【2025版】DeepSeek-R1量化策略实测,从零基础到精通,精通收藏这篇就够了!
结合量化投资:大语言模型从量化领域的日常工作到策略开发均有丰富应用场景:1)首先它可以帮助量化分析师高效实现代码构建,从策略逻辑到代码落地需要的开发周期可能会大大缩短。2)其次大语言模型可以通过检索论文网站帮助分析师快速查找最新的研究,快速提炼某一深度研究的主要观点,或结合某一领域大量资料形成专家知识库,便于对特定类型资料提问。3)在策略开发层面,

中金研究
DeepSeek-R1等大语言模型的快速进化和发展引起了投资者的广泛关注。本文尝试站在量化策略的角度探讨大模型如何助力投资,详细测试大模型在行业轮动、风格轮动和市场择时三大任务中的表现,并讨论目前大模型在量化策略开发中存在的局限性。

结合量化投资:大语言模型从量化领域的日常工作到策略开发均有丰富应用场景:1)首先它可以帮助量化分析师高效实现代码构建,从策略逻辑到代码落地需要的开发周期可能会大大缩短。2)其次大语言模型可以通过检索论文网站帮助分析师快速查找最新的研究,快速提炼某一深度研究的主要观点,或结合某一领域大量资料形成专家知识库,便于对特定类型资料提问。3)在策略开发层面,大语言模型和新闻、研报这类另类数据结合可以发挥更大的作用。
b)结合主动投资:对于非量化客户来说,用好大语言模型的关键在于明确大语言模型的长处与局限性。当前部分观点对于大模型的态度偏向两极:或认为大模型智能化非常超前,或认为大模型用处十分有限。我们认为当前大模型在金融领域的应用空间较大,但仍然只能作为协助者。因为大模型当前仍然有不少局限性,如大模型对于数字的准确度把握不足,知识库滞后,容易出现知识幻觉等。
671b标准版DeepSeek-R1在行业轮动任务上具有稳定超额
DeepSeek-R1(下文简称DeepSeek或DS-R1)模型基于MoE架构,通过大规模强化学习直接训练基座模型(V3)突破推理能力,其在数学、代码、自然语言推理等任务上,性能比肩 OpenAI o1 正式版。该模型的主要亮点在于使用强化学习算法大规模训练基座模型,无需监督微调(SFT)即可展现强大的推理能力,成功验证了强化学习在提升推理能力方面的可能性,为提升模型推理能力的提升开辟了新路径。
我们测试了本地部署的14b(140亿参数,下同)、70b和火山引擎提供的671b标准版DS-R1 API的表现,发现671b参数版的DS-R1在多项任务中优势明显,因此后续量化策略任务均采用该版本来测试。我们设计了三个经典的量化策略来测试其表现:**行业轮动、大小盘轮动和市场择时,样本外测试结果来看模型在行业轮动任务上表现更佳,1)2024年以来DeepSeek选择的行业多头组合相对全行业等权收益率超额22.3%,多次重复试验下效果较为稳定;**2)2024年以来大小盘轮动的策略胜率54.33%,相对等权的超额收益超过12%;3)市场择时方面2024年以来超额约18%,但稳定性稍弱。
