Ubuntu服务器系统Docker部署Ollama+AnythingLLM实现DeepSeek本地部署
docker部署deepseek+anythinyLLM
文章目录
- 服务器配置
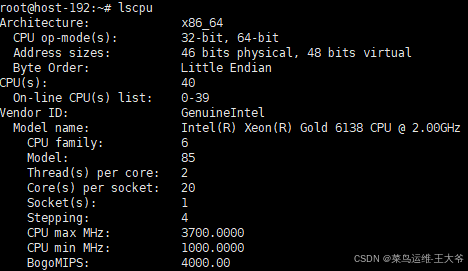
CPU:Intel® Xeon® Gold 6138 (20核心 40线程)
内存:32GB
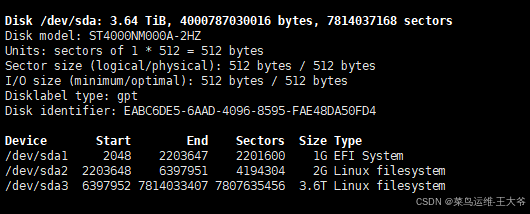
磁盘:4TB
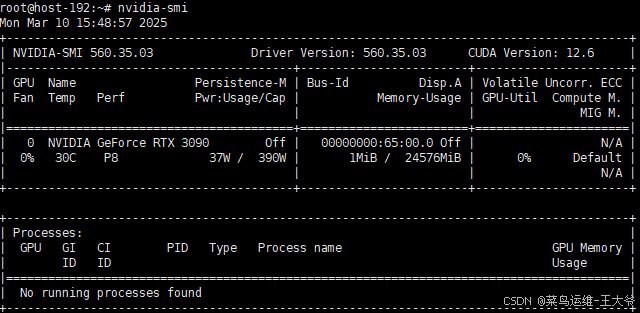
GPU:NVIDIA GeForce RTX 3090 24G显存
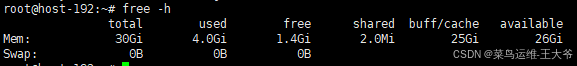
- 操作系统:Ubuntu server 22.04
- Docker版本:20.10.22
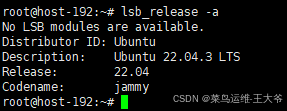
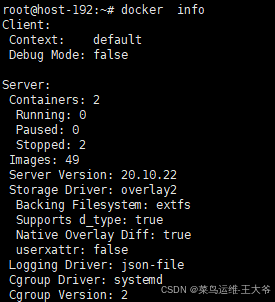
操作系统、docker、gpu驱动如何安装,这些都可以在网上搜到相关信息,本文就不再描述了。
拉取Ollama镜像
- Docker镜像仓库官方地址:docker官方镜像仓库地址
在“Explore”中找到“Gen AI”,然后往下翻,找到“Ollama”。
- 拉取指令
docker pull ollama/ollama

