第六天:还有一件事,DeepSeek-V3/R1 推理系统概述
在人工智能(AI)技术快速发展的今天,DeepSeek 团队推出了其全新的 DeepSeek-V3/R1推理系统。这一系统旨在通过更高的吞吐量和更低的延迟,推动 AGI(通用人工智能)的高效发展。为了实现这一目标,DeepSeek 采用了跨节点专家并行(Expert Parallelism,EP)技术,显著提高了 GPU 的计算效率,并在降低延迟的同时,扩展了批处理规模。
在人工智能(AI)技术快速发展的今天,DeepSeek 团队推出了其全新的 DeepSeek-V3/R1推理系统。这一系统旨在通过更高的吞吐量和更低的延迟,推动 AGI(通用人工智能)的高效发展。为了实现这一目标,DeepSeek 采用了跨节点专家并行(Expert Parallelism,EP)技术,显著提高了 GPU 的计算效率,并在降低延迟的同时,扩展了批处理规模。
系统设计原则
为 DeepSeek-V3/R1 推理提供服务的优化目标是:更高的吞吐量和更低的延迟。
为了优化这两个目标,我们的解决方案采用了跨节点专家并行(EP)技术。
- 首先,EP 大幅扩展了批处理规模,提高了 GPU 矩阵计算效率,提升了吞吐量。
- 其次,EP 将专家分布在 GPU 上,每个 GPU 只处理一小部分专家(减少内存访问需求),从而降低延迟。
然而,EP 增加了系统的复杂性,主要表现在两个方面:
- EP引入了跨节点通信。要优化吞吐量,必须设计适当的计算工作流程,使通信与计算重叠。
- EP 涉及多个节点,因此本质上需要数据并行性 (DP),并需要在不同的 DP 实例之间进行负载平衡。
本文重点介绍我们如何通过以下方式应对这些挑战:
- 利用 EP 来扩展批处理规模,
- 在计算背后隐藏通信延迟,以及
- 执行负载平衡。
大规模跨节点专家并行性 (EP)
由于 DeepSeek-V3/R1 中的专家数量众多,每层 256 个专家中只有 8 个被激活,因此模型的高稀疏性要求整体批处理规模非常大。 这就确保了每个专家都有足够的批处理规模,从而实现了更高的吞吐量和更低的延迟。 大规模跨节点 EP 至关重要。
