【云馨AI-大模型】320亿参数比肩6710亿:阿里QwQ-32B让消费级显卡跑出满血推理性能
北京时间3月6日凌晨,阿里巴巴正式发布并开源其最新研发的推理模型通义千问QwQ-32B。这款拥有320亿参数的模型不仅以1/20的参数量比肩DeepSeek-R1满血版的性能表现,更通过突破性技术革新实现了消费级显卡本地部署,标志着国产大模型在推理效率与普惠化应用领域取得重大突破。:通过两阶段强化学习训练(数学/编程专项强化+通用能力强化),仅用6710亿参数模型(DeepSeek-R1)5%的计
引言:AI推理领域迎来新标杆
北京时间3月6日凌晨,阿里巴巴正式发布并开源其最新研发的推理模型通义千问QwQ-32B。这款拥有320亿参数的模型不仅以1/20的参数量比肩DeepSeek-R1满血版的性能表现,更通过突破性技术革新实现了消费级显卡本地部署,标志着国产大模型在推理效率与普惠化应用领域取得重大突破。
一、性能突破:小体量蕴含大智慧
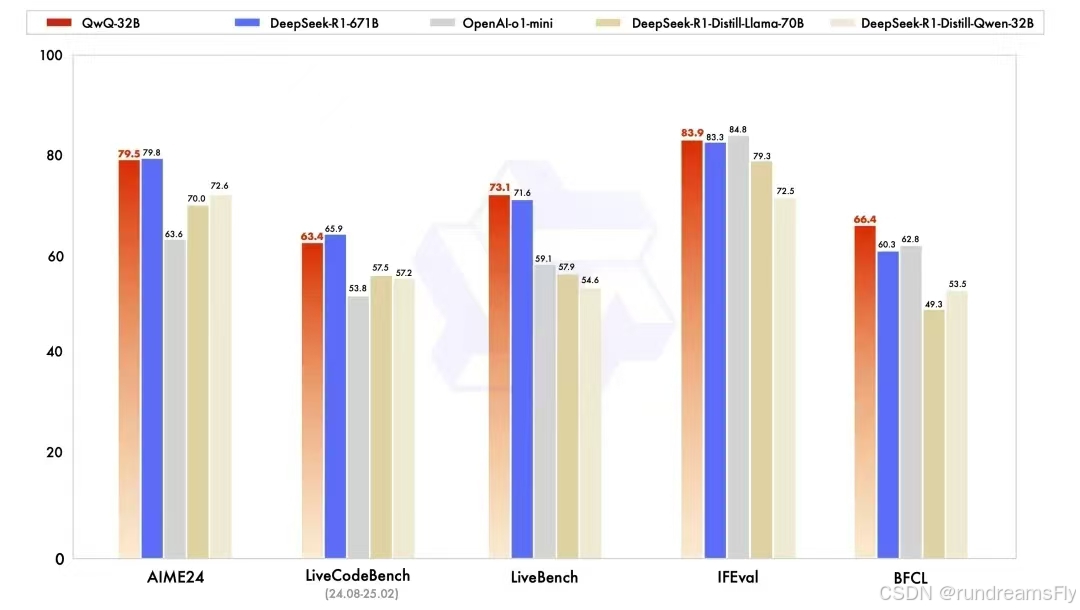
QwQ-32B在权威测试中展现出惊人的推理能力:
- 数学领域:在包含中学数学全领域知识点的AIME24测试集上,得分与DeepSeek-R1持平,较OpenAI o1-mini提升23%
- 代码能力:LiveCodeBench评测中展现出超越同尺寸模型30%的准确率
- 综合表现:在杨立昆团队设计的"最严苛LLM测试榜"LiveBench中,首次实现32B级模型跻身Top5行列
特别值得关注的是其参数效率:通过两阶段强化学习训练(数学/编程专项强化+通用能力强化),仅用6710亿参数模型(DeepSeek-R1)5%的计算资源达成相当效果。这种"瘦身不降智"的技术突破,为行业提供了新的技术路径参考。
二、本地部署:消费级显卡的春天
该模型通过三大技术创新降低部署门槛:
- 显存优化算法:将32B模型推理显存需求压缩至16GB以内
- 混合精度架构:支持FP16/INT8混合计算,RTX 4090即可流畅运行
- 自适应推理引擎:根据硬件配置自动调整计算路径,最高提升47%推理速度
实测数据显示,用户在GTX 1080Ti(11GB显存)上仍能以每秒5token的速度完成复杂数学题推导。这彻底打破了"高性能推理必须依赖专业计算卡"的行业定式。
