【本地部署DeepSeek(含可视化界面)】的两种方法
但面对动辄20GB的模型文件、复杂的Python依赖库,很多开发者止步于部署环节。本文将揭秘两大开箱即用的deepseek本地部署方案
引言
当数学公式在屏幕上闪烁,你却卡在微分方程求解的关键步骤;当编程调试陷入死循环,深夜的屏幕荧光映出你疲惫的双眼——此刻,你是否期待一个精通数理逻辑的AI伙伴,既能秒解高数难题,又能随手写出优雅代码?
DeepSeek的出现,正让这种想象照进现实。这个由国内团队研发的开源大模型,在权威评测中数学能力超越GPT-4,代码生成准确率比肩顶级工程师,却只需消费级显卡即可本地运行。
但面对动辄20GB的模型文件、复杂的Python依赖库,很多开发者止步于部署环节。本文将揭秘两大开箱即用的本地部署方案:
小白友好的 Ollama+Chatbox 组合,10分钟实现对话式AI。
支持微调的 LLaMA-Factory 方案,解锁模型训练监控面板
带您体验「数学教授+程序员」双核智能的终极形态。
一、背景
1.1 DeepSeek模型特点
1、数学能力
例如:写作业时卡住了,拍照发题目给它,分分钟给解题步骤
