本地部署DeepSeek
一共只需要3步1.下载ollama2.下载DeepSeek-R1模型3.搭建Chatbox界面我觉得吧,你要想本地能和官网一样的效果,那是不现实的,说实话也没这个必要,但本地部署最终要的是能解决数据隐私的问题。
一共只需要3步
1.下载ollama
2.下载DeepSeek-R1模型
3.搭建Chatbox界面
为啥要本地部署?
我觉得吧,你要想本地能和官网一样的效果,那是不现实的,说实话也没这个必要,但本地部署最终要的是能解决数据隐私的问题。
第一步 :安装 Ollama
Ollama 是个啥?你可以叫它「欧拉马」,可以理解成是个自己电脑上运行大语言模型的容器,开源,免费,不用联网。
这玩意怎么下?
要么直接搜索 Ollama;要么,就直接点击这个链接:https://ollama.com ,就可进入官网:
通过网盘分享的文件:Ollama
链接: https://pan.baidu.com/s/1HhgVAWiNjaEdH7Vl9VolCw?pwd=1234 提取码: 1234
 选择要下载的版本
选择要下载的版本
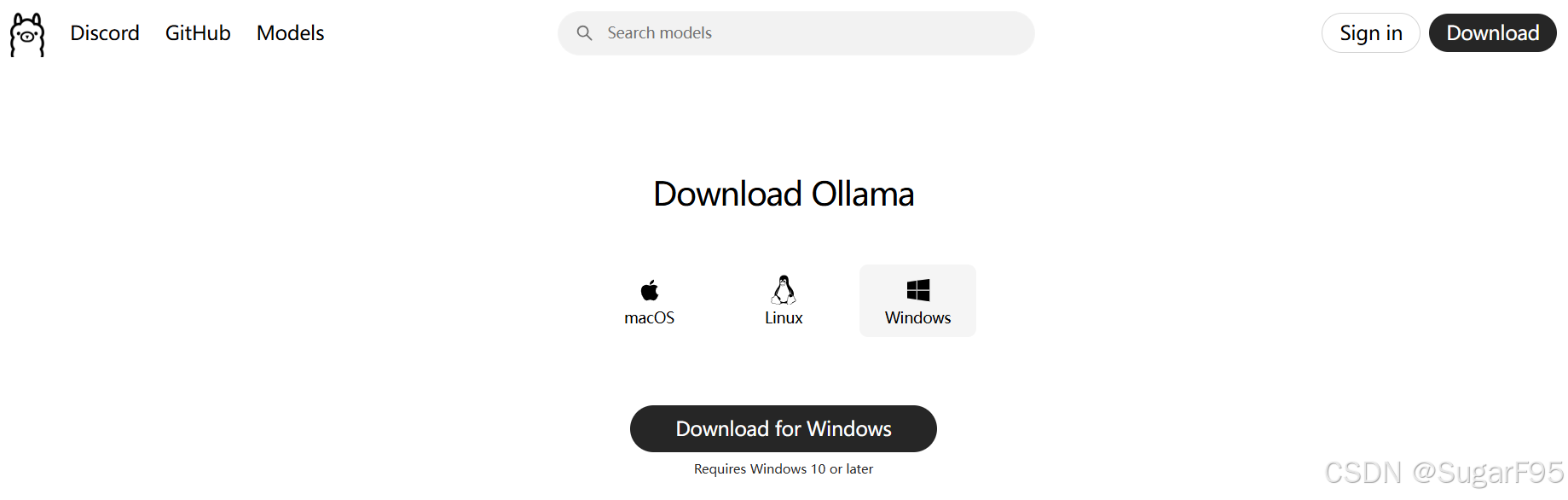
下载好后,直接点击对应的 app 运行:
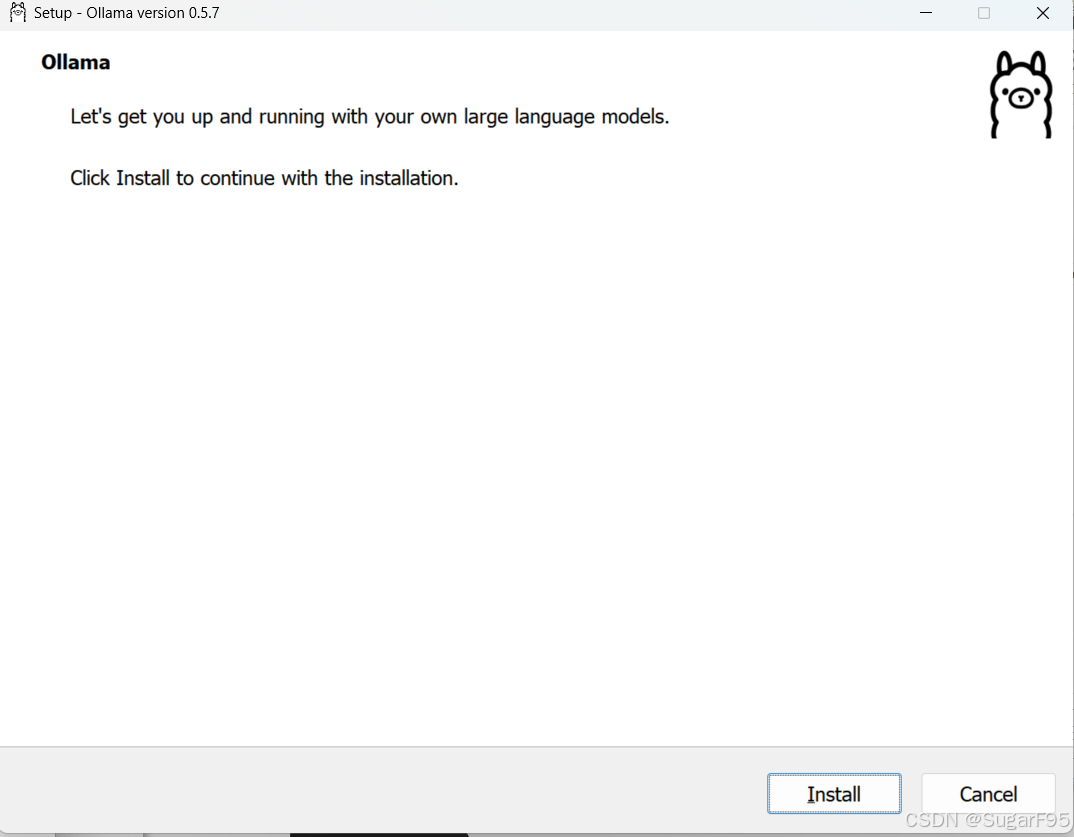
点击安装,
