【AI论文】START:具备工具使用的自学推理者
像OpenAI-o1和DeepSeek-R1这样的大型推理模型(LRMs)通过利用长的思维链(CoT)在复杂推理任务中展现出了非凡的能力。然而,这些模型仅依赖内部推理过程,因此常常受到幻觉和不高效问题的困扰。在本文中,我们介绍了START(具备工具使用的自学推理者),这是一种新型的工具集成式长思维链推理大语言模型(LLM),它通过利用外部工具显著增强了推理能力。通过代码执行,START能够执行复杂
摘要:像OpenAI-o1和DeepSeek-R1这样的大型推理模型(LRMs)通过利用长的思维链(CoT)在复杂推理任务中展现出了非凡的能力。然而,这些模型仅依赖内部推理过程,因此常常受到幻觉和不高效问题的困扰。在本文中,我们介绍了START(具备工具使用的自学推理者),这是一种新型的工具集成式长思维链推理大语言模型(LLM),它通过利用外部工具显著增强了推理能力。通过代码执行,START能够执行复杂计算、自我检查、探索多种方法以及自我调试,从而克服了LRMs的局限性。START的核心创新在于其自学框架,该框架包含两项关键技术:1)提示推理(Hint-infer):我们证明,在LRM的推理过程中插入人为设计的提示(例如,“等等,也许在这里使用Python是个好主意。”)能够有效地激发其利用外部工具的能力,而无需任何演示数据。提示推理还可以作为一种简单有效的顺序测试时扩展方法;2)提示拒绝采样微调(Hint-RFT):Hint-RFT将提示推理和拒绝采样微调(RFT)相结合,通过对LRM通过提示推理生成的包含工具调用的推理轨迹进行评分、过滤和修改,然后对LRM进行微调。通过这个框架,我们对QwQ-32B模型进行了微调,从而得到了START。在博士级别的科学问答(GPQA)、竞赛级别的数学基准测试(AMC23、AIME24、AIME25)以及竞赛级别的代码基准测试(LiveCodeBench)上,START分别取得了63.6%、95.0%、66.7%、47.1%和47.3%的准确率。它显著优于基础的QwQ-32B模型,并且性能与最先进的开源模型R1-Distill-Qwen-32B和专有模型o1-Preview相当。Huggingface链接:Paper page,论文链接:2503.04625
研究背景和目的
研究背景
随着大型语言模型(LLMs)的发展,复杂推理任务的能力得到了显著提升。特别是利用长链思维(Long Chain-of-Thought, Long CoT)方法,模型能够通过显式的中间推理步骤来分解问题,从而在数学、科学和编程等多个领域表现出色。然而,现有的Long CoT方法严重依赖于模型内部的推理机制,这导致在面对复杂计算或模拟任务时,模型容易产生幻觉(hallucinations)且效率低下。尽管一些先进的模型如OpenAI-o1和DeepSeek-R1通过强化学习展示了新的范式,如自我优化、自我反思和多策略探索等,但根本性的局限依然存在。例如,这些模型在处理需要复杂计算的问题时,往往因为仅依赖内部推理而产生错误。
工具集成推理(Tool-integrated Reasoning, TIR)是另一种改进传统CoT的方法,它通过调用外部工具(如代码解释器)来有效缓解Long CoT中的一些问题。OpenAI-o1报告了他们训练模型使用外部工具的经验,特别是在安全环境中编写和执行代码,但并未提供具体的技术细节。因此,如何协同结合Long CoT与TIR成为一个重要且直接的问题。