2、编程能力
例如:你说"能帮我写一个图片识别代码吗?",它就能生成Python代码
# 环境要求:Python 3.8+,需安装以下库:
pip install tensorflow opencv-python numpy
import tensorflow as tf
from tensorflow.keras.applications.mobilenet_v2 import MobileNetV2, preprocess_input, decode_predictions
import cv2
import numpy as np
def image_recognition(image_path):
# 加载预训练模型(约14MB,首次运行会自动下载)
model = MobileNetV2(weights='imagenet')
# 读取并预处理图像
img = cv2.imread(image_path)
img = cv2.resize(img, (224, 224)) # MobileNet输入尺寸
img = preprocess_input(img) # 标准化处理
img = np.expand_dims(img, axis=0) # 添加批次维度
# 执行预测
predictions = model.predict(img)
# 解码预测结果(显示前3个可能类别)
decoded_predictions = decode_predictions(predictions, top=3)[0]
# 打印结果
print(f"识别结果(置信度降序):")
for i, (imagenet_id, label, prob) in enumerate(decoded_predictions):
print(f"{i+1}. {label}: {prob*100:.2f}%")
if __name__ == "__main__":
# 使用示例(替换为你的图片路径)
image_path = "test_image.jpg" # 支持jpg/png格式
image_recognition(image_path)
3、日常也聪明
普通聊天、写文章、翻译都行(类似ChatGPT的功能)
但最牛的还是数理逻辑,比普通AI更"讲道理"