这个镜像比较大,而且国内拉取镜像本来也比较慢。之前还有阿里云,道客云等平台的镜像加速站,现在很多都不能用了,这里列几个可用的加速站点,读者可以配置上。
vim /etc/docker/daemon.json
{
"data-root": "/var/lib/docker",
"log-driver": "json-file",
"log-level": "warn",
"log-opts": {
"max-file": "3",
"max-size": "10m"
},
# 主要是如下内容,其余部分请根据自己实际环境配置。
"registry-mirrors": [
"https://proxy.1panel.live",
"https://docker.1panel.top",
"https://docker.m.daocloud.io",
"https://docker.1ms.run",
"https://docker.ketches.cn"
],
"runtimes": {
"nvidia": {
"args": [],
"path": "nvidia-container-runtime"
}
}
}
运行Ollama容器并拉取模型
根据镜像使用方式可知,运行ollama容器后,可在容器内拉取模型文件。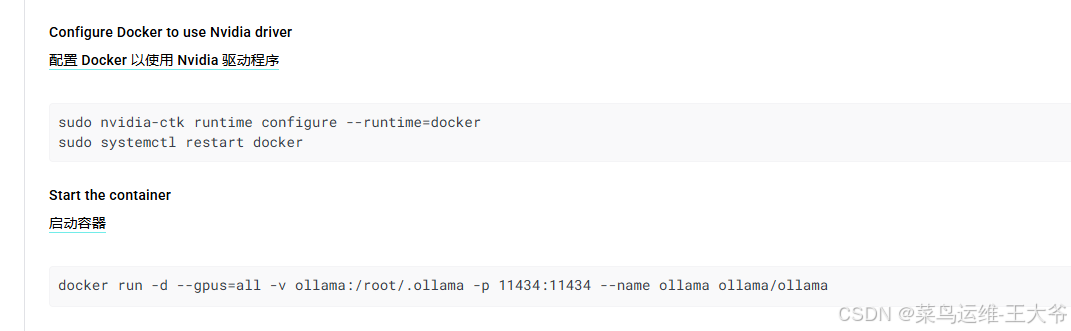
启动Ollama容器
docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
上述指令是官方给的参考指令,主要是-v参数,如果按照上述指令,-v后面直接根“ollama”,会在docker的存储卷中创建一个本地的ollama存储卷,如下图。不建议这种方式,因为这种方式,最后拉取的模型文件不好找(在这个目录中【/var/lib/docker/volumes】),还是建议采用自定义的绝对路径,方便找到模型文件保存的位置和迁移。
可以参考如下指令:
docker run -d --name ollama --gpus=all -v /home/rarelong/project/ollama/_data:/root/.ollama -p 11434:11434 ollama/ollama
其中,/home/rarelong/project/ollama/_data是我复制的/var/lib/docker/volumes/ollama/_data/这个目录的内容,说明ollama的模型文件是可以复制迁移的,那么就可以将ollama的镜像和这个目录全部打包,拷贝至没有互联网的环境中直接运行。
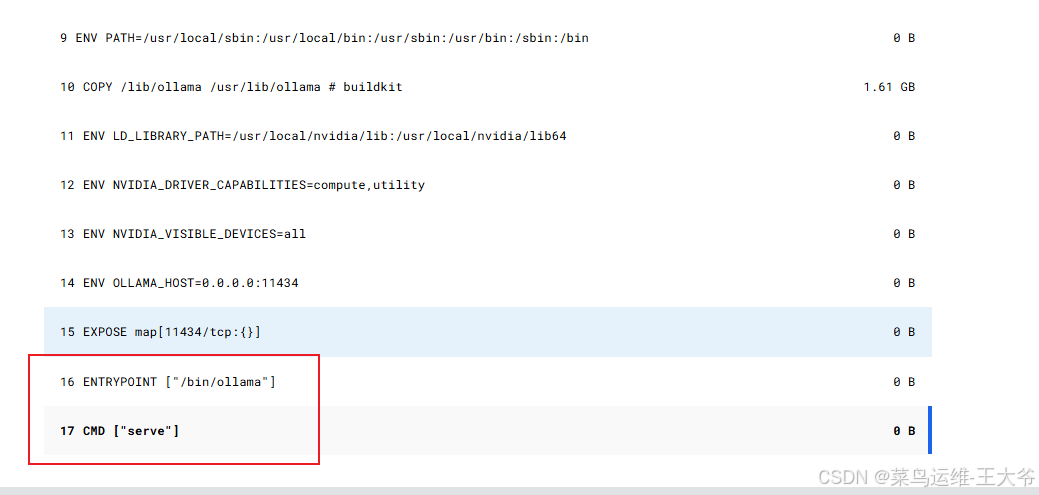
Ollama Dockerfile部分说明