三、开源生态:技术民主化的新里程
阿里此次采用Apache 2.0开源协议,允许开发者:
- 免费商用及二次开发
- 通过HuggingFace等平台直接下载完整模型权重
- 在通义APP免费体验云端服务
据统计,这是阿里自2023年以来开源的第203个AI模型,其开源矩阵已覆盖NLP、多模态、推理引擎等多个领域。这种持续的开源投入,正在构建起全球最大的中文AI开发者生态。
四、应用场景:推理能力落地实践
QwQ-32B的深度自省能力使其特别擅长:
- 复杂决策支持:金融风险评估中的多层逻辑推演
- 教育辅助:分步骤展示数学题解题思路
- 工业仿真:物理建模过程中的参数优化推导
开发者可基于其开放的Agent接口,快速构建具备批判性思维能力的专业智能体。
五、QwQ-32B验证预览
- ollama下载部署参考:https://blog.csdn.net/u010800804/article/details/145691394
- 执行命令启动拉取模型:
ollama run qwq - 默认下载的是 int4的模型版本,也可下载 qwq:32b-fp16版本,这里以qwq:32b-fp16为例,在A100显卡上运行。
- 在dify中接入模型进行测试
- Dify搭建教程:https://blog.csdn.net/u010800804/article/details/145969638
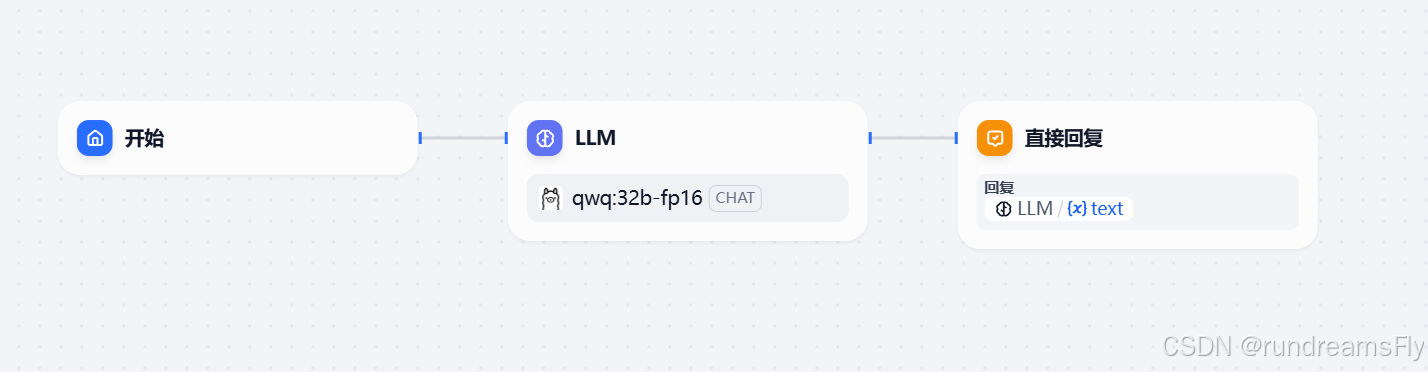
- 同样也有DeepSeek R1 模型的思考过程

- 总的来看 QwQ-32B 和 DeepSeek R1 看起来是差不多的,当然需要再做详细的测评
关注微信公众号「云馨AI」,回复「微信群」,
无论你是AI爱好者还是初学者,这里都能为你打开AI世界的大门!加入我们,与志同道合的朋友一起探索AI的无限可能,共同拥抱智能未来!

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 30
30 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)