由于我们采用了预填充-解码分解架构,因此我们在预填充和解码阶段采用了不同程度的并行:
- 预填充阶段 [路由专家 EP32、MLA/共享专家 DP32]: 每个部署单元跨越 4 个节点,拥有 32 个冗余路由专家,其中每个 GPU 处理 9 个路由专家和 1 个共享专家。
- 解码阶段 [路由专家 EP144、MLA/共享专家 DP144]: 每个部署单元跨越 18 个节点,拥有 32 个冗余路由专家,其中每个 GPU 管理 2 个路由专家和 1 个共享专家。
计算-通信重叠
大规模跨节点 EP 会带来巨大的通信开销。为了缓解这一问题,我们采用了双批次重叠策略,通过将一批请求分成两个微批次来隐藏通信成本并提高总体吞吐量。
在预填充阶段,这两个微批次交替执行,其中一个微批次的通信成本隐藏在另一个微批次的计算之后。
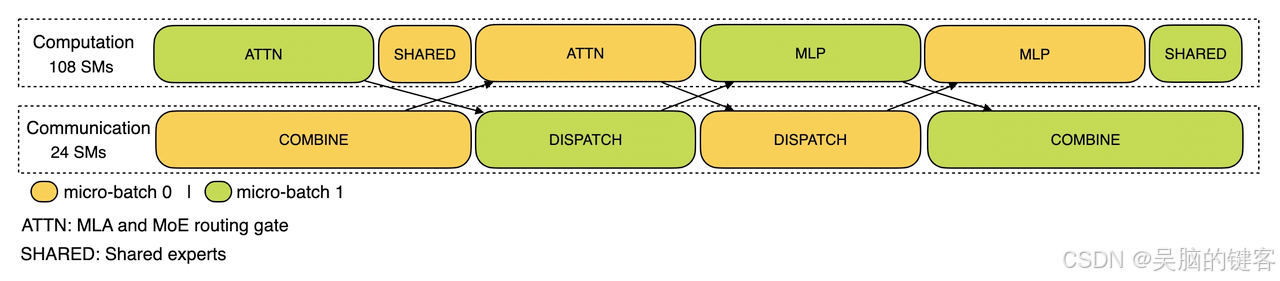
预填充阶段的通信-计算重叠
在解码阶段,不同阶段的执行时间是不平衡的。因此,我们将注意力层细分为两个步骤,并使用 5 级流水线来实现通信-计算的无缝重叠。
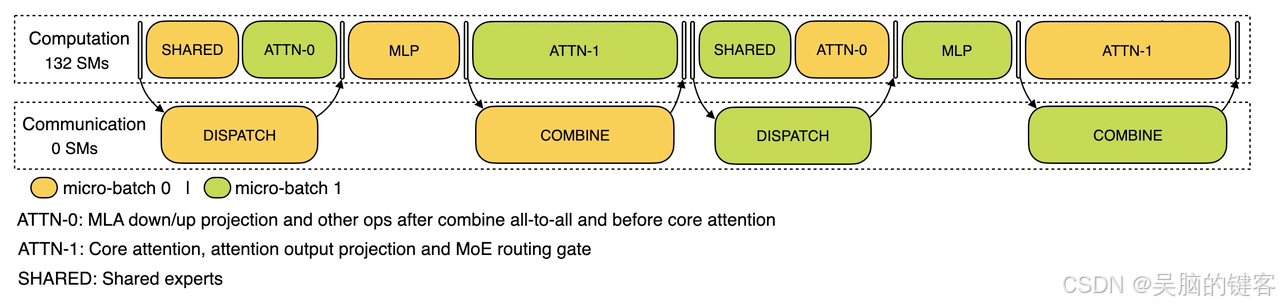
解码阶段的通信-计算重叠
有关我们的通信-计算重叠机制的更多详细信息,请访问 https://github.com/deepseek-ai/profile-data。
实现最佳负载平衡
大规模并行(包括 DP 和 EP)带来了一个严峻的挑战:如果单个 GPU 的计算或通信负荷过重,它就会成为性能瓶颈,拖慢整个系统的运行速度,同时让其他 GPU 闲置。为了最大限度地提高资源利用率,我们努力平衡所有 GPU 的计算和通信负载。
1.预填充负载平衡器
- 关键问题:DP 实例的请求数和序列长度不同,导致核心关注计算和调度发送负载不平衡。
- 优化目标:
- 在 GPU 之间平衡核心注意计算(核心注意计算负载平衡)。