如果你是 macos,就可以在菜单栏看到 Ollama 的小图标啦,这表明基础环境已经 ok。
第二步:下载 DeepSeek-R 1 模型
还是打开刚才的 Ollama 官网,进入「Models」页面。
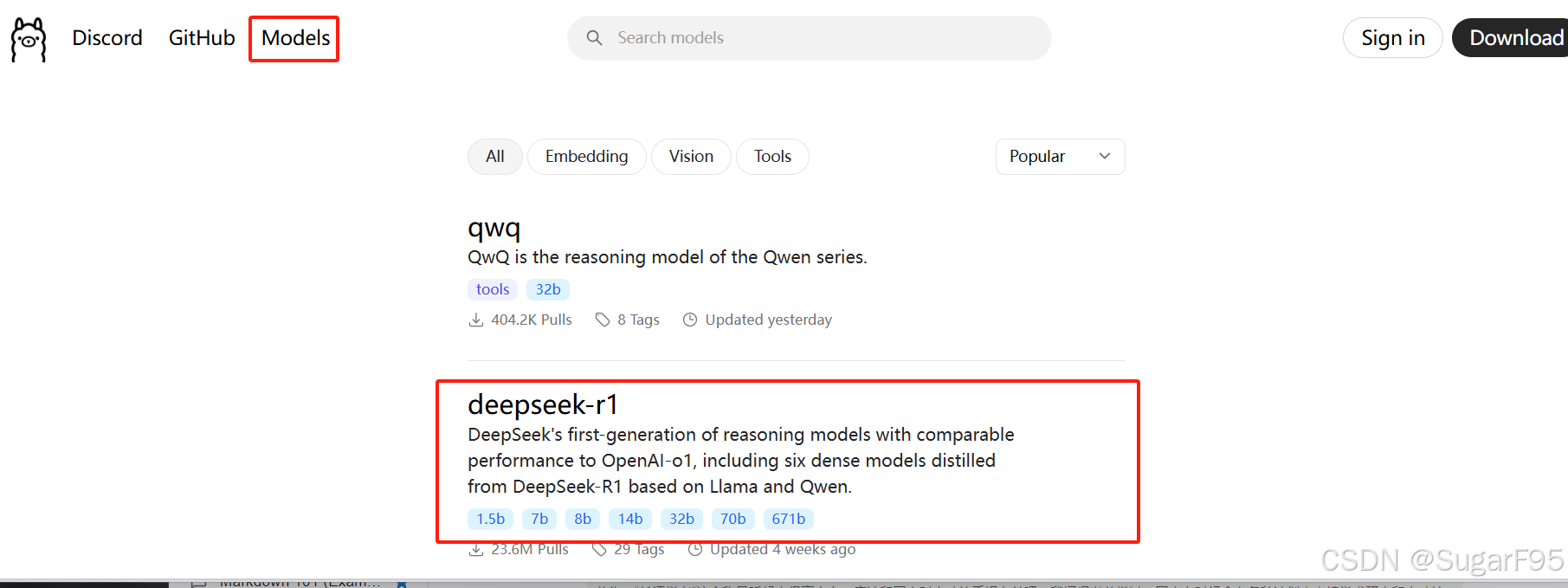
直接根据自己电脑配置选择对应参数的模型下载:
那你肯定会问,我电脑该选择哪个尺寸的下载呢?1.5b、7b、8b、14b 这些是啥?
1.5b 这些其实是大语言模型的参数规模,单位是 billion,B,即十亿。
比如 1.5b 就代表是 15亿参数。
一般来说,参数越多,模型的能力越强,但计算资源需求也越大。如果你看到这些数字,基本可以理解成这是某个AI模型的体型大小。
