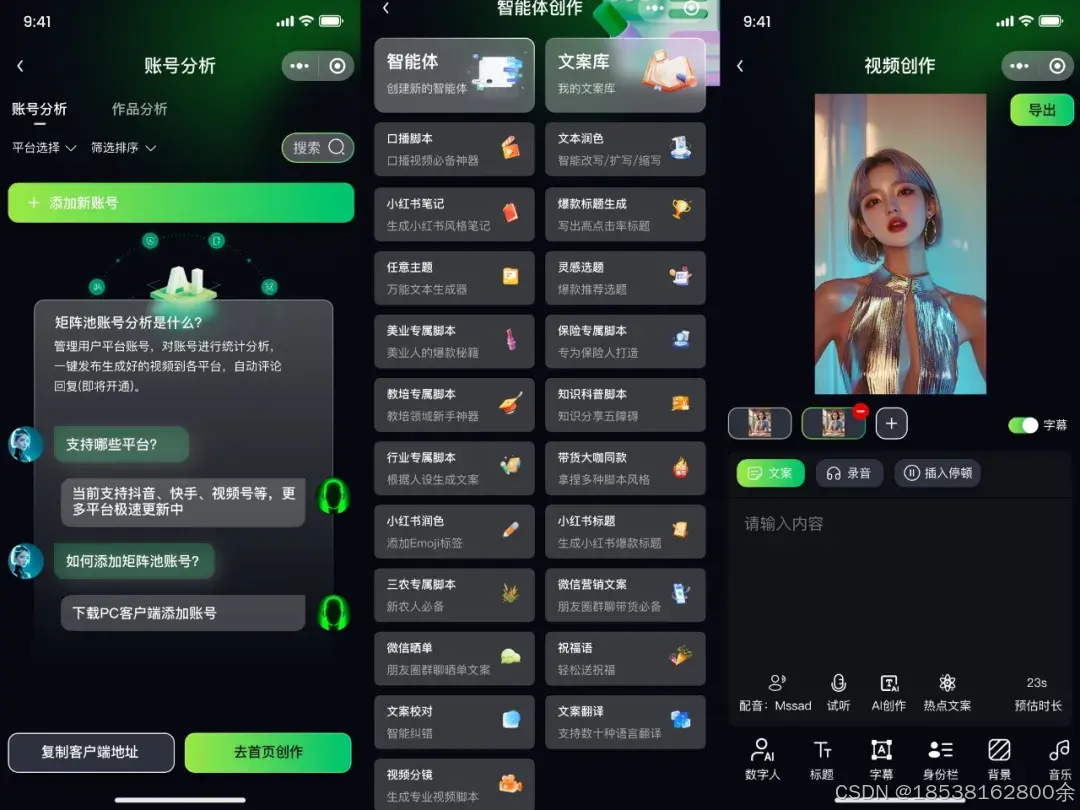
基于 DeepSeek 技术的数字人源码搭建全解析,支持OEM
DeepSeek 基于深度学习框架,如 TensorFlow 或 PyTorch 构建核心模型。其采用的神经网络架构,如 Transformer、卷积神经网络(CNN)等,在处理图像、语音和文本数据方面表现卓越。例如,在数字人面部表情生成中,CNN 可用于分析输入的表情特征图像,通过多层卷积和池化操作提取关键特征,为后续的表情合成提供数据基础。通过基于 DeepSeek 技术的数字人源码搭建,我们
一、引言
在数字人技术蓬勃发展的当下,DeepSeek 以其先进的特性为数字人系统搭建带来了新的可能。它融合了深度学习、计算机视觉、自然语言处理等多领域技术,旨在打造高度逼真、智能交互的数字人。本文将深入探讨如何基于 DeepSeek 技术进行数字人源码搭建,为开发者提供全面的技术指引。
二、DeepSeek 技术核心概述
(一)深度学习基础
DeepSeek 基于深度学习框架,如 TensorFlow 或 PyTorch 构建核心模型。其采用的神经网络架构,如 Transformer、卷积神经网络(CNN)等,在处理图像、语音和文本数据方面表现卓越。例如,在数字人面部表情生成中,CNN 可用于分析输入的表情特征图像,通过多层卷积和池化操作提取关键特征,为后续的表情合成提供数据基础。
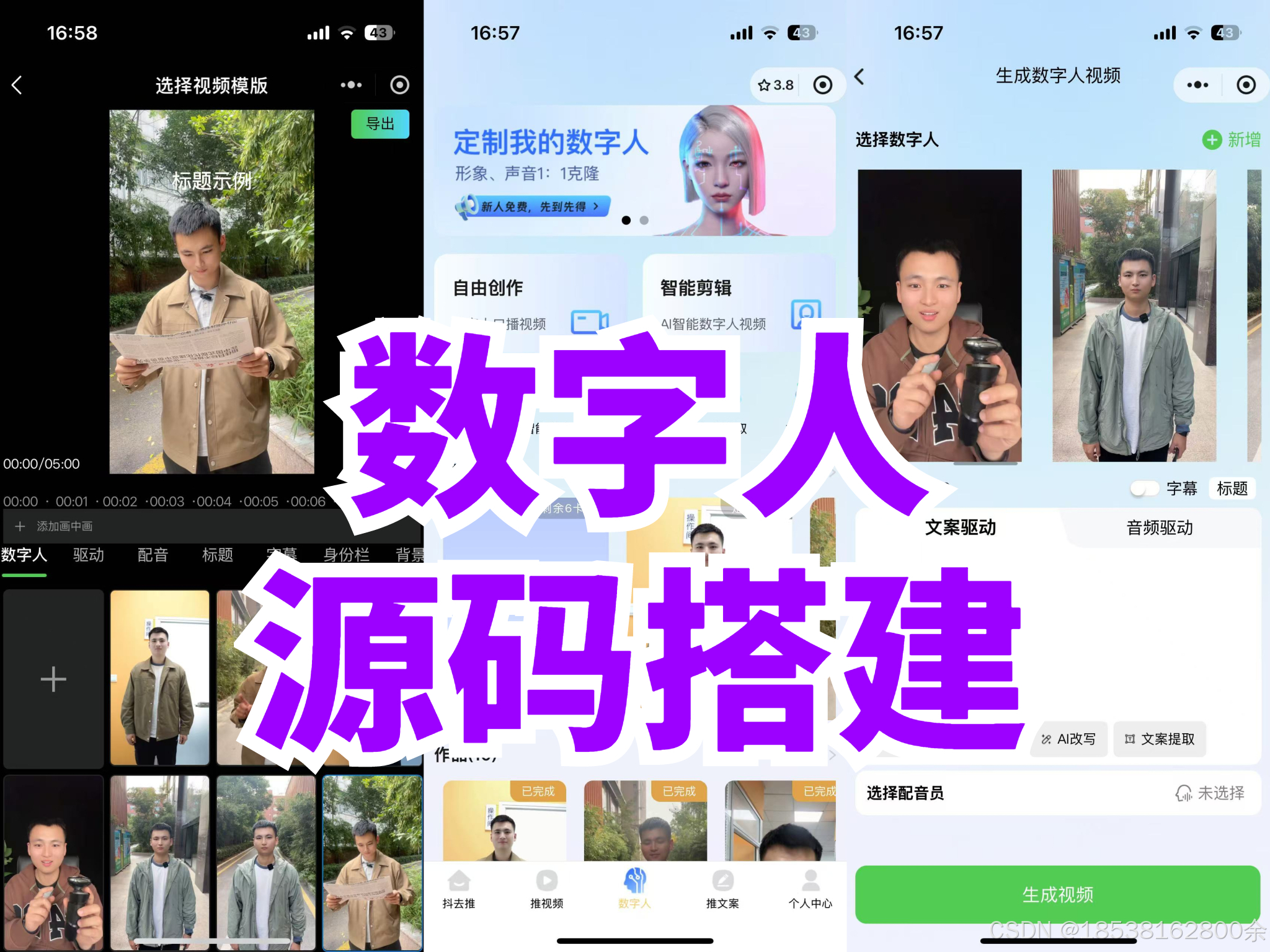
(二)多模态融合技术
数字人需要处理多种模态的信息,如语音、文本和视觉。DeepSeek 通过多模态融合技术,将不同来源的信息进行整合。例如,在对话场景中,语音识别模块将用户语音转换为文本,自然语言处理模块对文本进行理解和分析,同时视觉模块捕捉用户的面部表情和肢体动作。这些不同模态的数据通过特定的融合算法,如早期融合(在数据输入阶段就进行融合)、晚期融合(在模型输出阶段进行融合)等方式,为数字人提供更全面准确的交互信息。
(三)逼真渲染技术
为了实现数字人的高逼真度,DeepSeek 集成了先进的渲染技术。基于物理的渲染(PBR)方法被广泛应用,它通过模拟光线在物体表面的物理传播过程,包括反射、折射和散射等,来生成非常真实的图像效果。例如,在数字人皮肤材质的渲染上,PBR 能够精确模拟皮肤的质感、光泽和透明度,使得数字人的外观更加逼真自然。
三、开发环境搭建
(一)硬件需求
- 高性能 GPU:数字人开发中大量的深度学习计算任务对 GPU 性能要求极高。例如,NVIDIA 的 RTX 系列 GPU 在训练和推理过程中能显著加速模型运算。对于复杂的数字人模型,建议使用具有较大显存(如 16GB 及以上)的 GPU,以处理大规模的图像和数据运算。
- 大容量内存:充足的内存对于存储和处理数字人相关的数据至关重要。至少需要 32GB 以上的内存,以确保在加载大型模型和处理高分辨率图像、视频时系统能够稳定运行。
(二)软件需求