二、本地部署
2.1 方法一:Ollama + Chatbox 部署
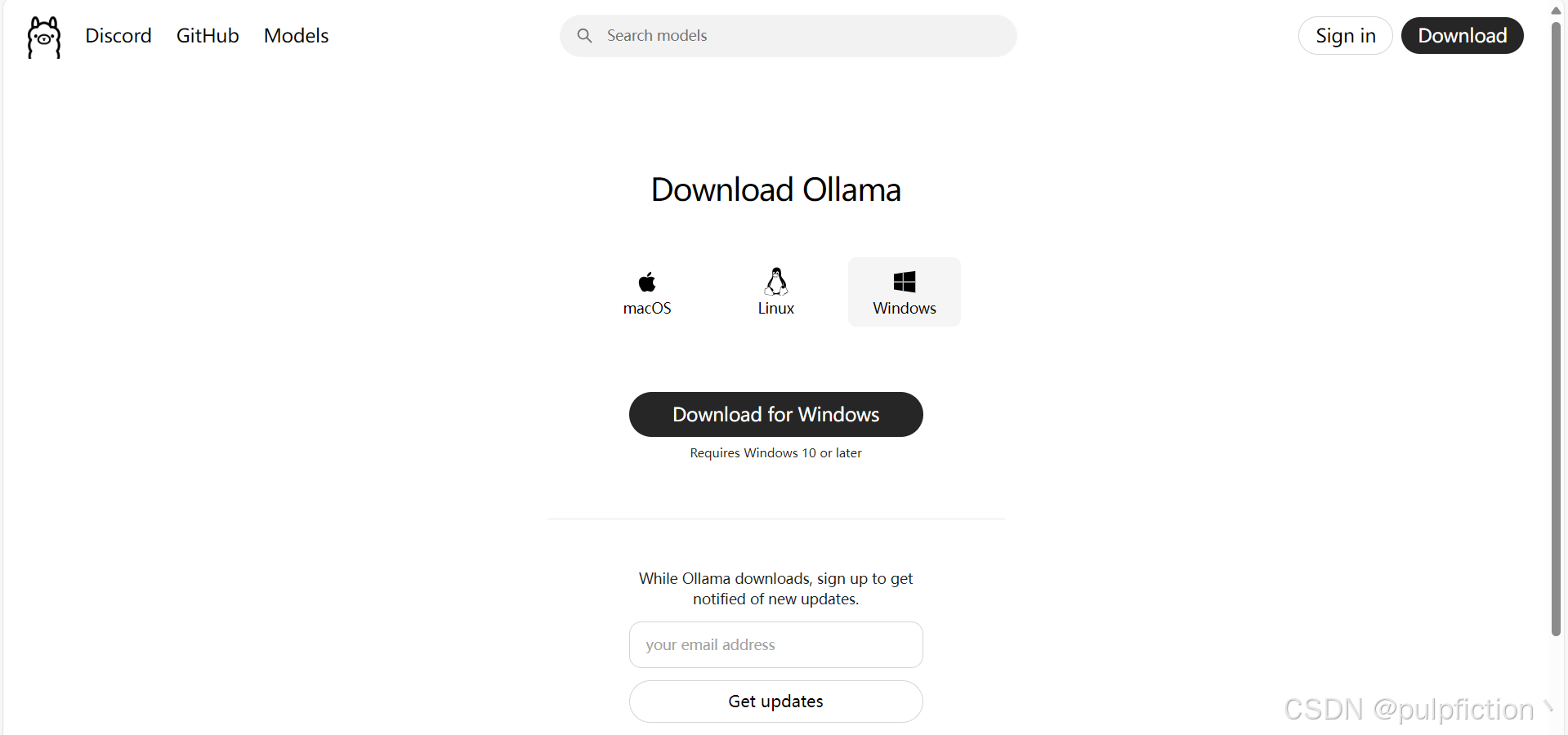
1、首先下载Ollama并安装,根据不同的操作系统选择
2、Ollama安装
安装方法有两种
- 双击鼠标安装(不推荐)
- 通过命令行安装(推荐),可自行设置安装路径
(1)命令行安装,以管理员身份打开cmd,并导航到安装包路径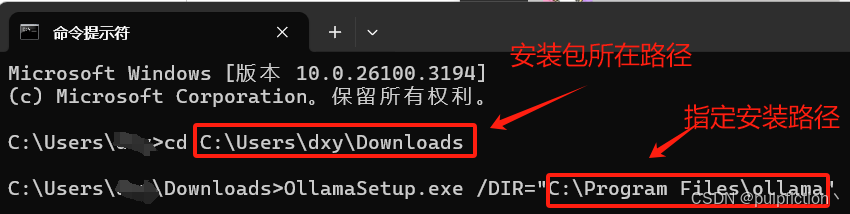
命令安装代码如下:
cd C:\Users\XX\Downloads
OllamaSetup.exe /DIR="C:\Program Files\ollama"
(2)执行命令,打开安装界面(鼠标双击一样可以弹出,但会默认安装在C盘,不能指定路径)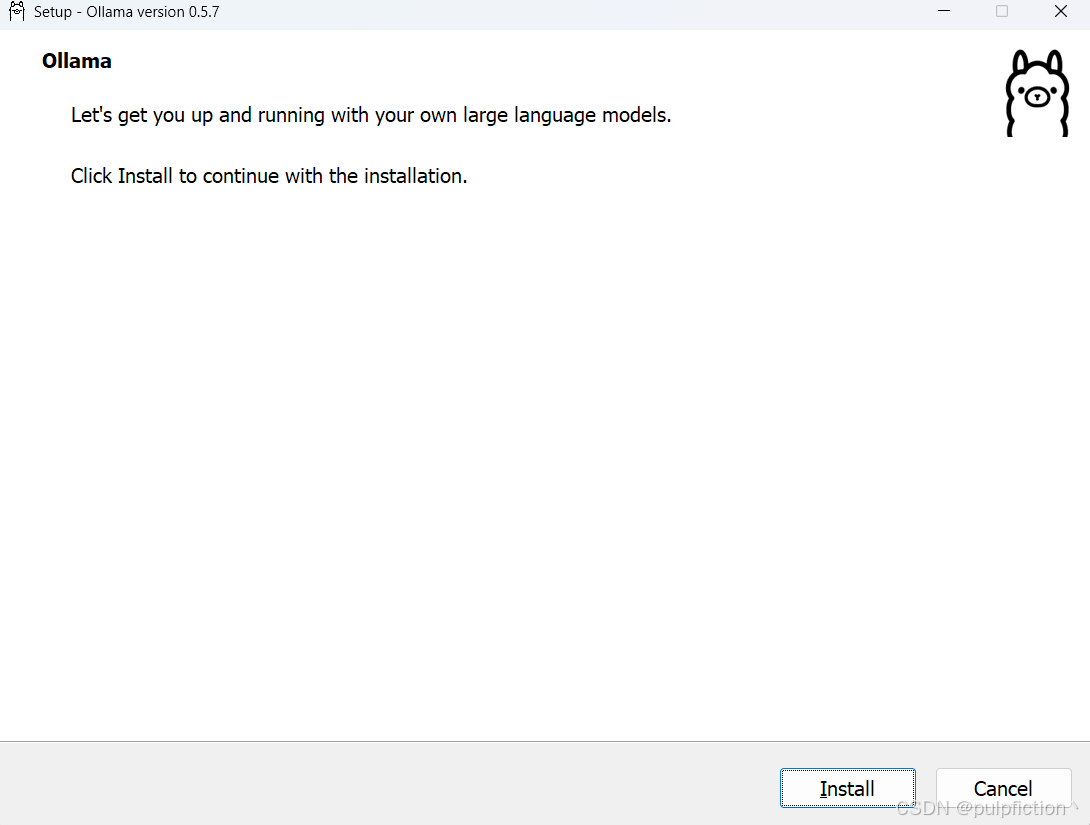
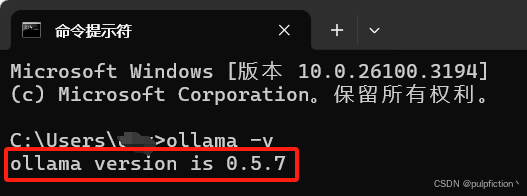
(3)安装完成后通过以下命令检测是否安装完成
ollama -v
(4) 修改模型存储位置(不修改会默认存储在C:\Users\xx.ollama\models下)