截至2025年2月20日,DS-R1对2025年3月最新推荐持仓为传媒、计算机、电新、汽车、消费者服务、通信。我们认为大语言模型在行业配置任务上相对于选股和市场择时任务具有独特优势:选股任务需要判断的标的数量较多,且更聚焦微观信息;而择时受大量因素影响,涨跌难以用固定逻辑归纳总结。而行业涨跌更多受宏观政策和行业景气影响,传导逻辑更为清晰,行业标的数量也相对适中,大语言模型能更好发挥其处理宏观中观信息和逻辑推理的优势。
大模型的局限性:幻觉、随机性、遗忘和数据泄露
即使大模型发展迅速,但不免存在多种局限性。结合前文使用DeepSeek-R1构建多种量化策略的体验,我们发现大模型目前主要存在的局限性和问题包括幻觉、生产内容的随机性、上下文记忆长度的限制以及数据泄露,在量化策略开发中需要对此类风险额外注意。
在量化策略开发中上述局限性的影响显著:1)输出内容产生知识幻觉可能导致输出错误内容,直接导致模型失效;2)随机性可能导致量化模型的表现难以复现,且无法规定随机数种子来固定输出;3)上下文长度的限制使得输入数据完备性受到挑战,即使是满足上下文长度限制的较长文本也可能**引发模型在推理环节对远端信息产生遗忘;**4)对比来看数据泄露可能是其中更小的问题:使用较晚数据训练(例如知识库截至2023年10月)的大模型,无法保证不在2018年的滚动训练中使用未来数据,这使得滚动区分样本内外的方法失去严谨性。
风险提示:本文测试结果均依赖于历史数据,未来有失效风险;大模型可能会有知识幻觉问题,导致模型结果不准确。
Text
正文
DeepSeek构建基于新闻的量化模型
大模型结合新闻数据在量化策略任务的优势
DeepSeek-R1模型创新点的技术细节
DeepSeek之所以能引起市场如此广泛关注的重要原因之一在于它开源展示了更加底层的算法优化逻辑。DeepSeek-V3在仅消耗 Llama3 405B模型10%计算资源的条件下,实现了与其相当的运算效能,其技术突破源于三项架构革新:多头潜在注意力机制(Multi-head Latent Attention, MLA),动态路由混合专家系统(Dynamic MoE)及多粒度令牌预测(MTP)。
► 多头潜在注意力机制:通过低秩联合压缩键(Key)和值(Value)矩阵,显著减少推理时的键值缓存(KV Cache)内存占用,结合解耦旋转位置嵌入(RoPE)技术,在保持模型性能的同时提升计算效率。
► 动态路由混合专家系统:采用总参数量达671b的混合专家架构,但每个 token 仅激活 37B 参数,通过动态路由机制智能分配输入到不同专家模块,实现训练成本与模型性能的高效平衡。
