
DeepSeek R1核心原理GRPO算法详解
模型的更新迭代实在是太快了,就在今天早上,阿里的千问发布推理模型号称媲美R1。那么对R1核心原理还比较模糊的同学,我们还是一起回头整理下对DeepSeek的核心原理GRPO算法的理解吧。
目录

也可以通过Qwen Chat直接进行体验!
模型的更新迭代实在是太快了,就在今天早上,阿里的千问发布QwQ-32B推理模型号称媲美R1。那么对R1核心原理还比较模糊的同学,我们还是一起回头整理下对DeepSeek的核心原理GRPO算法的理解吧。
一、强化学习与其他机器学习方法的比较
强化学习与监督学习和无监督学习相比,具有以下区别:
监督学习:需要大量的标记数据来训练模型,适用于有大量标注数据的场景。
无监督学习:不需要标记数据,适用于无监督的任务,如聚类分析。
强化学习:通过试错和反馈来学习,适用于需要从经验中优化策略的场景。可通俗理解为模型从试错中自己找到最优的路径答案,其核心是奖励函数,有最终目标要求才能制定奖励函数激励机制。
换句话说,如果一个训练任务,算法或模型不具备辨别能力或辨别规则来识别反馈每次回答的好坏,那这个任务就不适用强化学习。
比如,像deepseek一样我们需要训练出具备推理能力的R1模型,那就是需要强迫模型每次回答的时候带上自己的思考think强迫其思考(即明确输出格式让其每次都思考)。因此这个任务就可以通过识别反馈模型每次回答是否带think内容来进行RL训练,每次奖励有带思考的回答最终模型就会带上思考能力了。
这和训练下棋机器人以赢棋的规则为奖励,训练走路机器人以不倒下为奖励是一个道理。这些都是适合通过强化学习RL训练的。
但是如果是一个对图片内容理解准确度的多模态任务,是否适合使用RL训练呢?我的奖励机制要如何设置呢? 因为对于N个图片理解输出内容的准确率判断如果最终没办法判断反馈到奖励机制则不适合使用RL训练,反之,则就可以用RL解决任务训练。
二、DeepSeek R1核心原理GRPO算法详解
对以上提到的RL不是很理解的话,可以先来看基础原理部分。
1、RL基础原理理解
参考教程:传统强化学习算法
关键字:
传统强化学习算法, 如PPO(gpt)算法。PPO 需要单独的价值模型来估计每个响应的值,这会使内存和计算要求加倍。
相较于PPO,GRPO去掉了价值模型,而是通过分组分数来估计基线,从而可极大减少训练资源。
强化学习里的奖励模型Reward Model训练(鼓励打分的模型),这是开始强化学习之前的前置工作,要先训练得到这个模型才能进行RL。即ORM Reward Model。
2、R1强化学习使用的GRPO算法
参考教程:R1强化学习使用的GRPO算法
关键字:
GRPO vs PPO
GRPO算法RL步骤:
采样N个答案;(模型自己都试一下得出各个回答);
奖励函数reward;(给每个回答打分–可以是自定义硬编码py函数来打分)
计算优势(advantage) 反向传播;
优化目标loss 优化token的概率值;(奖励高的加概率值,奖励低的降低概率值)
防止RL过度优化;(loss函数里有纠偏的处理-可以理解为在作“刹车”动作)
如果需要深入理解GRPO算法,建议点击参考这篇文章。

