阿里QwQ-32B震撼发布:小模型如何挑战DeepSeek-R1霸主地位?
国产AI的又一次突破!2025年3月6日凌晨,阿里云通义千问团队抛出一枚重磅炸弹——全新开源推理模型 QwQ-32B 正式亮相!这款仅有 320亿参数 的“小个子”,竟然在性能上直逼拥有 6710亿参数 的国产霸主 DeepSeek-R1 满血版。更令人惊讶的是,它还能在消费级显卡甚至苹果笔记本上跑起来!这不仅是一次技术的飞跃,更是国产AI从“大力出奇迹”向“精巧出智慧”转型的标志。QwQ-32B
国产AI的又一次突破!
2025年3月6日凌晨,阿里云通义千问团队抛出一枚重磅炸弹——全新开源推理模型 QwQ-32B 正式亮相!
这款仅有 320亿参数 的“小个子”,竟然在性能上直逼拥有 6710亿参数 的国产霸主 DeepSeek-R1 满血版。
更令人惊讶的是,它还能在消费级显卡甚至苹果笔记本上跑起来!
这不仅是一次技术的飞跃,更是国产AI从“大力出奇迹”向“精巧出智慧”转型的标志。

QwQ-32B:小身材,大智慧

QwQ-32B 是阿里通义千问团队的最新力作。
通过大规模强化学习(RL)和多阶段训练,这款模型在数学推理、编程任务和通用能力上实现了质的突破。
官方数据显示,其性能不仅能与 DeepSeek-R1 媲美,在某些测试中甚至略胜一筹。
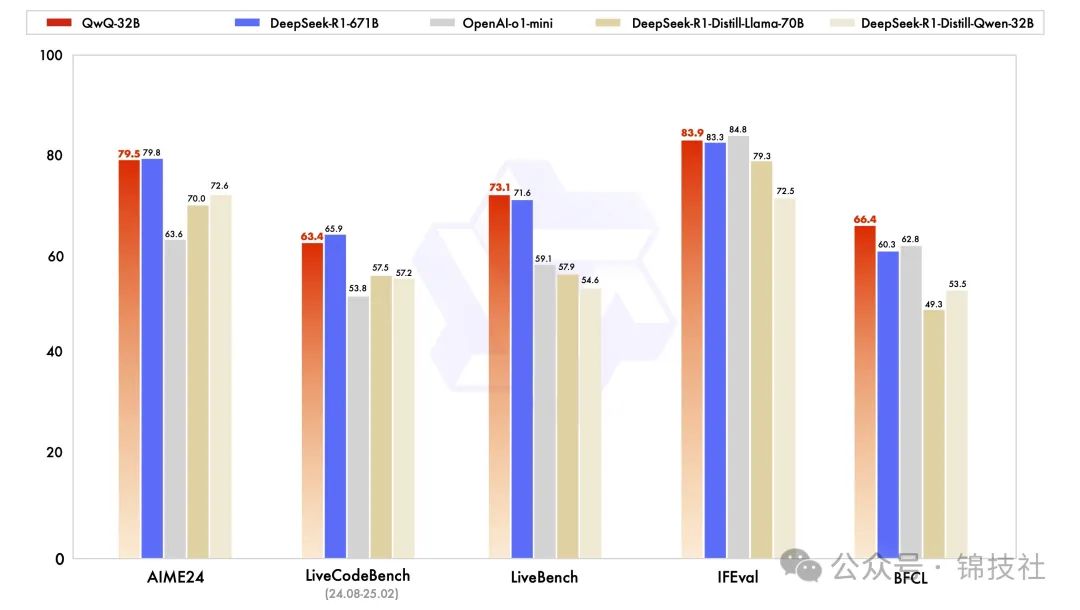
更重要的是,它集成了智能体(Agent)能力,可以在使用工具时进行批判性思考,并根据环境反馈动态调整推理过程。这种“边用边想”的特性,让 QwQ-32B 在动态交互场景中如鱼得水。
相比之下,QwQ-32B 的参数规模仅为 DeepSeek-R1 的 5%,部署成本却低到令人咋舌。
无论是个人开发者用 RTX 显卡,还是中小企业在本地服务器上运行,QwQ-32B 都能轻松驾驭。
阿里还贴心地采用了 Apache 2.0 协议 开源,任何人都可以免费下载商用,甚至通过官网直接体验。
Huggingface开源地址:
https://huggingface.co/Qwen/QwQ-32B
魔搭开源地址:
https://modelscope.cn/models/Qwen/QwQ-32B
通义千问(海外版)官网:
https://chat.qwen.ai
登录后点击左上角切换模型即可直接在线体验。
这波操作,简直是“技术平权”的教科书案例!
希望朋友们可以帮忙【点击一下】下面这个小卡片 ,点击一下立马关闭即可,你们的随手点击,就是我分享更多干货的动力源泉
,点击一下立马关闭即可,你们的随手点击,就是我分享更多干货的动力源泉

小巨人VS大霸主:谁更胜一筹?

