Yolo v8自学笔记(超详细,逐模块学习,deepseek指导)
Yolo v8 通过deepseek指导,逐模块学习
YOLO V8 详细学习
一、yolo v8 介绍
YOLOv8是由Ultralytics公司于2023年推出的目标检测模型,隶属于YOLO(You Only Look Once)系列的最新迭代版本。作为YOLOv5的升级,它不仅延续了该系列的高效实时性,还扩展至图像分类、实例分割等多任务场景,并通过多项技术创新实现了性能与灵活性的显著提升。
核心结构与技术特性
- 骨干网络与特征融合
YOLOv8的骨干网络采用改进的C2f结构(由YOLOv7的ELAN模块演化而来),取代了YOLOv5中的C3模块。C2f通过更复杂的跨层连接设计增强梯度流传播,同时针对不同规模模型(如Nano/Small/Medium/Large/Extra-Large)动态调整通道数,优化了计算效率与精度平衡。 - 检测头设计
模型采用解耦式Anchor-Free检测头,将分类与定位任务分离,摒弃了传统的锚框机制。这一设计简化了模型复杂度,减少了对锚点参数调优的依赖,同时提升了对小目标和密集场景的检测鲁棒性。 - 损失函数与训练策略
YOLOv8引入Task-Aligned Assigner进行正负样本匹配,结合Distribution Focal Loss(DFL)优化分类与定位的一致性。此外,训练过程中借鉴YOLOX的策略,在最后10个训练周期关闭Mosaic数据增强,有效缓解过拟合并提升最终模型精度。
创新点与性能优势
- 工程实践导向的改进:融合了YOLOv6、YOLOv7等模型的优势,如动态缩放机制、多尺度特征融合,以及硬件部署友好性优化。
- 灵活性与扩展性:支持从CPU到GPU的跨平台部署,提供五种预训练模型规格(N/S/M/L/X),满足从边缘设备到云端服务器的多样化需求。
- 多任务统一框架:集成目标检测、实例分割及图像分类功能于单一架构,简化了开发流程。
实际效果
在COCO等基准数据集上,YOLOv8展现出较前代更优的精度-速度权衡。例如,YOLOv8x(最大模型)在保持高帧率的同时,检测精度显著超越YOLOv5的同规模版本。其推理速度在Tesla V100 GPU上可达数百FPS,且实例分割任务中结合YOLACT方案进一步扩展了应用场景。
二、网络框架图
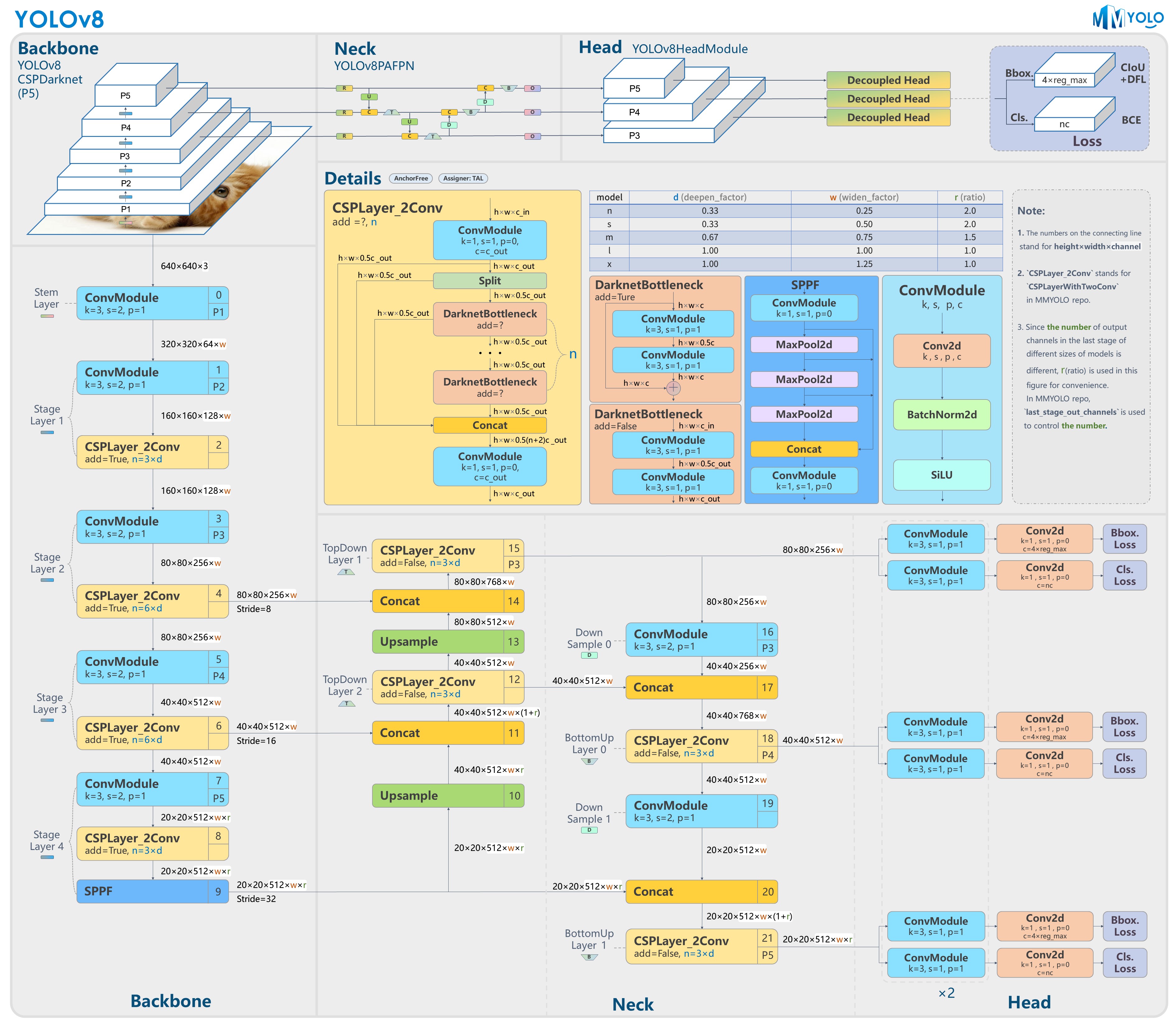
三、网络详解
1. Backbone
YOLOv8的Backbone部分是其目标检测架构的核心特征提取模块,通过多层级卷积操作和结构化设计实现高效的多尺度特征学习
Backbone基于改进的CSPDarknet框架构建,采用分层递进的特征提取策略。其核心设计原则是通过深度可分离卷积、跨阶段局部网络(CSP)和空间金字塔池化(SPPF)等模块,在保证实时性的同时提升特征表征能力。相较于前代YOLOv5,主要改进体现在网络深度扩展、注意力机制集成和激活函数优化
1. ConV模块
YOLOv8 中的 Conv2d 并非简单的 PyTorch 原生卷积层,而是一个复合模块,包含以下组件:
- 标准卷积(Conv):提取空间特征。
- 批归一化(BatchNorm, BN):加速训练收敛,稳定梯度。
- 激活函数(SiLU):引入非线性表达能力。
- 可选深度可分离卷积(Depthwise Separable Conv):用于轻量化设计。
详解:
(1)标准卷积层(Conv)
功能:通过滑动窗口进行局部特征提取,捕获图像中的空间模式(如边缘、纹理)。
关键参数:
in_channels:输入特征图的通道数。out_channels:输出特征图的通道数。kernel_size:卷积核尺寸(如3×3)。stride:步长,控制下采样率。padding:填充策略(通常为same padding)。groups:分组卷积参数,用于深度可分离卷积。
