
Ktransformers实践-仅用14G显存就能跑Deepseek-R1 671B
KTransformers 的原理主要基于以下核心技术:1. **异构计算与任务卸载**:通过混合专家(MoE)架构的稀疏性,将稀疏矩阵卸载到 CPU/DRAM 处理,稠密部分保留在 GPU 上,从而大幅降低显存需求。2. **高性能算子优化**:- 在 CPU 端,使用 Llamafile 内核结合多线程、任务调度和负载均衡优化,提升推理效率。- 在 GPU 端,引入 Marlin 内核,专门优
前言
KTransformers官方仓库:https://github.com/kvcache-ai/ktransformers
利用kimi生成的Ktransformers的原理:
KTransformers 的原理主要基于以下核心技术:
1. **异构计算与任务卸载**:通过混合专家(MoE)架构的稀疏性,将稀疏矩阵卸载到 CPU/DRAM 处理,稠密部分保留在 GPU 上,从而大幅降低显存需求。
2. **高性能算子优化**:
- 在 CPU 端,使用 Llamafile 内核结合多线程、任务调度和负载均衡优化,提升推理效率。
- 在 GPU 端,引入 Marlin 内核,专门优化量化矩阵计算,相比传统库加速 3.87 倍。
3. **量化与存储优化**:采用 4bit 量化技术,显著压缩模型存储需求,仅需 24GB 显存即可运行 671B 参数模型。
4. **CUDA Graph 优化**:通过 CUDA Graph 减少 Python 调用开销,降低 CPU/GPU 通信断点,实现高效的异构计算协同。
5. **模板注入框架**:提供基于 YAML 的模板注入框架,支持用户灵活切换量化策略和内核替换,适应不同场景。
这些技术的结合使得 KTransformers 能够在资源受限的环境中实现高效的推理性能。
一、如何使用
首先,使用 lscpu命令,看下我们的服务器是单插槽还是双插槽版本。

我这台机器有2个numa节点,所以是双插槽版本
接下来,我们按照文档:https://github.com/kvcache-ai/ktransformers/blob/main/doc/zh/DeepseekR1_V3_tutorial_zh.md
