快速用上专属于自己的大模型&智能体
昨天,公司同事突传喜讯,我们内部也成功部署了私有化的deepseek蒸馏模型,虽然参数量不大,但有了私有部署模型,就意味着,之前很多不能深入结合的业务,可以去做深入了。毕竟公有模型终归还是存在数据隐私方面的风险,而一些租赁方案,或者所谓的MaaS(模型即服务)的方案,本质上还是建立在云服务的基础上,也就是云服务时代存在的问题MaaS都有,最显著的就是,高峰期需求大,服务不稳,低谷期需求小,服务稳,
背景
昨天,公司同事突传喜讯,我们内部也成功部署了私有化的deepseek蒸馏模型,虽然参数量不大,但有了私有部署模型,就意味着,之前很多不能深入结合的业务,可以去做深入了。
毕竟公有模型终归还是存在数据隐私方面的风险,而一些租赁方案,或者所谓的MaaS(模型即服务)的方案,本质上还是建立在云服务的基础上,也就是云服务时代存在的问题MaaS都有,最显著的就是,高峰期需求大,服务不稳,低谷期需求小,服务稳,这基本属于自然现象了,没办法协调。
但我发现有些朋友,尤其是非技术类的用户,总感觉大模型这类产品和自己很远,所以他们不积极不主动的去接触,也就不去用,甚至一些技术人员传统观念根深蒂固,也把AI拒之千里之外。还有的人可能觉得这东西以后可能会替代自己,对自己的工作产生威胁等等,这里面可能有一些误解。当然本篇不会深入讨论这些问题,我认为AI一定会越来越普及,我们应该尽早的去面对AI普及带来的机遇和风险,如果AI真的对你的岗位存在威胁,那一味的远离可能会加速你被替代的时长!
所以本着打不过就加入的态度,我们应该积极的接触,应用,并驾驭AI,让他成为我们的工具,提高工作效率,而不是等着被替代!
这里,我想以一个小厂一线开发人员的视角出发,简单的聊一下,怎么快速的调教并构造出一个专属自己的大模型,也可以说是一个智能体(AI Agent)。
*部署模型
这里的部署,指的是,真正在服务器或者自己的机器上部署模型框架,目前这类方案跟多,大家可以自行gpt一下。
这不是本篇重点要聊的内容,我这里只简单介绍下Ollama,vLLM两个方向。
Ollama
Ollama最大的特点就是操作最简单,适合在自己的机器上操作,基本上有手就能操作。常用的命令我个人感觉和docker很像,只是把关键字换成ollama就行,比如拉取模型在ollama的命令就是
ollama pull xxx
其他的,大家看官方的文档即可
文档:https://github.com/ollama/ollama/blob/main/README.md#quickstart
vLLM
vLLM主要适合在服务器等生产环境部署,官网也提供了很多部署的路径,有基于GPU的,有基于CPU,还有基于NPU的,也提供了官方的docker镜像。
需要说明的是,vLLM本身是一个基于Python的库,也就是说它的上手门槛比Ollama高一些,但好在官方的文档给的非常具体,而且有专门的中文站点,如果有Python基础,上手部署也难度不大。感兴趣不怕折腾的小伙伴可以试试。
文档地址:https://vllm.hyper.ai/docs/
现在很多厂家推出了大模型一体机,配置给的都不低,单价基本在10w以内,比如MaxKB的一体机现在售价是3万一套,我感觉这也是私有化部署的一条路,有机房的话,一体机插到柜上就能用。
当然我没试过啊,但有同事说这东西不灵,说低于10w的配置都没法用,这个我就没办法验证了,我感觉这种一体机的思路挺好的,只要软硬件结合的好,一定是能大幅降低部署成本的。
构建专属模型&智能体
想要使用私有化的专属模型,一定要自己部署一套吗?
答案是否定的,只有部分的商用、政务等场景才需要真正部署私有化的模型,毕竟部署一套高可用的私有大模型,门槛还是挺高的,显卡,机柜等等硬件设备少说也得几十万起步。所以很多小厂在私有化大模型的选择上,还是走的租赁和MaaS的方案,这是现实原因,没得选。
那对于个人和用户量较少的企业用户来说,想要构造一个专属智能助手,还有没有更好的性价比方案呢?
我这里也推荐两个,分别是个人应用的AnythingLLM和适合小厂的MaxKb方案。
AnythingLLM
先奉上官方地址:https://anythingllm.com/
安装应用
它提供了基于Linux,Mac和Windows的客户端,我们可以根据自己的机器,下载对应的客户端安装即可。
安装流程和普通应用一样,装好后按提示进入软件即可!
