多台Macmini利用EXO搭建分布式AI集群提高deepseek -r1:14b推理能力方案分享(实测可用)
对比之下,一块RTX 4090显卡满载就要450瓦——这电费差距,长期运行成本得高多少!只要设备在网络中的某个位置连接,就可以用来运行模型,使用起来非常简单方便。这就好比把厨房和餐厅打通,厨师(GPU)和传菜员(CPU)再也不用跑来跑去,上菜速度直接翻倍!由图可以看到单台m4 mac的性能大约是28tokens/s,运算速度是8.52TFLOPS(每秒所执行的浮点运算次数)传统显卡(比如NVIDI
为什么用MacMini而不是Nvidia系列的卡?
统一内存:CPU和GPU的“共享充电宝”
传统显卡(比如NVIDIA RTX 4090)的显存最高只有24GB,而一台顶配Mac Mini能塞下64GB的统一内存——CPU和GPU共用同一块内存池,不用来回搬运数据。这就好比把厨房和餐厅打通,厨师(GPU)和传菜员(CPU)再也不用跑来跑去,上菜速度直接翻倍!
MLX框架
苹果在2023年推出了专为自家芯片优化的机器学习框架MLX,号称能榨干M系列芯片的每一滴性能。实测中,MLX跑Llama 3模型的生成速度比PyTorch快30%,甚至让Mac Mini单挑高端显卡也不虚!
功耗超级低:五台机器才用28瓦?
油管一博主实测发现,五台Mac Mini待机时总功耗仅28瓦,全速运行也才200瓦出头。对比之下,一块RTX 4090显卡满载就要450瓦——这电费差距,长期运行成本得高多少!!!
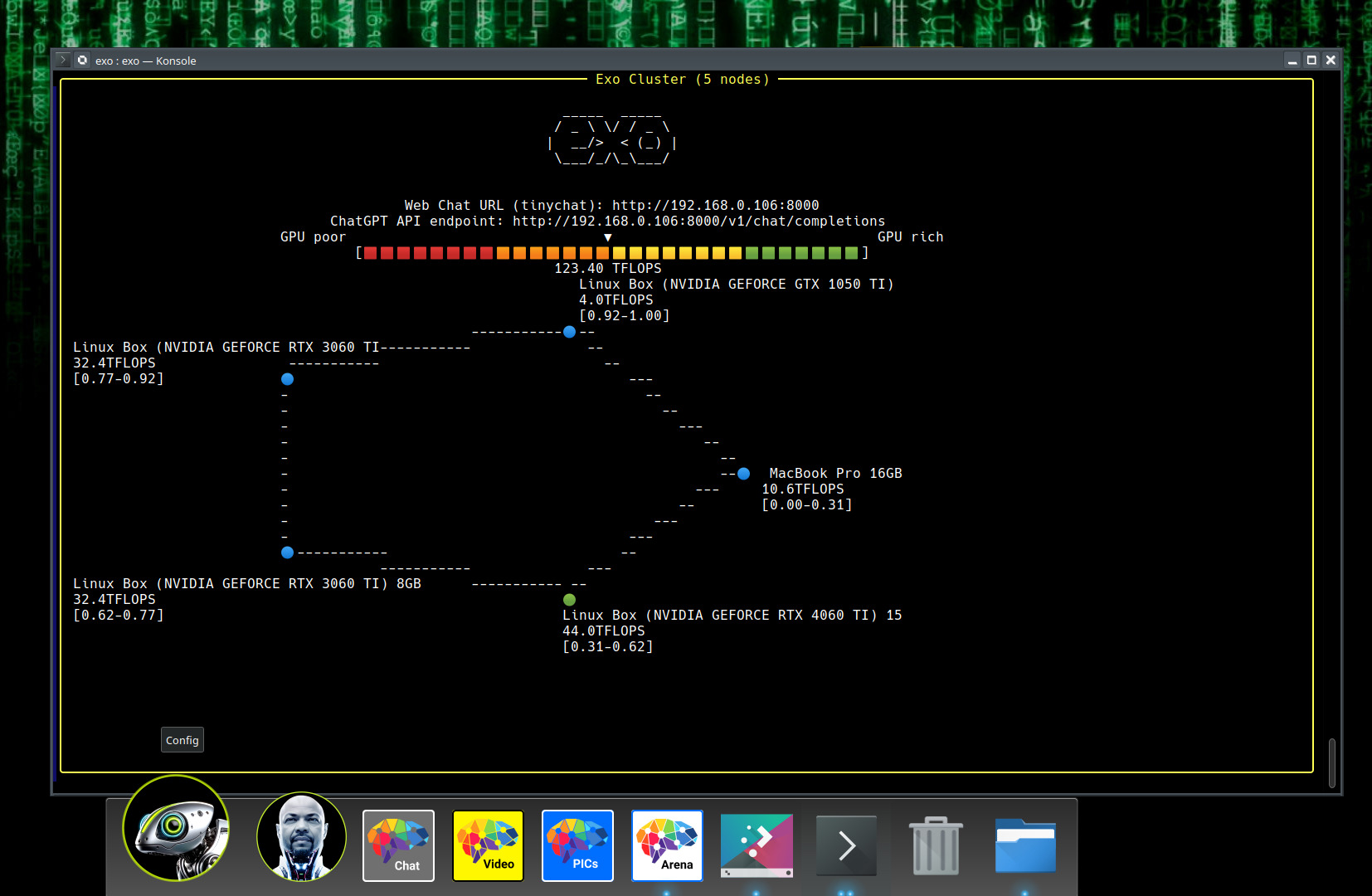
EXO基本原理
关键组件
- 分片管理:EXO 将 AI 模型划分为可管理的块。
- 智能分区:系统根据每个设备的能力找出分配任务的最佳方式。
- gRPC 通信:设备使用这种高速协议相互通信。
- 环形拓扑:数据以环形流动,每个设备在传递之前处理其部分。
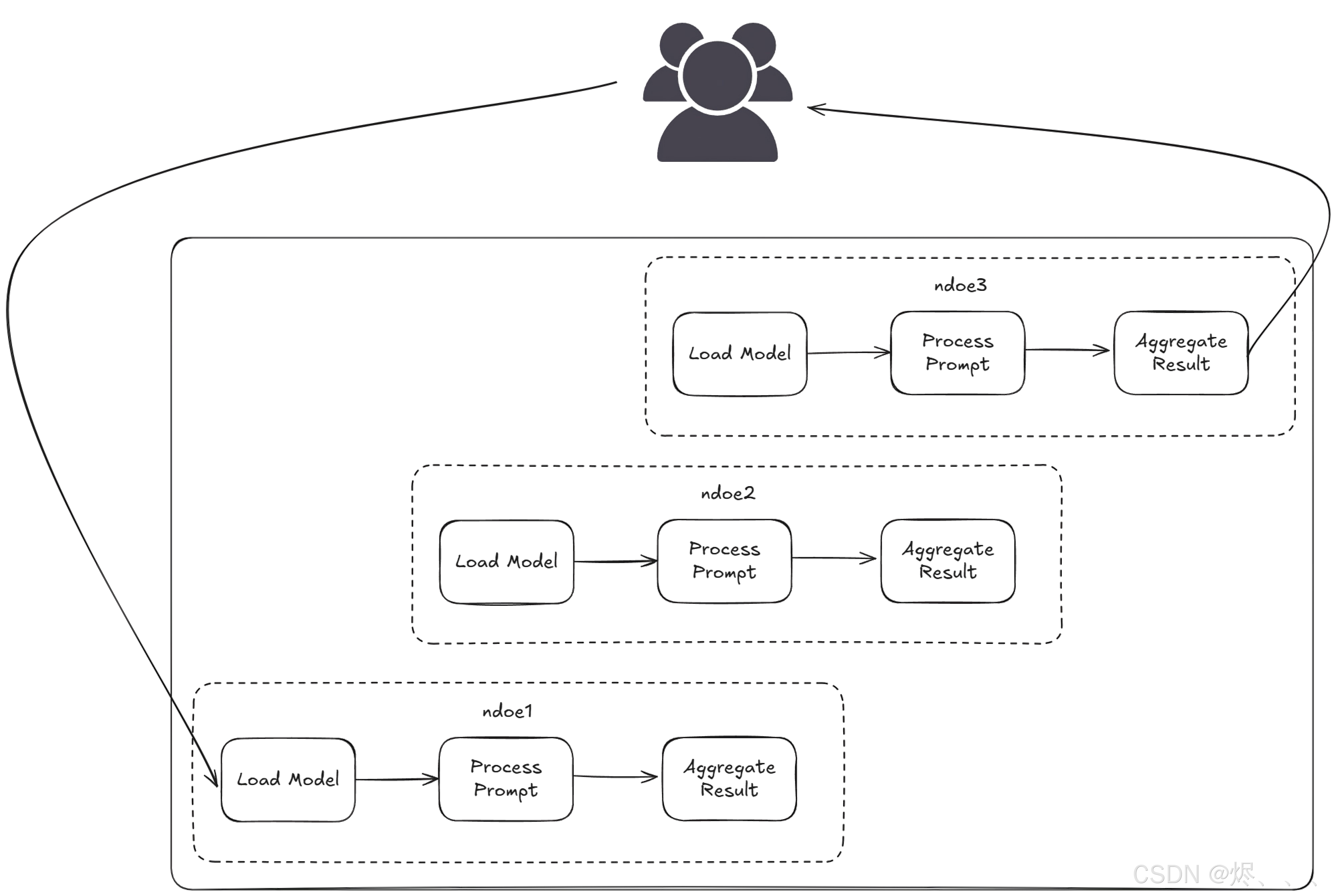
