template(chat_history_list: list[ChatHistory]):
"""构建聊天历史模板"""
if type(chat_history_list) != list or len(chat_history_list) == 0:
return []
history_messages: list[BaseMessage] = []
# 历史记录列表转换为 LangChain 消息对象数组
for history in chat_history_list:
if history.role == "user":
history_messages.append(HumanMessage(content=history.content))
elif history.role == "assistant":
history_messages.append(AIMessage(content=history.content))
return history_messages
def build_qa_chain():
# 初始化 Chroma 向量数据库
vector_store = Chroma(
persist_directory=VECTOR_DIR,
collection_name=COLLECTION_NAME,
embedding_function=OllamaEmbeddings(model=MODEL_NAME),
)
# 初始化 deepseek
llm = ChatOllama(
model=MODEL_NAME,
temperature=0.3,
streaming=True,
callbacks=[StreamingStdOutCallbackHandler()],
)
# 初始化检索,并配置
retriever = vector_store.as_retriever(
search_type="mmr",
search_kwargs={
"k": 5,
"fetch_k": 20,
"lambda_mult": 0.5,
"score_threshold": 0.6,
},
)
# system 提示词模板
system_template = """
您是一个设计用于査询文档来回答问题的代理,您的名字是超级牛逼哄哄的小天才助手。
您可以使用文档检索工具,并基于检索内容来回答问题。不需要说出检索文档的id。
您可能不查询文档就知道答案,但是您仍然应该查询文档来获得答案。
如果用户的问题与检索文档上下文的内容无关,您仍然应该查询文档来获得答案。
如果您从文档中找不到任何信息用于回答问题,则只需返回“抱歉,这个问题我还不知道。”作为答案。
文档上下文:{context}
"""
prompt = ChatPromptTemplate(
[
("system", system_template),
MessagesPlaceholder("chat_history"),
("human", "{question}"),
]
)
# 构建检索链管道 Runnable
# retriever.invoke() 作用是根据用户问题检索匹配最相关的文档
# x 值是管道里的参数,包括 question,chat_history,还要其他有关langchain的参数
return (
{
"context": lambda x: retriever.invoke(x["question"]),
"chat_history": lambda x: x["chat_history"],
"question": lambda x: x["question"],
}
| prompt
| llm
| StrOutputParser()
)
结语
现在,我们已经实现 FastApi 搭建 web server服务,并实现了:
- 实现文档管理 API 接口,有上传,更新,删除的操作。
- 添加会话管理 API 接口,每一个会话都对应着相关的聊天历史记录。
- 提供文档向量化 API 接口,目前只是简单的对所有文档全量向量化。后续我会更新,支持单个文档的向量化与去除向量化。
- 聊天交互流式响应 API 接口,符合 OpenAI 规范。
源代码 GitHub 地址:https://github.com/YuiGod/py-doc-qa-deepseek-server,欢迎 Start。
对于我这个 python 小萌新,写这个 server 端可以说是痛并快乐着,很多时候 python 看起来跟 typescript 和 java 很像,又有些不像。
如果代码看起来不够优雅,还请见谅。
现在已经把框架搭建起来,后面系统学习 LangGraph 时,将会以这个框架为基础陆续添加更多好玩的功能。
下一章,我们就开始使用 vue3 + ElementPlus + typescript 作为前端ui框架,实现问答系统前端功能。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 29
29 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)