研究目的
本研究旨在提出一种新颖的工具集成长链思维推理模型START(Self-Taught Reasoner with Tools),通过整合外部工具显著提升模型的推理能力。START模型的核心创新在于其自学习框架,该框架包含两项关键技术:Hint-infer和Hint Rejection Sampling Fine-Tuning(Hint-RFT)。通过这两项技术,START能够在推理过程中有效利用外部工具,解决Long CoT方法中的局限性,从而在复杂推理任务中表现出色。
研究方法
数据准备
训练数据由两部分组成:数学数据和代码数据。数学数据来源于AIME问题集(2024年之前)、MATH数据集和Numina-MATH数据集,共包含40K个数学问题。代码数据来源于Codeforces、代码竞赛和LiveCodeBench(2024年7月之前),共包含10K个代码问题。为确保训练集不会泄露测试数据,采用了与Yang et al. (2024)相同的去污染方法。
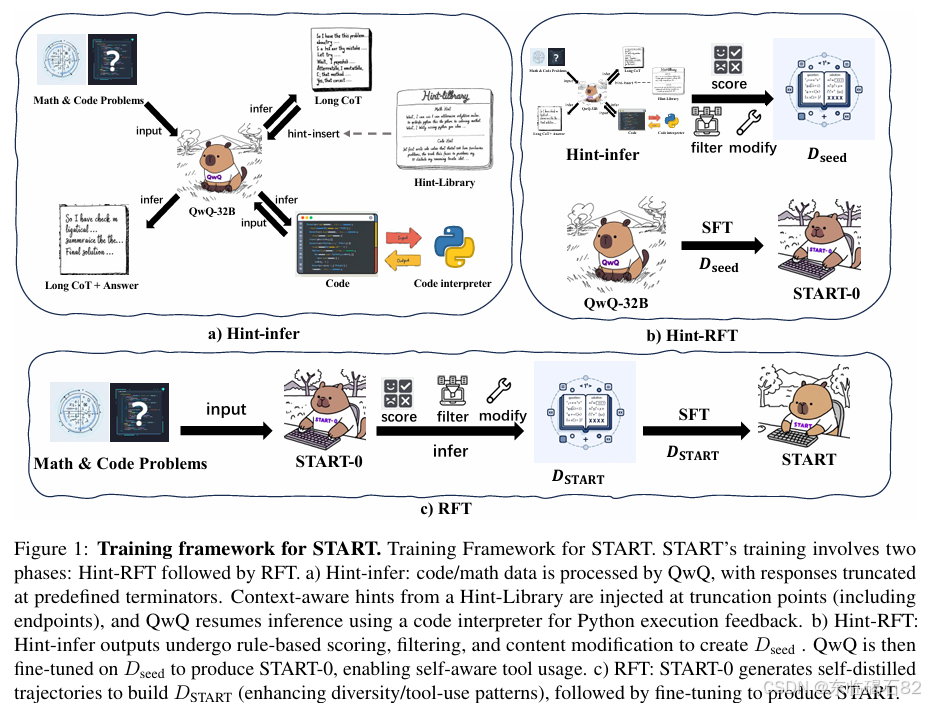
Hint-RFT
Hint-RFT框架包含两个主要步骤:Hint-infer和基于提示的拒绝采样微调(Hint-RFT)。
-
Hint-Library设计:基于LLMs的认知特性,设计了一系列针对不同场景的提示(Hints),这些提示旨在引导模型采用不同的策略。对于数学推理,设计了针对反思、逻辑验证、探索新方法的提示;对于编码任务,则侧重于设计促进模型自我调试能力的提示。
-
Hint-infer:在推理过程中,将提示随机插入到特定的连词之后(如“Alternatively”和“Wait”),或在Long CoT的停止标记之前。这些提示鼓励模型探索更广泛的推理空间,并在需要时调用外部工具(如Python解释器)进行复杂计算和自我调试。
-
数据处理和模型微调:采用主动学习方法,使用QwQ对所有训练数据进行贪婪推理和提示推理,召回那些在没有工具帮助下无法成功但在提示推理下成功的推理任务。这些数据被纳入启动数据集D_seed,用于微调QwQ得到START-0。
RFT
为进一步增强训练数据的多样性和数量,使用START-0对所有训练数据进行拒绝采样微调(RFT)。通过采样参数(temperature=0.6, top-p=0.95)进行多轮采样,对生成的推理轨迹进行评分、过滤和修改,得到数据集D_START。使用D_START中的数据再次微调QwQ,最终得到START模型。
研究结果
主要基准测试结果
在多个具有挑战性的推理任务基准上评估了START模型,包括博士级别的科学问答(GPQA)、数学基准(AMC23、AIME24、AIME25)和代码基准(LiveCodeBench)。结果显示,START在所有这些基准上均显著优于基线模型QwQ,并在某些任务上达到了与最先进的开源模型相当的性能。
-
GPQA:START在物理学领域表现出色,达到80.0%的准确率,超过了QwQ的73.8%和Search-o1的77.9%。在化学和生物学领域,START也取得了与顶尖模型相当的性能。
-