如果大家完整看到它的安装流程,可以看到,它实际上也用到了Ollama的一些库,毕竟Ollama真的太方便了。
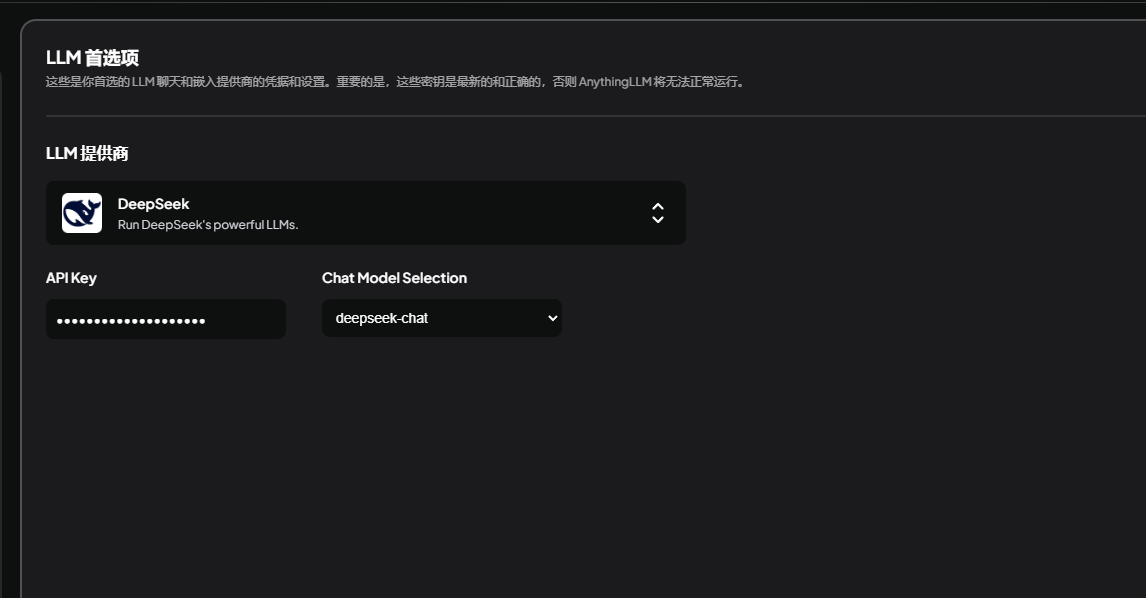
配置模型
按照引导,进入软件界面后,可以配置模型,可选的模型厂家包括,OpenAI,xAI,Azure,Deepseek等,这里我们选deepseek就好,如果你有其他厂家的key,选其他的也没问题。
选好之后,复制自己的APIKey到软件即可
创建工作区
