320 亿参数 “小个子” 逆袭,QwQ-32B 成大模型界新宠
新模型的发布总是能吸引众多目光,而的出现,无疑是一颗重磅炸弹,瞬间引发了广泛的关注和热议😎。这款由阿里旗下通义千问 Qwen 团队推出的推理模型,拥有 320 亿参数,却在性能上展现出了令人惊叹的实力,可与具备 6710 亿参数(其中 370 亿被激活)的 DeepSeek-R1 相媲美,堪称大模型界的一匹新 “黑马”🐎。在如今这个参数竞赛激烈的大模型时代,大家往往认为模型参数越多,性能就越强
在大模型领域,新模型的发布总是能吸引众多目光,而 QwQ-32B 的出现,无疑是一颗重磅炸弹,瞬间引发了广泛的关注和热议😎。这款由阿里旗下通义千问 Qwen 团队推出的推理模型,拥有 320 亿参数,却在性能上展现出了令人惊叹的实力,可与具备 6710 亿参数(其中 370 亿被激活)的 DeepSeek-R1 相媲美,堪称大模型界的一匹新 “黑马”🐎。

在如今这个参数竞赛激烈的大模型时代,大家往往认为模型参数越多,性能就越强。但 QwQ-32B 打破了这种常规认知,它以相对较少的参数实现了卓越的性能,就像是一个小个子却有着巨大能量的超级英雄。这不仅让人们对大模型的发展有了新的思考,也为行业带来了新的活力和可能性✨。 它在一系列基准测试中的表现,更是让其成为了众人瞩目的焦点。
一探 QwQ-32B 的技术 “内核”
QwQ-32B 能够在众多大模型中崭露头角,其背后的技术功不可没。下面,就让我们一起深入探究 QwQ-32B 的技术 “内核”,看看它是如何实现如此卓越的性能的🧐。
(一)强化学习:性能飞跃的 “密码”
QwQ-32B 的研发团队另辟蹊径,从冷启动检查点开始,实施了由结果导向奖励(Outcome Based Reward)驱动的强化学习(RL)扩展方法,为模型性能的提升找到了关键 “密码”🔑。
在初始阶段,团队专门针对数学和编码任务扩展强化学习。与传统依赖奖励模型的方式不同,他们采用了更为直接有效的反馈机制:利用数学问题准确性验证器来确保最终解决方案的正确性,就像一位严格的数学老师,仔细检查每一道题的答案是否正确;同时使用代码执行服务器来评估生成的代码是否成功通过预定义的测试用例,只有通过测试的代码才会得到奖励,这使得模型在数学和编程领域的能力得到了针对性的提升。随着训练轮次的推进,这两个领域的性能都呈现出持续提升的良好态势。
当数学和编程能力达到一定水平后,就进入了第二阶段,也就是扩展阶段。这一阶段,团队增加了针对通用能力的 RL 训练,使用来自通用奖励模型的奖励和一些基于规则的验证器进行训练。通过这种方式,模型在保持数学和编程能力的同时,其他通用能力,如指令遵循、与人类偏好的一致性以及智能体性能等,也都得到了显著提高。这就好比一个学生,不仅在数学和编程这两门学科上成绩优异,其他各科也全面发展,成为了一名综合素质优秀的学生🎓。
(二)参数与规模:小身材,大能量
在大模型的世界里,参数数量常常被视为衡量模型能力的重要指标。通常情况下,人们会认为参数越多,模型的能力就越强。然而,QwQ-32B 却打破了这一常规认知。它仅拥有 320 亿参数,与拥有 6710 亿参数(其中 370 亿被激活)的 DeepSeek-R1 相比,参数数量仅约为其 1/20,就像是一个小个子站在了巨人身边。但就是这个小个子,却展现出了与巨人相媲美的性能,在多项关键评测中表现卓越,这不得不让人惊叹🤩。
