使用NVIDIA RTX A6000两卡 跑QwQ-32B(推理能力比肩满血Deepseek R1)
阿里云Qwen团队发布了其最新研究成果QwQ-32B推理模型,该成果通过大规模强化学习技术突破性地提升了语言模型的智能水平。我利用公司的的A6000,实现单节点2卡跑通这个推理模型。这个推理模型比蒸馏版本的Qwen-32B要强的多,相当于满血版的DeepSeekR1。
1. 安装方法
- 使用modelscope下载模型
pip install modelscope
modelscope download --model "Qwen/QwQ-32B" --cache_dir "/models"
- 安装vllm
pip install vllm
- 启动
vllm serve "/models/Qwen/QwQ-32B/"
--served-model-name "qwq-32b"
--enable-auto-tool-choice
--tool-call-parser hermes
--max-model-len 81000
--tensor-parallel-size 2
--port 8080
请根据显存的大小来设置max-model-len过大有可能oom
2. 能力测试
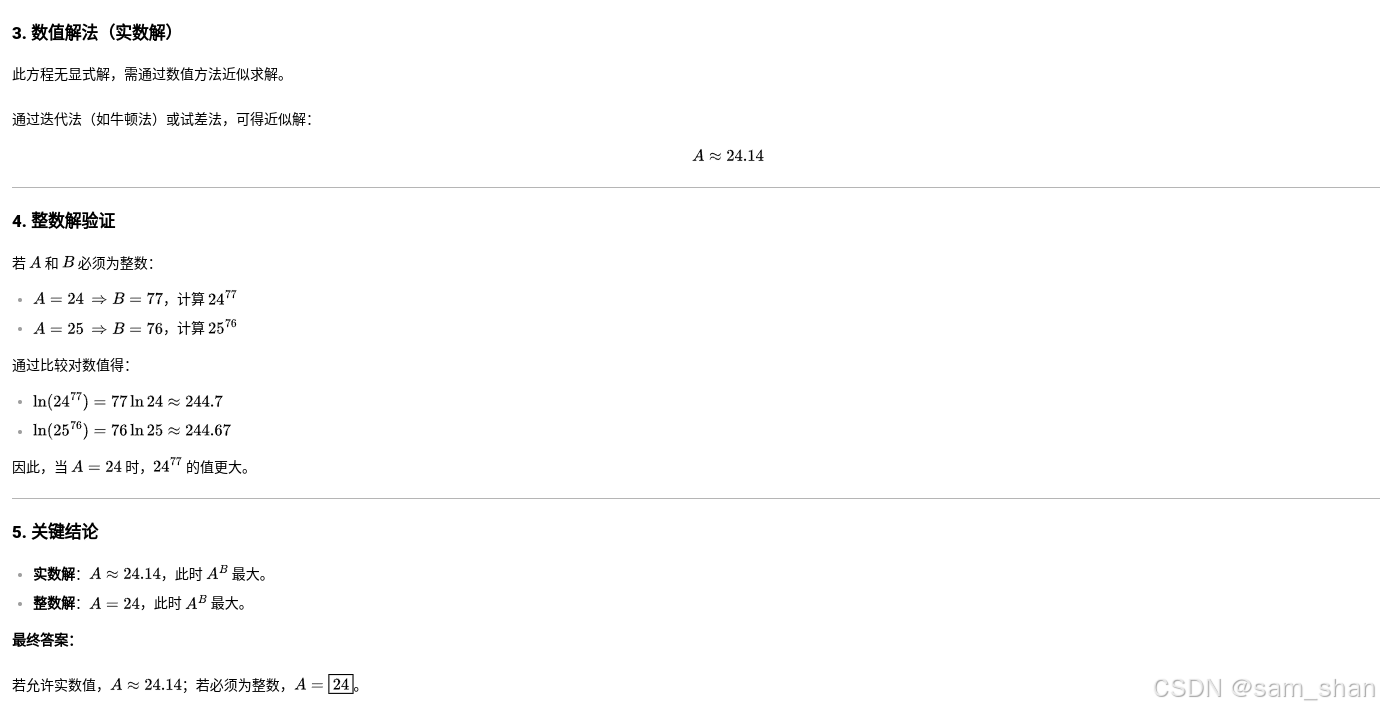
下面这个问题,蒸馏版本的32B可是推理不出来的。
问题: A+B=101 求A的B次方最大时A的取值
回答:
3. 性能测试

平均:20 tokens/s, 与Qwen2.5-32B的模型性能差不多。
一个小公司或者小团队完全够用了。同级别的L20也可以跑通,性能也不错。
以下使用R1生成的AI推理服务器配置清单,小伙伴们还等什么呀。
NVIDIA RTX A6000双卡配置清单
1. 核心计算组件
• 显卡:NVIDIA RTX A6000 ×2
• 显存容量:48GB/卡,支持FP16/FP32精度,支持NVLink桥接实现显存共享
• 性能定位:适合训练20B以下参数模型(FP16精度),或通过量化技术(如8-bit)运行30B-70B模型
• 参考单价:34,899元/卡
• 总价:69,798元
• CPU:AMD Ryzen Threadripper PRO 5995WX(32核64线程)
• 作用:支持多PCIe 4.0通道(128条),避免显卡带宽瓶颈
• 参考价:32,000元
• 主板:华硕Pro WS WRX80E-SAGE SE WIFI
• 特性:支持双PCIe 4.0 x16插槽,8通道DDR4内存,10Gbps网口
• 参考价:9,500元
2. 内存与存储
• 内存:芝奇皇家戟 256GB(8×32GB DDR4 3600MHz)