► 多粒度令牌预测:在训练中引入多 token 预测目标,同时预测后续多个 token 的分布,通过辅助损失函数优化模型对长序列的建模能力,进一步提升训练效率和生成连贯性。
DeepSeek-R1 基于MoE架构,通过大规模强化学习直接训练基座模型(V3)突破推理能力,其在数学、代码、自然语言推理等任务上,性能比肩 OpenAI o1 正式版。**该模型的主要亮点在于使用强化学习算法大规模训练基座模型,无需监督微调(SFT)即可展现强大的推理能力,**成功验证了强化学习在提升推理能力方面的可能性,为提升模型推理能力的提升开辟了新路径。
使用DeepSeek构造量化模型的流程
前置条件
使用DeepSeek-R1有几种主要方法:
1. 调用官方API
具有简单快捷的优势。但官方API中不支持修改temperature, top_p等关键参数的取值,且连接经常出现超时等问题。
2. 调用第三方平台API
考虑到官方API及网页端经常由于“服务器繁忙”等原因无法保证持续交互,第三方平台如火山引擎、阿里云百炼等均提供671b版DeepSeek的API调用服务,因而本篇报告下一章节所展示的实验结果均来自于第三方平台支持的DeepSeek-R1模型。
3. 本地部署
以下是本地部署DeepSeek大语言模型的三种主要途径:
图表:本地部署DeepSeek的几种方案

资料来源:DeepSeek-R1,中金公司研究部
不同参数版本DeepSeek-R1模型的表现差异
为了对不同参数版本的Deep Seek-R1的能力有一个直观的了解,本文选择四类常见的问答类问题,考察模型对问题的理解、分析及推理能力。由下表可以看到671b版的DeepSeek-R1在逻辑推理、常识问题及脑筋急转弯任务中都能回答正确;相比之下,本地所部署的轻量级参数模型只能保证逻辑推理问题,常识问题及脑筋急转弯都有出错可能性。值得一提的是,DeepSeek-R1在处理与数字相关的计算分析任务的表现水平要弱于相同场景下对文本类数据的处理结果。
图表:DeepSeek-R1低参数版本性能下降明显

注:逻辑推理问题测试数量3,其余类型问题数量均为1
资料来源:DeepSeek-R1,中金公司研究部
图表:常识问题不同参数的DeepSeek-R1回答对比

资料来源:DeepSeek-R1,中金公司研究部
模型构造流程
我们采用数库的新闻数据作为DeepSeek提示词的主要信息源。考虑到该模型的训练数据截至2023年10月,为防止发生数据泄露,仅提取2024年及之后的新闻用于测试大模型量化策略的表现。目前DeepSeek-R1支持的最大上下文长度为64K (tokens),粗略估计可接受约3-5万个中文字符作为输入信息,无法支持直接使用数库月均40万条的新闻数据。
