【RAG实战】零依赖!本地大模型+向量检索,从0构建RAG
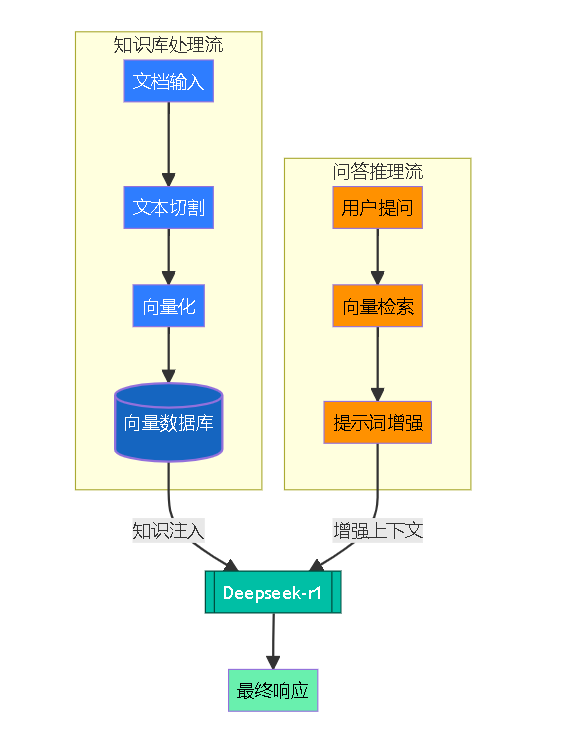
RAG即为检索增强生成,将数据检索的优势与大语言模型进行融合,能够完成幻觉减少的目的根据外挂的知识库再构建提示词进行提问能够使大模型在知识库涉及到的垂类领域更加精确本贴旨在尽可能使用较少第三方框架的情况下完成RAG整个流程,真正认识清楚并自己完成RAG的工作流程使用Ollama本地部署的Deepseek-r1:7b作为本地大语言模型,nomic-embed-text作为embedding模型。使用
目录
概述
RAG即为检索增强生成,将数据检索的优势与大语言模型进行融合,能够完成幻觉减少的目的
根据外挂的知识库再构建提示词进行提问能够使大模型在知识库涉及到的垂类领域更加精确
本贴旨在尽可能使用较少第三方框架的情况下完成RAG整个流程,真正认识清楚并自己完成RAG的工作流程
使用Ollama本地部署的Deepseek-r1:7b作为本地大语言模型,nomic-embed-text作为embedding模型。
使用原生 Python 实现 RAG_哔哩哔哩_bilibili
b站已经有佬完成这个任务,本帖仅作为学习细化。
相关的代码已经发布可以直接下载
环境配置
因为本帖主要为了理解整个RAG的流程所以环境比较简单也没用到复杂的框架,一个ollama需要提前装好并下好两个模型,python需要的第三方库就只有ollama和numpy了
pip install ollama
pip install numpy
ollama run deepseek-r1
ollama pull nomic-embed-text
以及一个帕金森相关的txt文件
一、原理
首先将知识库的所有内容通过分词器将整段文章分为一段一段的句子
再使用Embedding模型转化为向量,并将向量进行存储
在用户输入进问题后,将用户的问题经过Embedding转换为向量,计算余弦相似度找到相似的句子
将最相似的几个句子列出来,重新构建prompt提示词
最后再传入给大语言模型,获取回答。
1Embedding
Embedding选择使用本地Ollama拉取的nomic-embed-text模型
ollama pull nomic-embed-text使用python进行调用
from ollama import embeddings
# ollama embedding请求的构建
response = embeddings(model='nomic-embed-text', prompt='北京建筑大学是一所不亚于清华大学的好学校')
print(response)
# response回复可查看得到的response格式
print(response['embedding'])
# 查看embedding里的向量
print(len(response['embedding']))
# 查看维度通过上述代码即可完成一次embedding模型的使用
得到回复的格式如下