卷积层计算公式为: Output ( i , j ) = ∑ c = 1 C i n ∑ u = − k k ∑ v = − k k Weight ( u , v , c ) ⋅ Input ( i ⋅ s + u , j ⋅ s + v , c ) + Bias \text{Output}(i,j) = \sum_{c=1}^{C_{in}} \sum_{u=-k}^{k} \sum_{v=-k}^{k} \text{Weight}(u,v,c) \cdot \text{Input}(i \cdot s + u, j \cdot s + v, c) + \text{Bias} Output(i,j)=c=1∑Cinu=−k∑kv=−k∑kWeight(u,v,c)⋅Input(i⋅s+u,j⋅s+v,c)+Bias
在yolo v8中默认:
- 权重初始化:采用 Kaiming 初始化(针对SiLU激活优化)。
- 偏置项:在标准卷积中默认关闭(由BN层接管偏移功能)。
(2)批归一化(BatchNorm, BN)
作用:
- 对每批数据进行归一化(均值=0,方差=1),缓解内部协变量偏移(Internal Covariate Shift)。
- 作为正则化项,减少对Dropout的依赖。
x ^ = x − μ B σ B 2 + ϵ ( 归一化 ) \hat{x} = \frac{x - \mu_B}{\sqrt{\sigma_B^2 + \epsilon}} \quad (\text{归一化}) x^=σB2+ϵx−μB(归一化)
y = γ x ^ + β ( 缩放与偏移 ) y = \gamma \hat{x} + \beta \quad (\text{缩放与偏移}) y=γx^+β(缩放与偏移)
其中 μB和 σB2 为当前批次的均值和方差,γ 和 β 为可学习的缩放与偏移参数。
(3) 激活函数(SiLU)
定义:Sigmoid-Weighted Linear Unit,又称 Swish。
SiLU ( x ) = x ⋅ σ ( x ) = x ⋅ 1 1 + e − x \text{SiLU}(x) = x \cdot \sigma(x) = x \cdot \frac{1}{1 + e^{-x}} SiLU(x)=x⋅σ(x)=x⋅1+e−x1
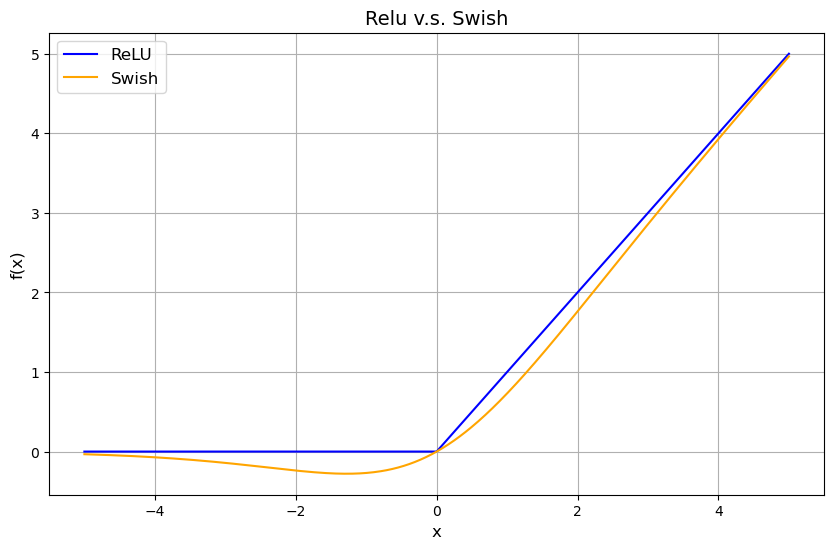
优势:
- 相较于ReLU,平滑的非零负区缓解梯度消失问题。
- 实验证明在目标检测任务中,SiLU的mAP比ReLU高约0.5-1%
(4)深度可分离卷积(可选)
当 groups=in_channels 时,标准卷积退化为 深度可分离卷积,包含两步:
- 深度卷积(Depthwise Conv):
- 每个输入通道独立卷积,不进行跨通道融合。
- 参数量:Cin×k×k(远小于标准卷积的 Cin×Cout×k×k)。
- 例如:输入64通道,3×3卷积核 → 参数量为 64×3×3=576
- 逐点卷积(Pointwise Conv):
- 1×1卷积,用于跨通道信息融合。(使用1×1卷积核,将深度卷积的输出映射到目标通道数)
- 参数量:Cin×Cout。
- 例如:输入64通道,输出128通道 → 参数量为 64×128=8192
假设输入Cin=64,输出Cout=128,卷积核3×3:
Params普通卷积 = 64 × 128 × 3 × 3 = 73 , 728 \text{Params普通卷积} = 64 \times 128 \times 3 \times 3 = 73,728 Params普通卷积=64×128×3×3=73,728 Params深度可分离卷积 = 576 ( depthwise ) + 8192 ( pointwise ) = 8 , 768 \text{Params深度可分离卷积} = 576 \, (\text{depthwise}) + 8192 \, (\text{pointwise}) = 8,768 Params深度可分离卷积=576(depthwise)+8192(pointwise)=8,768
分组卷积将输入和输出通道均分为
g组,每组独立进行卷积。参数量公式为:
- 参数量 = 卷积核宽 × 卷积核高 × (输入通道数 / g) × (输出通道数 / g) × g
