图灵奖得主推荐!强化学习2025必备创新思路!
先是DeepSeek把强化学习方法工程化,取得了目前为止最好的效果;再是强化学习之父获得了图灵奖,其不久前发布的论文Reward Centering,更是开启了领域的全新里程碑!不仅如此,在各大顶会其也是呈井喷状态,光是ICLR25就有十多篇。其中模型LS-Imagine、Kinetix更是拿下了Oral……由此可以窥见,2025发论文,强化学习的受追捧程度,想中稿的伙伴,可得抓紧了!目前热门的思
今年可真是强化学习的爆发年哇!先是DeepSeek把强化学习方法工程化,取得了目前为止最好的效果;再是强化学习之父获得了图灵奖,其不久前发布的论文Reward Centering,更是开启了领域的全新里程碑!
不仅如此,在各大顶会其也是呈井喷状态,光是ICLR25就有十多篇。其中模型LS-Imagine、Kinetix更是拿下了Oral……
由此可以窥见,2025发论文,强化学习的受追捧程度,想中稿的伙伴,可得抓紧了!目前热门的思路主要有:提升样本效率(课程学习+分层强化学习、元强化学习);多智能体协作设计;跨领域迁移学习;探索可解释性提升……
为方便大家研究的进行,每种思路都给大家准备了必读的顶会论文,共28篇,原文和源码都有!
论文原文+开源代码需要的同学看文末
Nature
Preserving and combining knowledge in robotic lifelong reinforcement learning
内容:这篇文章介绍了一种名为LEGION的机器人终身强化学习框架,旨在使机器人能够像人类一样持续积累知识并解决复杂任务。该框架通过贝叶斯非参数领域的狄利克雷过程混合模型(DPMM)和语言嵌入,实现知识的动态积累与长期记忆,同时避免了灾难性遗忘。实验表明,该框架能够在真实世界中通过语言指令完成多步复杂任务,并在多次训练循环中展现出快速的知识回忆和任务掌握能力,为实现通用人工智能提供了新的思路。
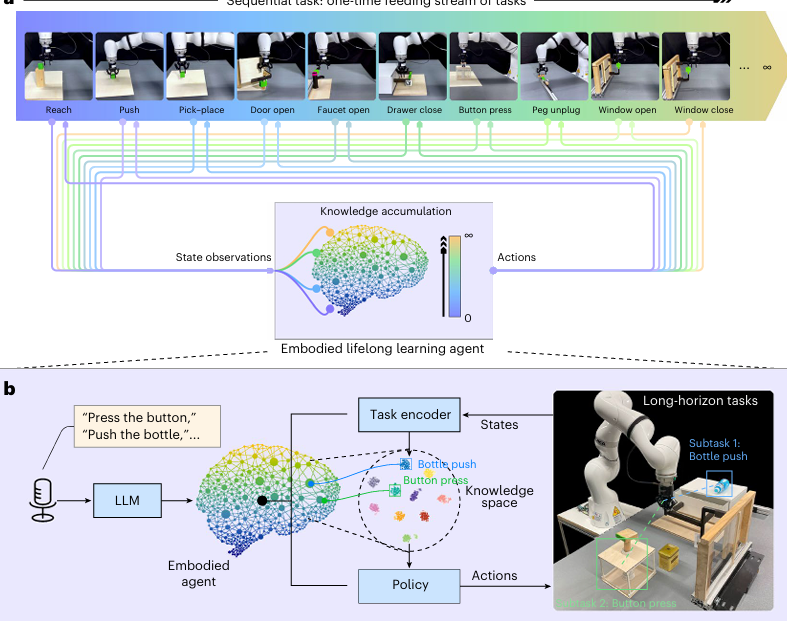
ICLR25 Oral
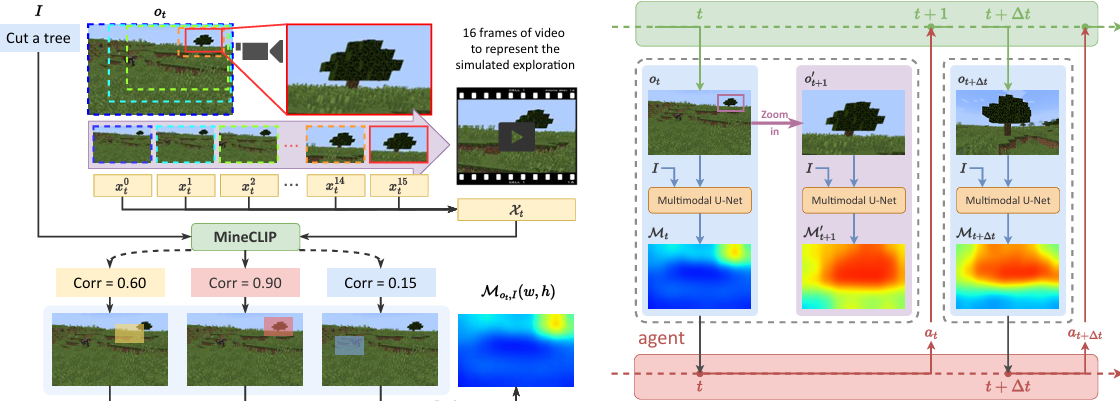
OPEN-WORLD REINFORCEMENT LEARNING OVER LONG SHORT-TERM IMAGINATION
内容:这篇文章介绍了一种名为LS-Imagine的新型模型基强化学习方法,旨在提高视觉强化学习代理在高维开放世界中的探索效率和样本效率。LS-Imagine通过构建一个长短期世界模型,模拟目标导向的跳跃状态转换,并结合视觉观察和任务描述生成的“可操作性地图”(affordance maps),将直接的长期价值融入行为学习中。该方法在《我的世界》(Minecraft)的MineDojo基准测试中表现出色,显著优于现有技术,尤其是在需要考虑长期回报的任务中。