从ollama的镜像dockerfile内容来看,官方指定了一个ENTRYPOINT [“/bin/ollama”],CMD [“server”],这导致我们只能先将ollama镜像启动起来,当作服务运行,然后用“docker exec -it”指令拉取模型文件或者运行模型。如果直接在启动的时候加上相关参数,会启动失败。如下图:

- 官方dockerfile部分内容
正常启动画面如下: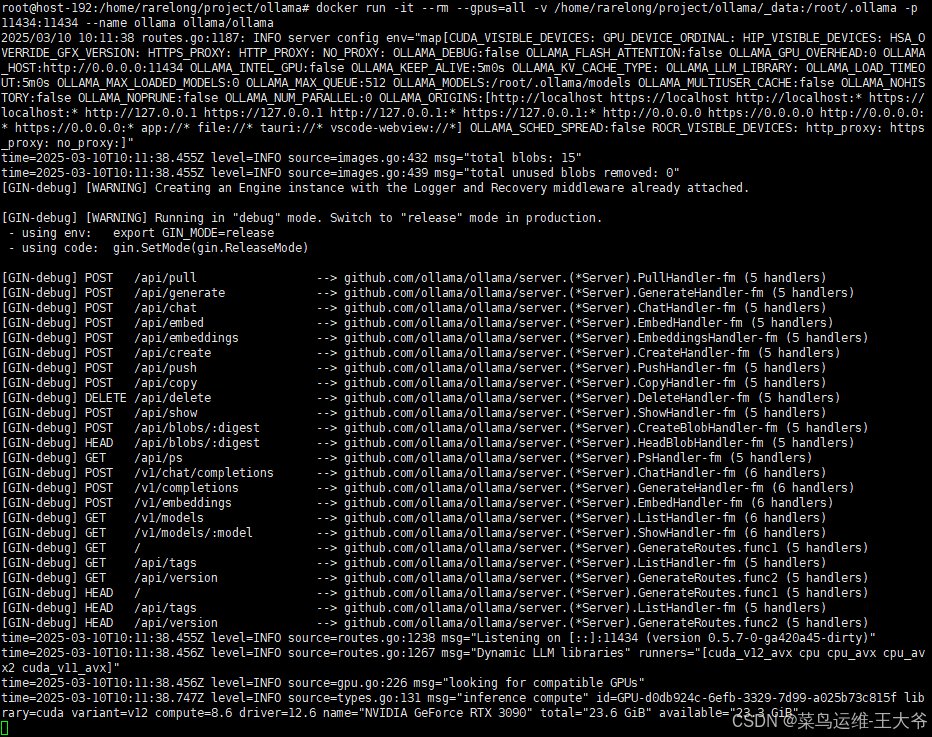
说明:其中docker启动的相关参数本文不做说明,比如【-itd,–rm,-p,-v】等,这些需要读者自行学习。本文并非基础教学内容,感谢理解。
拉取模型
Ollama官方地址:Ollama官方地址
前面几个就是deepseek-r1模型的链接,还有很多别的模型,可以根据需求下载。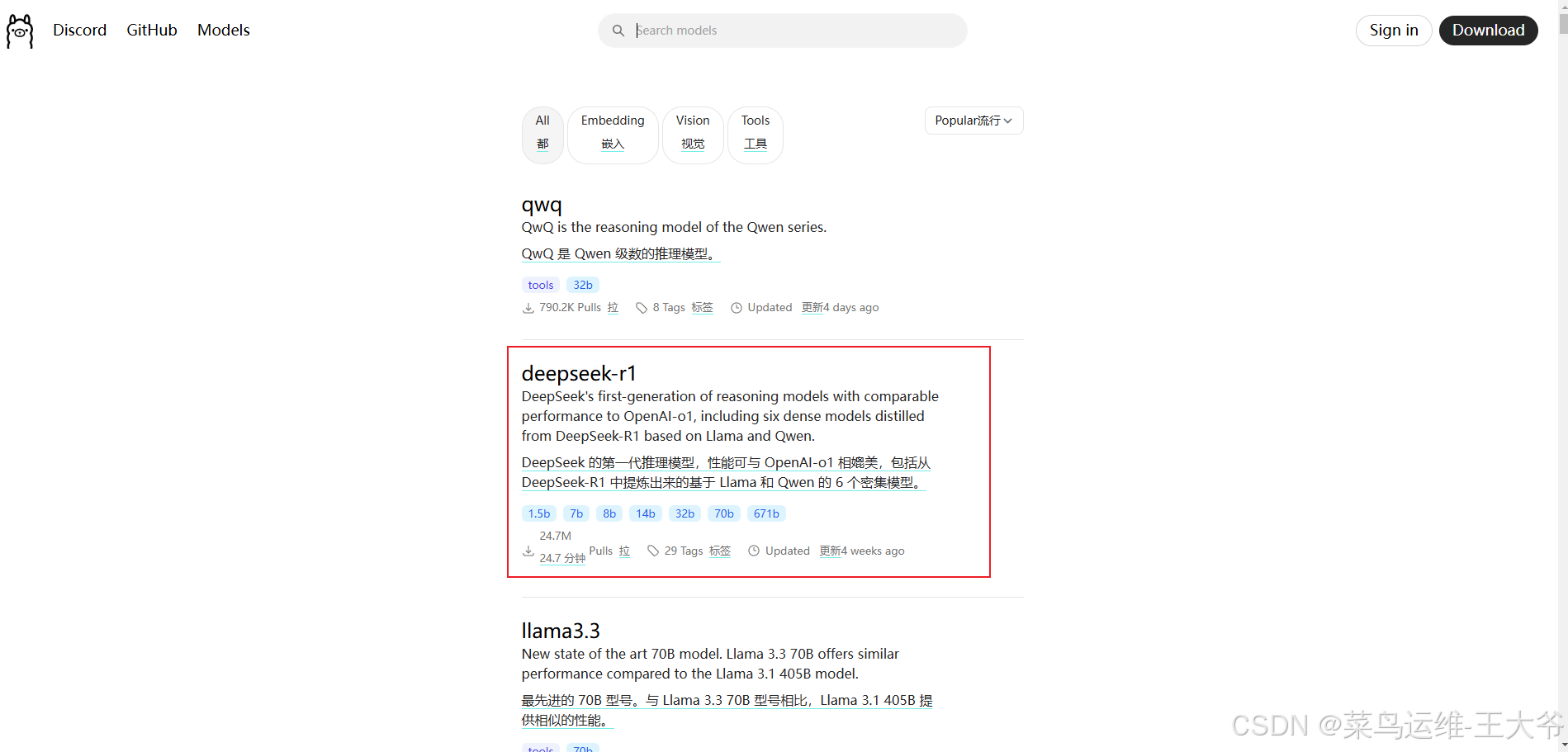
点击进去之后,就有选择版本和对应的下载指令。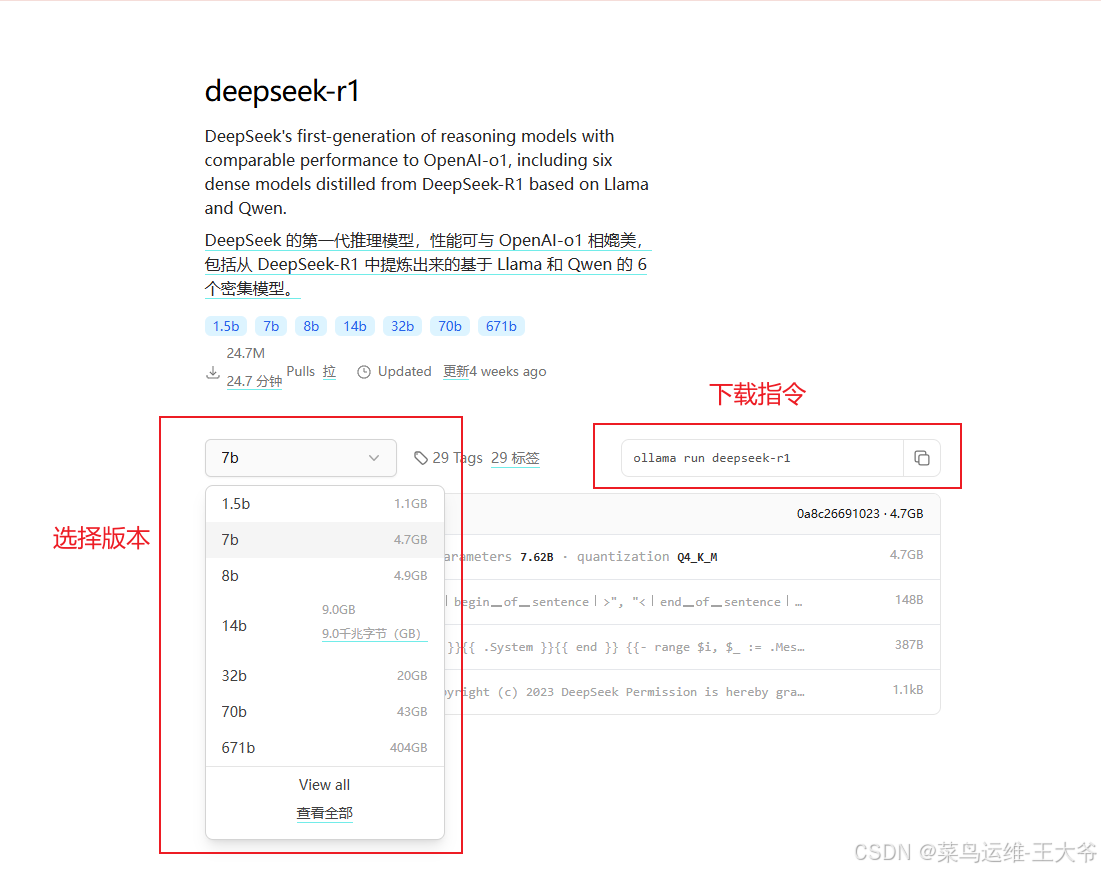
我这里已经下载了几个模型文件,32b,7b,8b这几个参数的文件。
比如这里我们再下载一个1.5b参数的模型。
- 如果采用的参数是“run”,当本地没有这个模型文件时,会自动从ollama仓库中去拉取这个文件,这点根docker运行容器类似。
- 只是单独拉取文件的话,应该是“pull”参数。这个根docker也是类似的。
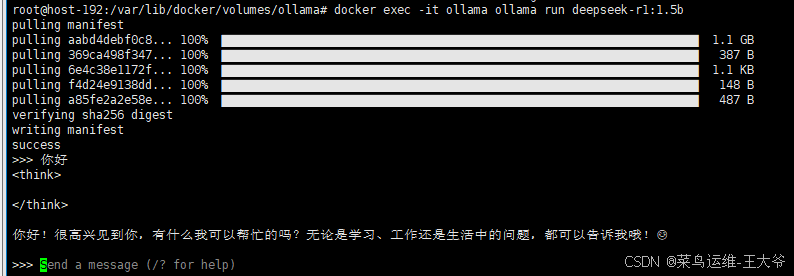