从两个维度对新闻进行筛选后,月度新闻的数量能够有效降低至3000条左右,并在一定程度上保证当月发生事件的完整性及有效性。具体来说,我们首先利用DeepSeek对数据库所有的新闻来源进行了分级,保留来自20个重要媒体的新闻,淘汰行业相关性低于0.45的信息。其次,仅保留月末最后一周的新闻标题,在保证新闻时效性之余,短小精炼的新闻标题相比摘要在有限的上下文长度内能够覆盖更加多元的新闻事件。
高效准确的提示词及合理的API接口参数设置能够引导模型生成更加符合预期的输出结果。我们在前期打磨提示词时发现,将任务拆分为步骤进行表述、展示输出样例、强制模型返回推理过程等细节能够有效提升DeepSeek的输出质量,并降低其幻觉出现的概率。此外还可以借助辅助工具如AIPRM、PromptPort等进行大模型提示词的自助生成,以进一步提升开发效率。
结合DeepSeek官方发布的R1使用建议[1],我们在API调用过程将温度参数(temperature)设置为0.6;信息列表(messages)中不涉及系统提示词;并在提示词中强制模型输出包含<思考>标签及思考过程,其余参数设置可参照下表。考虑到温度参数会引起大模型输出具有随机性,进而影响其构造的量化策略稳定性,本文将在最后一节“大模型的局限性及应对”中进行更为深入的探讨。
DeepSeek的调用流程可参照下图。本文采用单轮对话的方式,分月度将新闻标题数据及任务指令组合作为提示词调用大模型的API接口。由于大模型的输出可能存在幻觉(Hallucination[2]),需要对其结果进行基础格式及内容两方面的查验,若没问题则进行下一个月份的新闻数据及任务发布,否则需要重新执行当前任务,直至全部数据遍历完毕。相比网页端直接对话的方式,API调用的方法能够胜任批量处理数据的任务类型。
图表:DeepSeek-R1 API调用流程图
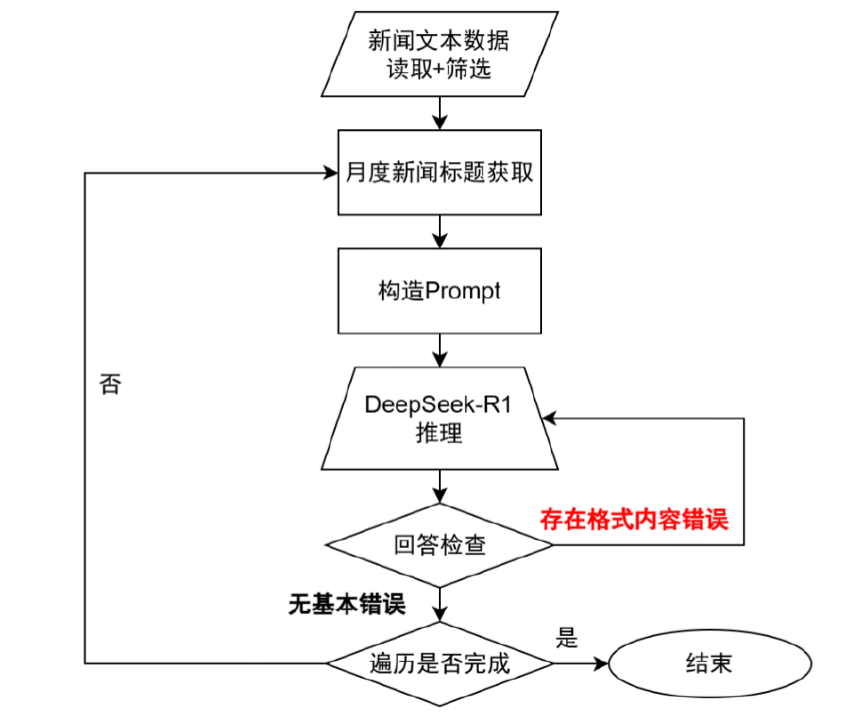
资料来源:中金公司研究部
回测效果展示:行业轮动超额22%
我们设计了三个经典的量化策略来测试DeepSeek-R1模型的表现:行业轮动、大小盘轮动和市场择时。测试结果来看模型在行业轮动任务上具有不错的表现。
行业轮动:样本外超额收益超22%
我们将该任务拆分为了六个具体的步骤,引导大模型从当月的新闻标题中提取涉及的行业及新闻情绪,预测中信一级30个行业下月的相对收益(范围在1~10以内的浮点数),并按照规定的格式输出思考过程及预测结果。具体的提示词内容可参照我们以2025年2月份的新闻数据构造的范例(下图所示),通过要求输出<思考>标签及过程,能够缓解模型绕过思考的问题;强调输出格式及内容要求,一定程度上可以缓解模型输出不充分的情况。
测试采用的数据区间为2024/01/01-2025/02/20,行业轮动策略的设定沿用《行业轮动系列(4):轮动节奏自适应行业轮动2.0模型》,根据DeepSeek-R1预测的行业得分降序排列,将排名前20%的行业等权构建多头组合,将得分最低的20%的行业等权构建空头组合。