- 深度学习框架:根据 DeepSeek 的实现,选择合适的深度学习框架。如果使用 TensorFlow,可通过官方网站下载安装对应版本。对于 PyTorch,也可在其官网获取安装指南,根据不同的操作系统和 CUDA 版本进行适配安装。
- 计算机视觉库:OpenCV 是常用的计算机视觉库,提供了丰富的图像处理和分析函数。可通过包管理工具(如 pip)进行安装。此外,对于 3D 渲染部分,需要安装相关的渲染库,如 Three.js(用于 Web 端渲染)或 Unity(用于游戏和应用开发),并根据具体需求进行配置。
- 自然语言处理工具包:NLTK(Natural Language Toolkit)和 SpaCy 是常见的自然语言处理工具包,提供了词性标注、命名实体识别等功能。通过 pip install nltk 和 pip install spacy 命令即可安装,同时还需下载相应的语言模型数据。
四、数字人源码搭建关键步骤
(一)模型构建
- 面部表情生成模型
-
- 使用深度学习构建一个基于 CNN 的面部表情生成模型。首先收集大量的面部表情图像数据集,对图像进行预处理,包括归一化、裁剪和标注表情类别。
-
- 构建 CNN 模型,例如包含多个卷积层、池化层和全连接层。卷积层用于提取图像的局部特征,池化层则对特征进行降维。在训练过程中,使用交叉熵损失函数来衡量模型预测结果与真实表情标签之间的差异,并通过反向传播算法更新模型参数。
-
- 示例代码(基于 PyTorch):
import torch
import torch.nn as nn
import torch.optim as optim
class FacialExpressionModel(nn.Module):
def __init__(self):
super(FacialExpressionModel, self).__init__();
self.conv1 = nn.Conv2d(3, 16, kernel_size = 3, padding = 1)
self.relu1 = nn.ReLU()
self.pool1 = nn.MaxPool2d(2)
self.conv2 = nn.Conv2d(16, 32, kernel_size = 3, padding = 1)
self.relu2 = nn.ReLU()
self.pool2 = nn.MaxPool2d(2)
self.fc1 = nn.Linear(32 * 64 * 64, 128)
self.relu3 = nn.ReLU()
self.fc2 = nn.Linear(128, num_classes)
def forward(self, x):
out = self.conv1(x)
out = self.relu1(out)
out = self.pool1(out)
out = self.conv2(out)
out = self.relu2(out)
out = self.pool2(out)
out = out.view(-1, 32 * 64 * 64)
out = self.fc1(out)
out = self.relu3(out)
out = self.fc2(out)