docker exec -it ollama ollama run deepseek-r1:1.5b

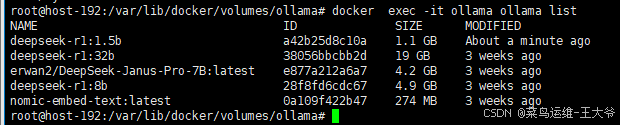
AnythingLLM容器部署
AnythingLLM官方地址:AnythingLLM官方地址
AnythingLLM 是一款专为企业或个人定制的 私有化大语言模型(LLM)应用平台,核心目标是为用户提供安全、可控且高度定制化的 AI 解决方案。
在官网上,一直往下翻,直到翻到“Run via Docker”时,点击,进入anythingllm的docker镜像仓库。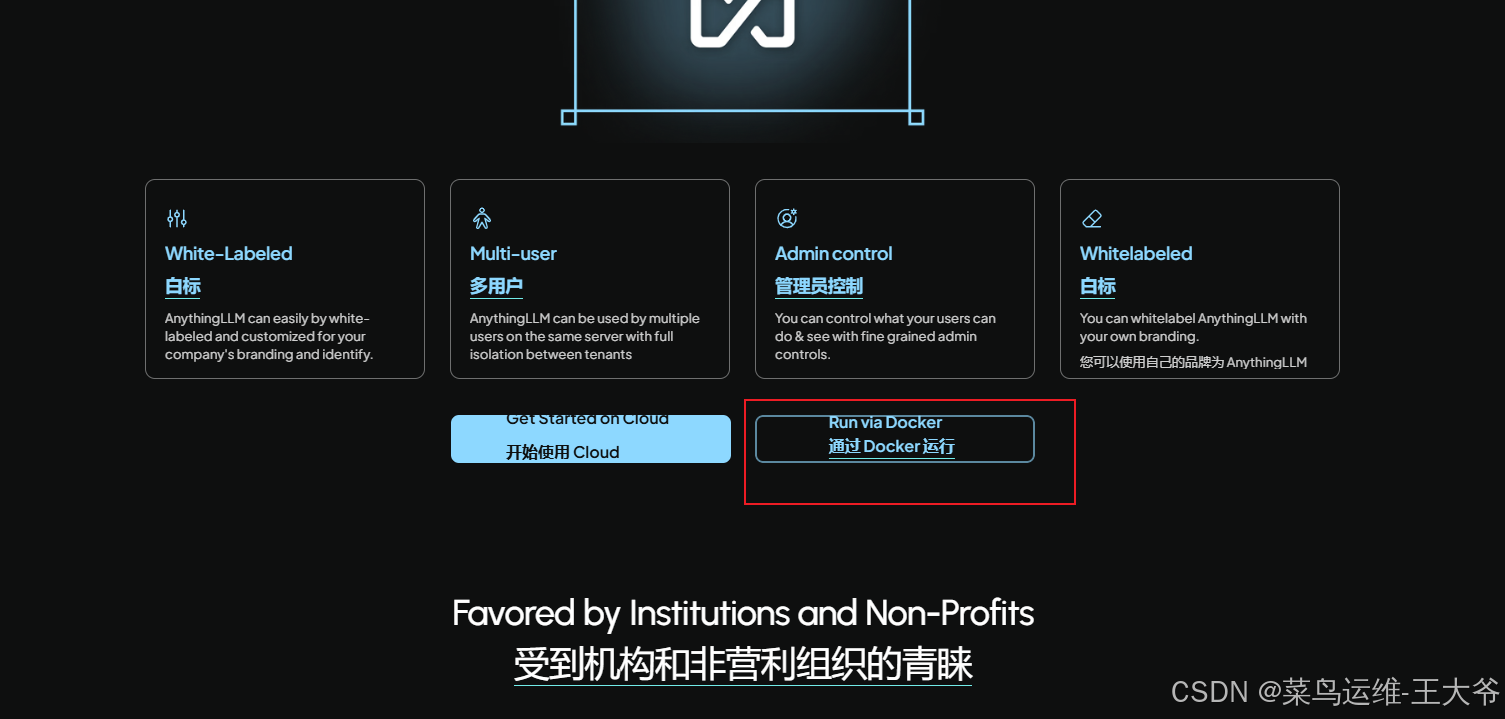
anythingllm镜像拉取
拉取镜像指令:
docker pull mintplexlabs/anythingllm
在概述文件中,有该镜像的相关说明,概述文件的最后有anythingllm容器的运行方式。

anythingllm容器运行
运行指南:anythingllm容器运行指南
anythingLLM文档
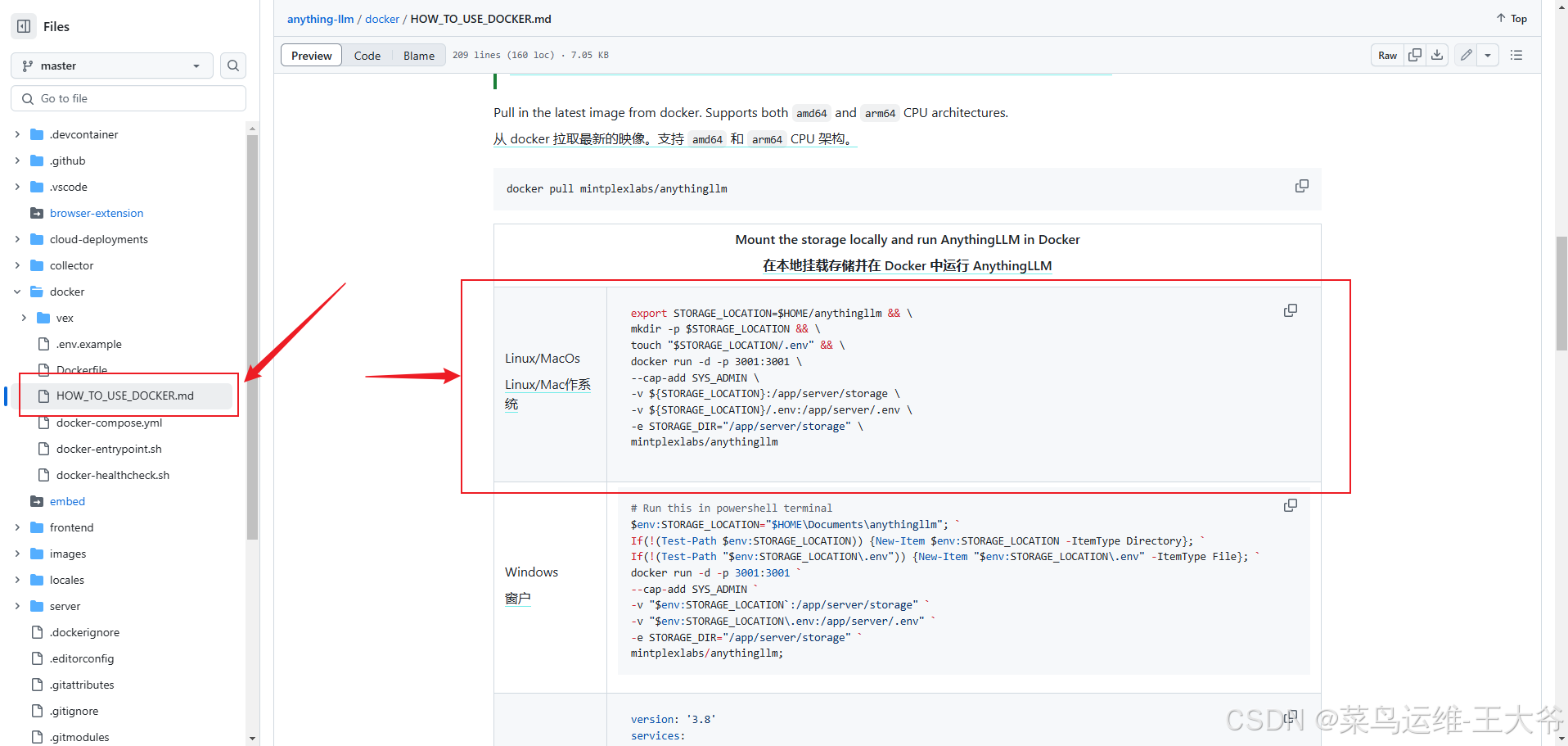
官方指令如下:
export STORAGE_LOCATION=$HOME/anythingllm && \
mkdir -p $STORAGE_LOCATION && \
