腾讯云大模型知识引擎与DeepSeek-R1:企业智能问答平台的构建实践
腾讯云大模型知识引擎(LKE)是面向企业客户的基于大语言模型的应用构建平台,提供多种应用开发方式,完成企业级Agent、RAG、工作流应用创建及发布。该平台支持企业将专属知识与大模型能力相结合,降低模型应用落地门槛,使企业能够高效打造效果佳、有价值的大模型应用。高效搭建大模型应用:提供多种应用开发方式,预置优质官方插件复杂知识处理能力强:使用OCR、LLM+RAG、MLLM等多种技术能力进行文档解
引言
随着人工智能技术的迅猛发展,大型语言模型已成为企业数字化转型的重要工具。腾讯云大模型知识引擎(LLM Knowledge Engine,简称LKE)作为面向企业客户及合作伙伴的知识应用构建平台,结合企业专属数据,能够高效构建知识问答等应用。而DeepSeek作为国内领先的大语言模型,以其卓越的表现在众多场景展现出巨大的应用潜力。本文将深入探讨如何利用腾讯云大模型知识引擎与DeepSeek-R1模型,为企业构建高效、精准的智能问答平台。
一、大模型知识引擎与DeepSeek技术概述
1.1 腾讯云大模型知识引擎简介
腾讯云大模型知识引擎(LKE)是面向企业客户的基于大语言模型的应用构建平台,提供多种应用开发方式,完成企业级Agent、RAG、工作流应用创建及发布。该平台支持企业将专属知识与大模型能力相结合,降低模型应用落地门槛,使企业能够高效打造效果佳、有价值的大模型应用。
LKE平台具有以下核心优势:
- 高效搭建大模型应用:提供多种应用开发方式,预置优质官方插件
- 复杂知识处理能力强:使用OCR、LLM+RAG、MLLM等多种技术能力进行文档解析
- 配套工具链完善:开放模型配置、知识配置、问答提取、应用评测等配置工具
1.2 DeepSeek-R1模型系列介绍
DeepSeek是由深度求索公司推出的大语言模型系列,主要包括以下几类:
- DeepSeek-V3:在14.8万亿高质量token上完成预训练的混合专家(MoE)语言模型,拥有6710亿参数。作为通用大语言模型,在知识问答、内容生成、智能客服等领域表现出色。
- DeepSeek-R1:基于DeepSeek-V3-Base训练生成的高性能推理模型,在数学、代码生成和逻辑推断等复杂推理任务上表现优异,参数量同样达到6710亿。
- DeepSeek-R1-Distill:使用DeepSeek-R1生成的样本对开源模型进行有监督微调(SFT)得到的蒸馏模型。包括多个不同规模的版本(1.5B、7B、8B、14B、32B、70B),具有更小的参数规模和更低的推理成本。
DeepSeek-R1各个版本的参数量对比及能力差异如下:
|
模型版本 |
参数量 |
主要特点 |
|---|---|---|
|
DeepSeek-R1-Distill-Qwen-1.5B |
1.5B |
基础文本处理任务优化,最低硬件资源需求 |
|
DeepSeek-R1-Distill-Qwen-7B |
7B |
多领域应用支持,逻辑推理能力提升200% |
|
DeepSeek-R1-Distill-Llama-8B |