任务如何在网络中流动
- 您提问:向 EXO 网络发送提示。
- 任务分配:系统将您的请求分配到可用设备上。
- 处理:每个设备在模型的各自部分上工作。
- 结果汇编:一个设备收集所有部分并组装最终答案。
实践:M1 16g + M4 16g 利用EXO搭建AI集群
安装Python
如果您的本地电脑没有安装python,请去以下地址安装python
https://www.python.org/downloads/macos/
官方要求如下:
- Python>=3.12.0 是必需的,因为以前版本中的 asyncio 存在问题。
- 对于支持 NVIDIA GPU 的 Linux(仅限 Linux,如果不使用 Linux 或 NVIDIA,请跳过):
- NVIDIA 驱动程序 - 使用
nvidia-smi - CUDA 工具包 - 从 NVIDIA CUDA 指南安装,使用
nvcc --version - cuDNN 库 - 从 NVIDIA cuDNN 页面下载,按照以下步骤验证安装
我使用3.12.9测试是没有问题。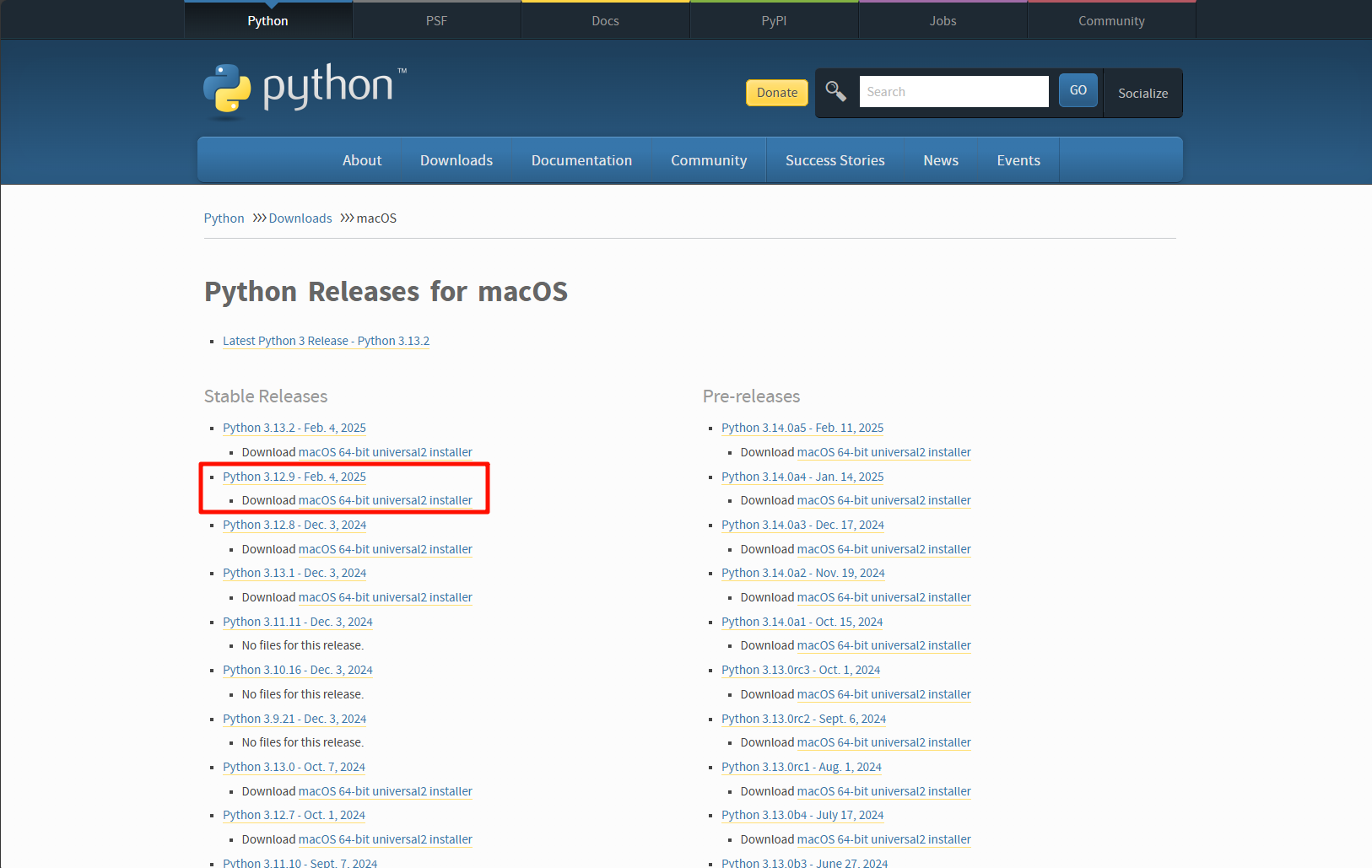
由于大部分包都是国外的,所以需要再配置一下镜像文件
- NVIDIA 驱动程序 - 使用
pip3 config set global.extra-index-url "https://pypi.tuna.tsinghua.edu.cn/simple https://mirrors.huaweicloud.com/repository/pypi/simple"
安装MLX
pip3 install mlx -i https://pypi.tuna.tsinghua.edu.cn/simple
安装使用EXO
安装项目和依赖
git clone https://github.com/exo-explore/exo.git
cd exo
pip3 install -e .