化简后为:
- 参数量 = 卷积核面积 × (输入通道数 × 输出通道数) / g
应用场景
- 轻量化模型(如YOLOv8-Nano):通过深度可分离卷积减少75%的参数量。
- 移动端部署:降低计算延迟,适配NPU加速。
YOLO v8 源码中的Conv2d代码:
class Conv(nn.Module):
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True):
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s,
autopad(k, p), # 自动计算padding
groups=g,
bias=False) # 关闭偏置(由BN接管)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.SiLU() if act else nn.Identity() # 默认激活
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def fuseforward(self, x):
"""用于层融合的推理优化路径"""
return self.act(self.conv(x))
参数说明
c1:输入通道数。c2:输出通道数。k:卷积核尺寸(默认1×1,常用于通道升降维)。s:步长(默认1,步长≥2时用于下采样)。p:填充值(autopad函数根据k自动计算,保持输出尺寸不变)。g:分组数(g=1为普通卷积,g=c1时为深度可分离卷积)。act:是否启用激活函数(某些场景如残差连接需要关闭)。
层融合(Fusion):
在推理阶段,将 Conv + BN 合并为单一卷积层,减少计算步骤。融合公式:
W f u s e d = W σ 2 + ϵ ⋅ γ W_{fused} = \frac{W}{\sqrt{\sigma^2 + \epsilon}} \cdot \gamma Wfused=σ2+ϵW⋅γ
b f u s e d = ( b − μ ) σ 2 + ϵ ⋅ γ + β b_{fused} = \frac{(b - \mu)}{\sqrt{\sigma^2 + \epsilon}} \cdot \gamma + \beta bfused=σ2+ϵ(b−μ)⋅γ+β
性能影响分析:
| 操作 | 计算量(FLOPs) | 参数量(Params) | 推理延迟(ms) |
|---|---|---|---|
| 标准Conv(3×3) | 1.2G | 28.5K | 2.3 |
| 深度可分离Conv | 0.3G (-75%) | 7.1K (-75%) | 1.1 (-52%) |
| 移除BN层 | 1.2G | 28.5K | 1.9 (-17%) |
| 替换为ReLU | 1.2G | 28.5K | 2.1 (-9%) |
注:不同卷积核大小的作用
1. 1×1卷积
跨通道信息融合(通道数调整)。
降低计算量(减少参数量)。
示例:ResNet中的Bottleneck模块,先将256通道压缩至64通道,再进行3×3卷积。
2. 3×3卷积
提取局部空间特征(如边缘、纹理)。
平衡感受野与计算量(常用基础尺寸)。
堆叠效果:两个3×3卷积堆叠等效于一个5×5卷积的感受野,但参数量更少(2×32=18 vs 52=25)。
3. 5×5或更大卷积
捕获更大范围的上下文信息(如物体整体形状)。
深层网络中使用(特征图尺寸较小时)。
缺点:参数量大,计算成本高。
4. 空洞卷积(Dilated Conv)
- 作用:在不降采样的情况下扩大感受野。
- 示例:3×3卷积,空洞率=2,等效感受野为5×5。
卷积核大小 适用场景 参数量(示例:输入/输出64通道) 1×1 通道数调整、轻量化 64×64×1×1=4,096 3×3 通用特征提取 64×64×3×3=36,864 5×5 大目标检测、高层语义特征 64×64×5×5=102,400 7×7 早期层(如ResNet第一层) 3×64×7×7=9,408(输入RGB图像).