这背后的奥秘,正是强化学习发挥了关键作用。通过创新的强化学习训练策略,QwQ-32B 能够更加高效地利用这些参数,使得每一个参数都物尽其用。就像一支训练有素的军队,虽然人数不多,但每个士兵都训练有素、协同作战,能够发挥出远超人数规模的战斗力💪。这种以较少参数实现高性能的特点,不仅降低了模型的训练成本和计算资源需求,也为大模型的发展提供了新的思路和方向。
(三)智能体集成:思考与反馈的进化
除了强化学习和高效的参数利用,QwQ-32B 还集成了与智能体(Agent)相关的能力,这使得它在推理过程中能够像人类一样进行批判性思考,并根据环境反馈调整推理,实现了思考与反馈的进化🧠。
在实际应用中,当 QwQ-32B 面对一个问题时,它会利用自身集成的智能体能力,结合环境信息和已有的知识,进行深入的思考和分析。例如,在解决一个复杂的科学问题时,它不仅能够运用所学的科学知识进行推理,还能根据问题的背景信息和用户的反馈,不断调整自己的思考方向和方法,最终给出更加准确和合理的答案。这种根据环境反馈调整推理的能力,使得 QwQ-32B 在处理各种复杂任务时,能够更加灵活和智能,大大提升了其实际应用价值。
实测见真章:QwQ-32B 的实力验证
理论上的优势固然重要,但实际表现才是检验大模型能力的关键。那么,QwQ-32B 在实际的基准测试和应用中,又有着怎样的表现呢🧐?让我们一起来看看。
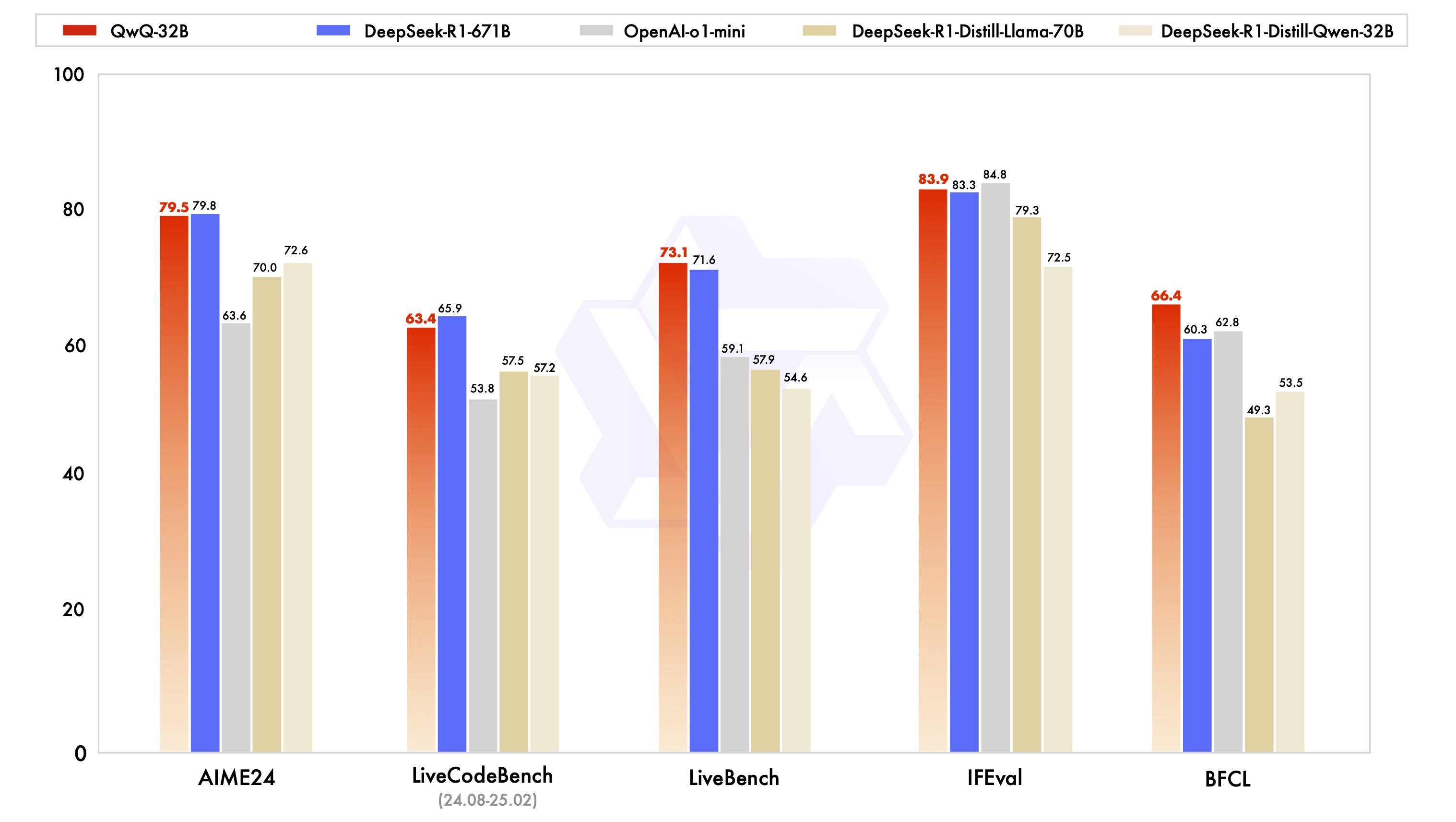
(一)基准测试结果解读
为了全面评估 QwQ-32B 的能力,研究团队对其进行了一系列严格的基准测试,涵盖了数学推理、编程能力、通用能力等多个关键领域,并与 DeepSeek-R1 等其他领先模型进行了对比。结果显示,QwQ-32B 在各项测试中都表现出了令人瞩目的实力💪。
在数学推理方面,QwQ-32B 在 AIME24 评测集中取得了与 DeepSeek-R1 相当的成绩,展现出了强大的数学思维和解题能力。无论是复杂的代数方程,还是抽象的几何问题,QwQ-32B 都能抽丝剥茧,准确地找到答案。例如,在解决一道涉及多元函数极值的数学题时,QwQ-32B 能够迅速运用所学的数学知识,通过合理的推理和计算,得出正确的结果,其解题思路清晰,步骤严谨,与 DeepSeek-R1 的表现不相上下,远胜于 o1-mini 等模型。
在编程能力的评估中,QwQ-32B 在 LiveCodeBench 测试中的表现同样出色,生成的代码质量颇高,通过测试用例验证的情况良好,和 DeepSeek-R1 处于同一水准。当给定一个实现特定功能的编程任务时,QwQ-32B 能够快速理解需求,运用多种编程语言,编写出高效、准确的代码。它不仅能够正确实现功能,还能在代码结构、注释规范等方面表现出色,展现出了专业级的编程水平。
在通用能力测试中,由 Meta 首席科学家杨立昆领衔的 “最难 LLMs 评测榜” LiveBench、谷歌等提出的指令遵循能力 IFEval 评测集、由加州大学伯克利分校等提出的评估准确调用函数或工具方面的 BFCL 测试中,QwQ-32B 更是脱颖而出,得分超越了 DeepSeek-R1。这表明 QwQ-32B 在理解和遵循指令、准确调用工具以及处理复杂任务等方面具有更强的能力,能够更好地满足用户在各种实际场景中的需求。
代码示例:手把手教你使用 QwQ-32B
了解了 QwQ-32B 的强大能力后,你是不是迫不及待地想要亲自体验一下呢🧐?别着急,下面就为大家提供两种常见的使用方式及代码示例,让你轻松上手。
