
【论文解读】deepseek R1迁移到多模态《Visual-RFT: Visual Reinforcement Fine-Tuning》
论文提出了一种全新的视觉强化微调方法,通过利用 LVLM 生成包含推理过程的多组候选答案,再结合规则化的可验证奖励(例如 IoU 奖励和分类准确率奖励),并采用 GRPO 算法进行策略优化,有效提升了模型在少样本条件下的视觉感知与推理能力。实验结果表明,该方法在细粒度分类、少样本目标检测、推理接地及开放词汇目标检测任务上均超越传统的监督微调方法,展示了其在多模态任务上的广阔应用前景。
·
论文链接:https://arxiv.org/pdf/2503.01785
1. 概述
主要目标:
- 本文旨在将强化微调(Reinforcement Fine-Tuning,RFT)方法从语言模型扩展到多模态任务中,特别是视觉任务。
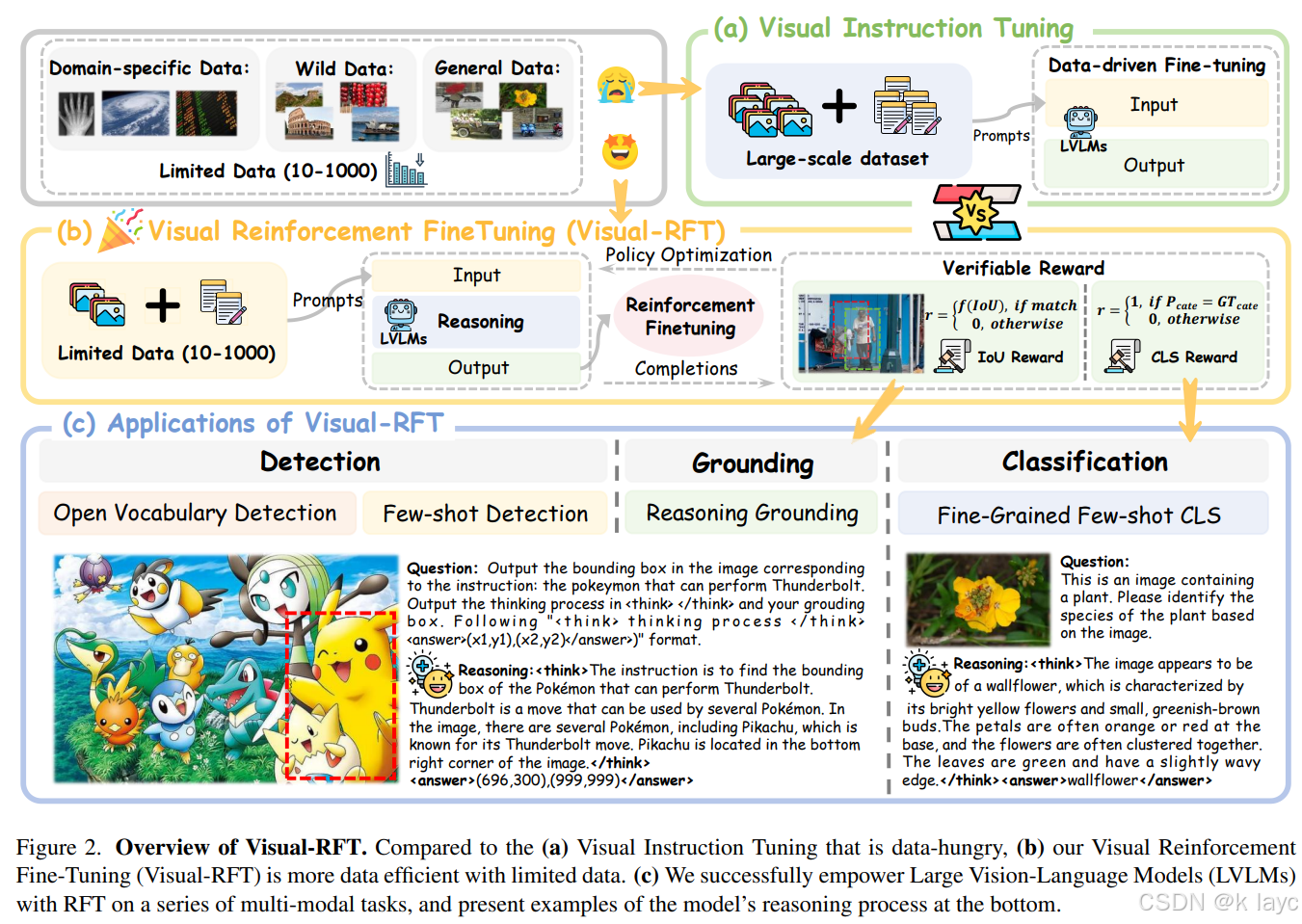
- 针对传统监督微调(Supervised Fine-Tuning,SFT)在数据稀缺条件下的局限性,提出了一种数据高效、基于规则验证奖励(Verifiable Reward)的视觉强化微调方法——Visual-RFT。
关键贡献:
- 提出了一种新的方法 Visual-RFT,利用 LVLM(Large Vision-Language Models)生成包含推理过程的多个候选答案,并通过设计针对视觉任务的规则化奖励函数来更新策略。
- 针对不同的视觉任务(如目标检测、图像分类、推理接地等)设计了专门的可验证奖励函数,例如利用 IoU 奖励来衡量目标检测中的边界框匹配程度。
- 实验结果显示,Visual-RFT 在少样本(few-shot)设置下大幅提升了模型在细粒度分类、开放词汇目标检测以及推理接地任务上的性能,相较于 SFT 具有明显优势。
2. 引言与背景
大模型与强化微调背景:
- 近年来,大型推理模型(如 OpenAI o1)展示了在回答前“深思熟虑”的能力,强化微调(RFT)被用来通过少量样本进行领域特定任务的高效微调。
- 与传统 SFT 直接模仿预设答案不同,RFT 通过对生成结果进行评估(例如使用预定义规则验证奖励)来引导模型学习正确的推理过程。
扩展到视觉领域的必要性:
- 尽管 RFT 在数学、代码等领域已有应用,但在多模态(视觉+语言)任务上的应用尚未充分探索。
- 本文提出的 Visual-RFT 旨在解决这一问题,通过设计面向视觉任务的奖励函数,使 LVLM 能够在数据稀缺的条件下也能高效学习并提升视觉感知与推理能力。