需要先确定自己的内存大小及存储,一般来说,模型参数越大,所需的计算资源和内存也越多。
如果您的设备内存为 8 GB,建议选择 1.5 B 或 7 B 模型,以确保模型能够流畅运行。如果您的设备内存为 16 GB 或更高,可以考虑选择 8 B 或 14 B 模型。至于 32 B 模型,可能需要更高的硬件配置才能流畅运行。
ollama run deepseek-r1:8b
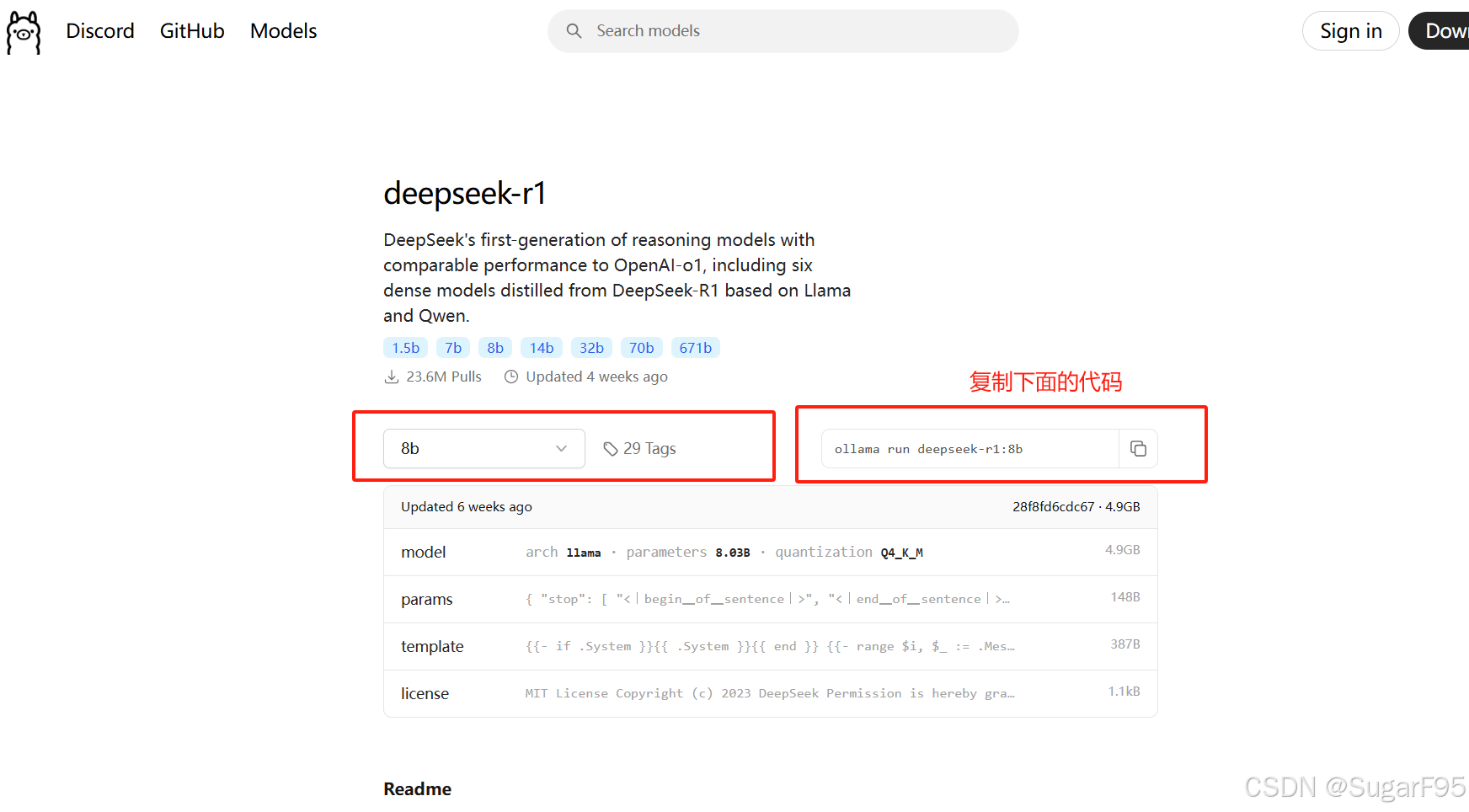
打开电脑终端

出现这样,就表示已经部署完成:
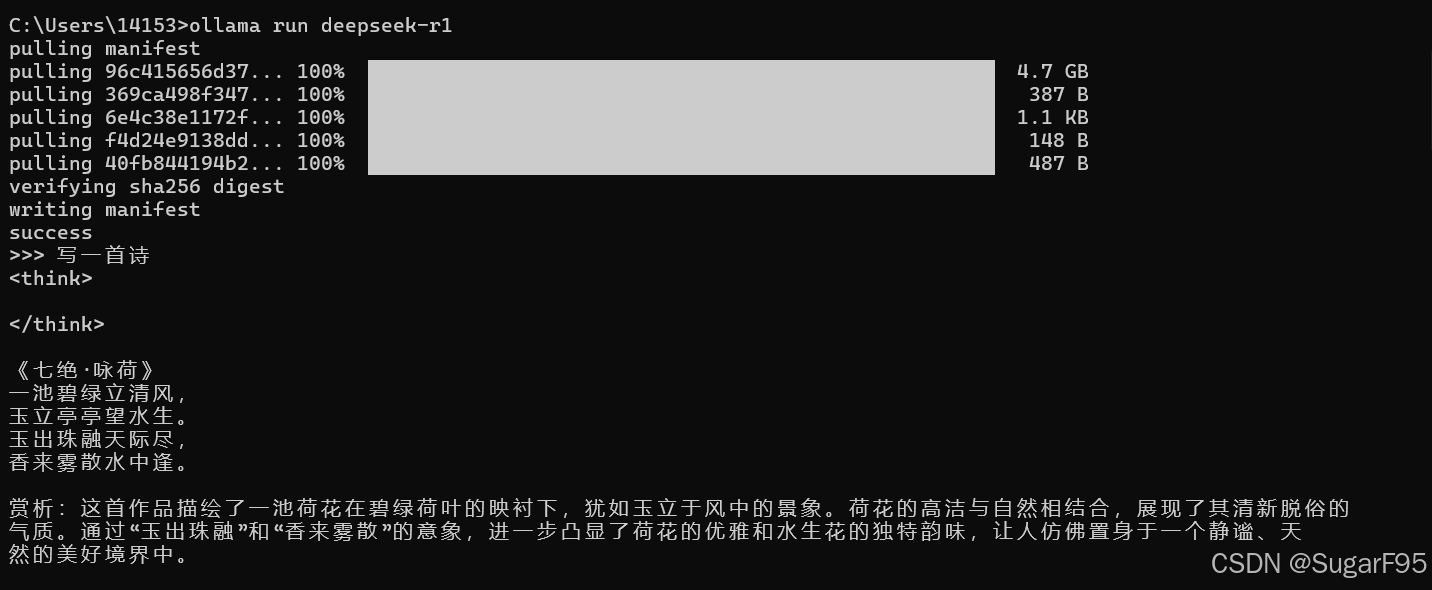