再说说DeepSeek-R1 满血版。
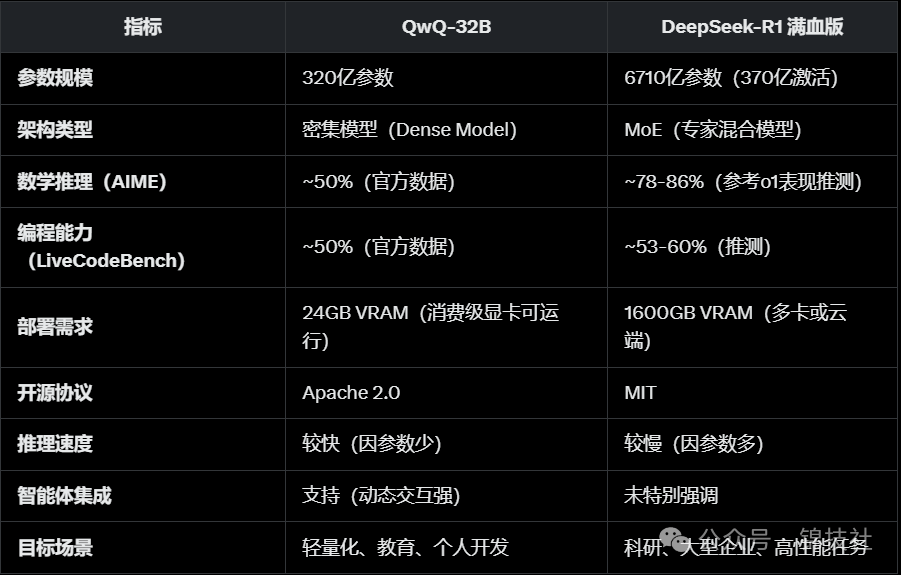
这款由深度求索团队打造的模型,拥有 6710亿参数(370亿激活),是典型的 Mixture-of-Experts (MoE) 架构代表。凭借强大的算力和强化学习优化,它在数学、代码生成和自然语言推理上对标 OpenAI o1,成为国产开源模型的骄傲。
MIT 协议的加持,也让它在全球开发者社区中声名鹊起。
然而,DeepSeek-R1 的强大是有代价的。它需要高端硬件支持,动辄多张 A100 显卡或云端算力,对普通用户来说门槛不低。这也让它的应用场景更多集中在科研机构或大型企业。
部署成本
-
QwQ-32B : 因参数量少,部署门槛低,支持消费级显卡(如Nvidia RTX 系列)运行,甚至能在苹果笔记本上部署,适合个人开发者或中小型企业使用。
-
DeepSeek-R1 满血版: 需要更高算力支持,通常要求多张高端显卡(如A100)或云服务器,部署成本较高,更适合资源充足的机构或企业。
推理能力与智能体集成
-
QwQ-32B : 通过大规模RL 训练,不仅推理能力强,还集成了Agent 功能,能在动态环境中自适应调整,展现出更强的工具使用与环境交互能力。
-
DeepSeek-R1 满血版: 推理能力同样卓越,尤其在深度思考和复杂推理任务中表现优异,但未特别强调智能体功能的集成,更多依赖静态推理。
开源生态
- 两者均采用宽松开源协议(QwQ-32B 为Apache 2.0,DeepSeek-R1 为MIT),支持免费商用。 QwQ-32B 背靠阿里生态,已在阿里云百炼平台上线并提供API 调用;DeepSeek-R1 则在Hugging Face 等平台广受欢迎。
应用场景
-
QwQ-32B : 适合轻量化部署、对成本敏感的场景,如教育、个人开发或中小企业应用。
-
DeepSeek-R1 满血版: 更适合需要极致性能的大型项目,如科研、工业级AI 系统开发。
QwQ-32B 以“精巧出智慧”的方式,用320亿参数实现了媲美DeepSeek-R1 满血版的性能,同时大幅降低部署成本,堪称性价比之王。 DeepSeek-R1 则以其大规模参数和全面能力,稳坐国产开源模型的顶尖位置。
两者各有千秋,选择时需根据算力资源和应用需求权衡。