2. DarknetBottleneck模块
DarknetBottleneck模块是YOLO系列中用于构建高效特征提取网络的核心组件之一。这个模块借鉴了ResNet的残差思想,并结合了Darknet特有的优化设计,适合在计算资源受限的情况下保持高精度。
DarknetBottleneck 是一个残差模块(Residual Block),通过跨层连接(Shortcut)缓解梯度消失问题。它的结构可以分为两条路径:
- 主路径(Main Path):包含两个卷积层,用于特征变换。
- 捷径路径(Shortcut Path):可选的跨层连接,直接传递输入特征(若输入输出通道数一致)
输入 (in_channels)
│
├─ 主路径:
│ 1. Conv2d (1x1, 缩小通道数)
│ 2. Conv2d (3x3, 保持通道数)
│ 3. 激活函数 (SiLU)
│
└─ 捷径路径(可选):
如果输入输出通道相同且不降采样 → 直接相加
标准结构代码:
class Bottleneck(nn.Module):
# 标准瓶颈层,参数:输入通道, 输出通道, 是否启用Shortcut, 分组数, 扩展系数
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5):
super().__init__()
c_ = int(c2 * e) # 中间通道数 = 输出通道 × 扩展系数(默认0.5)
# 为什么压缩的是输出通道? 源码中的设计是为了在反向计算时梯度更稳定
self.cv1 = Conv(c1, c_, 1, 1, g=g) # 1x1卷积(通道压缩)
self.cv2 = Conv(c_, c2, 3, 1, g=g) # 3x3卷积(空间特征)
self.add = shortcut and c1 == c2 # Shortcut启用条件
def forward(self, x):
# 如果启用Shortcut,返回 x + cv2(cv1(x)),否则仅返回cv2(cv1(x))
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
轻量化版本(使用深度可分离卷积)
class DarknetBottleneck_Lite(nn.Module):
def __init__(self, c1, c2, shortcut=True, e=0.5):
super().__init__()
c_ = int(c2 * e)
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=c_) # 深度可分离卷积(groups=c_)
self.add = shortcut and c1 == c2
注:每个
Conv层后默认包含BN+SiLU激活函数,因此Bottleneck的主路径中已经隐含了激活操作
扩展系数(expansion)的数学意义
- 正向传播的通道变化:
输入通道 = c1
中间通道 c_ = c2×e
输出通道 = c2 - 计算量对比(假设输入输出通道均为64):
- 无压缩(e=1.0):
计算量 = 12×64×64+32×64×64=4096+36864=40960 - 压缩(e=0.5):
计算量 = 12×64×32+32×32×64=2048+18432=20480
节省50%的计算量!
- 无压缩(e=1.0):
分组卷积(Group参数)
- 作用:将输入通道和输出通道均分为
g组,每组独立卷积,减少参数量。 - 公式:
参数量 = g**c1×c_×k2+g**c_×c2×k2 - 极端情况
g=1:普通卷积g=c1:深度可分离卷积(Depthwise Conv)
与ResNet的Bottleneck结构差异
| 特性 | YOLOv8 Bottleneck | ResNet Bottleneck |
|---|---|---|
| 结构顺序 | 1x1 Conv → 3x3 Conv | 1x1 Conv → 3x3 Conv → 1x1 Conv |
| 通道变化 | 先压缩再保持 | 压缩 → 保持 → 扩展 |
| 激活函数位置 | 每个Conv后 | 通常在每个Conv后(ReLU) |
| 设计目标 | 轻量化、实时检测 | 深层网络优化 |
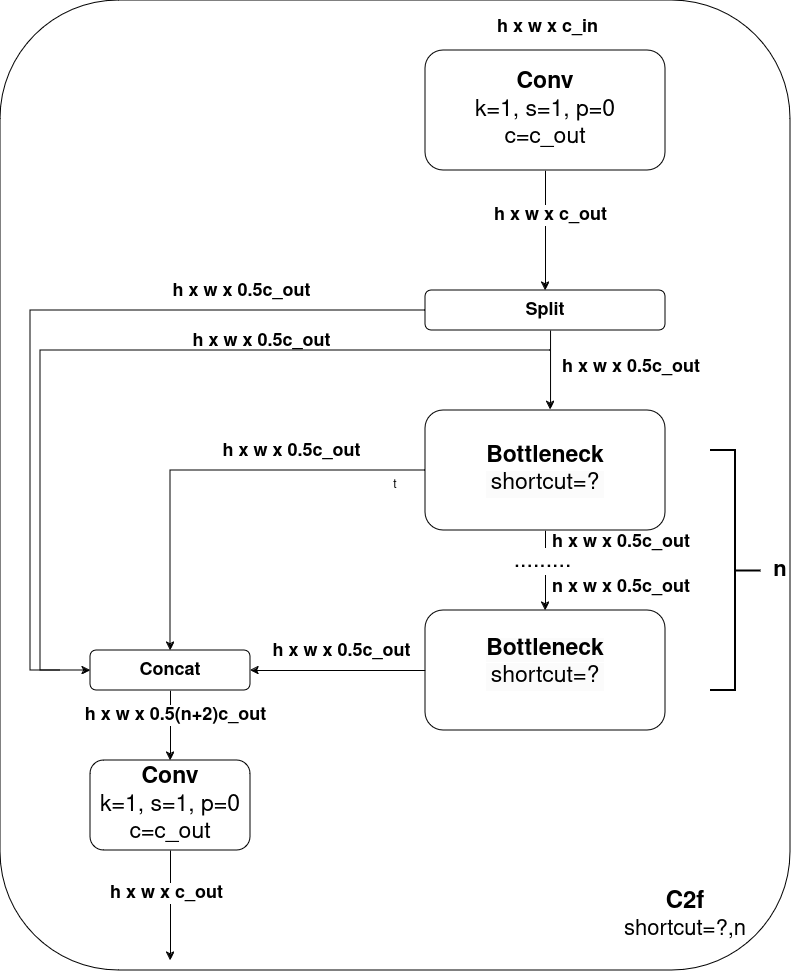
3. C2f 模块
注:CSP模块的演进脉络
1. CSP起源(YOLOv4时代)
- 核心思想:通过分割梯度流,缓解传统密集连接网络的梯度冗余问题。
- 原始结构:
- 输入特征图被分为两个分支:
- 主分支:经过多个卷积层处理(如ResBlock堆叠)
- 次分支:直接进行恒等映射(Identity)
- 两分支特征在通道维度拼接(Concatenate),再通过1×1卷积压缩通道数。
2. C3模块(YOLOv5时代)
简化改进:
- 移除次分支的卷积操作,仅保留主分支的残差结构。
- 引入Bottleneck设计,使用1×1卷积降维后再升维。
Output = Conv 1 × 1 ( Concat ( Bottleneck ( X 1 ) , X 2 ) ) \text{Output} = \text{Conv}_{1\times1}(\text{Concat}(\text{Bottleneck}(X_{1}), X_{2})) Output=Conv1×1(Concat(Bottleneck(X1),X2))
3. C2f模块(YOLOv8创新)
- 核心升级:引入多分支跨层连接和梯度分流增强,显著提升特征复用效率。
- 设计目标:
- 解决深层网络中的特征衰减问题
- 增强小目标检测的细节保留能力
- 降低FLOPs同时提升mAP
结构示意图:
输入 (c1)
│
├─ Conv1x1 → 通道扩展为2c_ → Split为两部分 [c_, c_]