return out
model = FacialExpressionModel()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr = 0.001)
- 语音合成模型
-
- 基于 DeepSeek 的语音合成通常采用 Tacotron 等模型。Tacotron 是一种端到端的语音合成模型,它接收文本输入并生成相应的语音波形。
-
- 首先准备大规模的语音数据集,包含文本和对应的语音音频。对文本进行编码,如使用字符级或词级的嵌入表示。对于语音音频,进行预处理,如归一化、分帧等操作。
-
- 构建 Tacotron 模型,包括编码器、注意力机制和解码器。编码器将文本转换为隐藏表示,注意力机制帮助解码器在生成语音时聚焦于文本的不同部分,解码器则生成语音的梅尔频谱图,最后通过声码器将梅尔频谱图转换为实际的语音波形。
-
- 示例代码(简化示意,基于 TensorFlow):
import tensorflow as tf
class TacotronEncoder(tf.keras.layers.Layer):
def __init__(self):
super(TacotronEncoder, self).__init__()
self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_dim)
self.conv1d = tf.keras.layers.Conv1D(filters = num_filters, kernel_size = kernel_size, padding='same')
self.batch_norm = tf.keras.layers.BatchNormalization()
self.gru = tf.keras.layers.GRU(units = gru_units, return_sequences = True)
def call(self, x):
x = self.embedding(x)
x = tf.transpose(x, perm = [0, 2, 1])
x = self.conv1d(x)
x = self.batch_norm(x)
x = tf.nn.relu(x)
x = self.gru(x)
return x
class TacotronDecoder(tf.keras.layers.Layer):
def __init__(self):
super(TacotronDecoder, self).__init__()
self.gru1 = tf.keras.layers.GRU(units = gru_units, return_sequences = True)
self.attention = Attention()
self.gru2 = tf.keras.layers.GRU(units = gru_units, return_sequences = True)
self.dense = tf.keras.layers.Dense(num_mels)