图表:行业轮动任务中的提示词示例
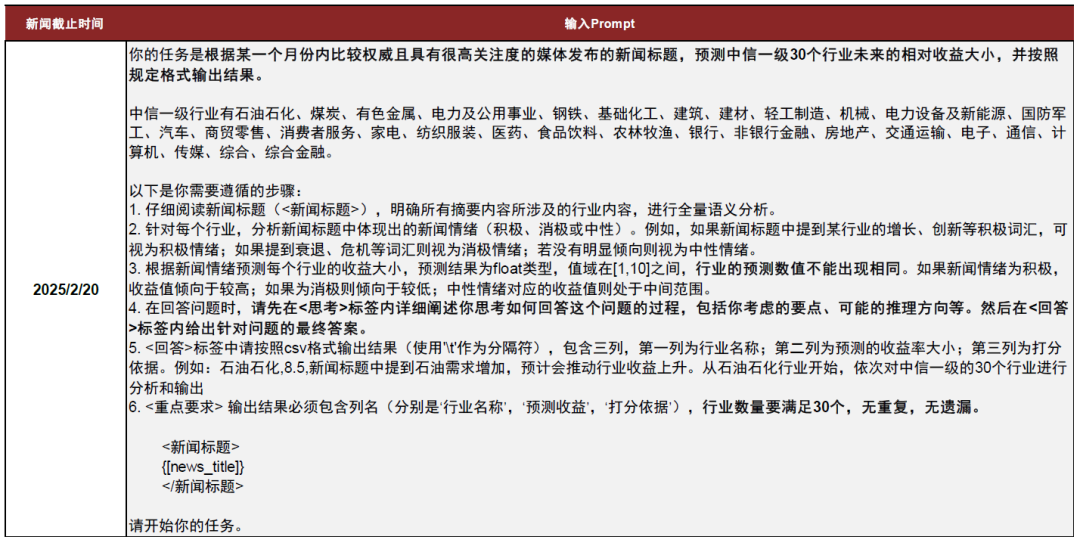
注:新闻数据(news_title)来源2025-02-01至2025-02-20
资料来源:中金公司研究部
**DeepSeek-R1模型在行业轮动任务样本外表现十分亮眼,超额收益达到22%,信息比率超1.8。**通过下图的组合净值序列可以看到,多头组合的超额收益回撤较小,整体较为稳定;从24年10月后出现明显增长,稳定战胜等权基准策略。
图表:DeepSeek-R1在行业轮动任务中表现亮眼
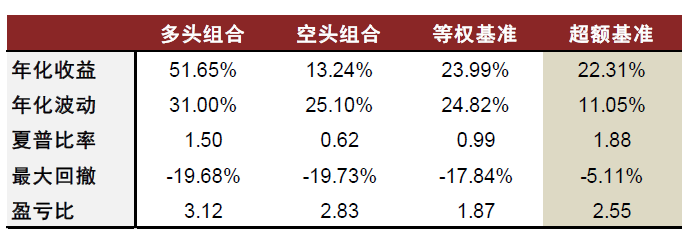
注:1)样本区间为 2024-01-01至2025-02-20;2)实验结果采用三次运行输出的平均值;3)超额收益相对基准为中信一级行业等权基准;4)所有收益均年化处理
资料来源:Wind,数库,中金公司研究部
图表:行业轮动任务样本外超额收益稳定
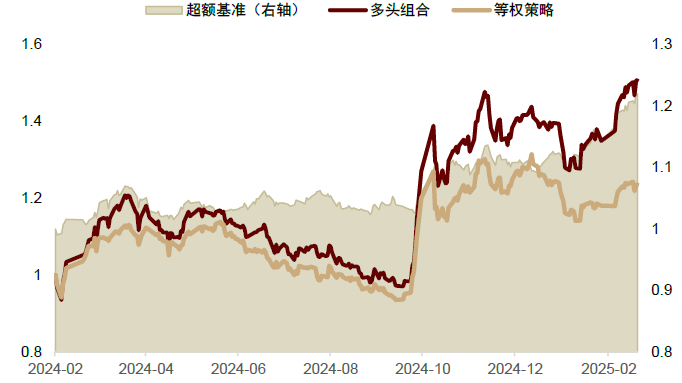
注:1)样本区间为 2024-01-01至2025-02-20;2)实验结果为三次运行输出平均值;3)超额收益相对基准为中信一级行业等权基准
资料来源:Wind,数库,中金公司研究部
下图展示的是样本外根据DeepSeek-R1预测结果进行持仓的行业明细,整体换手率偏低,为38.5%。**全时点多次看好电新、计算机、电子和汽车行业,这与24年以来新闻标题内容多围绕科技技术,创新制造等话题有关。**截至2025年2月20日,DeepSeek-R1对2025年3月最新推荐持仓为传媒、计算机、电新、汽车、消费者服务、通信。
图表:DeepSeek-R1在行业轮动任务中的持仓
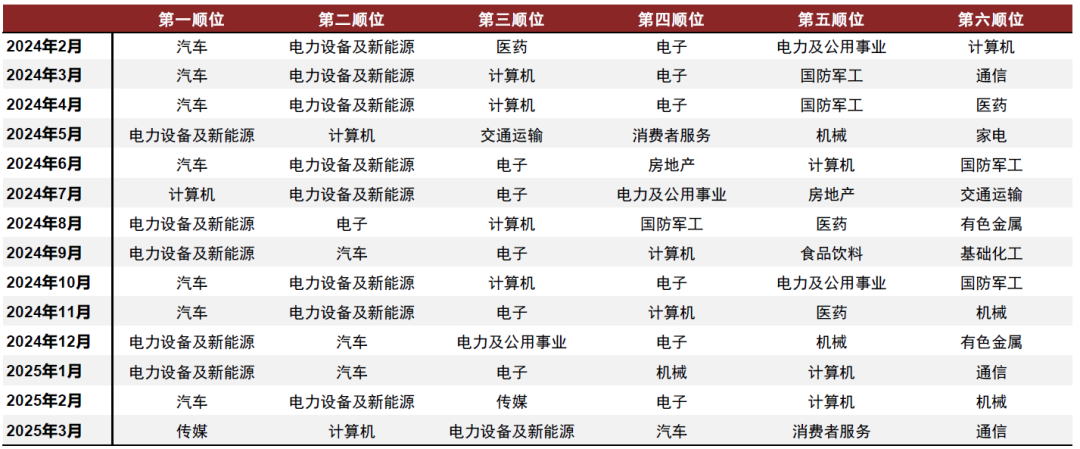
注:1)样本区间为 2024-01-01至2025-02-20;2)实验结果为三次运行输出平均值
资料来源:Wind,数库,中金公司研究部
下图展示的是输入最新月份的新闻数据标题,DeepSeek-R1预测未来收益排序前15名行业的得分及打分依据。可以看到,大模型对于新闻文本数据具有较好的理解、概括及分析能力,也使得行业轮动任务的预测结果相比其他深度学习模型具有更好的可解释性。
这里需要特别强调的是,由于温度参数设置为0.6,模型针对同一段上文所输出的下文存在差异,因此本节的回测结果均基于DeepSeek-R1三次预测平均值,以降低该策略的不确定性。
图表:DeepSeek-R1使用月度新闻预测收益及依据(前15名)展示
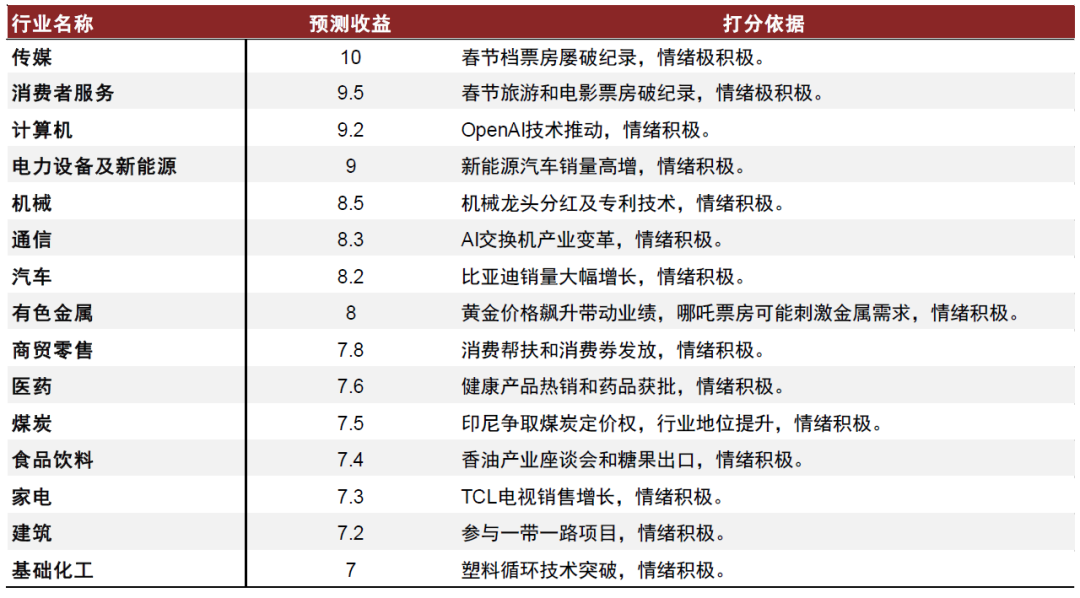