可以清晰的看到这个模型共有768个维度
1维到3维就是坐标轴的数量增加,可以直观看到,但是768个维度就没那么直观了
可以简单理解为一个拥有更多表示范围的高维空间,这样就更能使我们存储的向量具有唯一性
2大语言模型
大语言模型使用Ollama拉取deepseek-r1
from ollama import chat, Message
msgs = [
Message(role='system', content='你是一个医疗专业的智能体,对于医学领域的问题你得心应手'),
Message(role='user', content='帕金森有办法治疗码'),
]
response = chat(model='deepseek-r1', messages=msgs)
# 获取response
print(response)
# 查看response完整内容,可确定格式
print(response['message'])
# message中存储的是回答![]()
正常得到回复
二、RAG流程
分步逐步完成RAG部分的代码
首先回忆一下原理
知识库内容--分词器--句子--Embedding模型--向量
问题--Embedding--向量--余弦相似度--相似的句子--构建promp--大语言模型--回答。
那么一共需要这么几个东西
1分词器、2embedding向量转换、3相似度计算、4检索top5、5提示词模板、6大语言模型
1分词器
那首先完成分词器的内容,一篇文档要进行分词又要尽可能完整,首先想到的就是按照换行符切割
那首先需要完成文档的读取
with open(filepath, 'r', encoding='utf-8') as f:
content = f.read()然后是分词器的完成
def spilit(content):
chunks = []
lines = content.splitlines()
# 按换行符分割成行,处理所有类型的换行符
for line in lines:
if line.strip():
chunks.append(line)
return chunks 可以直观看见分词效果
可以直观看见分词效果
2向量转换
向量转换需要将将分词器得到的chunks传入ollama的embedding模型进行向量化并存储
def encode(texts):
# 使用ollama的embeddings模型获取向量并储存
embeds = []
for text in texts:
response = embeddings(model='nomic-embed-text', prompt=text)
embeds.append(response['embedding'])
return np.array(embeds)3相似度计算
余弦相似度的算法
点乘除以范数即可求出余弦相似度
def similarity(e1, e2):
# 计算余弦相似度
dot_product = np.dot(e1, e2)
# 点乘
norm_e1 = np.linalg.norm(e1)
norm_e2 = np.linalg.norm(e2)
# 范数
cosine_sim = dot_product / (norm_e1 * norm_e2)
# 余弦相似度 = 点乘 / (范数1 * 范数2)
return cosine_sim当然除了余弦相似度外还有很多计算相似度的方法,比如欧氏距离可以细分角度相似距离差距很远的情况,这里只先完成整个流程
有了余弦相似度就可以去知识库里去检索了
4检索top5
目的是找出来最相符的5个相关知识,首先需要得到所有的相似度,再进行排序,将最相关的5个句子提取出来。
def search(text, top_k=5):
# 文本解码
e = encode([text])[0]
# 相似度比较
sims = [(idx, similarity(e, ke)) for idx, ke in enumerate(embeds)]
sims.sort(key=lambda x: x[1], reverse=True)
# 匹配前5
best_matches = [docs[idx] for idx, _ in sims[:top_k]]
return best_matches首先生成了一个包含每个预存文档的索引 idx 和与输入文本的相似度列表
然后按相似度分数降序排列,最高分排在最前
取排序后前 top_k 个索引对应的文档。
5提示词模板
检索部分也完成之后可以准备进行提示词的构建了
最简单的提示词模板就是
基于:*知识*
回答:*问题*
但是我们有5个问题,写的简单一点就是
prompt_template = """
基于以下知识:1:%s,2:%s,3:%s,4:%s,5:%s
回答用户的问题:%s
"""直接把知识和问题填到提示词里面就可以完成提示词模板的内容了
6大语言模型
然后只需要将得到的提示词再发给大语言模型就可以了
def chat(text):
# 先检索知识库再构建prompt传给ollama
context = search(text)
prompt = prompt_template % (context[0], context[1], context[2], context[3], context[4], text)
print(prompt)
response = chat(model, [Message(role='system', content=prompt)])
return response['message']这样所有的部分都被写成了函数,已经有了一个完整的流程了接下来只需要进行数据的传入,我们进行一个简单的封装看看效果
三、效果
主要分成知识库和大模型两个类
class Kb:
def __init__(self, filepath):
with open(filepath, 'r', encoding='utf-8') as f:
content = f.read()
# 文件读取
self.docs = self.spilit_content(content)
self.embeds = self.encode((self.docs))
@staticmethod
def spilit_content(content):
chunks = []
# 按换行符分割成行,处理所有类型的换行符
lines = content.splitlines()
for line in lines:
if line.strip():
chunks.append(line)
return chunks
@staticmethod
def encode(texts):
# 使用ollama的embeddings模型获取向量并储存
embeds = []
for text in texts:
response = embeddings(model='nomic-embed-text', prompt=text)
embeds.append(response['embedding'])
return np.array(embeds)
@staticmethod
def similarity(e1, e2):
# 计算余弦相似度
dot_product = np.dot(e1, e2)
# 点乘
norm_e1 = np.linalg.norm(e1)
norm_e2 = np.linalg.norm(e2)
# 范数
cosine_sim = dot_product / (norm_e1 * norm_e2)
# 余弦相似度 = 点乘 / (范数1 * 范数2)
return cosine_sim
def search(self, text, top_k=5):
# 文本解码
e = self.encode([text])[0]
# 相似度比较
sims = [(idx, self.similarity(e, ke)) for idx, ke in enumerate(self.embeds)]
sims.sort(key=lambda x: x[1], reverse=True)
# 匹配前5
best_matches = [self.docs[idx] for idx, _ in sims[:top_k]]
return best_matchesclass RAG:
def __init__(self, model, kb:Kb):
self.model = model
self.kb = kb
self.prompt_template = """
基于以下知识:1:%s,2:%s,3:%s,4:%s,5:%s
回答用户的问题:%s
"""
def chat(self, text):
# 先检索知识库再构建prompt传给ollama
context = self.kb.search(text)
prompt = self.prompt_template % (context[0], context[1], context[2], context[3], context[4], text)
print(prompt)
response = chat(self.model, [Message(role='system', content=prompt)])
return response['message']封装完后通过简单的while循环进行调用
if __name__ == '__main__':
kb = Kb('knowledgeBase/帕金森氏症en.txt')
rag = RAG('deepseek-r1', kb)
while True:
print(rag.prompt_template)
q = input('Human:')
r = rag.chat(q)
print('Assistant: ', r['content'])运行起来查看一下效果

可以看到检索到知识库内容的效果还并不理想,主要是仅通过余弦相似度进行判断,会把无意义的名词单句也放进来

 但回答效果确实是根据知识库给出的消息作答,看得出来确实很有效果
但回答效果确实是根据知识库给出的消息作答,看得出来确实很有效果
结语
通过RAG进行大模型的回复对于垂向领域内的效果非常显著,将重要的知识存储并进行检索,根据检索出来的知识再进行作答,本人认为自己深入浅出的详细讲解了RAG的整个流程,不需要复杂的准备就可以完成一个简单的RAG,本贴仅为学习,欢迎大家来复刻并一起学习。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 37
37 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)