3. 方法论
3.1 强化学习与可验证奖励
强化学习目标:
- 目标是使策略模型 π θ \pi_\theta πθ 在给定输入问题 q q q 下生成的输出 o o o 尽可能获得高的可验证奖励。
- 其目标函数可以表示为:
max π θ E o ∼ π θ ( q ) [ R R L V R ( q , o ) ] \max_{\pi_\theta} E_{o\sim\pi_\theta(q)}\left[ R_{RLVR}(q,o) \right] πθmaxEo∼πθ(q)[RRLVR(q,o)]
带 KL 正则化的目标函数:
- 为了确保更新过程中策略模型与参考模型
π
r
e
f
\pi_{ref}
πref 的差异不会过大,引入了 KL 散度约束,目标函数为:
R R L V R ( q , o ) = R ( q , o ) − β K L [ π θ ( o ∣ q ) ∥ π r e f ( o ∣ q ) ] R_{RLVR}(q,o) = R(q,o) - \beta KL\left[\pi_\theta(o\mid q) \parallel \pi_{ref}(o\mid q)\right] RRLVR(q,o)=R(q,o)−βKL[πθ(o∣q)∥πref(o∣q)]
其中 R ( q , o ) R(q,o) R(q,o) 是通过预定义规则计算的可验证奖励, β \beta β 是超参数。
可验证奖励函数:
- 与传统的基于训练偏好数据的奖励模型不同,可验证奖励直接利用规则判断输出是否与“正确答案”一致,从而简化了奖励计算过程。
3.2 Visual-RFT 框架
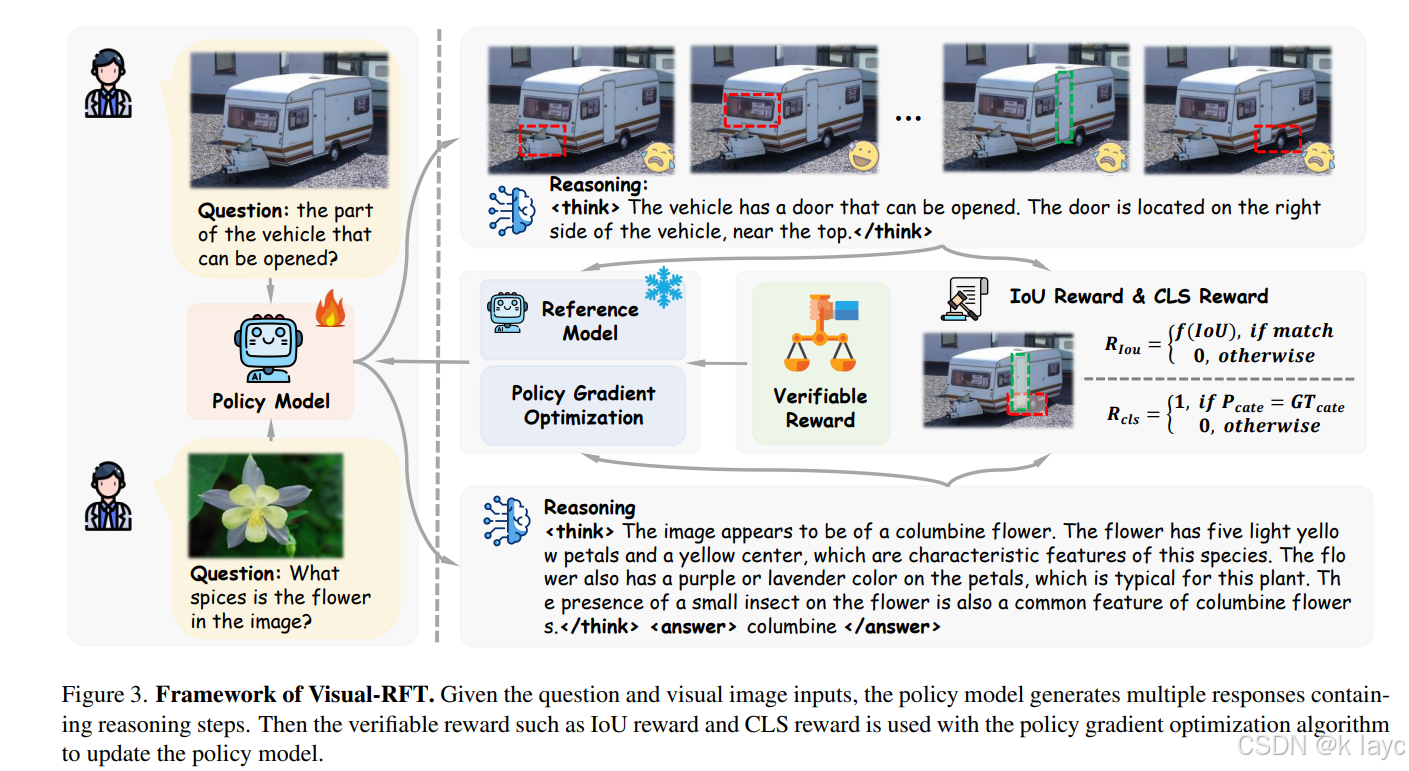
Visual-RFT 框架主要包含以下几个关键步骤:
3.2.1 多模态生成与推理过程
- 输入:图像和问题(例如“这是一张包含植物的图像,请判断植物种类”)。
- 策略生成:LVLM 利用输入生成多个响应,每个响应包含推理过程(由 <think> 标签包围)和最终答案(由 <answer> 标签包围)。
- 示例:
- 对于图像分类任务,模型先输出推理过程,然后给出最终的分类结果。
- 对于目标检测任务,模型输出边界框坐标以及置信度,并附带推理说明。
3.2.2 针对视觉任务设计的可验证奖励
目标检测奖励:
- 针对目标检测任务,设计了基于 IoU(Intersection over Union)和置信度的奖励函数。
- 具体步骤如下:
- 对于模型生成的候选边界框 { b 1 , b 2 , … , b n } \{b_1, b_2, \dots, b_n\} {b1,b2,…,bn},与地面真值边界框 { b 1 g , b 2 g , … , b m g } \{b^g_1, b^g_2, \dots, b^g_m\} {b1g,b2g,…,bmg}进行匹配,计算每个候选边界框的 IoU 值。
- IoU 奖励
R
I
o
U
R_{IoU}
RIoU 定义为所有边界框 IoU 的平均值:
R I o U = ∑ i = 1 n i o u i n R_{IoU} = \frac{\sum_{i=1}^{n} iou_i}{n} RIoU=n∑i=1nioui - 对于每个边界框,定义置信度奖励
r
c
i
r_{ci}
rci 如下:
r c i = { c i , if i o u i ≠ 0 1 − c i , if i o u i = 0 r_{ci} = \begin{cases} c_i, & \text{if } iou_i \neq 0 \\ 1 - c_i, & \text{if } iou_i = 0 \end{cases} rci={ci,1−ci,if ioui=0if ioui=0 - 整体置信度奖励为:
R c o n f = ∑ i = 1 n r c i n R_{conf} = \frac{\sum_{i=1}^{n} r_{ci}}{n} Rconf=n∑i=1nrci - 此外,为保证模型输出格式符合要求,还会设置格式奖励 R f o r m a t R_{format} Rformat。
- 最终目标检测奖励:
R d = R I o U + R c o n f + R f o r m a t R_d = R_{IoU} + R_{conf} + R_{format} Rd=RIoU+Rconf+Rformat
图像分类奖励:
- 分类任务奖励由准确性奖励和格式奖励构成:
R c l s = R a c c + R f o r m a t R_{cls} = R_{acc} + R_{format} Rcls=Racc+Rformat- 其中 R a c c R_{acc} Racc 根据模型输出类别与地面真值是否一致给予 1 或 0 的奖励。
3.2.3 策略更新与 GRPO
- 策略优化算法:
- Visual-RFT 采用 Group Relative Policy Optimization(GRPO)算法更新策略模型。