进行ktransformers的安装即可
我这里按照V0.2的双插槽版本安装,你也可以试试V0.3
中途碰到的问题,自行解决,基本都可以通过google解决
缺啥装啥就行了
模型下载路径:https://modelscope.cn/models/bartowski/DeepSeek-R1-GGUF/summary
用别的版本的Q4_K_M应该也行
下载命令:
modelscope download --model bartowski/DeepSeek-R1-GGUF --include "DeepSeek-R1-Q4_K_
M/*" --local_dir ./DeepSeek-R1-Q4_K_M
整个应该有377G
除了模型权重之外,我们还需要下载模型的其它配置,这个需要从Deepseek-R1原始仓库下载:
https://modelscope.cn/models/deepseek-ai/DeepSeek-R1/summary
下载命令
GIT_LFS_SKIP_SMUDGE=1 git clone https://www.modelscope.cn/deepseek-ai/DeepSeek-R1.git
只需要下载除模型权重外的其它文件即可
万事具备后,我们启动模型,启动命令:
cd ktransformers
python ./ktransformers/local_chat.py --model_path ./DeepSeek-R1 --gguf_path ./DeepSee
k-R1-Q4_K_M/DeepSeek-R1-Q4_K_M --cpu_infer 24 --max_new_tokens 1000
启动时间较长,可以摸鱼玩会手机
具体的参数说明,可以看官方介绍
二、实际效果
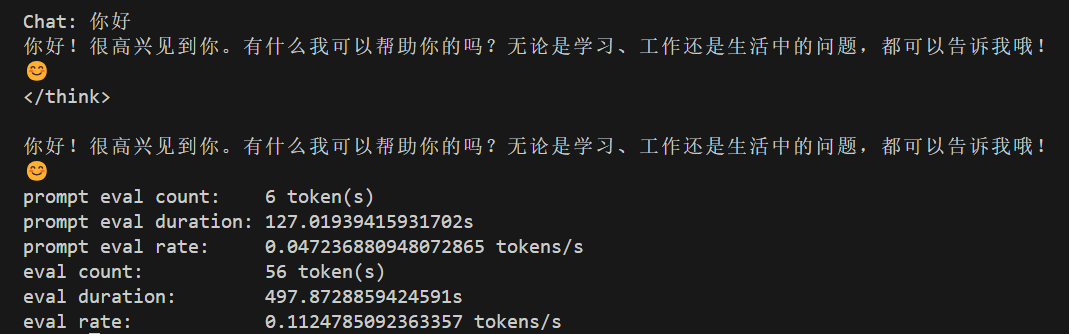
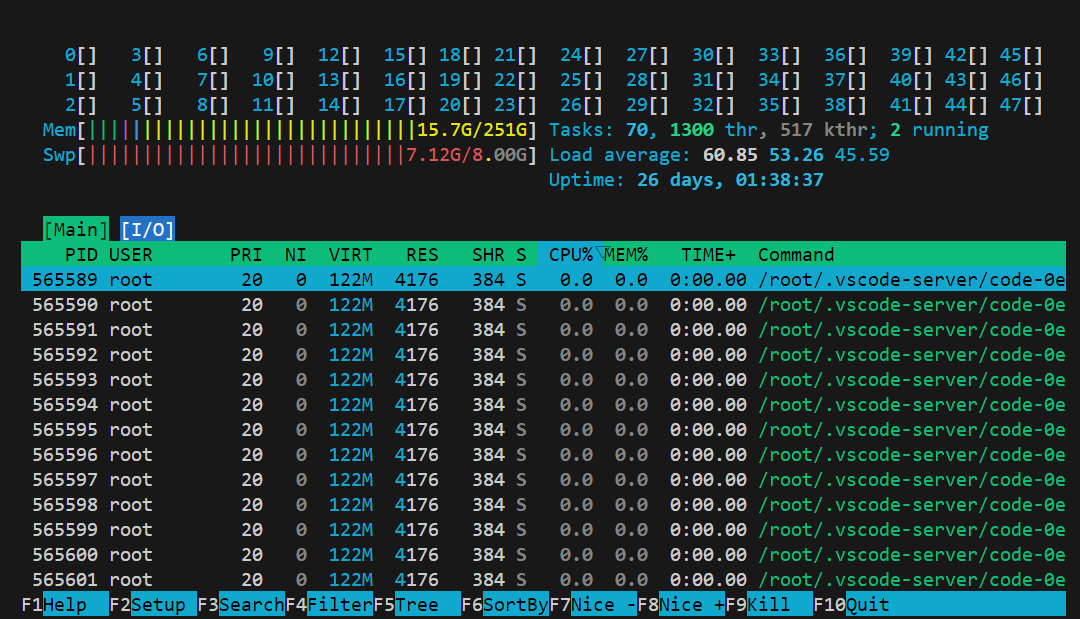
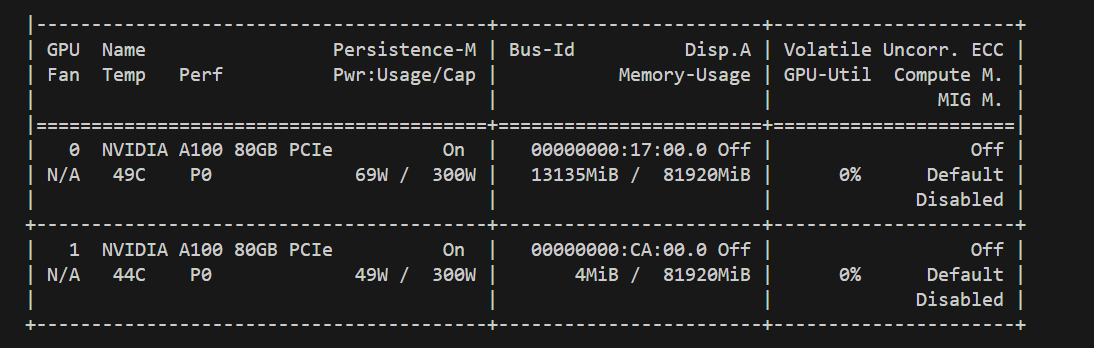
可以看到,速度出奇的慢,显存占的不多,只有占了14G不到,且GPU利用率不高,内存几乎占满了,因此,确实可以用14G显存跑Deepseek-R1 671B,但速度非常慢。