注:1)新闻数据来源2025-02-01至2025-02-20;2)DeepSeek单次输出结果
资料来源:Wind,数库,中金公司研究部
大模型的局限性:幻觉、随机性、遗忘和数据泄露
虽然大模型在诸多领域应用前景广泛,但目前在多个方面仍存在一定的局限性。结合前文使用DeepSeek-R1构建多种量化策略的经验,我们发现大模型目前主要存在的局限性和问题包括幻觉、生产内容的随机性、上下文记忆长度的限制以及数据泄露,在金融场景实际应用中需要对此类风险额外注意。
幻觉
香港科技大学的研究人员在论文《Survey of Hallucination in Natural Language Generation》中系统地探讨了自然语言处理模型所存在的幻觉(Hallucination)问题,它指的是模型所生成的内容是无意义的或不忠实于提供的源内容。**对于大语言模型来说,这种现象可能源于模型在生成文本时缺乏对事实的深刻理解,**导致其输出内容在语法和结构上是连贯的,但在事实准确性上存在问题。这种幻觉可能误导用户,影响模型在实际应用中的可靠性。
根据Vectara公司最新发布的截至2025年2月24日的大语言模型幻觉评测榜单结果[3],当前主流的AI模型在文本摘要任务中产生幻觉的概率分布在0.7%-3%之间,其中由Google的Gemini-2.0模型和OpenAI的o3模型幻觉产生概率最低,DeepSeek(最新的模型暂时未参与测试)早期发布的V2.5幻觉产生概率为2.4%,与OpenAI-o1模型水平大致相同。
Sukriti Gupta在论文《6 Techniques to Reduce Hallucinations in LLMs》探讨了改进的几种方式,例如采用高级规范的提示词,结合使用知识图谱和RAG等技术提升模型知识库容量等。
图表:大语言模型幻觉概率排名
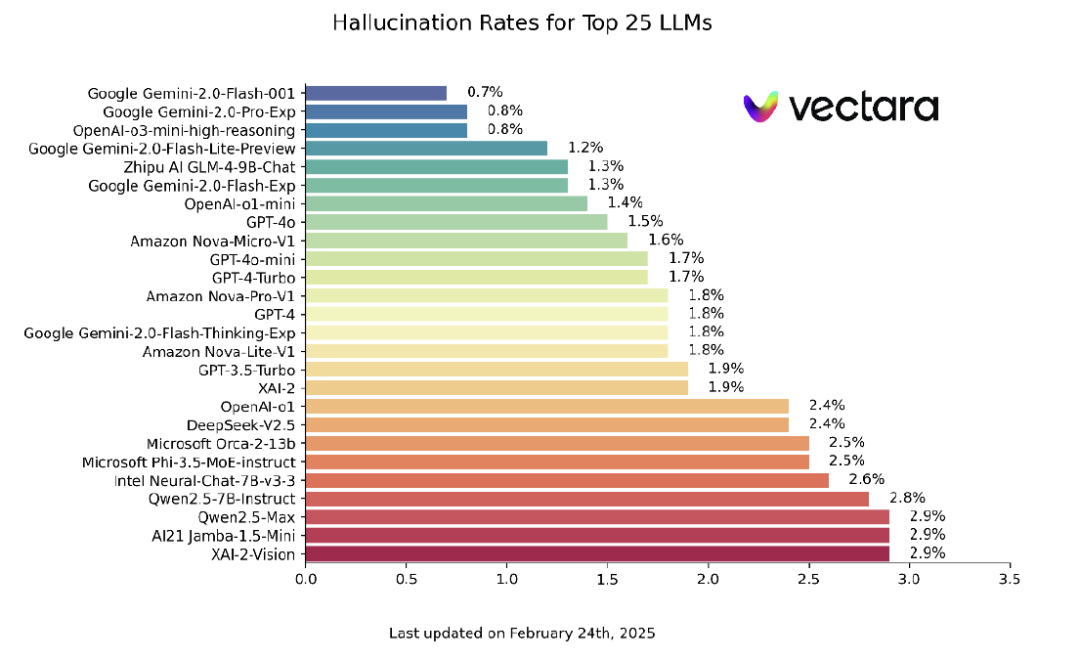
资料来源:vectara,中金公司研究部
随机性
作为生成式模型,大语言模型中的temperature等参数负责控制其输出的随机程度,其核心原理是通过调整模型预测概率分布的“平滑度”。通常来说,temperature取值接近0的温度参数,将放大高预测分数(logits)token的概率,使分布趋于尖锐(仅高概率词被选中),使输出更为确定;而取值接近1的温度参数,将压缩token预测值间的差异性,使输出更加随机。
在前文的行业轮动任务中,我们尝试使用temperature=0.6的设定控制DeepSeek-R1的调用过程。考虑到该参数对输出结果随机性的影响,我们重复了3次实验流程,将3次预测结果的平均值用于行业轮动策略的构建。下图展示了单次输出结果构建的策略在样本外的收益能力,可以看到虽然随机性对预测值产生了一定的影响,但均能战胜等权基准,具有超额收益。此外,我们也尝试探索不同temperature取值对模型性能的影响。实验结果表明,temperature的取值会干扰大模型预测结果构建行业轮动策略的性能好坏,但无直接相关性。