• 作用:满足大模型数据预处理和CPU显存卸载需求
• 参考价:8,000元
• 存储:
• 主硬盘:三星990 PRO 2TB NVMe SSD(7,400MB/s)
◦ 用途:存放数据集和模型检查点
◦ 参考价:1,800元
• 扩展存储:希捷酷狼PRO 18TB HDD ×2(RAID 1备份)
◦ 参考价:7,000元
3. 电源与散热
• 电源:海盗船AX1600i(1600W 80PLUS钛金)
• 必要性:双A6000峰值功耗约600W,需冗余供电
• 参考价:4,500元
• 散热:
• CPU散热:猫头鹰NH-U14S TR4风冷
◦ 参考价:800元
• 机箱风扇:联力积木风扇 SL120 ×6(保障双显卡风道)
◦ 参考价:1,200元
4. 机箱与扩展
• 机箱:联力PC-O11 Dynamic XL(全塔式)
• 特性:支持E-ATX主板,8槽位兼容双显卡厚度
• 参考价:1,500元
• 其他:
• NVLink桥接器:NVIDIA RTX A6000专用桥接器
◦ 参考价:1,500元
总价格估算
| 组件 | 单价(元) | 数量 | 小计(元) |
|---|---|---|---|
| 显卡 | 34,899 | 2 | 69,798 |
| CPU | 32,000 | 1 | 32,000 |
| 主板 | 9,500 | 1 | 9,500 |
| 内存 | 8,000 | 1 | 8,000 |
| 主硬盘 | 1,800 | 1 | 1,800 |
| 扩展存储 | 3,500 | 2 | 7,000 |
| 电源 | 4,500 | 1 | 4,500 |
| 散热系统 | 2,000 | 1 | 2,000 |
| 机箱 | 1,500 | 1 | 1,500 |
| NVLink桥接器 | 1,500 | 1 | 1,500 |
| 总计 | 137,498元 |
关键配置解析
-
多卡性能优化:
• 通过NVLink实现显存池化,双卡总显存可达96GB(需框架支持如vLLM),可运行70B模型的8-bit量化版本(需70GB显存);
• 推荐使用DeepSpeed或PyTorch的模型并行策略,提升训练效率。 -
成本与性能平衡:
• 对比云服务(如16xA100成本约50美元/小时),本地部署更适合长期训练需求;
• 若预算有限,可先单卡运行,后期扩展至双卡。 -
扩展建议:
• 增加至4卡需更换主板为超微H12SSL系列,并升级电源至2000W以上;
• 对于千亿级模型,建议采用A100/H100集群或混合精度+量化方案。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)