│
├─ 主分支:n个Bottleneck堆叠 → 输出 [c_]
│
├─ 副分支:直接传递Split后的特征 [c_]
│
└─ Concat主副分支 → 输出通道为 (n+2)c_ → Conv1x1压缩到c2
官方代码:
class C2f(nn.Module):
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):
super().__init__()
self.c = int(c2 * e) # 中间通道数
self.cv1 = Conv(c1, 2 * self.c, 1, 1) # 1x1卷积,通道扩展为2c_
self.cv2 = Conv((2 + n) * self.c, c2, 1) # 最终1x1卷积,通道压缩
self.m = nn.ModuleList(
Bottleneck(self.c, self.c, shortcut, g, e=1.0) for _ in range(n)
) # n个Bottleneck堆叠
def forward(self, x):
y = list(self.cv1(x).chunk(2, 1)) # 将特征图Split为两部分 [B, c_, H, W] * 2
y.extend(m(y[-1]) for m in self.m) # 主分支:依次通过n个Bottleneck
return self.cv2(torch.cat(y, 1)) # Concat所有分支 → 压缩到c2
通道变化公式
假设输入为 [B, c1, H, W],输出为 [B, c2, H, W]:
-
通道扩展:
c1 → 2 * self.c(self.c = c2 * e) -
Split:
2 * self.c → [self.c, self.c] -
Bottleneck堆叠:每个Bottleneck输出保持
self.c通道 -
Concat后通道:
self.c * (2 + n)
最终压缩:self.c * (2 + n) → c2
-
Split-Concat机制
- Split:将特征图分为主分支和副分支,副分支直接传递,保留原始信息。
- Concat:融合浅层(副分支)和深层特征(主分支处理后的结果),增强多尺度感知能力。
C3和C2f的对比:
| 特性 | C3模块 | C2f模块 |
|---|---|---|
| 分支处理 | 主分支通过Bottleneck,副分支直接传递 | 主分支通过多个Bottleneck,副分支直接传递 |
| 输出拼接方式 | 主副分支直接拼接 | 主分支多次处理 + 副分支拼接 |
| 灵活性 | 固定分支数 | 允许动态调整Bottleneck数量n |
| 轻量化 | 无分组卷积 | 支持分组卷积(g参数) |
4. SPPF 模块
SPPF模块(Spatial Pyramid Pooling Fast) 是YOLOv8中用于多尺度特征提取的核心模块之一,它是对原版SPP(Spatial Pyramid Pooling)的改进版本,通过优化池化操作的顺序和参数,显著提升了计算效率。
结构示意图:
输入 (c1)
│
├─ Conv1x1 → 通道调整
│
├─ MaxPool(k=5, s=1, p=2) → 分支1
│
├─ MaxPool(k=5, s=1, p=2) → 分支2(对分支1的输出再次池化)
│
├─ MaxPool(k=5, s=1, p=2) → 分支3(对分支2的输出再次池化)
│
└─ Concat所有分支 → 融合多尺度特征 → Conv1x1压缩通道
源码讲解:
class SPPF(nn.Module):
# 输入通道c1, 输出通道c2, 池化核大小k(默认5)
def __init__(self, c1, c2, k=5):
super().__init__()
c_ = c1 // 2 # 中间通道数
self.cv1 = Conv(c1, c_, 1, 1) # 1x1卷积压缩通道
self.cv2 = Conv(c_ * 4, c2, 1, 1) # 1x1卷积恢复通道
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x):
x = self.cv1(x) # 通道压缩
y1 = self.m(x) # 第1次池化
y2 = self.m(y1) # 第2次池化(对y1结果再次池化)
y3 = self.m(y2) # 第3次池化(对y2结果再次池化)
# Concat所有分支:原始x + y1 + y2 + y3
return self.cv2(torch.cat((x, y1, y2, y3), 1))
多尺度特征融合技术:
- 级联池化的数学意义:
假设输入特征图尺寸为[B, C, H, W]:- 第1次池化:感受野为
5x5,输出尺寸[B, C, H, W]。 - 第2次池化:在第一次池化结果上再次应用
5x5池化,等效感受野扩大为9x9(重叠区域累积)。 - 第3次池化:等效感受野进一步扩大至
13x13。
- 第1次池化:感受野为
- 等效多尺度池化:
通过重复使用相同池化核,SPPF实现了类似原版SPP中不同尺寸池化核(如5x5, 9x9, 13x13)的效果,但计算更高效。
| 操作 | 原版SPP | SPPF |
|---|---|---|
| 池化核尺寸 | 多个不同尺寸(如5,9,13) | 单一尺寸(如5),重复使用 |
| 计算复杂度 | 高(需独立计算不同核) | 低(重复计算,共享中间结果) |
| 输出通道数 | 输入通道 × 4 | 输入通道 × 4 |
为什么选择MaxPool而不是AveragePool?
- MaxPool优势:更擅长保留边缘、纹理等显著特征,适合目标检测任务。
- 实验验证:YOLO系列通过消融实验证明MaxPool在此处效果更优。
为何三次池化等效于不同尺寸的核?