图表:DeepSeek-R1在行业轮动任务中的多头组合与等权基准收益净值曲线
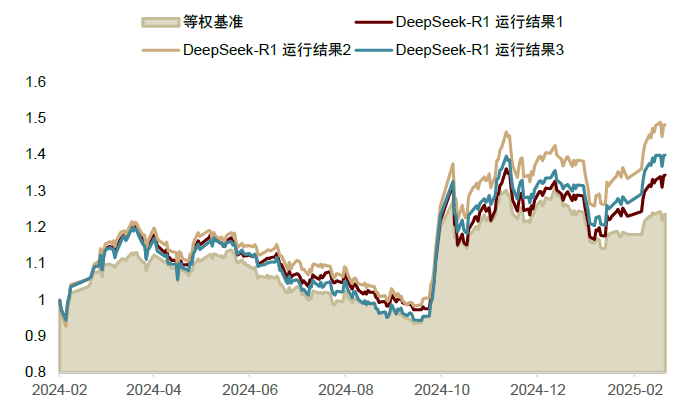
注:1)样本区间为 2024-01-01至2025-02-20;2)实验结果为三次运行输出;3)等权基准为中信一级行业等权;4)温度参数temperature=0.6
资料来源:Wind,数库,中金公司研究部
图表:DeepSeek-R1不同温度参数取值对行业轮动任务结果的影响
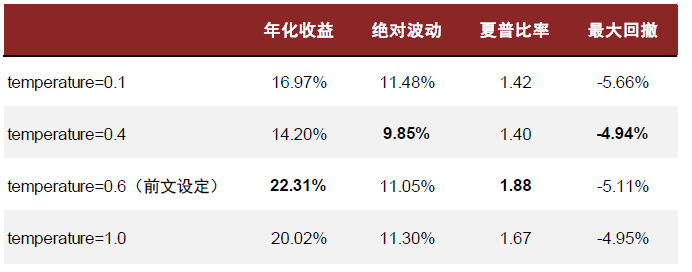
注:1)样本区间为 2024-01-01至2025-02-20;2)实验结果均为三次运行输出;3)等权基准为中信一级行业等权;
资料来源:Wind,数库,中金公司研究部
上下文长度限制
研究显示[4],**目前大语言模型在长文本处理中存在显著的系统性瓶颈。**当输入序列超过某一阈值时,模型对远端信息的记忆和调用能力急剧衰减,这种衰减在需要全局关联的推理任务中影响尤为显著。由于现有架构在计算资源分配机制上存在固有缺陷,难以支撑长距离依赖关系的有效建模,信息熵随序列长度呈指数级增长。随着上下文窗口扩展,模型的语义整合误差率将呈现非线性上升趋势。尤其是在涉及多层级推理的复杂场景中,现有模型仍无法避免关键信息的片段化丢失。
目前主流的大语言模型上下文长度水平在32-128k之间不等。本文所使用的DeepSeek-R1上下文长度则为64k,一定程度上限制了模型可接收的新闻数量。如前文所述,我们通过对新闻数据进行筛选实现压缩,保证了模型推理任务的正常进行。但不可否认的是,**上下文长度的限制使月度新闻数据的完整性及多样性遭到了损坏,即使是满足上下文长度限制的较长文本也可能引发模型在推理环节对远端信息产生遗忘,**从而影响其推理效果。
样本内数据泄露的可能性
论文《Evaluating Large Language Models on Academic Literature Understanding and Review: An Empirical Study among Early-stage Scholars[5]》发现,大语言模型在处理学术文献时存在隐私泄露风险:模型可能通过训练接收到敏感信息(如未发表成果、知识产权),并随着数据偏差从而进一步加剧信息泄露的风险。