touch "$STORAGE_LOCATION/.env" && \
docker run -d -p 3001:3001 \
--cap-add SYS_ADMIN \
-v ${STORAGE_LOCATION}:/app/server/storage \
-v ${STORAGE_LOCATION}/.env:/app/server/.env \
-e STORAGE_DIR="/app/server/storage" \
mintplexlabs/anythingllm
简单解释一下上述指令中的一些参数:
- export STORAGE_LOCATION= $ HOME/anythingllm:export定义当前bash的临时变量,变量名称【STORAGE_LOCATION】,变量值【 $ HOME/anythingllm】,其中$HOME是系统环境变量,值为当前用户的家目录。
- &&:表示执行完上一条指令后,继续执行下一条指令,如果上一条指令执行失败,后面的指令不再执行。
- mkdir:创建文件夹;-p:递归创建文件夹。
- touch:创建文件;.env:前面带点的文件为隐藏文件。这里应该是一个保存环境变量配置的文件。
- docker run:运行容器。
- cap-add SYS_ADMIN:给容器赋予比较宽泛的管理权限。注意【–cap-add SYS_ADMIN】 如果您想抓取网页,这是必需的命令。我们使用 PuppeeteerJS 来抓取网站链接,而 --cap-add SYS_ADMIN 允许我们在所有运行时中使用沙盒 Chromium 以实现最佳安全实践。