工作区的概念每个人理解都不一样,我理解就是方便整理的,你可以把你的工作方向划分一下,创建不同的工作区,这样更加清晰。
非开发人员不了解的话,随便起个名字就好。
投喂训练
到此,基本的配置工作就完成了,我们可以上传本地的一些文档,图片等等,然后训练。
比如我这里准备一个本地工具的操作文档。我在投喂之前,先问他一个关于该工具的使用的问题,它的回答是这样的。
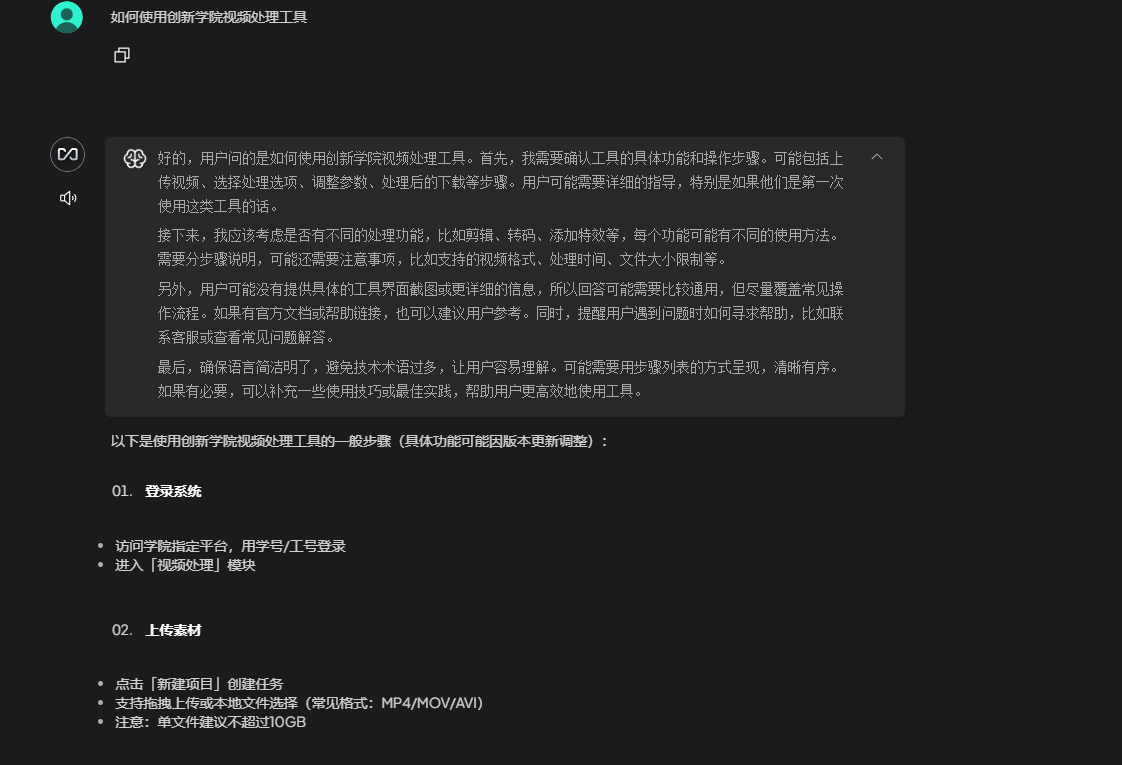