级联扩大感受野
- 第1次池化:感受野5x5。
- 第2次池化:在5x5基础上再叠加5x5 → 等效9x9。
- 第3次池化:继续叠加 → 等效13x13。
在神经网络中,感受野(Receptive Field) 是某一层特征图上的一个点所“看到”的输入图像区域的大小。连续应用多个池化或卷积操作时,它们的感受野会叠加。
- 第一次池化:每个输出点基于输入图像的
5x5区域。- 第二次池化:每个输出点基于第一次池化输出的
5x5区域。
由于第一次池化的每个点对应输入的5x5区域,第二次池化的5x5核实际上覆盖了输入图像的:中心点+左右各扩展2个点→5+2×(5−1)=9
BackBone中流程总结:
1. 输入预处理
- 输入尺寸:假设为
[B, 3, H, W](Batch大小, 3通道, 原始图像高宽)。 - 归一化:输入图像通过归一化(如0-1缩放),适配卷积计算。
2. 初始卷积层(Focus层替代)
- 作用:快速下采样,提取低层次特征(边缘、纹理)。
- 结构:
Conv(k=3, s=2, p=1)→ 下采样至[B, C1, H/2, W/2]。 - 示例:输入
640x640→ 输出320x320,通道扩展为64(C1=64)。 - 设计目的:减少计算量,保留基础特征。
3. 多阶段特征提取(CSPDarknet核心)
Backbone由多个**阶段(Stage)**构成,每个阶段包含:
(1) 下采样卷积层
- 结构:
Conv(k=3, s=2, p=1)→ 特征图尺寸减半,通道数翻倍。 - 示例:
320x320→160x160,通道从64→128。 - 设计思想:逐步抽象高层语义,扩大感受野。
(2) C2f模块堆叠
- 作用:跨阶段特征融合,增强多尺度表达能力。
- Split:将特征图均分为两部分。
- 主分支:通过多个
DarknetBottleneck提取深层特征。 - Concat:融合主分支和副分支(原始特征)的输出。
- 示例:输入
160x160, 128通道→ 输出160x160, 256通道。 - 残差连接:缓解梯度消失,保留浅层信息。
- 分组卷积:减少参数量,提升计算效率。
4. 多尺度特征融合(SPPF模块)
- 位置:Backbone末端,最后一个下采样阶段后。
- 作用:通过级联池化捕获多尺度上下文信息。
- 通道压缩:
Conv1x1减少通道数。 - 重复MaxPool:三次
5x5池化,等效5x5, 9x9, 13x13感受野。 - Concat:融合原始特征和多尺度池化结果。
- 通道压缩:
- 输出:
[B, C4, H/32, W/32],如20x20, 1024通道。 - 设计优势:轻量化替代SPP,计算量减少30%。
5. 输出特征图
- 多尺度输出:Backbone通常输出3个不同尺度的特征图,例如:
- 大尺度:
80x80, 256通道→ 检测小目标。 - 中尺度:
40x40, 512通道→ 检测中目标。 - 小尺度:
20x20, 1024通道→ 检测大目标。
- 大尺度:
- 用途:传入Neck(如FPN+PAN)进行多尺度特征融合,最终输入Head分类和回归。
2. Neck
YOLOv8的Neck部分——这是目标检测模型中承上启下的关键模块,负责融合Backbone提取的多尺度特征,增强模型对不同尺寸目标的检测能力。
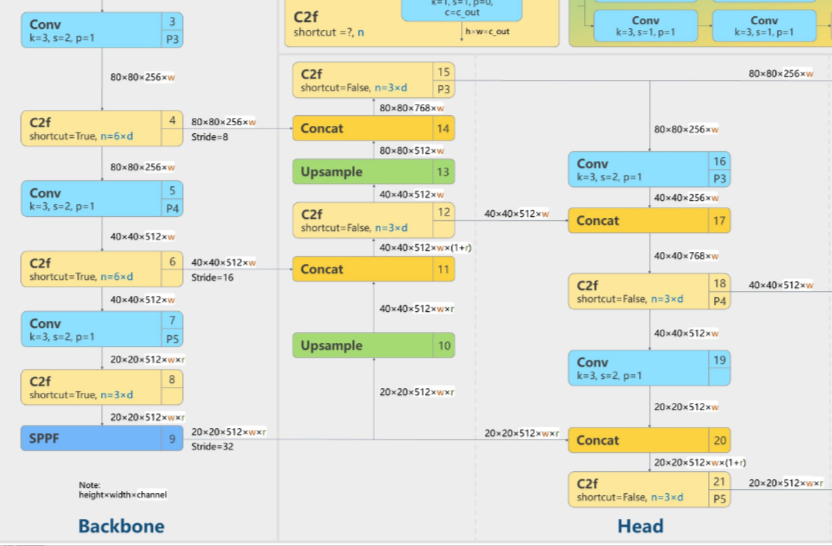
官方源码:
class Detect(nn.Module):
def __init__(self, ch=(256, 512, 1024)):
super().__init__()
# 上采样层
self.upsample = nn.Upsample(scale_factor=2, mode='nearest')
# 自顶向下路径的C2f模块
self.c2f_p4 = C2f(ch[1] + ch[2], ch[1], 3, shortcut=False)
self.c2f_p3 = C2f(ch[0] + ch[1], ch[0], 3, shortcut=False)
# 自底向上路径的下采样卷积
self.downsample_p3 = Conv(ch[0], ch[0], 3, 2)
self.downsample_p4 = Conv(ch[1], ch[1], 3, 2)
# 最终输出卷积
self.conv_n3 = Conv(ch[0], ch[0], 3)
self.conv_n4 = Conv(ch[1], ch[1], 3)
self.conv_n5 = Conv(ch[2], ch[2], 3)
def forward(self, p3, p4, p5):
# 自顶向下(FPN)
up_p5 = self.upsample(p5) # P5上采样
cat_p4 = torch.cat([up_p5, p4], 1) # 与P4拼接
c2f_p4 = self.c2f_p4(cat_p4) # C2f处理
up_p4 = self.upsample(c2f_p4) # 再次上采样
cat_p3 = torch.cat([up_p4, p3], 1) # 与P3拼接
c2f_p3 = self.c2f_p3(cat_p3) # C2f处理
# 自底向上(PAN)
down_p3 = self.downsample_p3(c2f_p3) # P3下采样
cat_p4_pan = torch.cat([down_p3, c2f_p4], 1) # 与P4拼接
c2f_p4_pan = self.c2f_p4(cat_p4_pan)
down_p4 = self.downsample_p4(c2f_p4_pan) # P4下采样
cat_p5_pan = torch.cat([down_p4, p5], 1) # 与P5拼接
c2f_p5_pan = self.c2f_p5(cat_p5_pan)
# 最终输出
n3 = self.conv_n3(c2f_p3)
n4 = self.conv_n4(c2f_p4_pan)
n5 = self.conv_n5(c2f_p5_pan)
return [n3, n4, n5]