def call(self, encoder_output, decoder_input):
x = self.gru1(decoder_input)
context = self.attention(encoder_output, x)
x = tf.concat([context, x], axis = -1)
x = self.gru2(x)
x = self.dense(x)
return x
- 自然语言处理模型
-
- 采用预训练的语言模型,如 GPT - Neo 等,并进行微调以适应数字人的对话场景。首先加载预训练模型权重,然后根据数字人特定的对话数据集进行微调。
-
- 在微调过程中,将对话数据进行预处理,如分词、构建输入序列等。设置合适的损失函数(如交叉熵损失)和优化器(如 AdamW),通过反向传播更新模型参数,使模型能够更好地理解和生成符合数字人对话风格的文本。
-
- 示例代码(基于 Hugging Face 的 Transformers 库):
from transformers import GPTNeoForCausalLM, GPT2Tokenizer, AdamW
tokenizer = GPT2Tokenizer.from_pretrained('EleutherAI/gpt - neo - 1.3B')
model = GPTNeoForCausalLM.from_pretrained('EleutherAI/gpt - neo - 1.3B')
optimizer = AdamW(model.parameters(), lr = 1e - 5)
for epoch in range(num_epochs):
for batch in data_loader:
input_ids = batch['input_ids']
attention_mask = batch['attention_mask']
labels = batch['labels']
outputs = model(input_ids = input_ids, attention_mask = attention_mask, labels = labels)
loss = outputs.loss
loss.backward()
optimizer.step()
optimizer.zero_grad()
(二)多模态交互实现
- 语音识别与文本处理
-
- 使用 DeepSeek 集成的语音识别模块,如基于深度神经网络的 ASR(Automatic Speech Recognition)模型。在初始化时加载预训练的语音识别模型权重。当接收到用户语音输入时,对音频进行预处理,如降噪、分帧等操作,然后输入到 ASR 模型中进行识别,得到文本输出。
-
- 将识别出的文本输入到自然语言处理模型中进行理解和分析。例如,提取关键词、分析语义意图等,以便数字人能够根据用户意图生成合适的回应。
- 视觉交互处理
-
- 利用摄像头捕捉用户的面部表情和肢体动作。通过计算机视觉算法,如基于 OpenCV 的人脸检测和表情识别技术,识别用户的面部表情。在识别过程中,首先进行人脸检测,定位人脸位置,然后提取面部关键点,通过关键点的变化来判断表情类别。