我投喂过这个文档之后,启动训练,结束后再次问同样的问题,他给我的回答就是基于该文档的内容了。
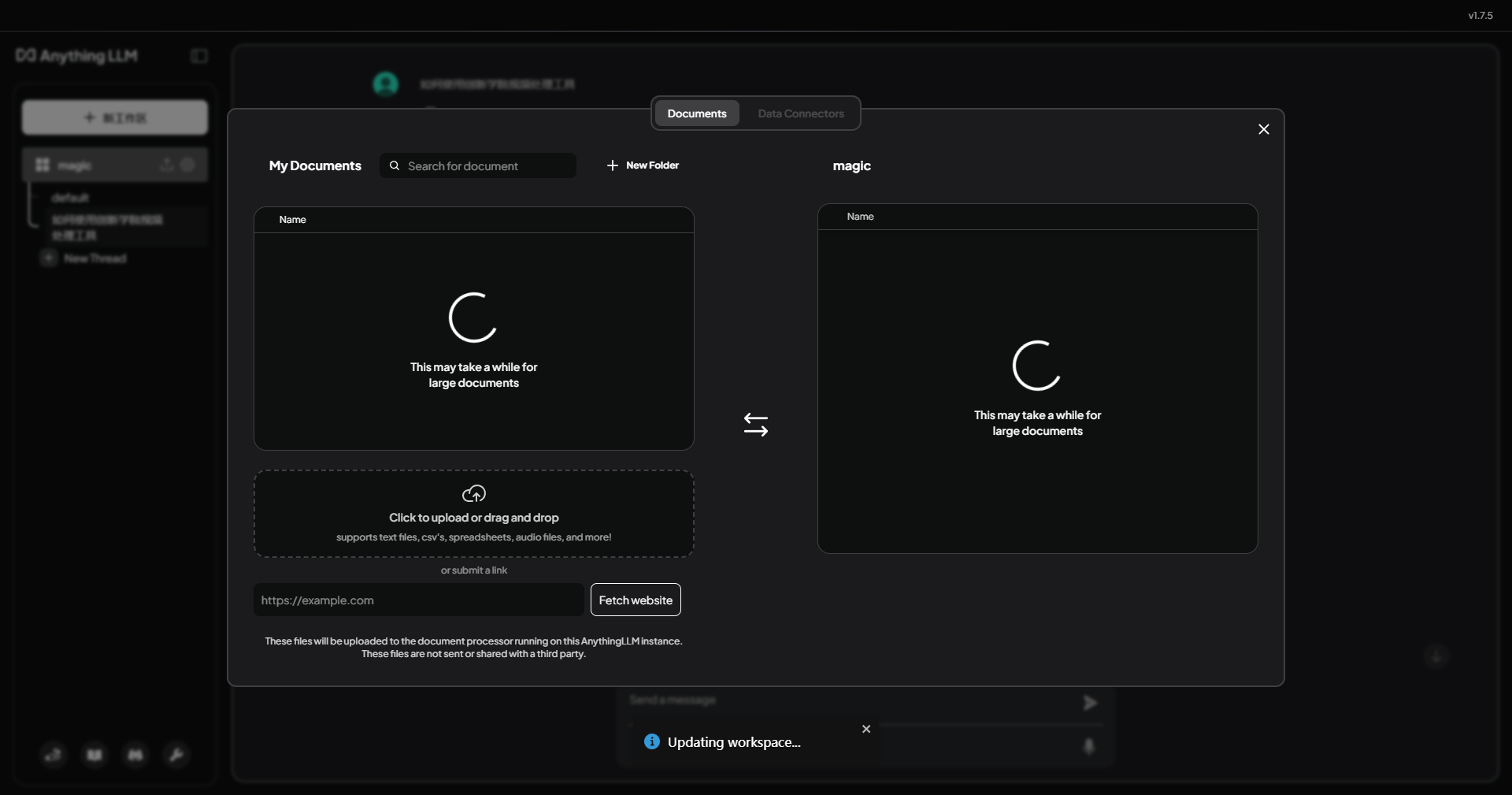
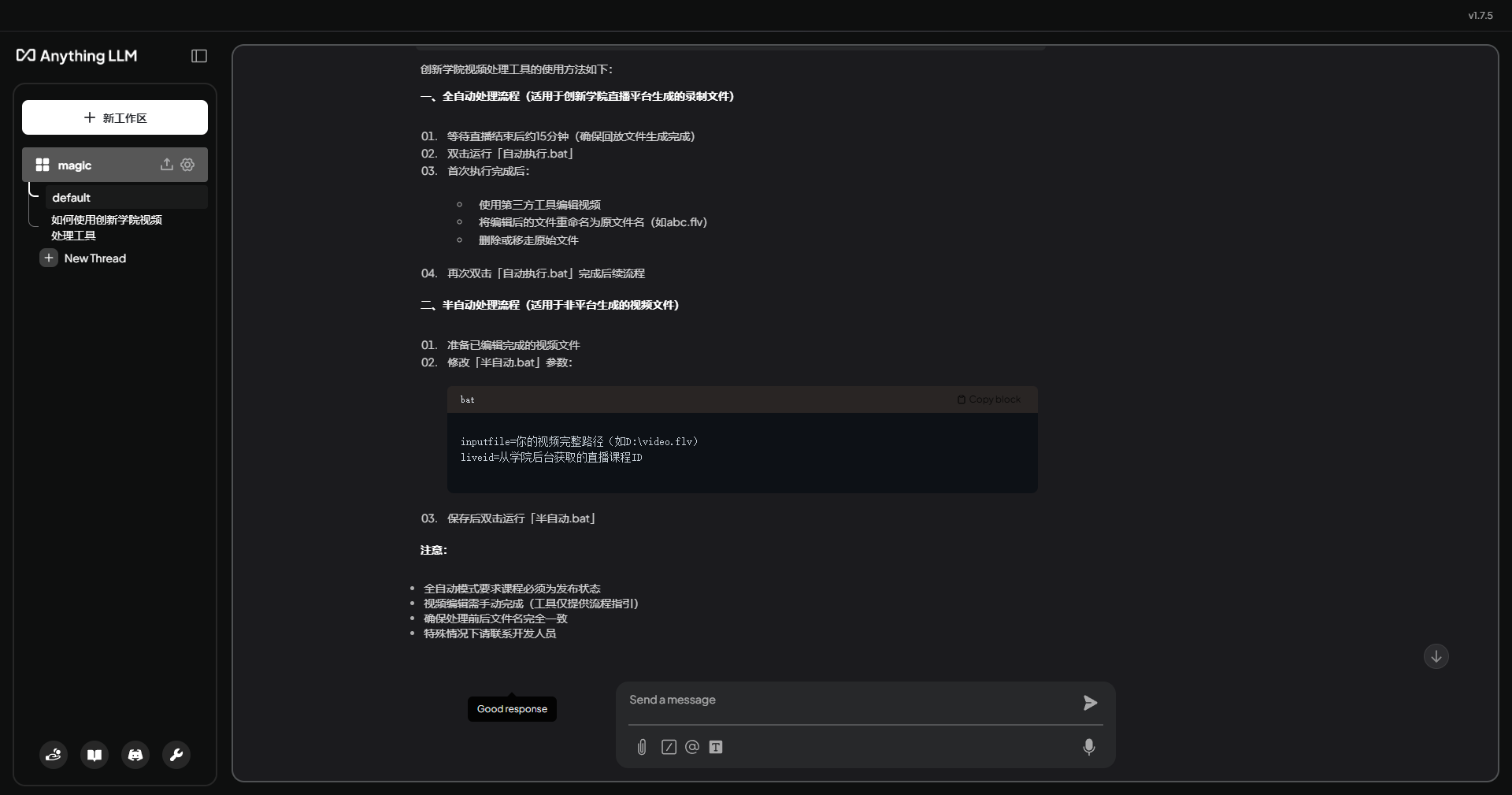
如果你是从事运营,产品,咨询,客服等需要对内部产品细节十分了解的岗位,或者就是普通用户,想更多的了解一些感兴趣的内容,借助这个软件,就可以定制一个专属的文档助手,不用再为繁杂的软件操作细节抓瞎,非常方便!