NeurIPS24
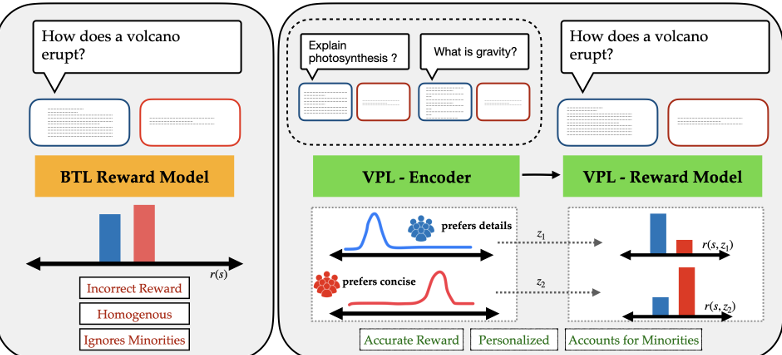
Personalizing Reinforcement Learning from Human Feedback with Variational Preference Learning
内容:本文提出了一种基于变分偏好学习的强化学习方法,用于从人类反馈中实现个性化学习。当前的人类反馈强化学习(RLHF)技术无法处理不同人群中的偏好差异,而是简单地对这些差异进行平均,导致对个体子群体的奖励不准确和性能不佳。为了解决这一问题,研究者们开发了一种多模态RLHF方法,通过潜在变量公式推断出特定于用户的潜在变量,并在此基础上学习奖励模型和策略,而无需额外的用户特定数据。实验表明,这种方法能够提高奖励函数的准确性,并在模拟控制问题和多元语言数据集上表现出色。此外,该方法还展示了在主动学习用户偏好方面的优势。
CVPR24
AlignSAM: Aligning Segment Anything Model to Open Context via Reinforcement Learning
内容:本文提出了一种新框架,旨在通过强化学习为 SAM自动生成提示,以适应开放环境中的多样化下游任务。AlignSAM 通过一个代理(agent)与基础模型交互,逐步优化分割预测,并引入语义重校准模块为提示提供精确的标签信息,从而提升模型处理显式和隐式语义任务的能力。实验表明,AlignSAM 在多个具有挑战性的分割任务中优于现有的先进方法,展示了其在不同场景下的适应性和优越性。
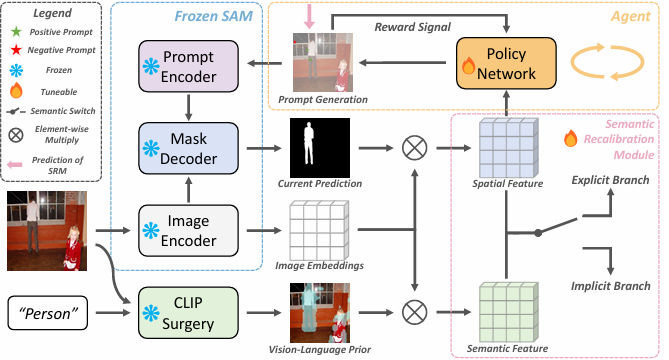
ICML24
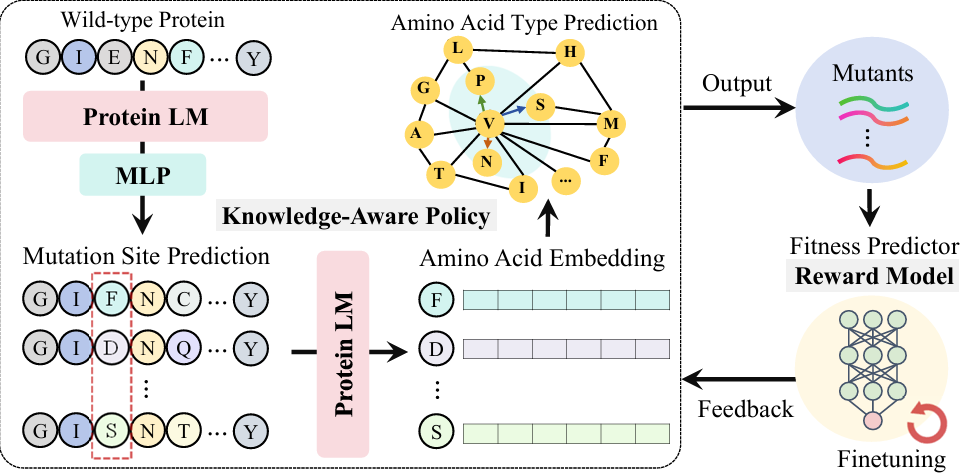
Knowledge-aware Reinforced Language Models for Protein Directed Evolution
内容:本文提出了一种名为KnowRLM的新方法,用于蛋白质定向进化。该方法通过构建氨基酸知识图谱(AAKG)来表示氨基酸之间的复杂生化关系,并引入基于蛋白质语言模型(PLM)的策略网络,通过在AAKG上进行优先随机游走来预测突变位点和类型。此外,KnowRLM 使用动态滑动窗口机制调整氨基酸探索范围,并通过主动学习方法优化整个系统,以模拟实际生物设置。
码字不易,欢迎大家点赞评论收藏!
关注下方《AI科研技术派》
回复【强化全新】获取完整论文
👇

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 20
20 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)