我这里之前运行过这个容器,所以前面的那些环境变量就不用设置了。如果你需要自定义这些换变量的内容,如数据存储目录(~/anythingllm目录),环境变量文件(.env),可以先行创建,在通过-v参数,以绝对路径方式挂载进容器。
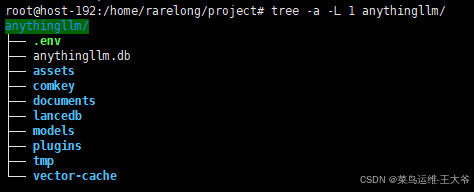
- 自定义运行指令:
docker run -d -p 3001:3001 --cap-add SYS_ADMIN -v /home/rarelong/project/anythingllm/:/app/server/storage -v /home/rarelong/project/anythingllm/.env:/app/server/.env -e STORAGE_DIR="/app/server/storage" mintplexlabs/anythingllm
通过这种方式,也可以把~/anythingllm目录和anythingllm的镜像打包迁移至别的安装有docker的服务器或pc上运行。
使用anythingLLM
- 访问
在浏览器输入服务器IP+端口,即可访问。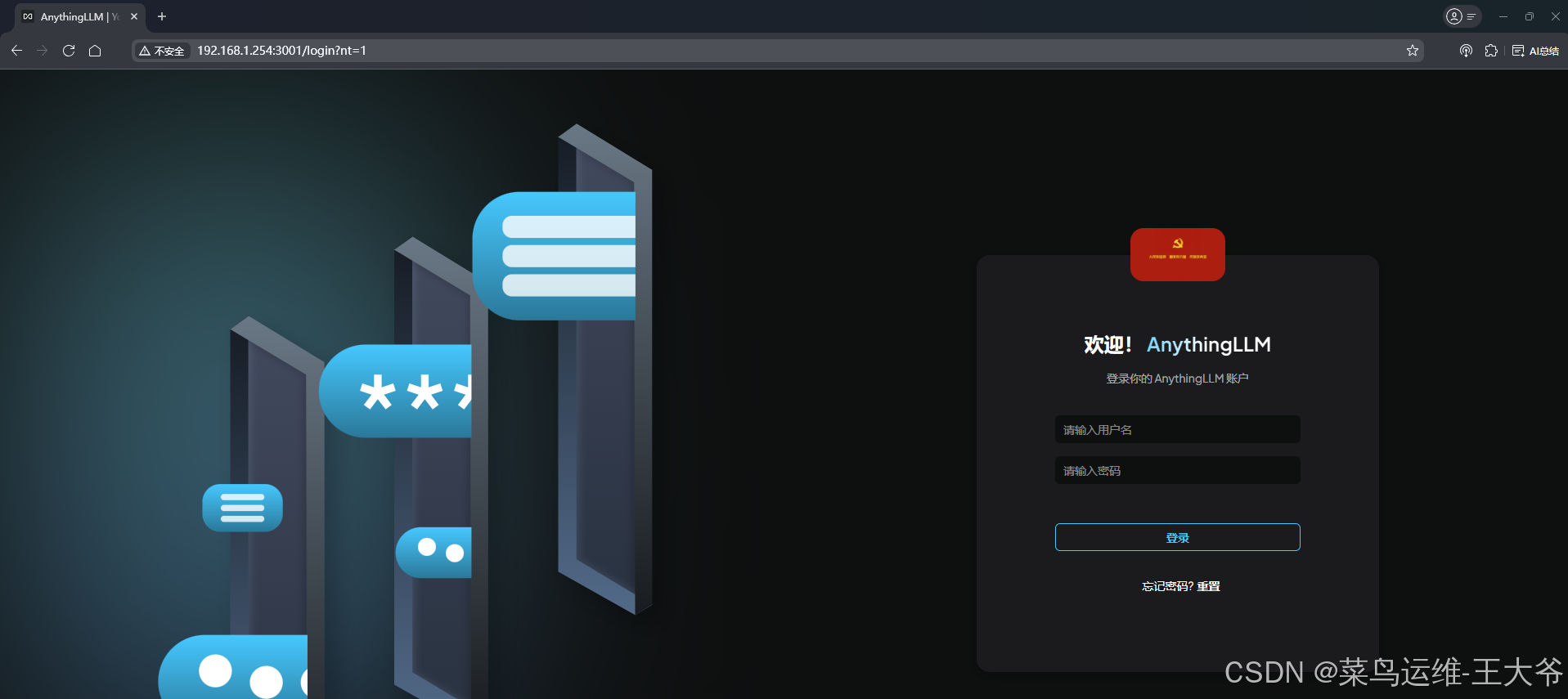
- 选择模型