- 均衡每个 GPU 的输入标记计数(调度发送负载均衡),防止在特定 GPU 上进行长时间处理。
2. 解码负载平衡器
- 关键问题:DP 实例的请求数和序列长度不均衡,导致核心关注计算(与 KVCache 使用有关)和调度发送负载不均衡。
- 优化目标:
- 在 GPU 之间平衡 KVCache 的使用(核心注意计算负载平衡)。
- 均衡每个 GPU 的请求计数(调度发送负载平衡)。
3. 专家级并行负载平衡器
- 关键问题:对于给定的 MoE 模型,存在固有的高负载专家,导致不同 GPU 之间的专家计算工作量不平衡。
- 优化目标:
- 平衡每个 GPU 上的专家计算(即最大限度地降低所有 GPU 的最大调度接收负载)。
DeepSeek 在线推理系统示意图
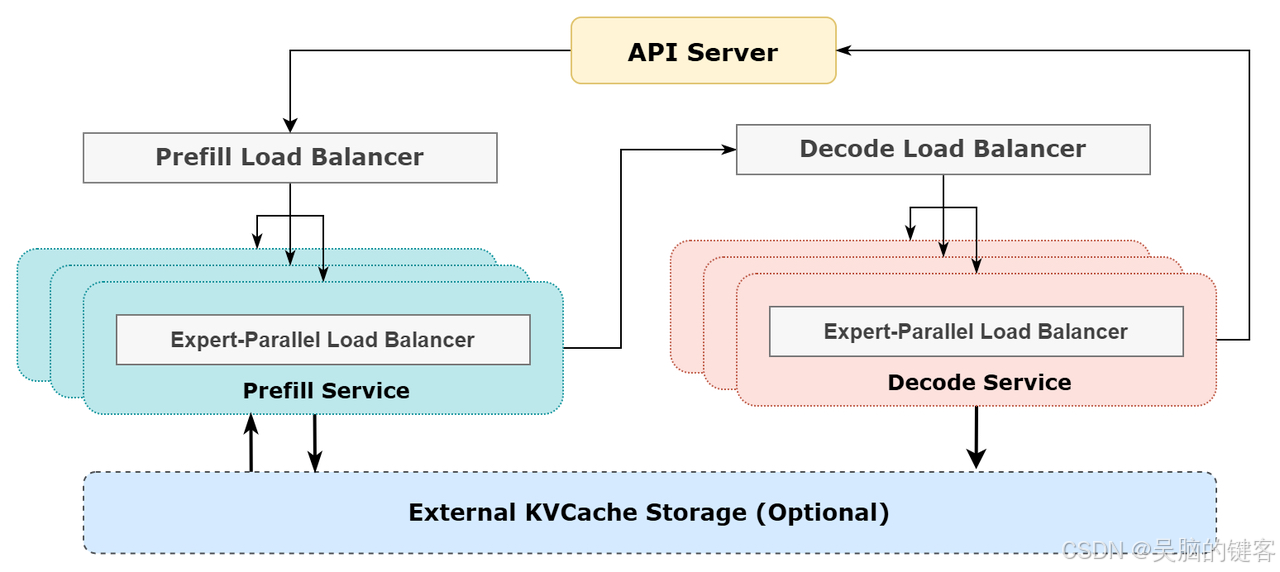
DeepSeek 在线推理系统示意图
DeepSeek 在线服务统计
所有DeepSeek-V3/R1推理服务均在H800 GPU上提供,精度与训练一致。
具体而言,矩阵乘法和调度传输采用与训练一致的 FP8 格式,
核心工作重点计算和组合传输采用 BF16 格式,确保最佳服务性能。
此外,由于白天服务负载高,晚上负载低,我们实施了一种机制,在白天高峰时段在所有节点部署推理服务。
在夜间低负荷时段,我们减少推理节点,将资源分配给研究和培训。
在过去的 24 小时内(UTC+8 02/27/2025 中午 12:00 至 02/28/2025 中午 12:00),V3 和 R1 推理服务的合并峰值节点占用率达到 278,平均占用率为 226.75 个节点(每个节点包含 8 个 H800 GPU)。
假设一个 H800 GPU 的租赁费用为每小时 2 美元,则每天的总费用为 87,072 美元。
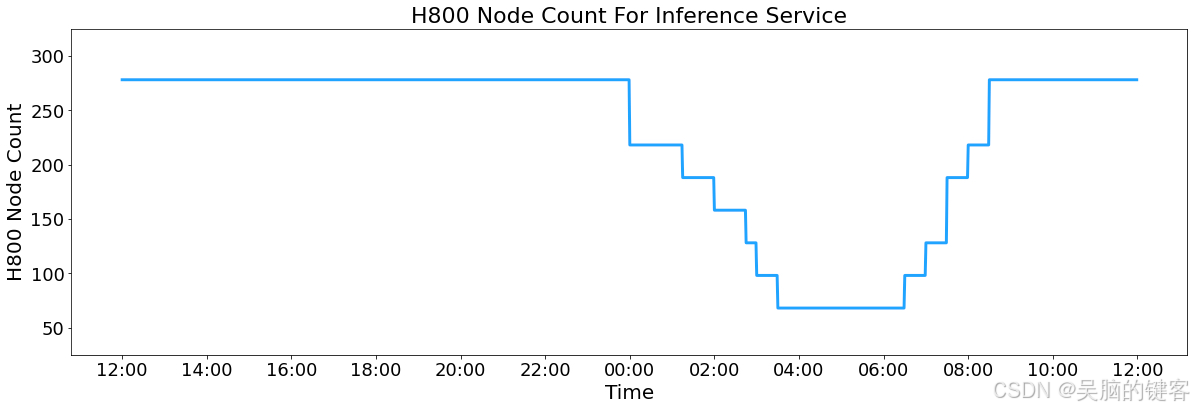
H800 Node Count For Inference Service.png