3、R1强化学习实践
参考教程:自己复现R1顿悟时刻
关键词:
使用huggingface的TRL强化学习库自己复现R1顿悟时刻,选择TRL其中的强化学习算法之一GRPO来进行实践。
模拟R1强化学习训练实践步骤:
1.模型下载;(这里选的千问模型–答案的回答质量其实取决于原模型,强化训练任务目标只是训练强迫它进行推理)
2.分词器 处理;
3.奖励函数;(这里是自己自定义编写)–也可以是多个子函数结合 – 本次任务则是
4.对回答的格式是否符合奖励的规则规范来奖励,训练强迫它按照预定思考think模版走带上思考,当顿悟后回答就会具备思考能力。(即此处任务的强化学习是对回答格式的激励,如强迫它推理能力,但如果出现回答内容质量不行那是原模型的“脑子”问题,比如模型太小能力不足,与本次RL理论上无关。)
5.训练集 处理;
6.开始训练,用GRPO算法开始训练;(直到某一刻会出现顿悟时刻–模型就会按照我们的格式要求进行回答了)
7.TensorBoard仪表盘;(训练中可通过观察各曲线图,符合后也可直接kill训练,直接可让训练停在某个checkpoint。)
在DeepSeek-R1-Zero模型的训练过程中,研究人员观察到了这种现象,并将其称为“顿悟时刻”(Aha Moment)。
这种时刻不仅是模型在学习过程中的一个重要转折点,也是研究人员观察到的显著变化。在DeepSeek-R1-Zero的中间版本中,模型学会了以人类的语气进行反思,甚至能够修正一些形而上学假设,表现出类似人类自我反思的能力。
这种“顿悟时刻”通常发生在模型通过强化学习(RL)重新评估其初始方法,学会为问题分配更多的思考时间,而无需任何人工反馈或描述如何执行的数据。
这种行为不仅证明了模型不断增长的推理能力,也是强化学习导致意想不到的复杂结果的迷人例子。
三、DeepSeek系列模型关系解读
众所周知,DeepSeek在春节期间发布R1的时候就具有了了好几个系列模型了,看github。下图基本表达了DeepSeek系列家族模型的相互关系,一张图解释了各个模型是怎么来的。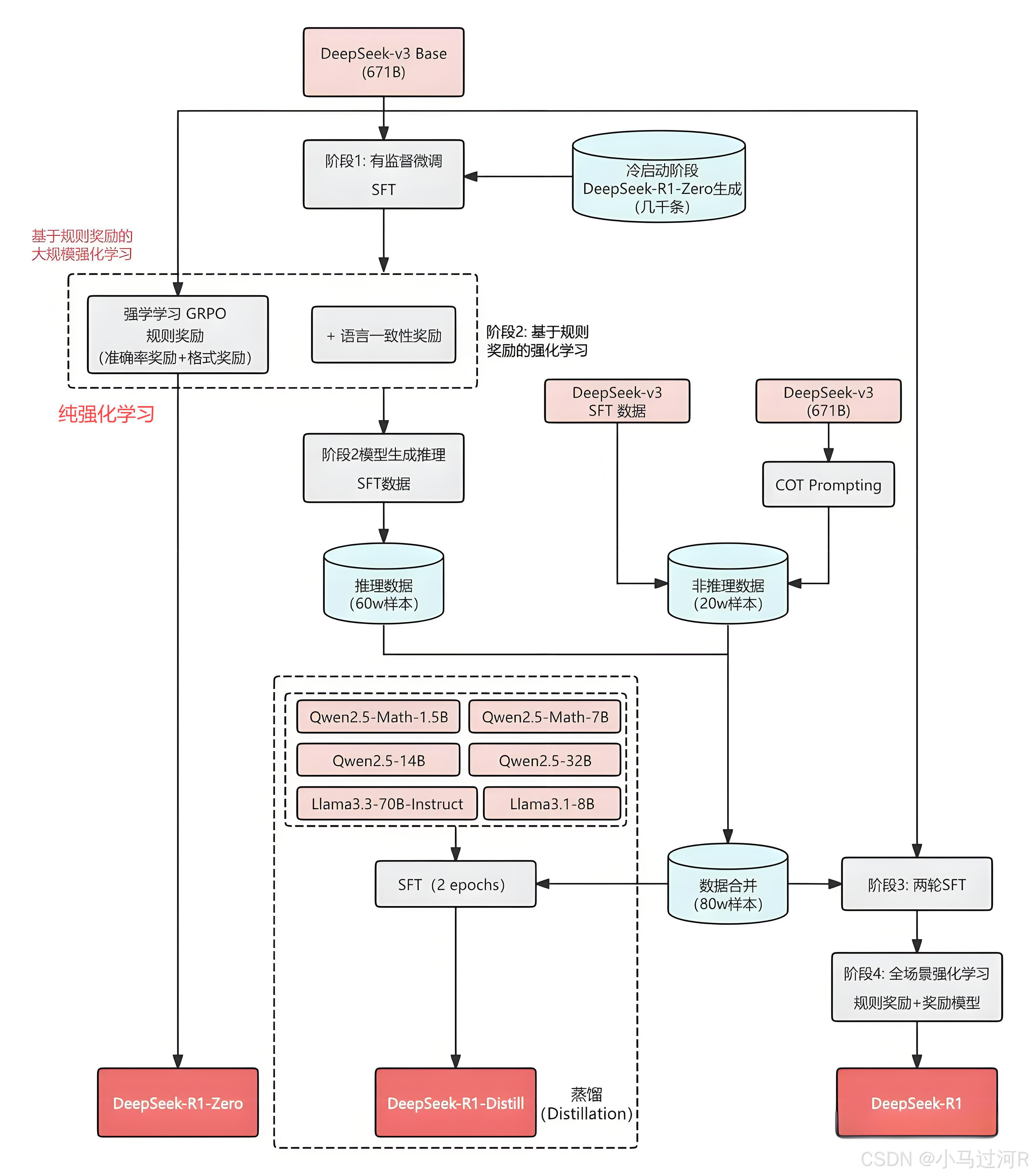
从图中可以看出,
2025年01月20日,DeepSeek 正式发布 DeepSeek-R1,并同步开源模型权重。
开源 DeepSeek-R1 推理大模型,与 o1 性能相近。【DeepSeek-R1 是基于V3 通过一些列的 SFT 、RL-GRPO(DeepSeek-R1-Zero 纯强化学习)等得到的】
DeepSeek-R1 提出了多阶段训练策略: 冷启动 SFT -> RL -> COT + 通用数据 SFT(80w)->全场景 RL。
DeepSeek开源了 DeepSeek-R1-Zero,是预训练模型直接 RL,不走 SFT。(是GRPO)
DeepSeek开源了用 R1 数据蒸馏的 Qwen、Llama 系列小模型,蒸馏模型能力超过 o1-mini 和 QWQ。比如通过简单蒸馏 DeepSeek-R1 的输出,得到 DeepSeek-R1-Distill-Qwen-7B。
如何通俗理解强化学习R1?可以认为RL是模型自己通过奖励反馈机制试错经验摸索学习得得到成绩100分,蒸馏是有老师教直接迁移能力到学生模型得到的成绩100分。(蒸馏:学生模型需要的数据是老师生的,直接通过SFT训出一个新的学生模型)
那么为什么不直接RL小模型呢而是蒸馏?因为通常情况下小模型参数小能力小,自我学习效果不行。
相关信息:
https://mp.weixin.qq.com/s/1YiNu6QBxAVkJaBxT5mfMg
https://huggingface.co/Qwen/QwQ-32B
- 彩蛋的位置~

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 25
25 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)