这个需要ollama已经下载了相关模型,才能选择对应的模型文件。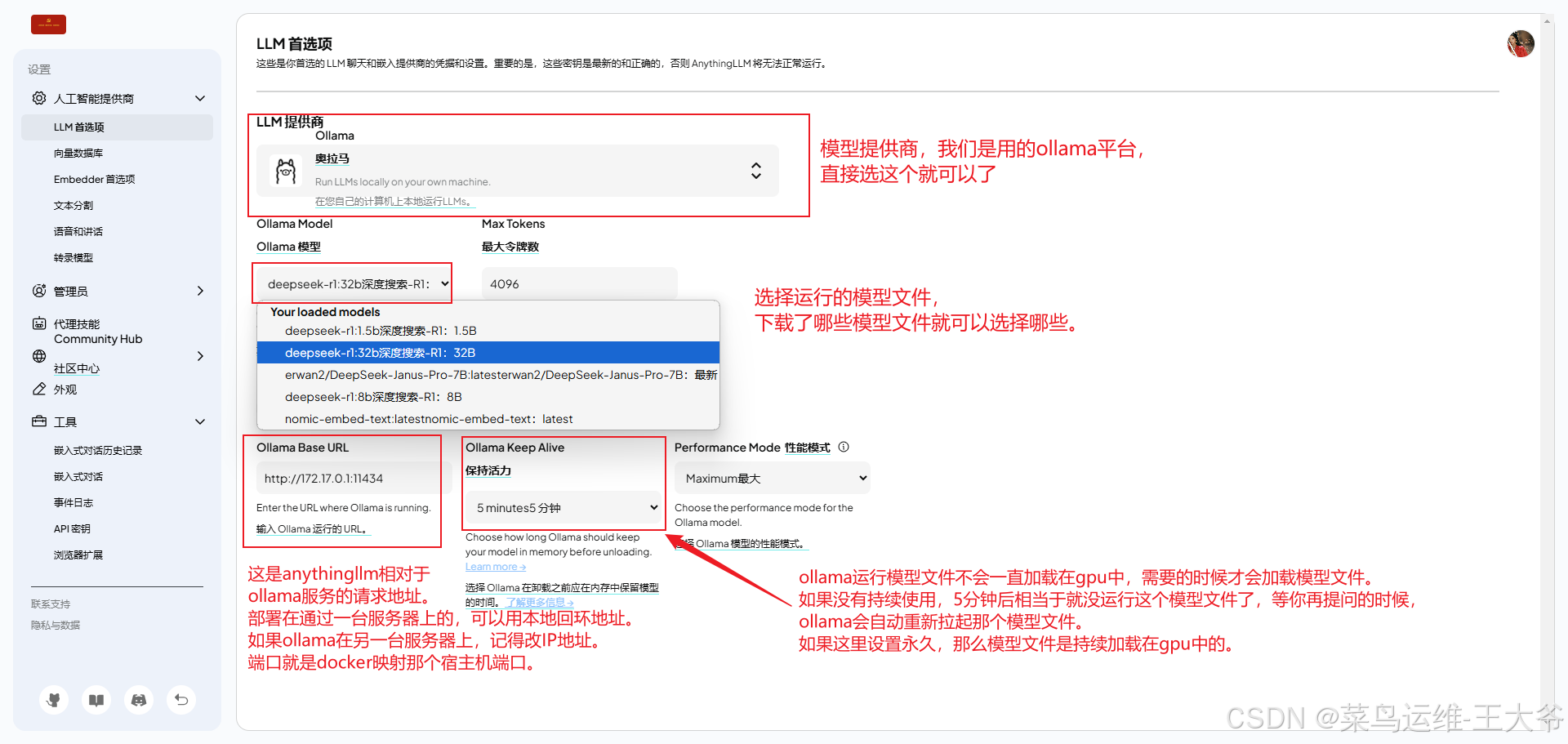
给它上传一个文件,然后问它一个问题。
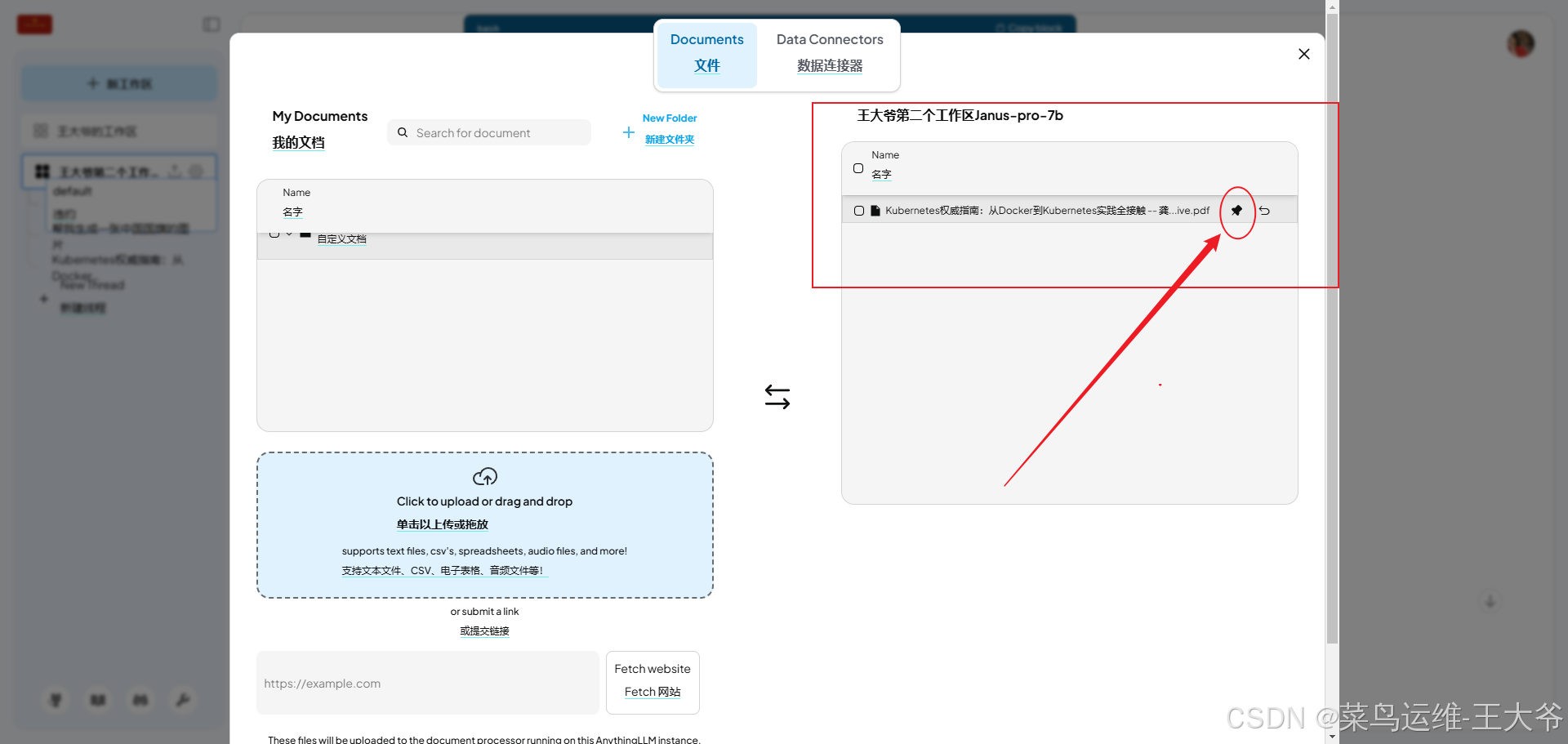
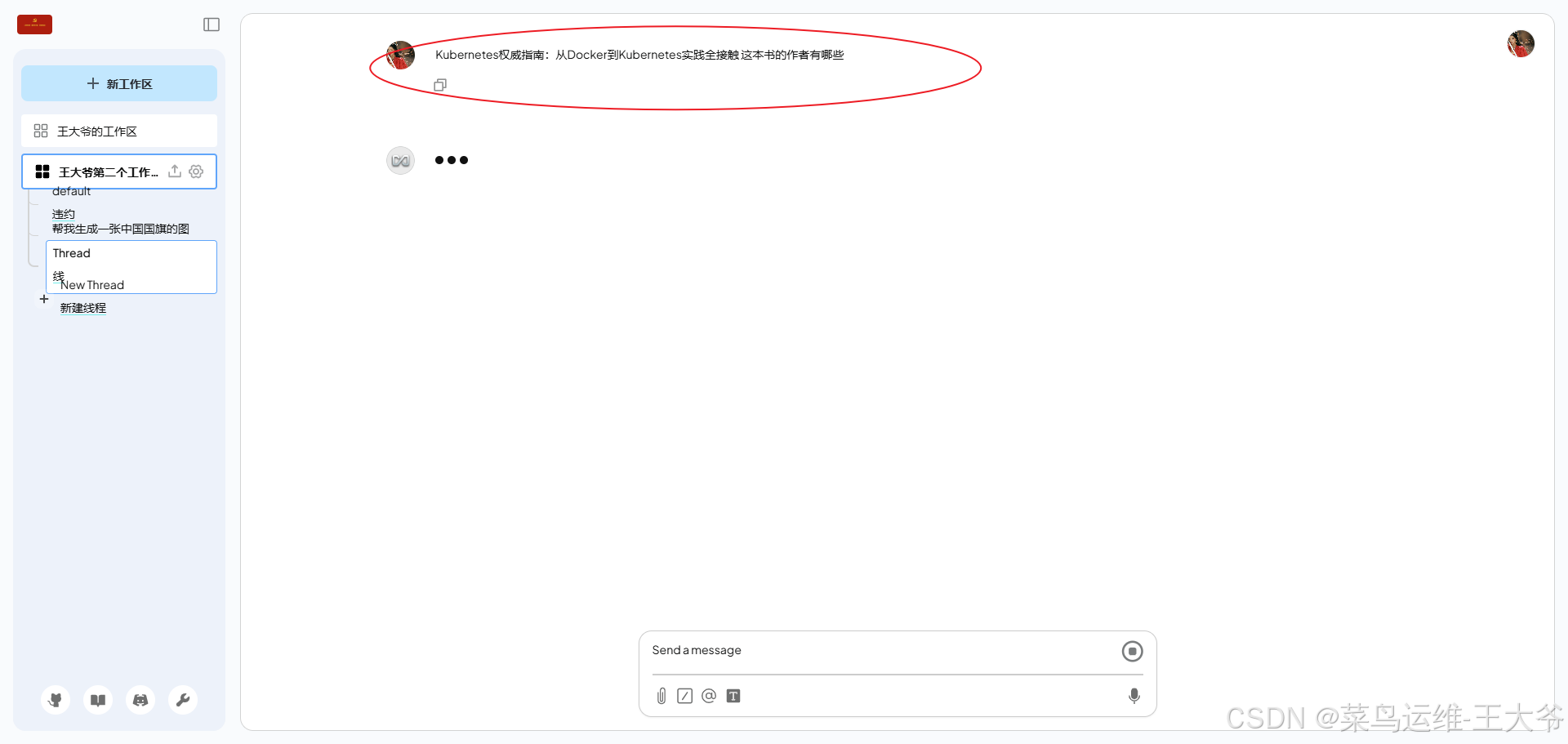
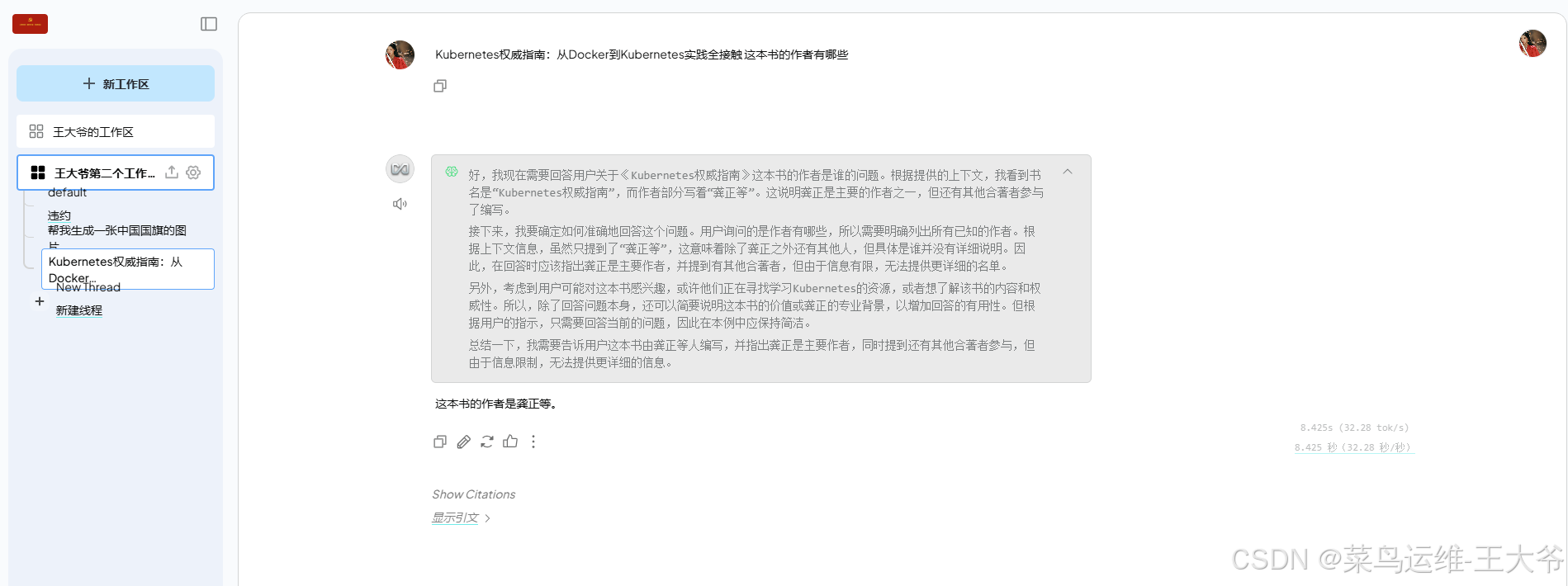
可以看到32b参数模型运行需要的显存空间是20G左右。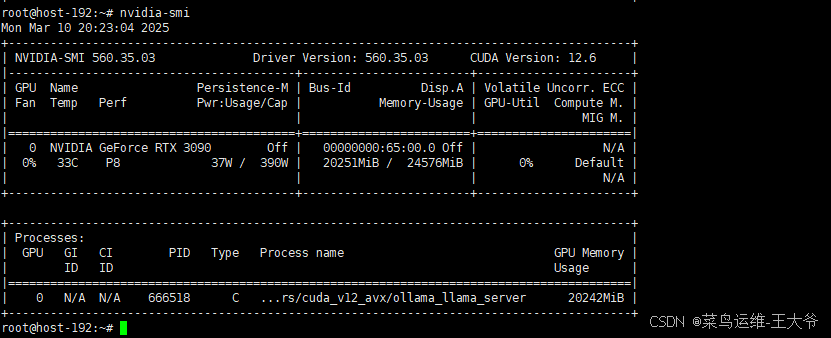
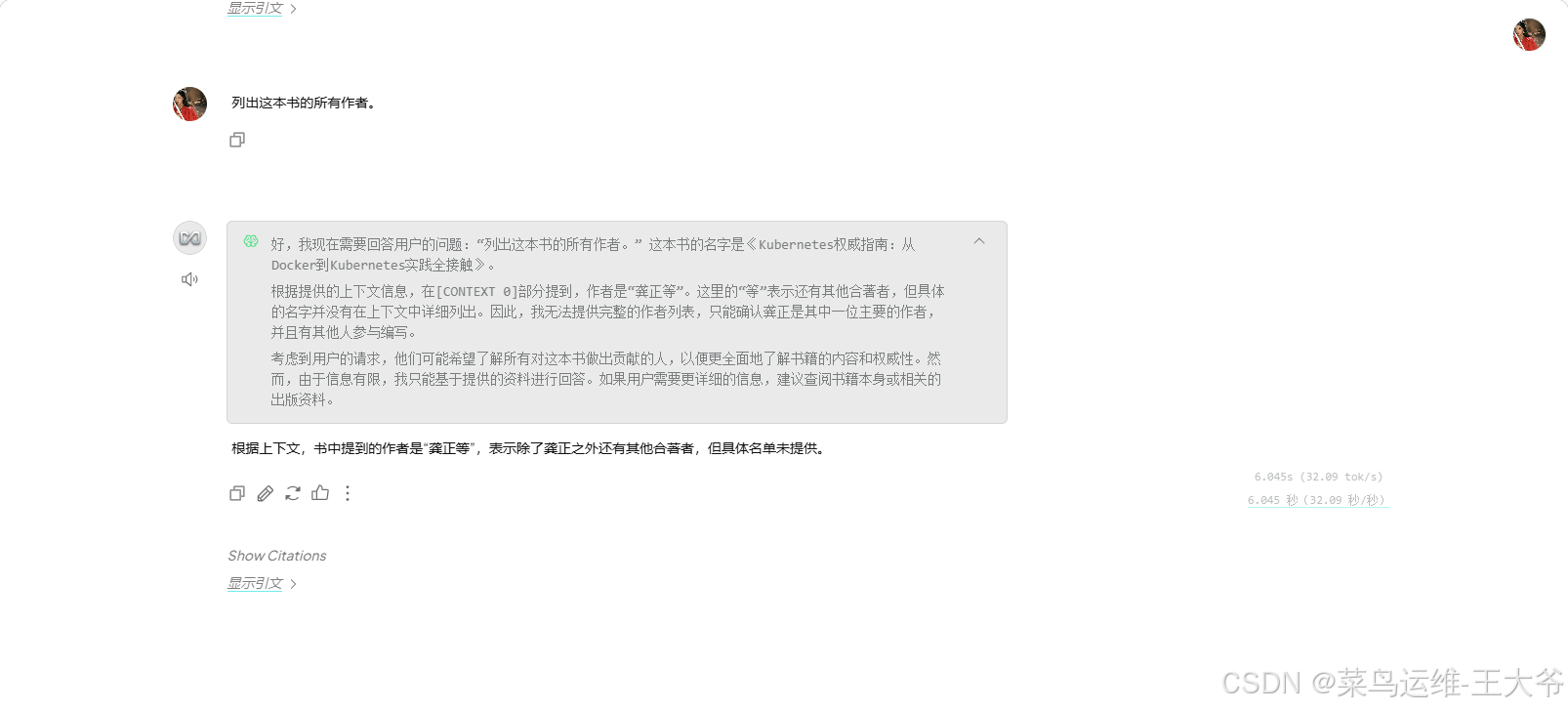
看来它还是没认到这个图片的内容。
- 再次提问


- 过一会,gpu中的模型文件就没有了。
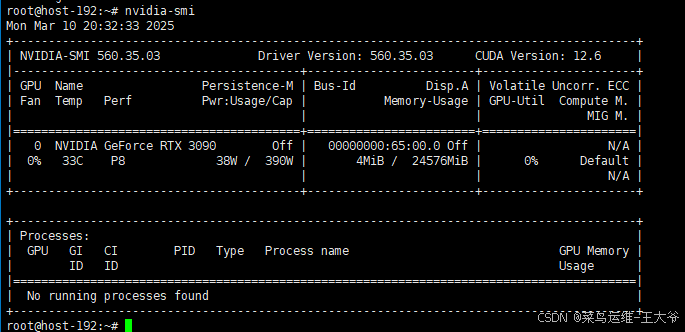
由此可见,anythingLLM对于pdf这种文档的处理还有一定的困难,比如pdf里面的图片中的内容,就没解析到。不过万能的网友已经有了解决方案,读者可以搜索学习。
主要就是要让大模型认识你给的内容。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 22
22 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)