8B |
长上下文对话生成(128K tokens),对话连贯性增强 |
|
DeepSeek-R1-Distill-Qwen-14B |
14B |
文本生成质量达SOTA水平,复杂语义理解能力提升 |
|
DeepSeek-R1-Distill-Qwen-32B |
32B |
支持数学证明/法律文书等复杂推理任务,多模态扩展接口 |
|
DeepSeek-R1-Distill-Llama-70B |
70B |
人类水平语义理解(HSS 89.7),支持专业领域知识图谱融合 |
|
DeepSeek-R1/V3 |
671B |
万亿级token训练,支持超复杂系统建模,语境偏差率<0.17%(行业最低水平) |
二、基于腾讯云构建DeepSeek模型服务
为了构建企业级智能问答平台,首先需要部署可靠的DeepSeek模型服务。腾讯云提供了多种方式部署DeepSeek模型,主要包括以下几种方案:
2.1 腾讯云高性能应用服务HAI部署
HAI(High-performance AI)平台是腾讯云面向高性能计算与深度学习的综合解决方案,提供GPU/CPU资源调度、自动化部署以及运维监控等功能。使用HAI部署DeepSeek的主要优势在于稳定性高、扩展性好,特别适合企业长期运行的模型服务。
HAI部署DeepSeek的基本流程如下:
- 选择适合的计算资源,根据不同版本模型选择对应规格
- 一键部署模型,平台自动完成环境配置
- 通过API或WebUI接口访问模型服务
2.2 腾讯云TI-ONE训练平台部署
TI-ONE平台作为腾讯云的AI训练平台,也支持快速部署DeepSeek系列模型。TI平台已将DeepSeek模型内置在大模型广场中,用户可直接选择模型并一键部署。
TI-ONE平台部署DeepSeek的主要步骤:
- 在TI-ONE平台大模型广场中选择所需DeepSeek模型版本
- 选择算力资源(按量计费或包年包月)
- 一键部署,平台自动完成环境配置和模型加载
- 通过对话界面或API接口使用模型服务
对于不同规模的DeepSeek模型,所需的硬件资源也有显著差异:
- 小型模型(1.5B-8B):单卡A10即可支持推理服务
- 中型模型(14B-32B):需要16C以上CPU,至少1-2张高性能GPU卡
- 大型模型(70B):需要32C以上CPU,至少2张高性能GPU卡
- 超大型模型(671B):需要使用特殊HCCPNV6机型,并配置多节点分布式部署
2.3 模型部署效果对比
根据腾讯云文档中的实际测试,不同规模的DeepSeek模型在推理效果上存在明显差异。以一个测试案例为例:
问题:
> 在我的厨房里,有一张桌子,上面放着一个杯子,杯子里有一个球。我把杯子移到了卧室的床上,并将杯子倒过来。然后,我再次拿起杯子,移到了主房间。现在,球在哪里?
- DeepSeek-R1-Distill-Qwen-1.5B的回答认为球仍在杯中,没有正确理解杯子倒扣导致球掉出的物理过程。
- DeepSeek-R1模型(671B)正确推理出了杯子倒扣时球会掉出并留在床上,展现了更强的物理常识推理能力。