在量化领域,模型的测试经常需要通过时间来区分样本内外,通过检测样本内外模型表现的一致性和稳定性来测试模型是否出现过拟合的问题。而在构建量化策略时,由于大模型已经使用了截至某一时刻的各类数据,很难保证策略样本内不会出现数据泄露的问题。例如将2019年的新闻数据输入给大语言模型,希望其判断2020年的市场走势时,大模型很有可能运用其截至2023年底的知识库,从而出现“偷看”问题答案的问题,这也是我们在上文仅测试2024年以来策略表现的主要原因。
[1]https://github.com/DeepSeek-ai/DeepSeek-R1, Readme, Usage Recommendations
[2]Hallucination:the generated content that is nonsensical or unfaithful to the provided source content.
JI Z, LEE N, FRIESKE R, et al. Survey of Hallucination in Natural Language Generation[J/OL]. ACM Computing Surveys, 2023
[3]https://github.com/vectara/hallucination-leaderboard
[4]Kuratov, Yury and Bulatov, et al., BABILong: Testing the Limits of LLMs with Long Context Reasoning-in-a-Haystack, NeurIPS, 2024
[5]Jiyao Wang, Haolong Hu, Zuyuan Wang, et al., Evaluating Large Language Models on Academic Literature Understanding and Review: An Empirical Study among Early-stage Scholars, CHI, 2024
## AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2025最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2025最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2025最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2025最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2025最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 23
23 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)