在 24 小时统计时段内(UTC+8 02/27/2025 12:00 PM 至 02/28/2025 12:00 PM),V3 和 R1:
- 输入令牌总数:608B,其中 342B 令牌(56.3%)进入磁盘 KV 缓存。
- 输出令牌总数:168B。平均输出速度为每秒 20-22 个标记,每个输出标记的 kvcache 平均长度为 4 989 个标记。
- 在预填充过程中,每个 H800 节点的平均吞吐量为每秒约 73.7k 标记输入(包括缓存命中),在解码过程中,平均吞吐量为每秒约 14.8k 标记输出。
上述统计数据包括来自网页、APP 和 API 的所有用户请求。如果所有代币都按照 DeepSeek-R1 的定价(*)计费,则每日总收入为 562 027 美元,成本利润率为 545%。
(*) R1 Pricing: $0.14/M input tokens (cache hit), $0.55/M input tokens (cache miss), $2.19/M output tokens.
然而,由于以下原因,我们的实际收入大幅减少:
- DeepSeek-V3的定价明显低于R1,
-只有部分服务实现了货币化(Web 和 APP 访问仍然免费), - 非高峰时段自动应用夜间折扣。
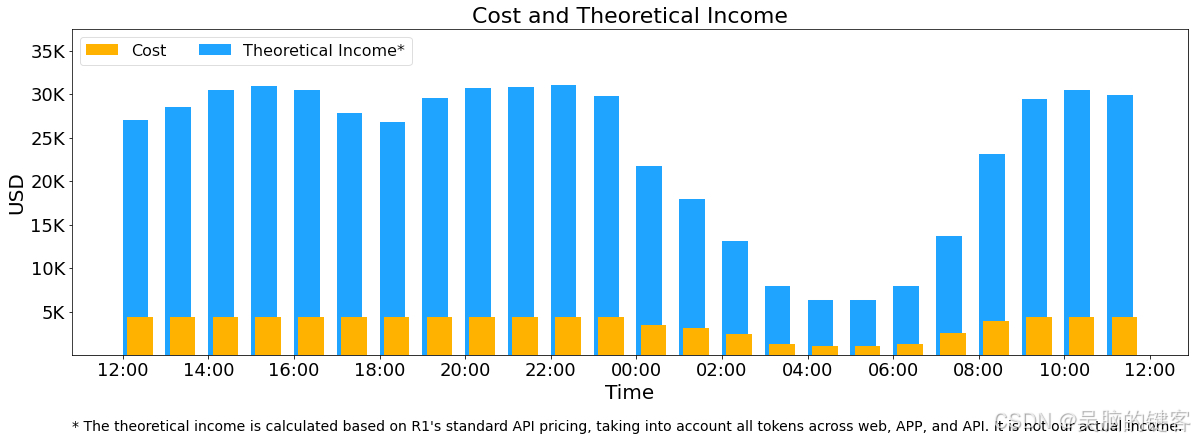
成本和理论收入
原文
https://github.com/deepseek-ai/open-infra-index/blob/main/202502OpenSourceWeek/day_6_one_more_thing_deepseekV3R1_inference_system_overview.md

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 15
15 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)