这一对比充分说明,虽然小型蒸馏模型在部署成本和响应速度上具有优势,但在处理复杂推理任务时,大型模型的表现明显更为出色。企业在选择模型时,需要根据应用场景和预算进行权衡。
三、知识引擎LKE与DeepSeek的融合应用
将DeepSeek模型与腾讯云大模型知识引擎结合,可以构建强大的企业智能问答平台。下面介绍构建过程的关键环节。
3.1 知识库构建流程
企业智能问答系统的核心是构建专业领域知识库,主要步骤包括:
- 知识收集与整理:收集企业内部文档、产品手册、业务流程等资料
- 文档预处理:使用OCR技术处理非结构化文档,提取有效文本内容
- 知识分块:将长文档拆分为合适大小的知识块,便于检索与匹配
- 向量化存储:使用DeepSeek模型对知识块进行向量化,构建高效检索库
- 知识关联:建立知识点之间的关联关系,形成知识图谱
3.2 RAG检索增强系统设计
基于LKE平台的检索增强生成(RAG)系统是企业知识问答的核心组件,其设计架构如下:
- 查询理解:使用DeepSeek模型对用户问题进行解析和意图理解
- 知识检索:基于语义向量匹配,从知识库中检索相关内容
- 上下文组装:将检索到的知识与问题组合成合适的Prompt
- 答案生成:由DeepSeek模型基于检索内容生成精确答案
- 答案评估:通过自动化评估机制判断答案质量,必要时请求人工干预
3.3 多轮对话与记忆机制
在企业问答场景中,多轮对话能力至关重要。结合DeepSeek与LKE可以实现:
- 对话上下文管理:维护用户会话状态,保持对话连贯性
- 动态知识加载:根据对话进展动态调整检索的知识范围
- 交互式澄清:当问题不明确时,通过主动提问引导用户明确需求
- 个性化记忆:记录用户偏好和常用信息,提供个性化服务体验
四、企业应用场景与实践案例
腾讯云大模型知识引擎与DeepSeek的结合可应用于多种企业场景,下面介绍几个典型案例。
4.1 智能客服系统
智能客服是大模型最广泛的应用场景之一。基于腾讯云LKE与DeepSeek构建的智能客服系统具有以下特点:
- 全面知识覆盖:整合产品手册、常见问题、解决方案等内容
- 多轮对话能力:支持复杂问题的拆解与持续探讨
- 业务流程集成:可对接订单系统、CRM系统等企业内部系统
- 情感理解与回应:识别用户情绪,提供更人性化的服务体验
系统架构图示:
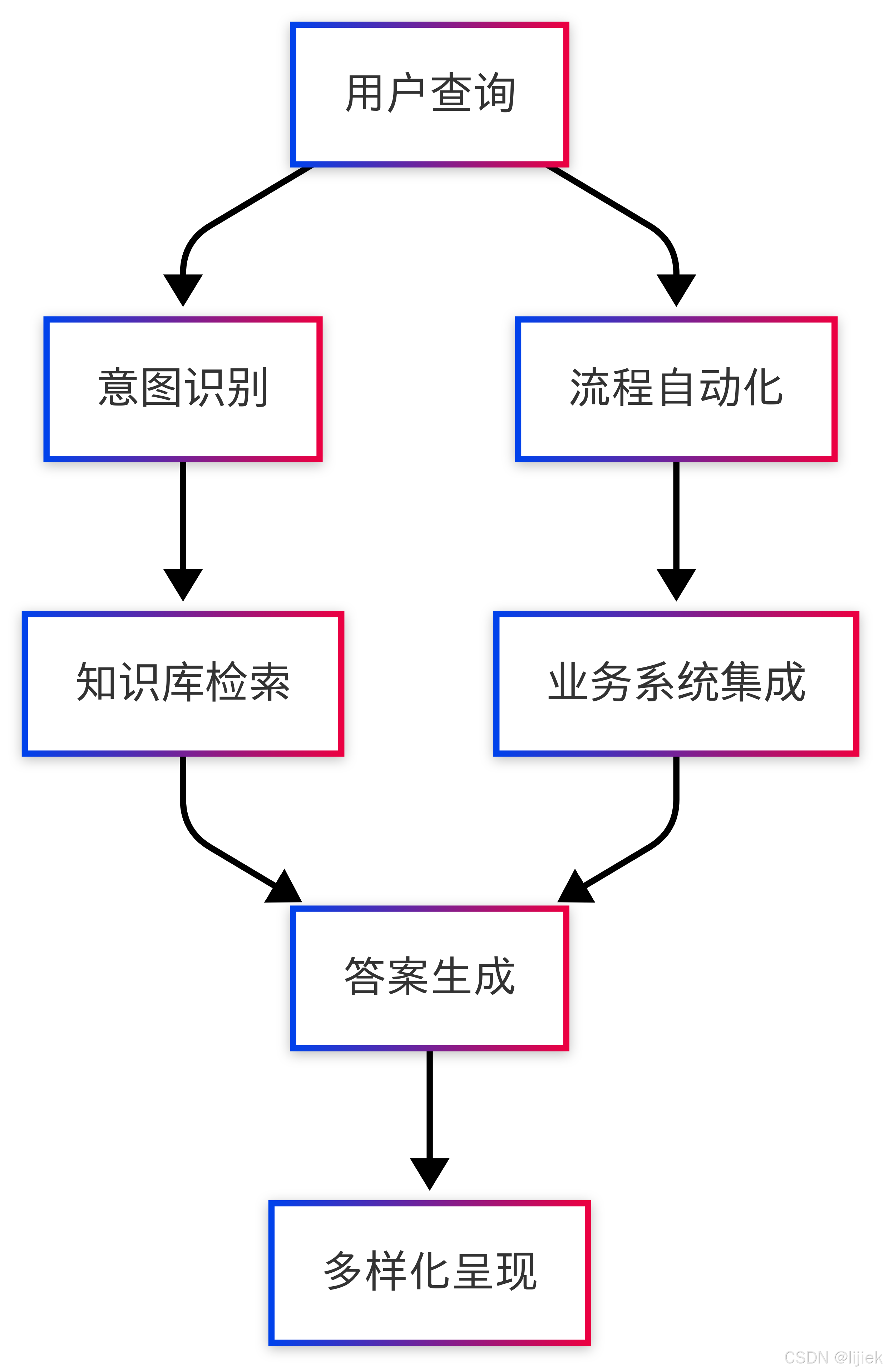
系统架构图
4.2 企业内部知识库助手
企业内部知识管理是另一个重要应用场景,可以帮助员工快速获取所需信息:
- 文档智能检索:从海量内部文档中精准定位所需信息
- 技术知识问答:解答研发、技术实施等专业问题
- 流程指导:提供企业各类业务流程的操作指南
- 培训辅助:作为新员工培训的智能辅导工具
4.3 垂直行业专业问答
针对金融、医疗、法律等专业领域,结合DeepSeek的强大推理能力,可构建专业知识问答系统:
- 金融领域:投资咨询、风险分析、监管合规解读
- 医疗健康:疾病咨询、用药指导、健康管理建议
- 法律服务:法规解读、案例分析、合同审核建议
五、系统优化与持续迭代
企业智能问答平台的构建不是一蹴而就的,需要持续优化与迭代。