ollama run deepseek-r1 启动
/bye to exit 关闭
第三步:搭建 Chatbox 界面
这命令行对于不会编程的小伙伴来说,太难受了。
不过没关系,开源的 Chatbox 就可以解决这个问题,你可以理解成他是个好看的 UI 界面搭载的应用程序,让你和大模型对话就像呼吸空气一样自然🉑
使用方法也很简单,下面简单介绍一下:
1、下载并安装客户端
打开官网直接下载:**https://chatboxai.app/zh
打开后是这样的,
选择使用自己的 API Key 或者本地模型:
选择 Ollama API

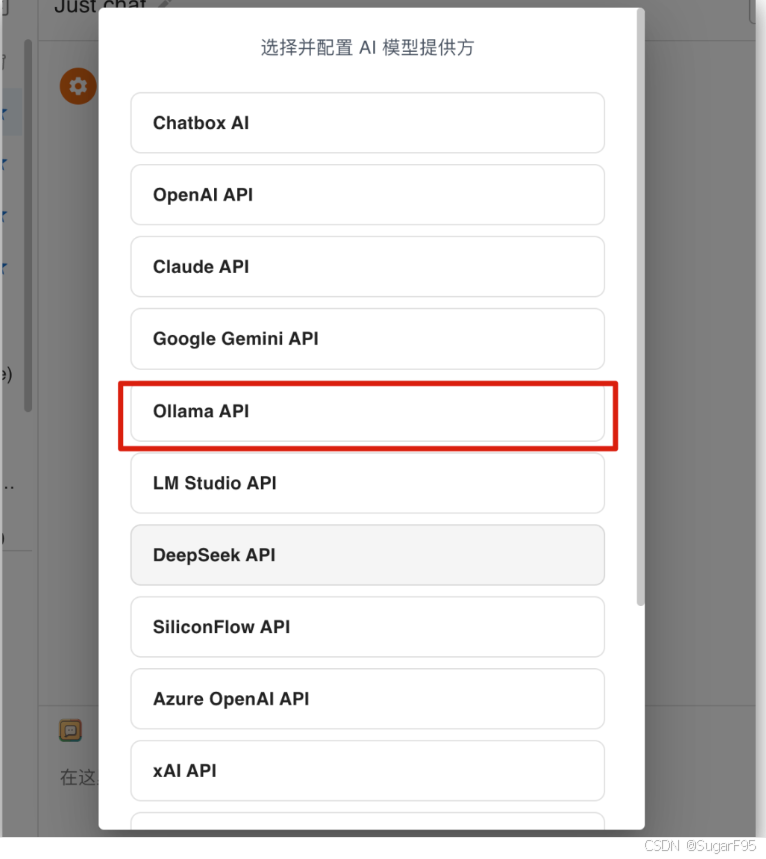