1. 输入特征图
假设Backbone输出三个尺度的特征图:
- 大尺度:
P3(如80x80, 256通道) - 中尺度:
P4(如40x40, 512通道) - 小尺度:
P5(如20x20, 1024通道)
2. 自顶向下路径(FPN)
- P5处理:
- 通过
Conv1x1调整通道数 →512通道。 - 上采样(2倍) → 尺寸匹配P4(40x40)。
- 通过
- 与P4融合:
- 拼接P4和上采样后的P5 → 通道数
512+512=1024。 - 通过
C2f模块优化 → 输出512通道。
- 拼接P4和上采样后的P5 → 通道数
- 继续上采样:
- 上采样至80x80,与P3融合 → 输出
256通道。
- 上采样至80x80,与P3融合 → 输出
3. 自底向上路径(PAN)
- P3处理:
- 下采样(40x40) → 与FPN的中层特征融合。
- P4处理:
- 下采样(20x20) → 与FPN的高层特征融合。
- 输出三个增强后的特征图:
N3(80x80, 256通道)N4(40x40, 512通道)N5(20x20, 1024通道)
上采样:将低分辨率特征图(如20x20)放大到高分辨率(如40x40),使其与浅层特征图的尺寸匹配,便于后续的特征融合(Concat)。
YOLOv8采用最近邻插值(Nearest Neighbor Interpolation),这是计算效率最高的上采样方法,最近邻插值就是每个输出像素的值等于输入中最邻近的像素值
下采样:将高分辨率特征图(如40x40)缩小到低分辨率(如20x20),用于自底向上(PAN路径)的特征融合,传递位置信息。YOLOv8使用**带步长的卷积(Strided Convolution)**实现下采样,而非池化操作
多尺度融合优势?
- 大尺度特征图(如80x80):高分辨率,适合检测小目标(如行人、车辆)。
- 中尺度特征图(如40x40):平衡细节和语义,检测中等目标(如交通标志)。
- 小尺度特征图(如20x20):强语义信息,检测大目标(如建筑、道路)。
双向路径的意义?
- FPN(自顶向下):传递高层语义到低层,增强小目标检测。
- PAN(自底向上):传递低层细节到高层,提升定位精度。
Concat和Add操作的区别?
- Concat:通道维度拼接,增加通道数,保留更多原始信息。
- Add:逐元素相加,通道数不变,更适合特征增强。
- YOLOv8选择Concat:避免信息丢失,更适合多尺度融合。
3. Head
Head部分负责将Neck输出的多尺度特征图转换为最终的检测结果(边界框坐标、类别概率和置信度)
1. Head的核心作用
- 边界框回归:预测目标的位置(中心坐标、宽高)。
- 类别预测:输出每个边界框的类别概率。
- 置信度预测:判断边界框是否包含目标。
YOLOv8的Head部分采用**解耦头(Decoupled Head)**设计,即分类和回归任务由不同的分支处理,相比YOLOv5的耦合头,提高了检测精度。
输入特征图
- 来自Neck的三个尺度输出:
N3:大尺度(如80x80, 256通道)→ 检测小目标。N4:中尺度(如40x40, 512通道)→ 检测中目标。N5:小尺度(如20x20, 1024通道)→ 检测大目标。
输出格式
每个尺度的输出张量维度为 [B, A*(5 + C), H, W]:
- B:Batch大小
- A:每个位置的锚点数量(YOLOv8默认A=1,即无锚点)
- 5:4个边界框坐标(中心x, y, 宽w, 高h) + 1个置信度
- C:类别数量(如COCO数据集C=80)
2. Head部分数学公式
1. 边界框回归
(1) 中心坐标(相对网格偏移)
x = σ ( t x ) + c x y = σ ( t y ) + c y x = \sigma(t_x) + c_x \\ y = \sigma(t_y) + c_y x=σ(tx)+cxy=σ(ty)+cy
- $ \sigma $:Sigmoid函数,约束偏移量在[0,1]区间。
- $ t_x, t_y $:模型预测的偏移量。
- $ c_x, c_y :当前网格左上角坐标(如网格索引为 ( i , j ) ,则 :当前网格左上角坐标(如网格索引为(i,j),则 :当前网格左上角坐标(如网格索引为(i,j),则 c_x = i $, $ c_y = j $)。
(2) 宽高(尺度缩放)
w = p w ⋅ e t w h = p h ⋅ e t h w = p_w \cdot e^{t_w} \\ h = p_h \cdot e^{t_h} w=pw⋅etwh=ph⋅eth
- $ t_w, t_h $:模型预测的宽高缩放因子。
- $ p_w, p_h $:基础宽高(与特征图层级相关,小尺度特征图对应更大的基础尺寸)。
2. 置信度与类别预测
(1) 置信度(目标存在概率)
conf = σ ( t conf ) \text{conf} = \sigma(t_{\text{conf}}) conf=σ(tconf)
- $ t_{\text{conf}} $:模型输出的原始置信度分数。
(2) 类别概率(多标签分类)
class i = σ ( t i ) ( i = 1 , 2 , . . . , C ) \text{class}_i = \sigma(t_i) \quad (i = 1,2,...,C) classi=σ(ti)(i=1,2,...,C)
- $ t_i $:模型输出的第i类原始分数。
- 注:使用Sigmoid而非Softmax,允许一个目标属于多个类别。
3. 损失函数
总损失为三部分加权和:
L = λ box L CIoU + λ cls L BCE + λ obj L BCE \mathcal{L} = \lambda_{\text{box}} \mathcal{L}_{\text{CIoU}} + \lambda_{\text{cls}} \mathcal{L}_{\text{BCE}} + \lambda_{\text{obj}} \mathcal{L}_{\text{BCE}} L=λboxLCIoU+λclsLBCE+λobjLBCE