- GRPO 的核心思想是生成一组候选响应,然后计算每个响应的相对质量:
A i = r i − mean ( { r 1 , … , r G } ) std ( { r 1 , … , r G } ) A_i = \frac{r_i - \text{mean}(\{r_1, \dots, r_G\})}{\text{std}(\{r_1, \dots, r_G\})} Ai=std({r1,…,rG})ri−mean({r1,…,rG})
其中 A i A_i Ai 表示第 i i i 个响应的相对质量。
- 通过这种方式,模型能够在多个候选响应中偏好质量更高的答案,从而在少样本条件下迅速提升性能。
3.3 数据准备
多模态训练数据构建:
- 为了训练 Visual-RFT,作者设计了特殊的提示(prompts)格式,引导模型在生成最终答案前输出完整的推理过程。
- 例如:
- 检测提示:要求模型检测图像中特定类别对象,并严格按照指定格式输出 <think> 和 <answer> 标签包围的内容。
- 分类提示:要求模型在图像分类任务中先输出推理过程,再给出最终分类结果。
格式奖励:
- 在训练过程中,还设置了格式奖励 R f o r m a t R_{format} Rformat,促使模型输出符合预定模板的内容,保证推理过程和最终答案的结构化输出。
4. 实验与结果
4.1 实验设置
- 少样本(few-shot)设置:
- 在细粒度图像分类、少样本目标检测、推理接地以及开放词汇目标检测任务中,Visual-RFT 均以极少的训练样本(例如 1-shot、2-shot、4-shot 等)进行训练和测试。
- 基线对比:
- 实验中对比了传统 SFT 方法以及多轮 RAG 方法(如 Self-RAG、GenGround、RQ-RAG 等)。
- 实现细节:
- 基础模型选用 Qwen2-VL-2B 或 Qwen2-VL-7B 等大型视觉语言模型。
- 检索模型采用 NV-Embed-v2,检索结果数设置为 10。
4.2 主要结果
-
细粒度图像分类:
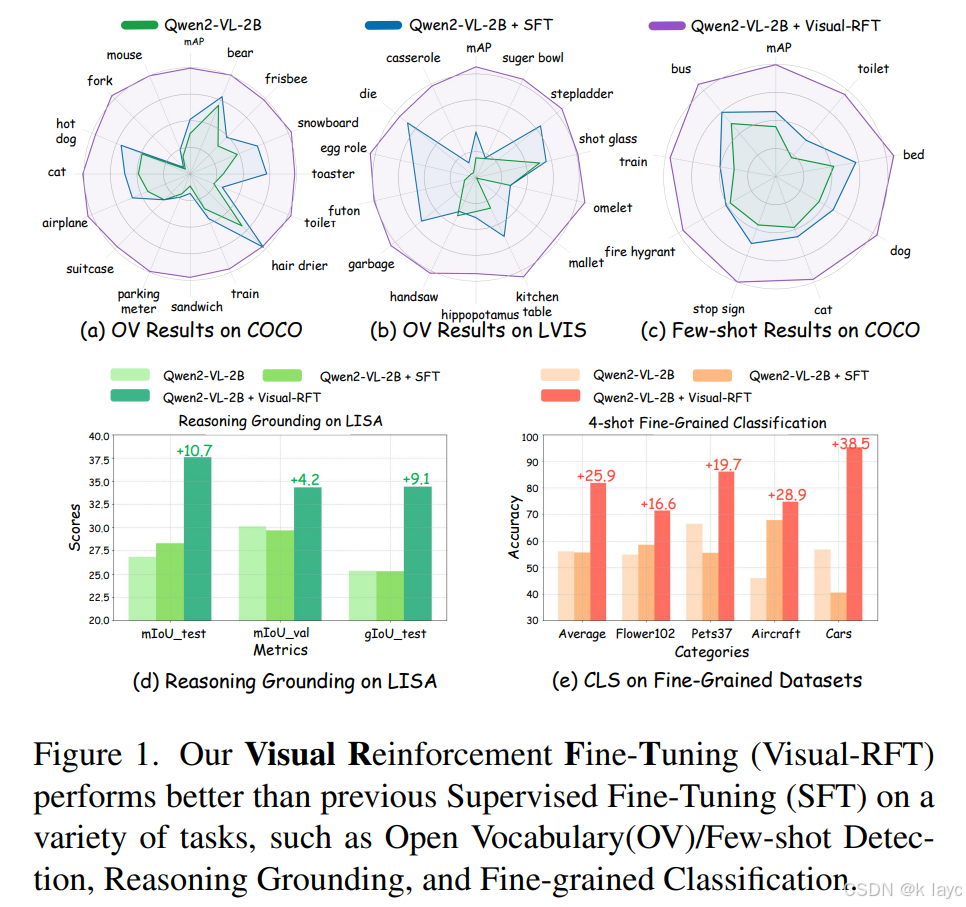
- 在 one-shot 设置下,Visual-RFT 相较于 SFT 提升准确率显著,例如在 Flower102 数据集上提升了约 24.3%。
- 在 4-shot、8-shot、16-shot 等设置中,Visual-RFT 均明显优于 SFT,证明了其在数据稀缺下的强泛化能力。

-
少样本目标检测:
- 在 COCO 数据集的少样本设置中,Visual-RFT 在 mAP(平均精度均值)上比 SFT 有大幅提升;例如在两样本设置下提升了约 21.9 个点。
- 在 LVIS 数据集中,对于稀有类别也能取得显著改进。

-
推理接地:
- 在 LISA 数据集上,Visual-RFT 显著提高了边界框 IoU 和 gIoU(用于评价分割掩膜的指标),表明其在推理接地任务上具有更强的精确性和鲁棒性。
-
开放词汇目标检测:
- Visual-RFT 在未见过的新类别上也能快速迁移,取得了比 SFT 更高的检测精度。
4.3 消融实验
- 实验通过对比去除 Visual-RFT 中的各个模块(例如奖励函数、GRPO、格式奖励等),证明了每个模块对最终性能的正向贡献:
- 消融结果表明,采用可验证奖励和 GRPO 更新策略是提升模型性能的关键因素。
- 同时,格式奖励对确保输出推理过程的规范性也起到了辅助作用。
5. 结论
主要结论:
- 本文提出的 Visual-RFT 是首个将基于规则验证奖励的强化微调方法成功应用于视觉任务的工作。
- 通过设计针对目标检测、图像分类等任务的专用奖励函数,并利用 GRPO 算法进行策略优化,Visual-RFT 能够在数据极为有限的情况下大幅提升 LVLM 的视觉感知和推理能力。
- 实验结果在多个视觉任务上均显示出显著优于传统 SFT 的性能,展示了该方法在实际应用中的巨大潜力。
未来工作方向:
- 探索更丰富的视觉任务场景和奖励设计,以进一步提升多模态模型的表现。
- 结合更多的领域知识和更大规模的少样本数据,进一步验证 Visual-RFT 在开放词汇、复杂场景下的泛化能力。
- 对强化微调过程中的超参数(如奖励权重、KL 正则系数等)进行更深入的调优研究。
6. 总结
论文 Visual-RFT: Visual Reinforcement Fine-Tuning 提出了一种全新的视觉强化微调方法,通过利用 LVLM 生成包含推理过程的多组候选答案,再结合规则化的可验证奖励(例如 IoU 奖励和分类准确率奖励),并采用 GRPO 算法进行策略优化,有效提升了模型在少样本条件下的视觉感知与推理能力。实验结果表明,该方法在细粒度分类、少样本目标检测、推理接地及开放词汇目标检测任务上均超越传统的监督微调方法,展示了其在多模态任务上的广阔应用前景。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 23
23 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)