如果你想使用多张GPU进行推理,可以增加参数optimize_rule_path,指定具体的路径,配置文件可以在ktransformers/optimize/optimize_rules/找到
双卡推理命令参考:
python ./ktransformers/local_chat.py --model_path ./DeepSeek-R1 --gguf_path ./DeepSeek-R1-Q4_K_M/DeepSee
k-R1-Q4_K_M --cpu_infer 65 --max_new_tokens 1000 --optimize_rule_path ./ktransformers/optimize/optimize_rules/DeepSeek-V3-Chat-multi-gpu.yaml --use_cuda_graph false
启动后你会发现,速度压根没啥变化,甚至变得更慢了,并且,多张卡占用的显存并没有变化,加起来还是14G显存左右。
这是因为ktransformers只放了两个专家在GPU上,其它专家都放在内存中,你需要修改对应配置,将更多专家放在GPU上,一个专家大概占6G显存。
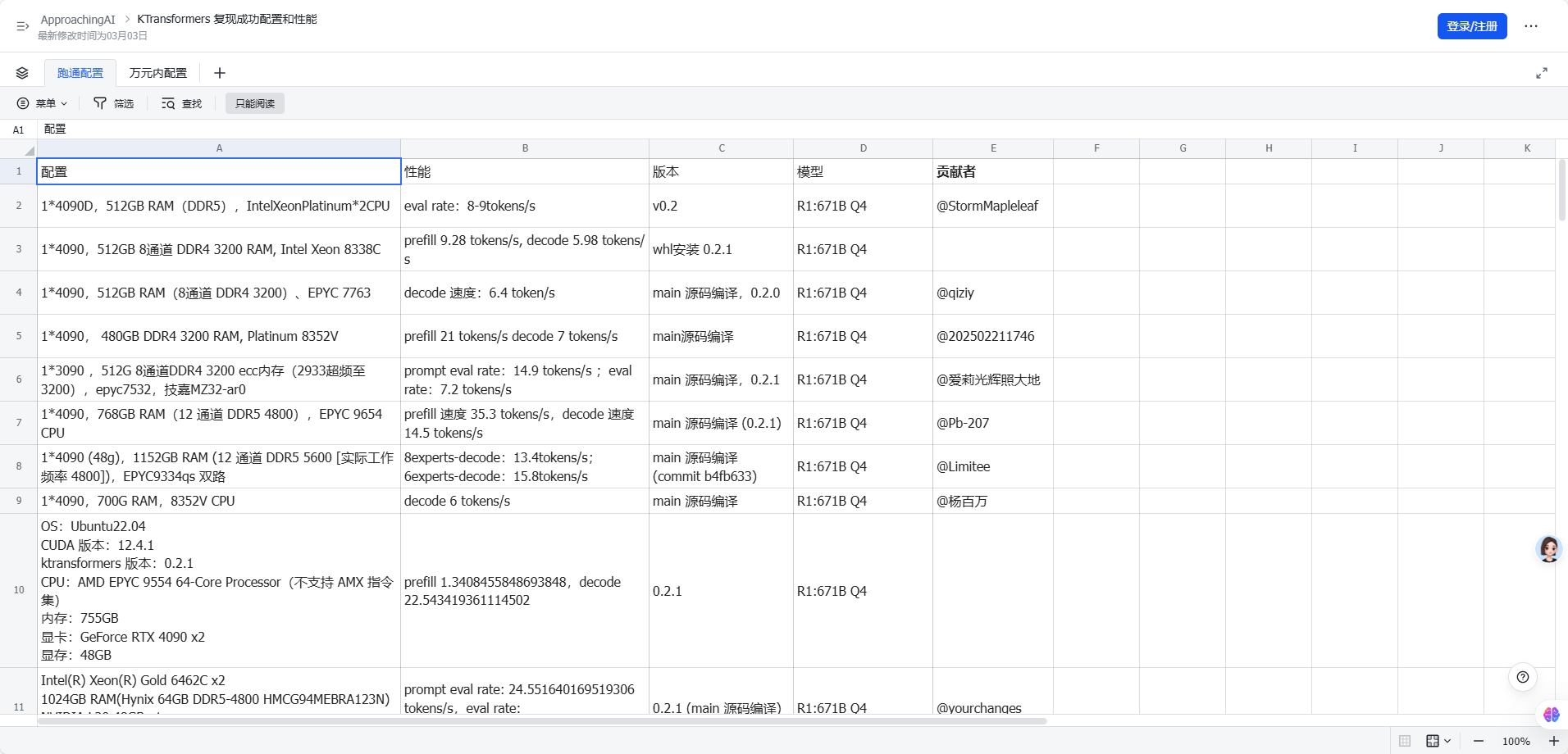
不过 就算把所有专家都放GPU上,也不会使推理速度加快多少,ktransformers主要的瓶颈在CPU和内存带宽。我这个机器,内存带宽只有10G左右,ktransformers社区其它成功案例的硬件配置及推理速度参考:https://swcil84qspu.feishu.cn/wiki/ZlhBwiSyEiZWyMkMdtDcpNyLnlf
三、总结
总体来说,ktransformers以内存换显存的做法,确实可以在低GPU资源机器上进行Deepseek R1 671B模型的推理,如果你的机器CPU、内存配置较高,确实能有个不错的推理速度,但是要配这样一套高配置的服务器,应该也要花不少钱,且几乎无并发
总结:自己玩玩可以,要想用在生产,还是需要加钱买卡

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)