打开后可以自行设置参数
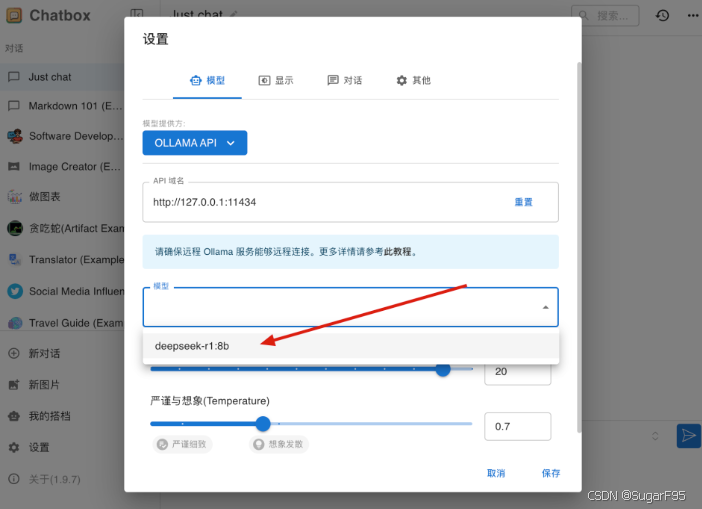
也可以自己设置头像
然后就可以自行使用UI界面了
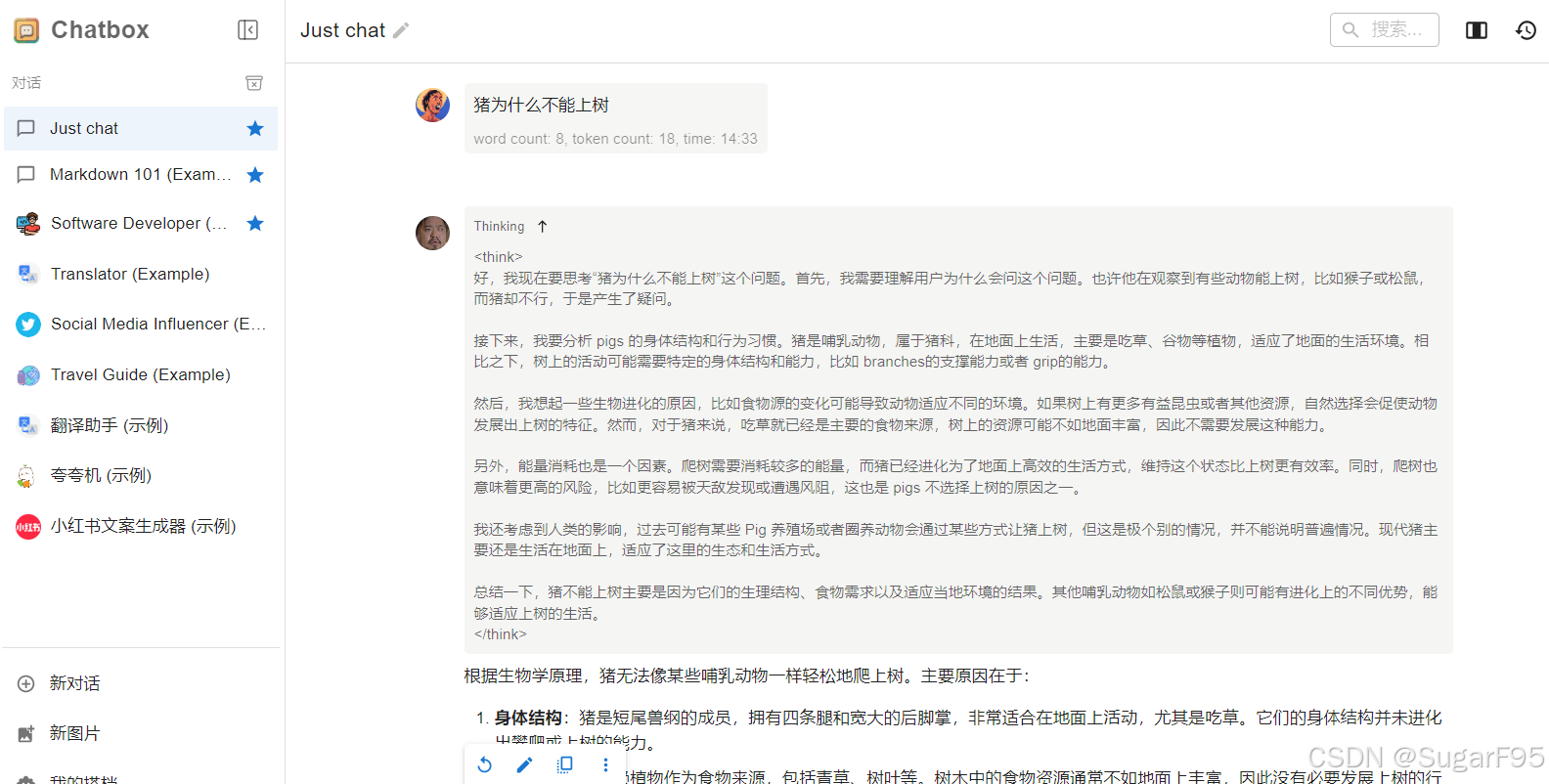
至此,简单三步,本地就运安装运行起来了 DeepSeek R1。
但这个时候,在你本地跑的只是个小 baby,他并没有像官方一样智能,只能处理简单的任务。
不过如果只是单纯的做自己知识库助手,也够了,毕竟本地的数据也就这么多。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)