(一)Hugging Face Transformers 调用
Hugging Face Transformers 是一个广泛使用的自然语言处理库,提供了丰富的工具和模型,方便我们进行各种文本处理任务。通过这个库,我们可以很方便地调用 QwQ-32B 模型。
from transformers import AutoModelForCausalLM, AutoTokenizer
# 模型名称
model_name = "Qwen/QwQ-32B"
# 从预训练模型中加载模型,设置数据类型为自动,设备映射为自动
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# 从预训练模型中加载分词器
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 用户输入的问题
prompt = "How many r's are in the word \"strawberry\""
# 构建消息列表,这里只有用户的问题
messages = [
{"role": "user", "content": prompt}
]
# 应用聊天模板,生成模型输入文本,不进行分词,添加生成提示
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
# 将输入文本转换为模型所需的张量形式,并移动到模型所在设备上
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# 使用模型生成回答,设置最大新生成的令牌数为32768
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
# 从生成的令牌ID中提取新生成的部分
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
# 将生成的令牌ID解码为文本
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
# 打印回答
print(response)
(二)阿里云 DashScope API 使用
除了使用 Hugging Face Transformers 库,我们还可以通过阿里云 DashScope API 来使用 QwQ-32B 模型,这种方式更加便捷,适合在云端环境中使用。
from openai import OpenAI
import os
# 初始化OpenAI客户端,设置API密钥和基础URL
client = OpenAI(
# 如果环境变量未配置,替换为你的API Key: api_key="sk-xxx"
# 如何获取API Key:https://help.aliyun.com/zh/model-studio/developer-reference/get-api-key
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
# 初始化推理内容和回答内容
reasoning_content = ""
content = ""
# 标记是否开始回答
is_answering = False
# 使用模型生成回答,设置模型为qwq-32b,传入用户问题,启用流式输出
completion = client.chat.completions.create(