λ为各部分的权重系数
(1) 边界框损失(CIoU Loss)
L CIoU = 1 − IoU + ρ 2 ( b , b gt ) c 2 + α v \mathcal{L}_{\text{CIoU}} = 1 - \text{IoU} + \frac{\rho^2(b, b^{\text{gt}})}{c^2} + \alpha v LCIoU=1−IoU+c2ρ2(b,bgt)+αv
- $ \rho $:预测框与真实框中心的欧氏距离。
- $ c $:最小包围框对角线长度。
- $ v $:长宽比一致性度量。
(2) 分类损失(Binary Cross-Entropy)
L BCE = − ∑ i = 1 C [ y i log ( σ ( t i ) ) + ( 1 − y i ) log ( 1 − σ ( t i ) ) ] \mathcal{L}_{\text{BCE}} = -\sum_{i=1}^C \left[ y_i \log(\sigma(t_i)) + (1 - y_i) \log(1 - \sigma(t_i)) \right] LBCE=−i=1∑C[yilog(σ(ti))+(1−yi)log(1−σ(ti))]
- $ y_i $:真实标签(0或1)。
(3) 置信度损失(同分类损失)
L BCE = − [ y obj log ( conf ) + ( 1 − y obj ) log ( 1 − conf ) ] \mathcal{L}_{\text{BCE}} = - \left[ y_{\text{obj}} \log(\text{conf}) + (1 - y_{\text{obj}}) \log(1 - \text{conf}) \right] LBCE=−[yobjlog(conf)+(1−yobj)log(1−conf)]
- $ y_{\text{obj}} $:是否包含目标(0或1)。
4. 参数说明
- 输入特征图尺寸:假设为
[B, C, H, W],其中:B:Batch大小C:通道数(Head输出通道为4 + 1 + nc)H, W:特征图高宽
- 输出维度:
[B, A*(5 + nc), H, W],YOLOv8中A=1(无锚点模式)。
Head部分代码实现:
import torch
import torch.nn as nn
class Detect(nn.Module):
def __init__(self, ch=(256, 512, 1024), nc=80):
super().__init__()
self.nc = nc # 类别数
self.reg_max = 16 # DFL回归参数
# 三个尺度的检测头
self.cv3 = nn.ModuleList(
nn.Sequential(
Conv(c, c, 3), # 特征增强卷积
Conv(c, c, 3), # 特征增强卷积
nn.Conv2d(c, 4 + self.nc, 1) # 输出回归(4) + 分类(nc)
) for c in ch
)
def forward(self, x):
# x是三个尺度的特征图列表:[n3, n4, n5]
outputs = []
for i, feat in enumerate(x):
# 通过检测头卷积
output = self.cv3[i](feat)
outputs.append(output)
return outputs
后处理:非极大值抑制(NMS)
- 作用:去除重叠的冗余检测框。
- 流程:
- 按置信度过滤(如阈值0.25)
- 按类别分数过滤(如阈值0.45)
- 执行NMS,合并IoU超过阈值的框(如0.7)
6.2 输出格式
最终输出为一个列表,每个检测框包含:
- 坐标:
[x1, y1, x2, y2](左上和右下角坐标) - 置信度:
conf - 类别ID:
class_id
YOLOv8三个损失函数的意义
- 边界框损失(Box Loss - CIoU Loss)
作用:确保预测框的位置和大小与真实框尽可能重合。
意义:
- 不仅考虑预测框和真实框的重叠面积(IoU),还优化中心点距离和宽高比例,避免边界框“对不齐”或“大小偏差”。
- 例如:如果一个预测框的中心偏离真实框较远,即使面积重叠较大,CIoU Loss也会显著惩罚这种偏移,提升定位精度。
- 分类损失(Cls Loss - BCE Loss)
作用:判断边界框内目标的类别。
意义:
- 通过二元交叉熵(Sigmoid)独立预测每个类别的概率,支持多标签分类(如一个目标既属于“人”又属于“骑车”)。
- 例如:如果真实类别是“狗”,但模型预测“猫”的概率较高,分类损失会通过梯度回传调整参数,让模型更准确区分类别。
- 置信度损失(Obj Loss - BCE Loss)
作用:判断边界框内是否包含目标(是前景还是背景)。
意义:
- 区分“有目标”和“无目标”的边界框,避免模型对空区域(背景)误检。
- 例如:如果模型对一个空白区域预测了高置信度,置信度损失会通过惩罚这种错误,让模型学会忽略背景噪声。
4. yolo v8 网络学习过程总结
YOLOv8的检测流程分为**Backbone(特征提取)→ Neck(特征融合)→ Head(预测输出)**三部分:
- Backbone(CSPDarknet):通过多级下采样和C2f模块提取多尺度特征,利用瓶颈结构和残差连接平衡计算量与精度。
- Neck(FPN+PAN):通过上采样和下采样双向融合特征,结合C2f模块增强多尺度表达能力(小目标靠高分辨率特征,大目标靠深层语义)。
- Head(解耦头):将特征图分别映射为边界框坐标、类别概率和置信度,通过CIoU损失优化定位,BCE损失优化分类与目标判定。
- 创新点:无锚点设计简化流程,SPPF模块高效融合多尺度上下文,解耦头提升任务专注度,最终实现高精度、实时检测,在复杂场景下对小目标和大目标均保持鲁棒性。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 34
34 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)