DeepSeek模型介绍及选择建议
通过对DeepSeek的介绍,让各位读者简单认识DeepSeek。
除了DeepSeek之外,其它六家也被投资界称为中国大模型企业六小龙(智谱AI、百川智能、月之暗面、零一万物、阶跃星辰、MiniMax)。
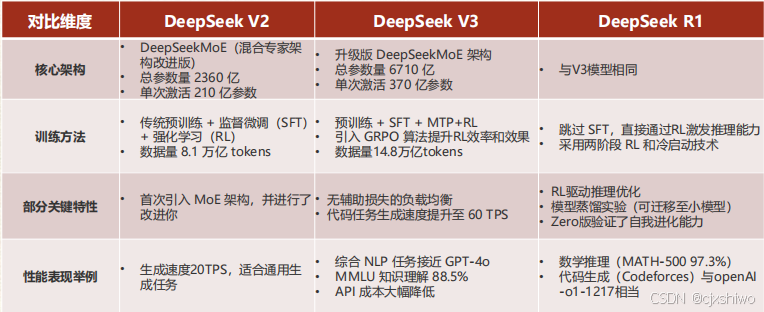
通过强化学习自动学习复杂的推理行为(自我验证与反思),然后随着训练的深入,模型逐步提升了对复杂任务的解答能力,并显著提高了模型推理能力。在数学和编程基准测试集上,与open AI-o1模型的表现相当并大幅超越其它现有大模型。
DeepSeek模型特点总结
基础架构:
1、 混合专家模型(MoE):DeepSeek采用MoE架构,通过动态选择最适合输入数据的专家模块进行处理,提升推理能力和效率。
2、 无辅助损失的负载均衡策略(EP):该策略使DeepSeekMoE在不对优化目标产生干扰的前提下,实现各个专家的负载均衡,避免了某些专家可能会被过度使用,而其他专家则被闲置的现象。
3、 多头潜在注意力机制(MLA):MLA通过低秩压缩减少Key-Value缓存,显著提升推理效率。
4、 强化学习驱动(RL):DeepSeek-R1在训练中大规模应用强化学习,将传统的PPO替换为GRPO训练算法,显著提升推理能力。
5、多Token预测(MTP):通过多Token预测,Deepseek不仅提高了推理速度,还降低了训练成本。
社会价值:
1、 开源生态:DeepSeek采用开源策略,使用最为开放的MIT开源协议,吸引了大量开发者和研究人员,推动了AI技术的发展。
2、 模型蒸馏支持:DeepSeek-R1同时发布了多个模型蒸馏。虽然这些蒸馏模型的生产初衷是为了验证蒸馏效果,但在实质上帮助用户可以训练更小型的模型以满足不同应用场景需求,也给用户提供更多的抑制了DeepSeek R1满血版模型的能力的小模型选择(虽然也给市场和用户造成了很多困扰)。
3、 AI产品和技术的普及教育:对于社会,认识到AI是一个趋势,不是昙花一现;对于市场,用户开始主动引入AI,不用教育了;对于大模型企业, 越发开始重视infra工程的价值了。
模型蒸馏的定义
1、 通俗解释:模型蒸馏就像是让一个“老师”(大模型)把知识传授给一个“学生”(小模型),让“学生”变成“学霸”。
2、 正式定义:模型蒸馏是一种将大型复杂模型(教师模型)的知识迁移到小型高效模型(学生模型)的技术。
模型蒸馏的原理
1、 教师模型的训练:先训练一个性能强大但计算成本高的教师模型。
2、 生成软标签:教师模型对数据进行预测,得到每个样本的概率分布,这些就是软标签。
3、 训练学生模型:用软标签和硬标签共同训练学生模型。
4、 优化与调整:通过调整超参数,优化学生模型的性能。
蒸馏技术的优势
1、 模型压缩:学生模型参数少,计算成本低,更适合在资源受限的环境中部署。
2、 性能提升:学生模型通过学习教师模型的输出概率分布,能够更好地理解数据的模式和特征。
3、 效率提高:学生模型训练所需的样本数量可能更少,训练成本降低。
DeepSeek-R1蒸馏模型-能力对比
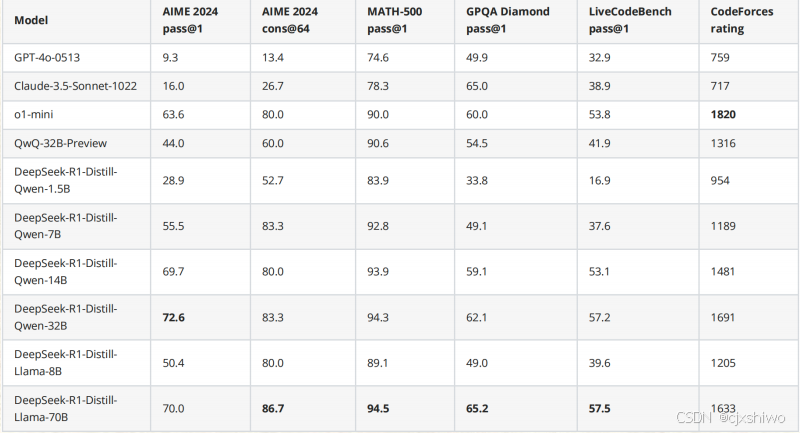
DeepSeek蒸馏版的选择经验
1、 千万别用1.5B和8B只适合玩玩,不适合做正经业务;
2、 做自然语言对话7B就很好用了;
3、 预算有限又想搞事情就选14B;
4、 要做知识问答选32B,对代码支持也不错;
5、 70B性价比最低,与32B性能类似,成本翻倍,谨慎使用。
下期预告:DeepSeek本地部署

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)