# alternatively, with venv
source install.sh
下载好之后可以直接拷贝到另一台电脑上,不需要再重复下载了。
多设备启动exo
设备1:
exo
设备2:
exo
与其他分布式推理框架不同,exo 不使用主从架构。相反,exo 设备以p2p(点对点)的方式连接。只要设备在网络中的某个位置连接,就可以用来运行模型,使用起来非常简单方便。
使用exo
exo 提供了一个与 ChatGPT 兼容的 API,以运行模型。只需在您的应用程序中进行一行更改即可使用 exo 在您自己的硬件上运行模型。例如:
curl http://localhost:52415/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "llama-3.2-3b",
"messages": [{"role": "user", "content": "What is the meaning of exo?"}],
"temperature": 0.7
}'
还可以用一个类似 ChatGPT 的 WebUI(由 tinygrad tinychat 提供支持)
http://localhost:52415
测试EXO
前提
设备清单:
- m1 macmini 16+256g
- m4 macmini 16+256g
- 一根千兆网线互联
测试环境: - ollama平台
- deepseek r1:14b模型
- 问题:蓝牙耳机坏了应该看牙科还是耳科?
单台主机性能
由图可以看到单台m4 mac的性能大约是28tokens/s,运算速度是8.52TFLOPS(每秒所执行的浮点运算次数)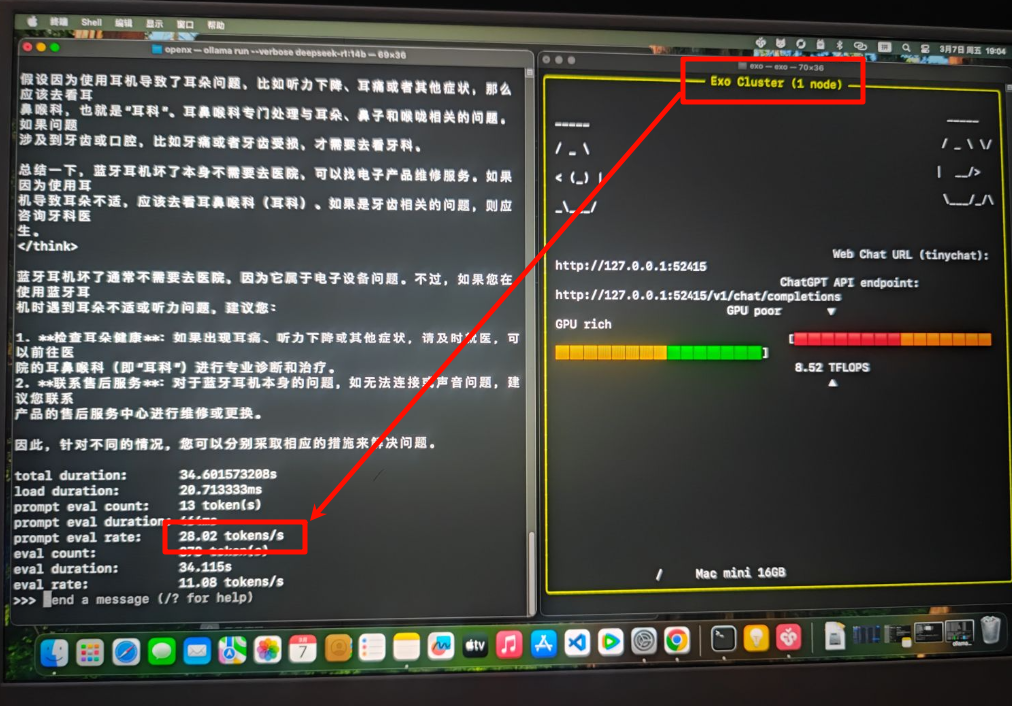
集群的性能
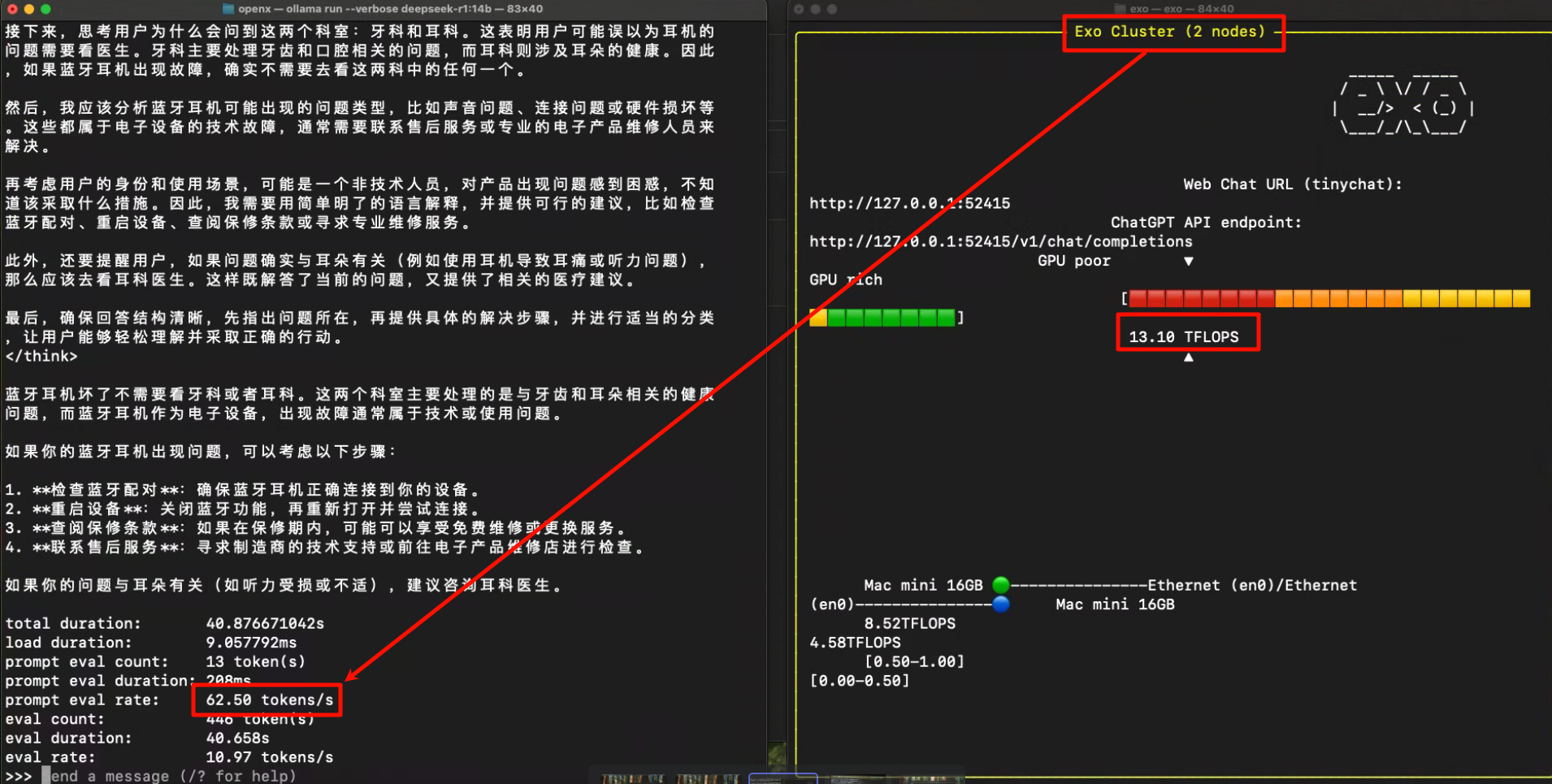
由图可以看到两台mac的性能大约是62.5tokens/s,运算速度是13.10TFLOPS(每秒所执行的浮点运算次数),由此可以得出一个基本结论:利用exo使两台mac互联,推理能力可以线性增加。
附件
项目源码及环境
通过网盘分享的文件:exo
链接: https://pan.baidu.com/s/1nKXngRRNhbo6tHnZu0GOHQ?pwd=9dc8
提取码: 9dc8
下面是实际应用的项目:
https://yiyongai.cn/
参考资料
https://github.com/exo-explore/exo?tab=readme-ov-file
https://github.com/ml-explore/mlx
https://www.youtube.com/watch?v=GBR6pHZ68Ho&t=2s

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)