数学基准:START在MATH500、AMC23、AIME24和AIME25上分别取得了94.4%、95.0%、66.7%和47.1%的准确率,相比QwQ有显著提升。特别是在AMC23和AIME24上,START的准确率分别提高了15.0%和16.7%。
-
LiveCodeBench:在代码基准上,START通过集成调试工具的能力,相比QwQ在准确率上提高了5.9%。特别是在中等难度的问题上,START的准确率从QwQ的46.0%提高到84.6%。
Hint-infer的有效性
通过Hint-RFT,我们发现QwQ本身具备调用工具的能力,但这种能力很难仅通过提示触发,而需要明确的提示来激活。START通过Hint-RFT显著增强了QwQ的工具调用能力,证明了微调在解锁模型潜在能力方面的有效性。此外,Hint-infer作为一种简单而有效的测试时扩展方法,通过多次在推理过程结束前插入提示,可以同时增加模型的思考时间和准确率。
研究局限
尽管START模型在多个基准上取得了显著成果,但仍存在一些局限性:
-
工具种类有限:本研究仅关注Python解释器的集成,未探索其他外部工具(如搜索引擎、专业库或不同计算资源)的潜力。未来工作可以探索如何集成更多样化的工具集,以提高模型在不同领域的推理能力和通用性。
-
提示设计的局限性:手动设计提示可能会无意中打断模型原有的推理流程。尽管我们尝试在推理过程中的关键节点插入提示以优化性能,但提示的有效性和位置可能因具体任务或上下文而异。未来需要更精细的标准来确定最有效的提示类型和位置。
-
基准测试的局限性:本研究在有限的一组基准上进行了评估,虽然结果展示了有前景的成果,但模型性能在更广泛和更多样化的数据集上的泛化能力仍有待验证。START的性能可能对任务复杂性、领域特异性和输入数据的特性敏感。
-
技术滥用风险:模型生成代码或提出问题解决策略的能力可能被滥用于恶意目的,如制造虚假信息或自动化有害任务。因此,必须实施保障措施并建立道德准则来监控和减轻这些风险。
未来研究方向
-
多样化工具集成:探索将更多种类的外部工具集成到模型中,如搜索引擎、特定领域的库和不同的计算资源。这将有助于提高模型在不同领域和任务上的推理能力和通用性。
-
智能提示生成:开发自动或智能的提示生成方法,以减少对手动设计提示的依赖。这种方法可以基于模型当前的推理状态和上下文动态生成提示,从而提高提示的有效性和适用性。
-
增强泛化能力:在更多样化和挑战性的基准上评估模型性能,以验证其在不同任务、领域和数据集上的泛化能力。此外,可以探索使用数据增强和迁移学习等技术来提高模型的泛化能力。
-
技术伦理与安全保障:建立严格的技术伦理准则和安全保障机制,以确保工具集成推理模型的安全、负责任地使用。这包括对模型输出的监控、对潜在滥用风险的评估和应对措施的制定。
-
与其他先进技术的结合:探索将START模型与其他先进技术(如强化学习、多模态推理等)相结合的可能性。这将有助于进一步提高模型的推理能力和应用范围。
通过解决这些局限性和探索未来研究方向,可以推动工具集成推理模型的发展,使其在更多复杂和高级的认知任务中发挥更大的作用。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 33
33 0
0- 0



 已为社区贡献76条内容
已为社区贡献76条内容

所有评论(0)