其他
除了提供基于桌面的应用,AnythingLLM也提供了云方案,同时也有本地部署的方案,和Ollama,vLLm的方向差不多,算是个全能型选手,感兴趣的可以参考一下官方文档(https://github.com/Mintplex-Labs/anything-llm)的介绍!
MaxKb
简介
商用层面的话,MaxKb提供的解决方案我个人感觉还是挺清晰的,他们的产品有软件应用,有开发框架,还和主流云厂商做了对接,提供了便捷的插件,也有一体机这种硬件,关于更多他们的介绍,大家可以看一下它的官网:https://maxkb.cn/
本地部署
这里我主要聊一下本地部署MaxKb的RAG产品,开箱即用,非常方便。
官网提供了,离线,在线,阿里云,腾讯云,1panel,命令行这几种安装方式,我这里条件有限,就演示下在本地使用docker在线部署的方式。
首先根据文档确认下自己的机器是否满足安装条件,确认完成后,就可以拉取镜像安装了。
docker run -d --name=maxkb --restart=always -p 8080:8080 -v ~/.maxkb:/var/lib/postgresql/data -v ~/.python-packages:/opt/maxkb/app/sandbox/python-packages registry.fit2cloud.com/maxkb/maxkb
安装好后的效果如下
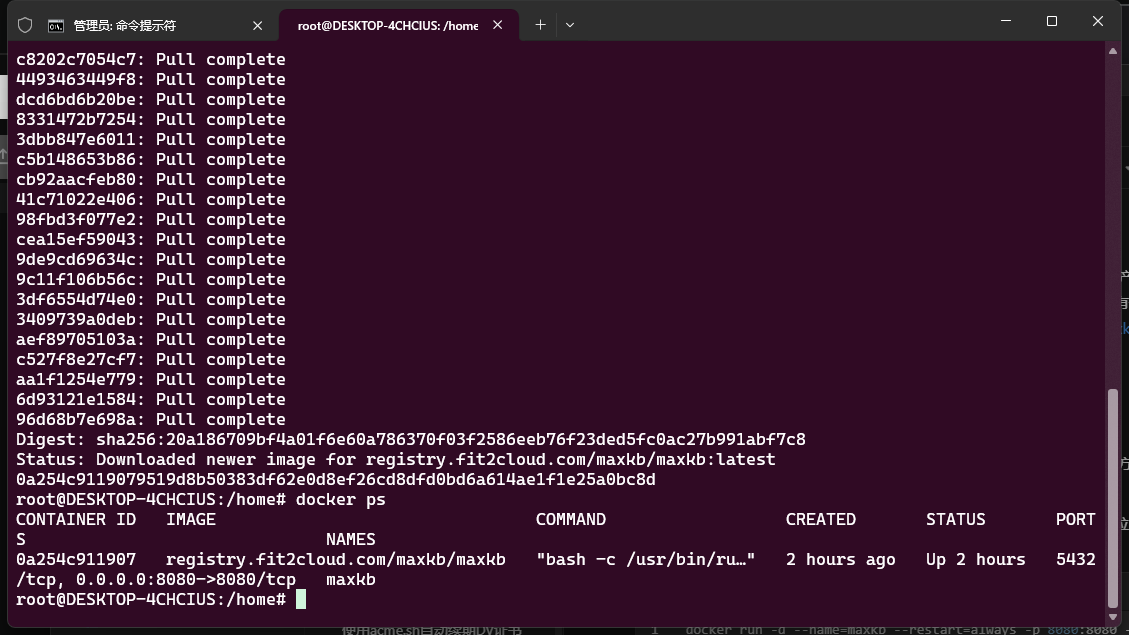
容器启动后,监听8080端口,可以直接在浏览器访问,之后使用默认的账号密码,就可以登录进来了。
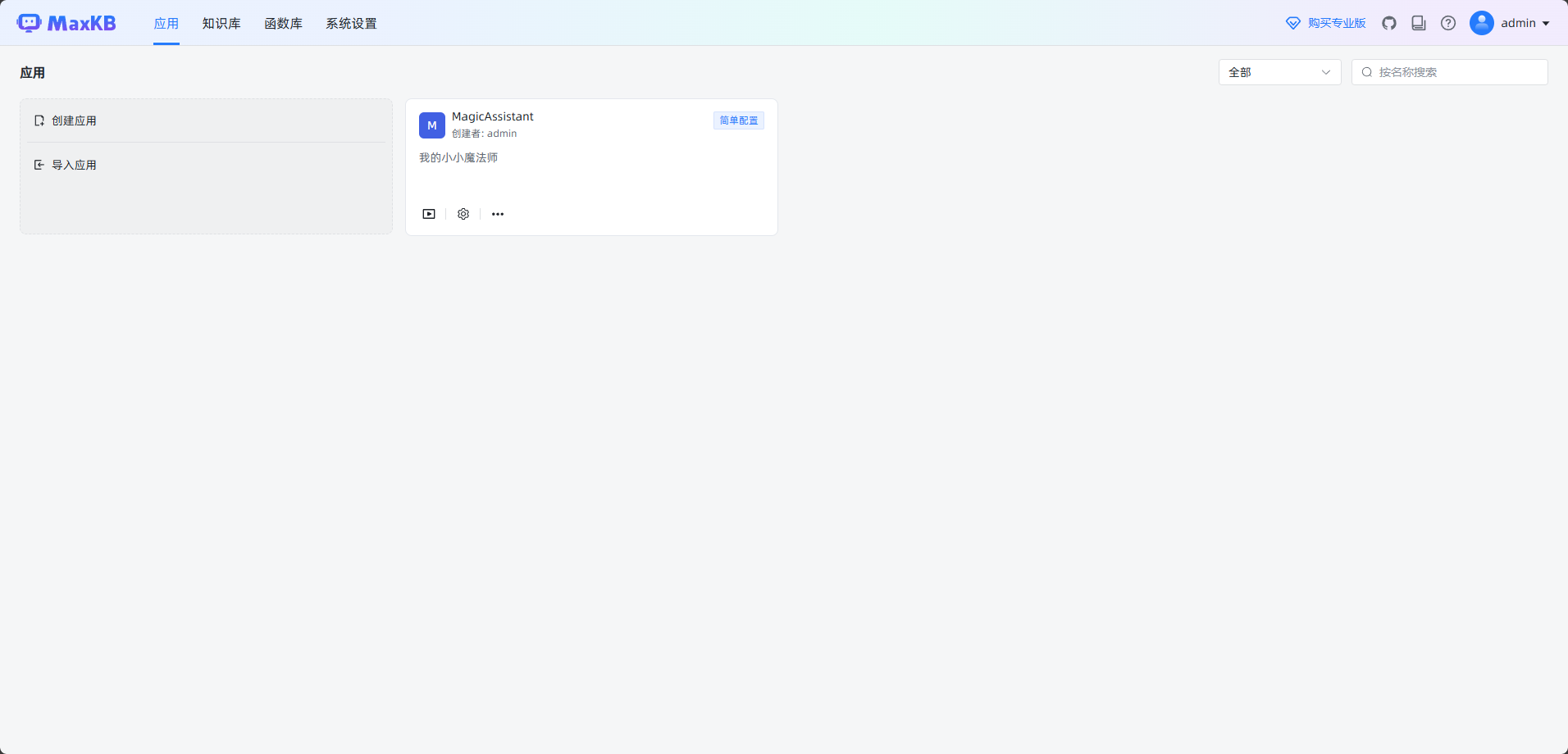
实际上官方的文档也十分清楚,还是推荐看文档。
创建应用
后续的流程,实际上和AnythingLLM的逻辑差不多,也是先创建应用,然后绑定AI模型,MaxKb作为国产软件,对国产模型的支持度好很多。
而且,也支持本地模型。
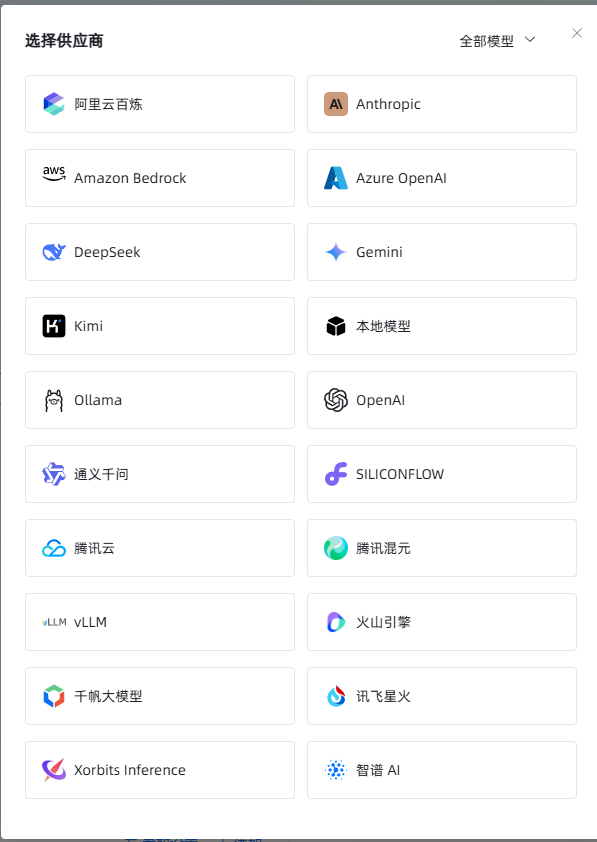
这里,我绑定一个kimi的模型,其他道理一样,都是需要自己有一个APIkey。
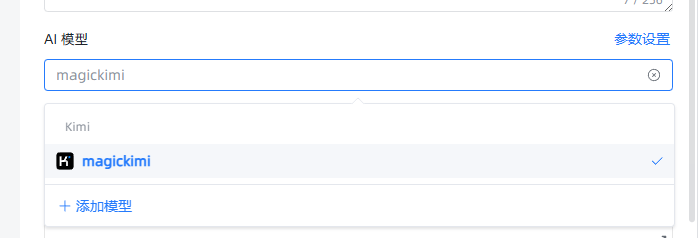
其他参数可以先不管,去配置下知识库
配置知识库
配置知识库目的就是做检索增强(RAG),软件界面提供的操作流程也非常清晰方便,傻瓜式的按引导操作即可。