QwQ-32B模型实测

1.首先我们给他测试最近很火的问题,9.11和9.9哪个大?
我们看一下他的回答。
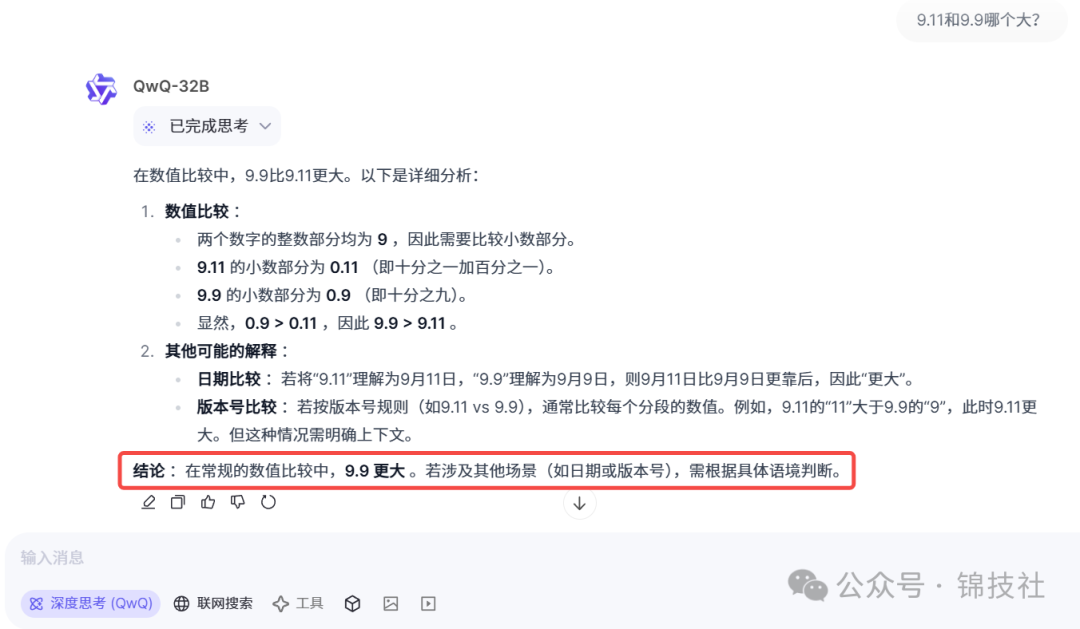
我们可以看到他很轻松的就回答了正确答案,并说若涉及其他场景,需根据具体语境判断。
2.经典问题,“strawberry” 中有几个“r”。
回答如下:
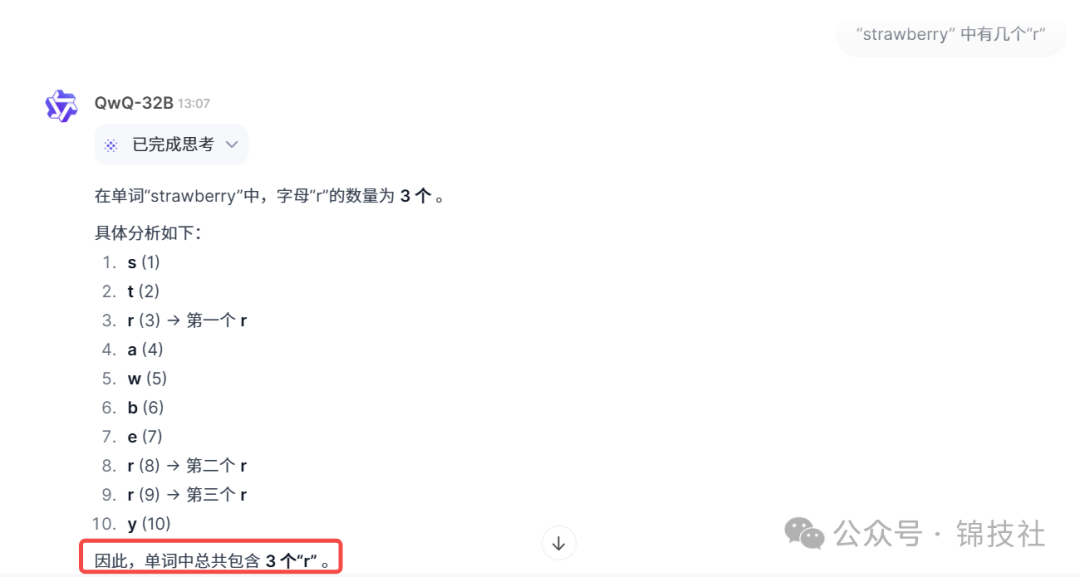
3.这里我们用下面这道有意思的题目来测试一下它的逻辑推理能力。
在一个小镇上有三个居民:张三、李四、王五。他们每个人要么是骑士,要么是间谍。骑士总是说真话,间谍总是说谎。他们的陈述如下:
张三说:“李四是间谍。”
李四说:“王五是骑士。”
王五说:“张三和李四都是间谍。”
问题:根据这些陈述,确定张三、李四、王五分别是什么身份(骑士或间谍)。请一步步解释你的推理过程。
QwQ-32B的回答如下,仅用了两个步骤。
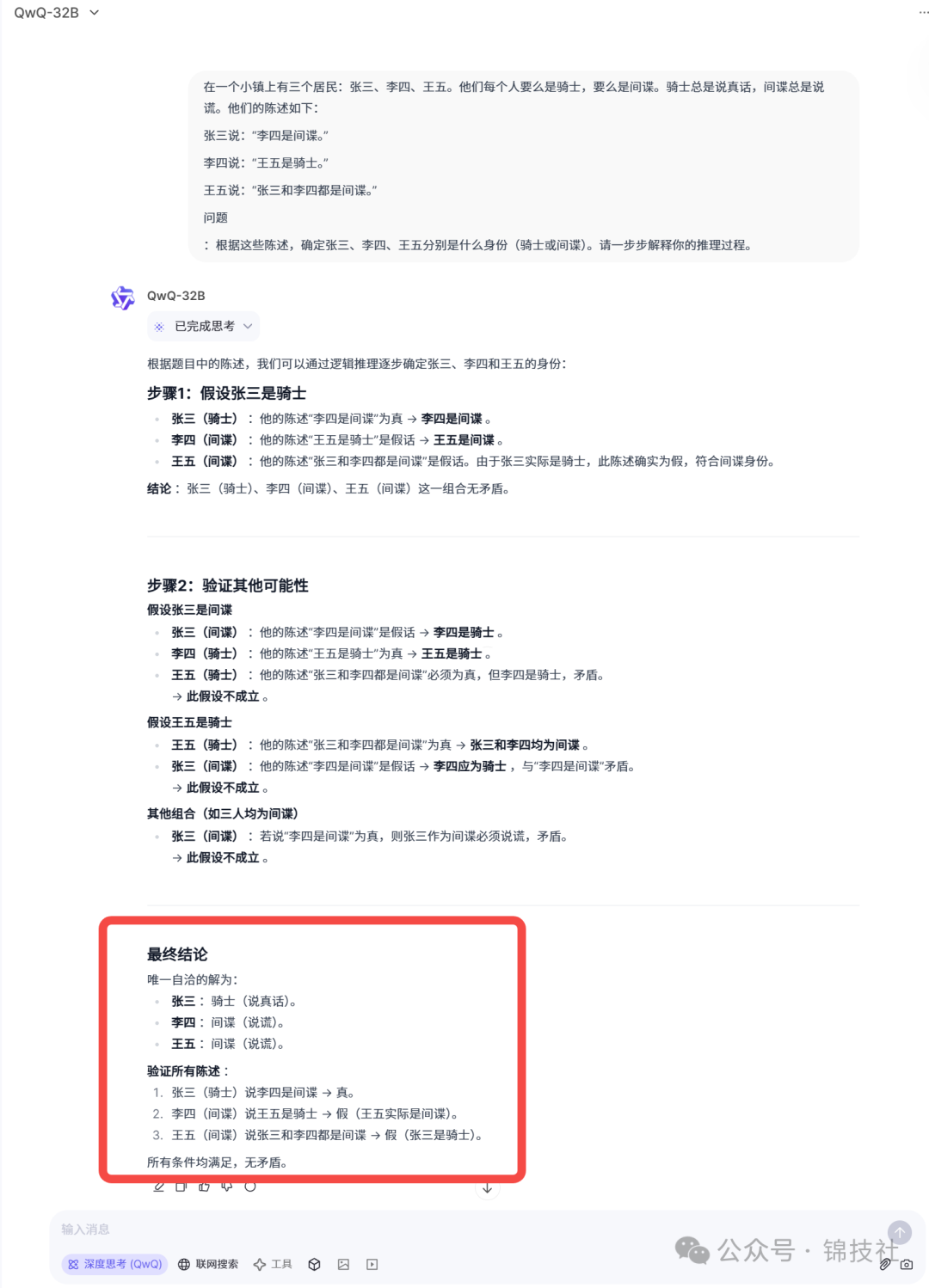
Grok3的回答如下,用了四步。

版面有限,这里就不跟大家一一测试其它问题了。有需要的小伙伴可以自行去测试。
可以在官网直接体验,也可以在阿里云百炼调用API使用,或者直接下载模型部署到本地。
对该模型的API和本地部署感兴趣的小伙伴可以在文末留言:感兴趣。人多了我会在文章写个教程教大家。
好了,本期的分享就到这里。
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)
👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。


👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型落地应用案例PPT👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(全套教程文末领取哈)

👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)

👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 10
10 0
0- 0



 已为社区贡献56条内容
已为社区贡献56条内容

所有评论(0)