-
- 对于肢体动作识别,可采用基于骨骼关键点检测的方法,如 OpenPose 等技术。将检测到的肢体动作信息与数字人的行为模型相结合,使数字人能够做出相应的动作回应,增强交互的真实感。
(三)渲染与呈现
- 3D 模型搭建与材质设置
-
- 使用 3D 建模软件(如 Blender 或 Maya)创建数字人的 3D 模型,包括身体、面部等部分。在建模过程中,注重细节和比例,以确保数字人的外观逼真。
-
- 为模型设置材质,如皮肤材质可使用基于 PBR 的材质设置,调整颜色、粗糙度、金属度等参数,以模拟真实皮肤的质感。头发材质可通过调整透明度、光泽度等参数,使其看起来更加自然。
- 实时渲染与动画驱动
-
- 在开发环境中,使用渲染引擎(如 Unity 或 Unreal Engine)进行实时渲染。将创建好的 3D 模型导入渲染引擎,并根据数字人的动作和表情数据进行动画驱动。
-
- 例如,根据面部表情生成模型的输出,驱动数字人面部的骨骼动画,实现表情变化。同时,根据肢体动作识别的结果,驱动数字人身体的骨骼动画,实现肢体动作的同步。通过实时渲染,将数字人的动态画面呈现给用户。
五、优化与调试
(一)模型优化
- 模型压缩:对于训练好的数字人模型,采用模型压缩技术,如剪枝和量化。剪枝可以去除模型中不重要的连接和神经元,减少模型的参数数量,从而降低计算复杂度。量化则是将模型的参数从高精度数据类型转换为低精度数据类型,如从 32 位浮点数转换为 8 位整数,在不显著影响模型性能的前提下提高计算效率。
- 硬件加速:利用 GPU 的并行计算能力进行模型加速。在深度学习框架中,配置好 GPU 相关参数,确保模型能够在 GPU 上进行训练和推理。此外,对于一些特定的计算任务,如矩阵运算等,可以使用 GPU 加速库(如 cuDNN)进一步提升计算速度。
(二)调试技巧
- 数据可视化:在开发过程中,使用数据可视化工具(如 TensorBoard)对模型训练过程中的数据进行可视化。例如,可视化损失函数的变化曲线,观察模型是否收敛;可视化模型的中间层输出,了解模型对不同输入数据的特征提取情况,以便及时发现模型训练中的问题。
- 错误排查:当出现错误时,仔细检查代码中的语法错误和逻辑错误。对于模型训练中的错误,如梯度消失或梯度爆炸等问题,通过调整学习率、优化器参数或模型结构来解决。在多模态交互部分,检查传感器数据的输入是否正确,以及不同模块之间的数据传输是否正常。
六、总结与展望
通过基于 DeepSeek 技术的数字人源码搭建,我们能够创建出具有高度智能交互和逼真外观的数字人系统。从模型构建到多模态交互实现,再到渲染呈现,每个环节都紧密相连。在未来,随着技术的不断发展,数字人将在更多领域得到应用,如虚拟主播、智能客服、元宇宙社交等。开发者可以在本文的基础上,不断优化和拓展数字人系统,探索更多创新的应用场景,为数字人技术的发展贡献自己的力量。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)