model="qwq-32b",
messages=[
{"role": "user", "content": "Which is larger, 9.9 or 9.11?"}
],
stream=True,
# 取消注释以下行以在最后一个块中返回令牌使用情况
# stream_options={
# "include_usage": True
# }
)
print("\n" + "=" * 20 + "reasoning content" + "=" * 20 + "\n")
# 处理流式输出的回答
for chunk in completion:
# 如果chunk.choices为空,打印令牌使用情况
if not chunk.choices:
print("\nUsage:")
print(chunk.usage)
else:
delta = chunk.choices[0].delta
# 打印推理内容
if hasattr(delta,'reasoning_content') and delta.reasoning_content is not None:
print(delta.reasoning_content, end='', flush=True)
reasoning_content += delta.reasoning_content
else:
if delta.content != "" and is_answering is False:
print("\n" + "=" * 20 + "content" + "=" * 20 + "\n")
is_answering = True
# 打印回答内容
print(delta.content, end='', flush=True)
content += delta.content
未来可期:QwQ-32B 的展望与影响
(一)Qwen 团队的未来规划
QwQ-32B 的推出,仅仅是 Qwen 团队在人工智能领域探索征程中的一个重要里程碑,而他们的目光早已投向了更为广阔的未来。在后续的研究与开发中,Qwen 团队有着一系列宏伟且极具前瞻性的规划📈。
从模型优化的角度来看,团队计划进一步挖掘强化学习的潜力,不断完善 QwQ-32B 的训练算法。他们将致力于优化模型的奖励机制,使其能够更加精准地引导模型学习,提高学习效率和效果。通过更深入地研究强化学习中的各种技术细节,如如何更好地平衡探索与利用、如何优化策略梯度的计算等,团队期望能够让 QwQ-32B 在面对各种复杂任务时,表现得更加出色,实现更高的性能提升。
在能力扩展方面,团队积极探索将智能体与强化学习深度集成的可能性,以实现长时推理。这意味着 QwQ-32B 将能够处理更加复杂、长期的任务,不仅仅局限于当前的短期问题求解。例如,在智能决策领域,它可以模拟人类的长期规划思维,为企业制定战略决策提供更具前瞻性和全面性的建议;在科学研究领域,它能够对复杂的科学问题进行持续深入的分析和推理,辅助科学家进行更深入的研究。
Qwen 团队还计划将 QwQ-32B 与更多的领域知识相结合,拓展其应用范围。比如,在医疗领域,与医学知识图谱相结合,帮助医生

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 32
32 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)