- 创建
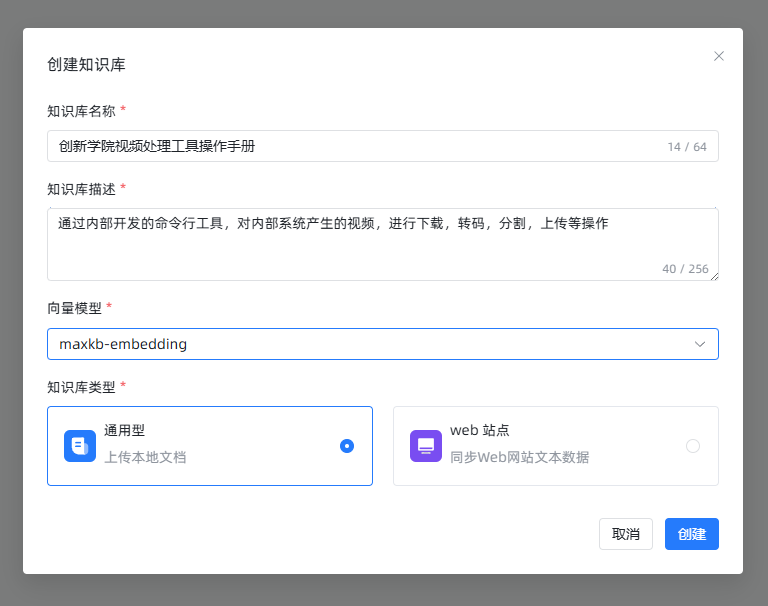
- 上传本地文档
- 分段
- 训练
- 训练完成

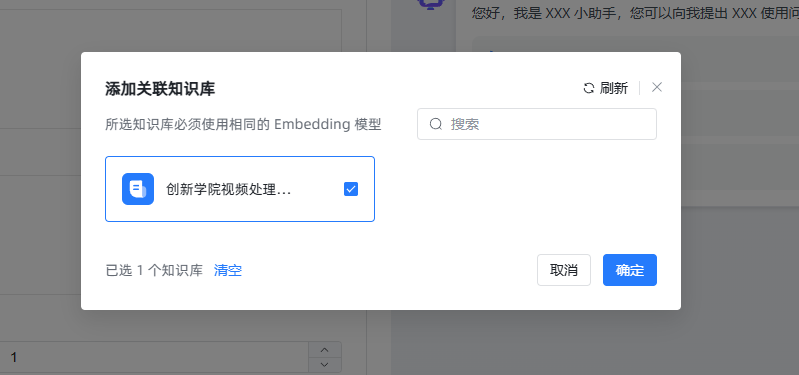
关联知识库
回到刚才创建的应用上,如果刚才没有关联知识库的话,现在可以关联一下
测试
绑定完以后,可以在旁边的调试窗口,测试一下效果
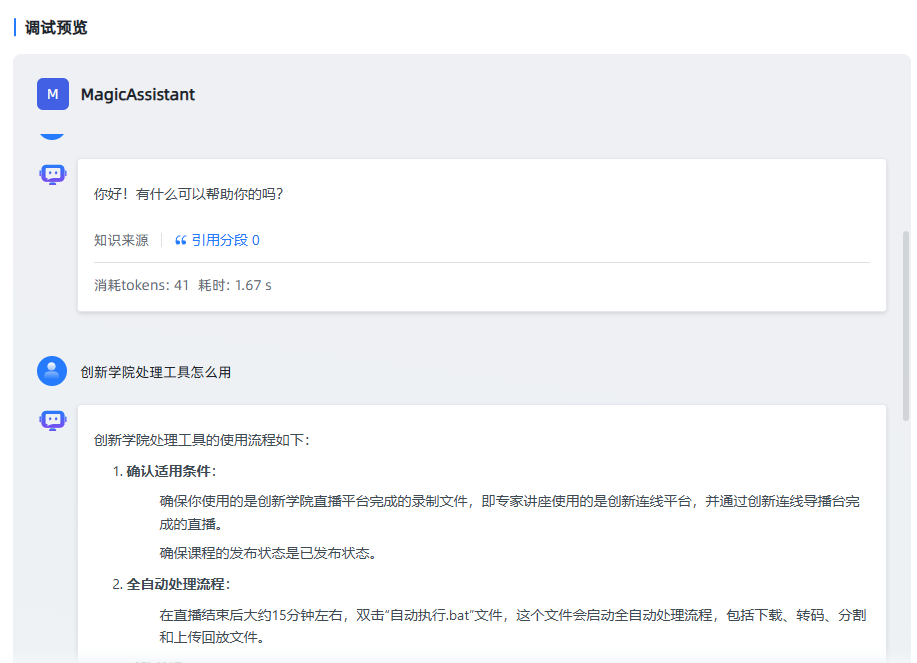
可以看到,它的回答正式根据知识库里的内容输出的。
保存发布
测试没问题以后,就可以发布应用了,注意,这个应用是我们自己训练的应用哟,虽然它的底座还是公有模型,但已经可以使用我们本地的私有数据了,而且,没有隐私安全问题。
发布之后,可以到概览界面,使用MaxKb为我们创建的url,这个就可以放到私有业务的系统里使用了。
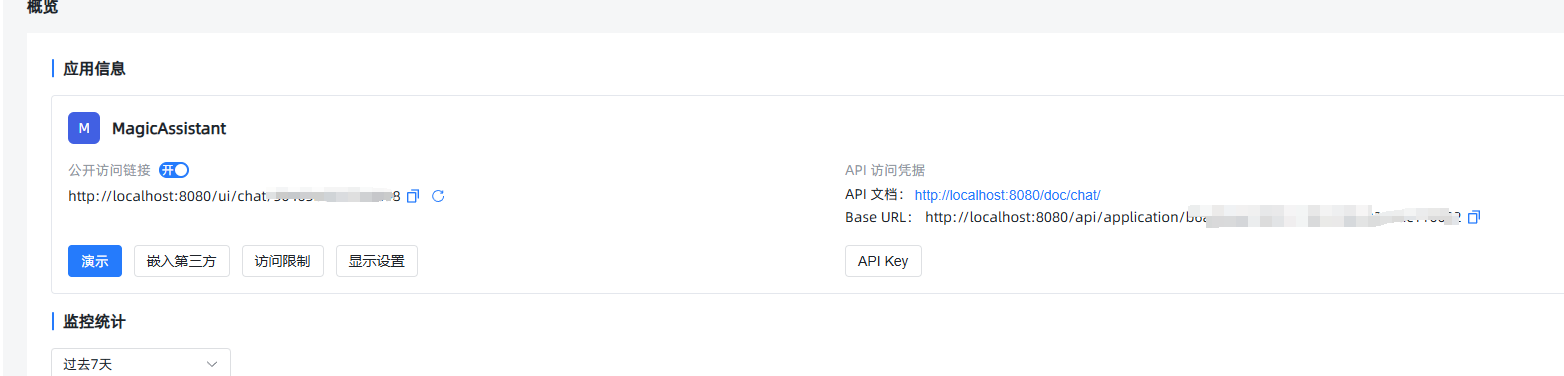
嵌入第三方
它这里还提供了一个非常好的功能,叫做“嵌入第三方”,当我们把模型配置好以后,可以点击这个“嵌入第三方”按钮,复制他为我们生成的代码到我们已有的其他系统里,就可以很方便的使用这个私有模型了。
我随便找了个页面,放上他为我们生成的代码,效果如下,丝滑流畅~
其他智能体
构建专属智能体的方向,还有Dify,扣子等,这些就稍微有一点门槛了,感兴趣的可以了解下。
当然如果有开发基础,也可以开发构建更加契合业务需求的智能体。说到这,笔者之前也写过这方面的博客,如《再尝Semantic Kernel,planning特性很香》,大家可以去给捧个场哈哈。
而我刚介绍的方案基本都不太需要有开发基础就能上手掌握,尤其AnythingLLM,适用于绝大部分人。
结语
好了,基本就是这些啦,再推荐一本关于大模型的书,叫做《大模型导论》,希望AI时代,我们每个人都能找准自己的定位,利用好AI,增强自己,而不是被取代。
最后再多说一句,大模型飞速发展,存在信息差是肯定的,如果你真的不了解AI,短期内也不想了解,就不要轻易相信那些在你面前扯各种AI概念的人,尤其是不熟的人,现在这方面的诈骗也挺多的,保护好自己。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 30
30 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)