5.1 模型性能优化
为提升系统响应速度和资源利用效率,可采取以下措施:
- 模型量化:对DeepSeek模型进行INT8/INT4量化,减少资源消耗
- 模型蒸馏:针对特定领域训练小型专用模型,提高推理效率
- 并行服务:实现多实例负载均衡,提高系统处理能力
- 缓存机制:对高频问题答案进行缓存,减少重复计算
5.2 知识库持续更新机制
知识库的实时性直接影响问答质量,应建立完善的更新机制:
- 自动爬取更新:定期从企业内部系统抓取最新知识
- 人工审核流程:关键知识点变更需经专业人员审核
- 反馈优化闭环:根据用户反馈,持续优化知识内容
- 知识时效管理:为知识设置有效期,自动提醒更新
5.3 评估与反馈体系
建立科学的评估体系对系统持续优化至关重要:
- 自动化评估:通过设计测试集,定期评估系统表现
- 用户反馈收集:在回答后提供评分和反馈渠道
- 错误分析:对常见错误建立分类,针对性优化
- A/B测试:对重要功能更新进行对比测试,验证效果
六、部署与安全合规
企业级应用必须关注部署便捷性与安全合规。
6.1 灵活部署选项
腾讯云提供多种部署方式以满足不同企业需求:
- 公有云部署:通过腾讯云HAI或TI-ONE平台快速部署,无需基础设施维护
- 私有化部署:支持在企业内部数据中心部署,保障数据安全
- 混合云方案:关键模块内部部署,通用能力使用云服务
- 容器化部署:支持Kubernetes编排,灵活伸缩
6.2 数据安全与隐私保护
在处理企业敏感数据时,安全与隐私保护是首要考虑因素:
- 数据隔离:确保企业数据与其他用户完全隔离
- 传输加密:所有数据传输采用TLS加密
- 访问控制:基于角色的精细化权限管理
- 隐私计算:支持联邦学习等隐私保护技术
- 数据留存控制:支持定期清理和销毁临时数据
6.3 合规认证与审计
满足行业合规要求是企业应用的基础保障:
- 合规认证:符合ISO27001、SOC2等安全标准
- 操作审计:记录所有关键操作,支持事后追溯
- 风险评估:定期开展安全风险评估
- 应急响应:建立完善的安全事件响应机制
七、总结与展望
腾讯云大模型知识引擎与DeepSeek的结合,为企业智能问答平台构建提供了强大支持。通过整合企业专属知识与先进的大语言模型,企业可以构建高效、精准的知识服务系统,提升信息流通效率,增强决策支持能力。
未来,随着模型技术的持续进步和应用经验的积累,企业智能问答平台将向以下方向发展:
- 多模态理解:融合文本、图像、音频等多种信息,提供更全面的知识服务
- 主动学习能力:系统能够主动发现知识盲点,引导补充相关知识
- 个性化定制:根据不同用户角色和场景,提供差异化的知识服务
- 跨系统协同:与企业各业务系统深度集成,形成统一的智能决策支持平台
通过腾讯云大模型知识引擎与DeepSeek的创新结合,企业可以加速实现知识管理的数字化转型,打造更具竞争力的智能企业形态。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐
 15
15 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)