打开系统高级设置,点击环境变量,然后在用户变量中点击新建按钮,变量名为OLLAMA_MODELS,变量值为自行设置路径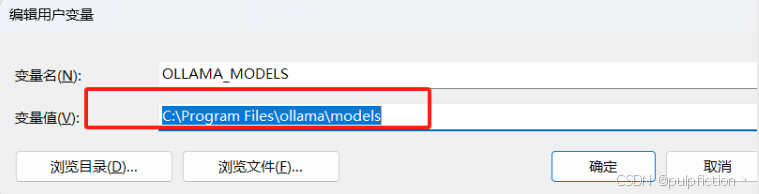
3、下载deepseek
(1)点击ollama官网模型,选择模型,我电脑不行选择了1.5b,电脑配置好的可以自行选择更大的模型。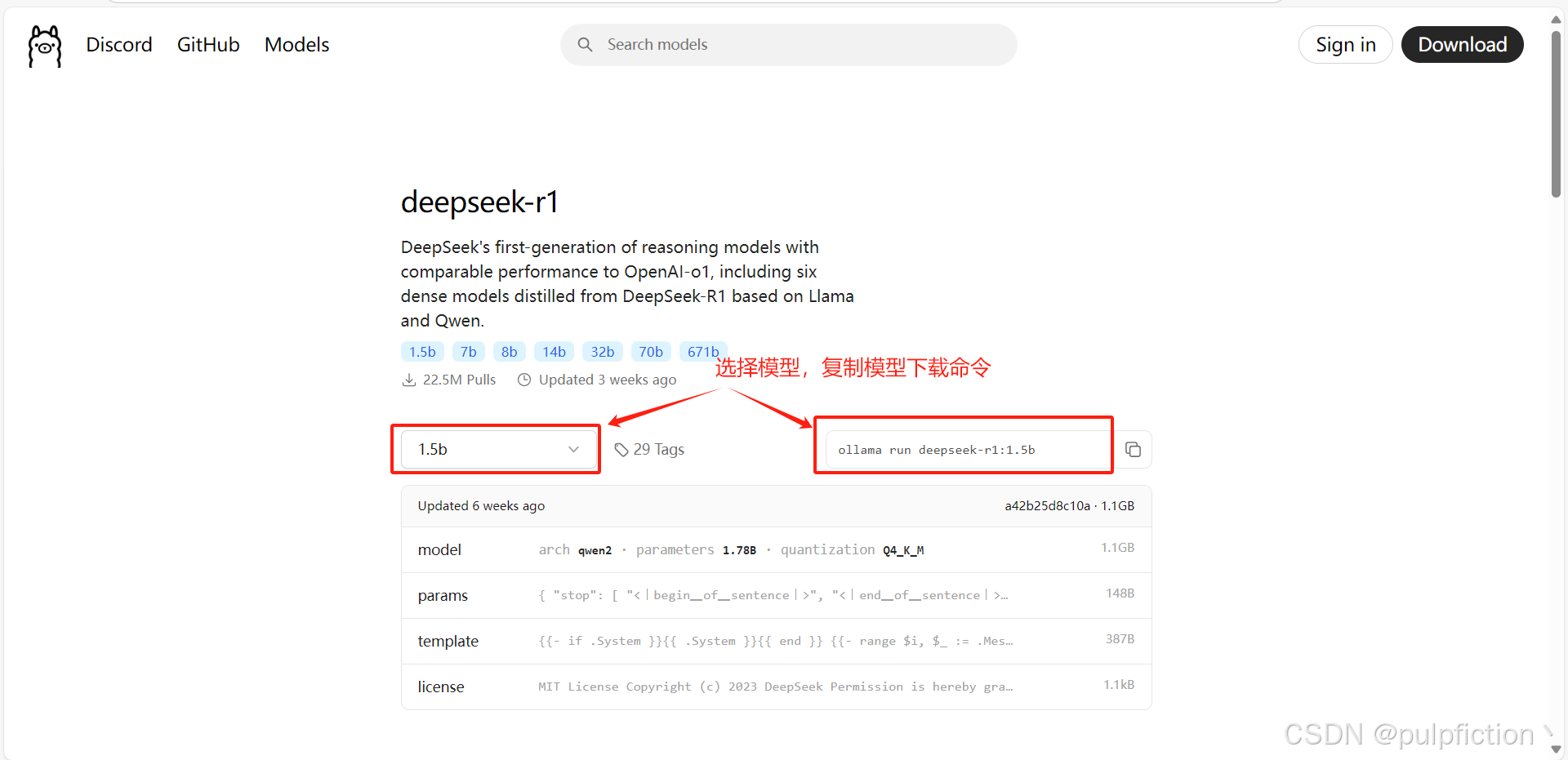
(2)打开cmd,输入ollama命令,下载模型
ollama run deepseek-r1:1.5b
如果出现了图中的报错信息,将图中的地址复制到浏览器重新执行命令即可下载。
安装成功即可对话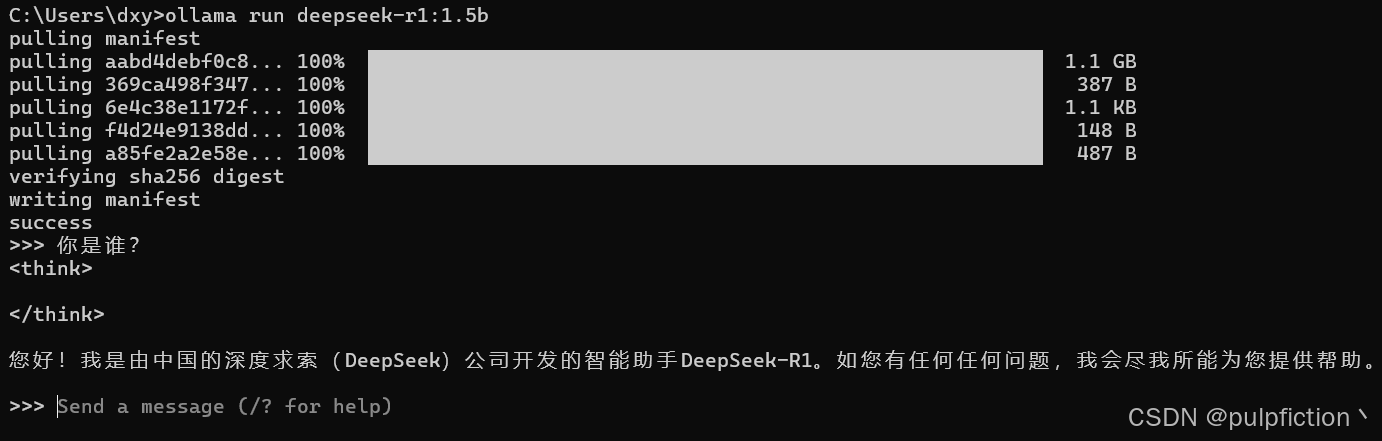
4、Chatbox安装
(1)进行Chatbox官网选择对应的版本下载即可
(2)点击Chatbox-Setup.exe正常安装即可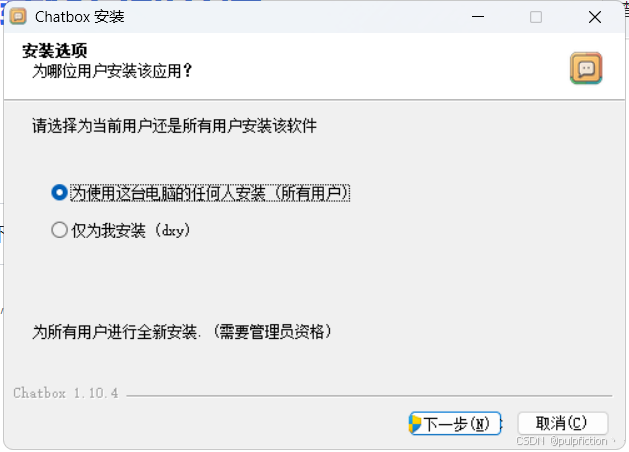
(3)安装完成以后打开chatbox设置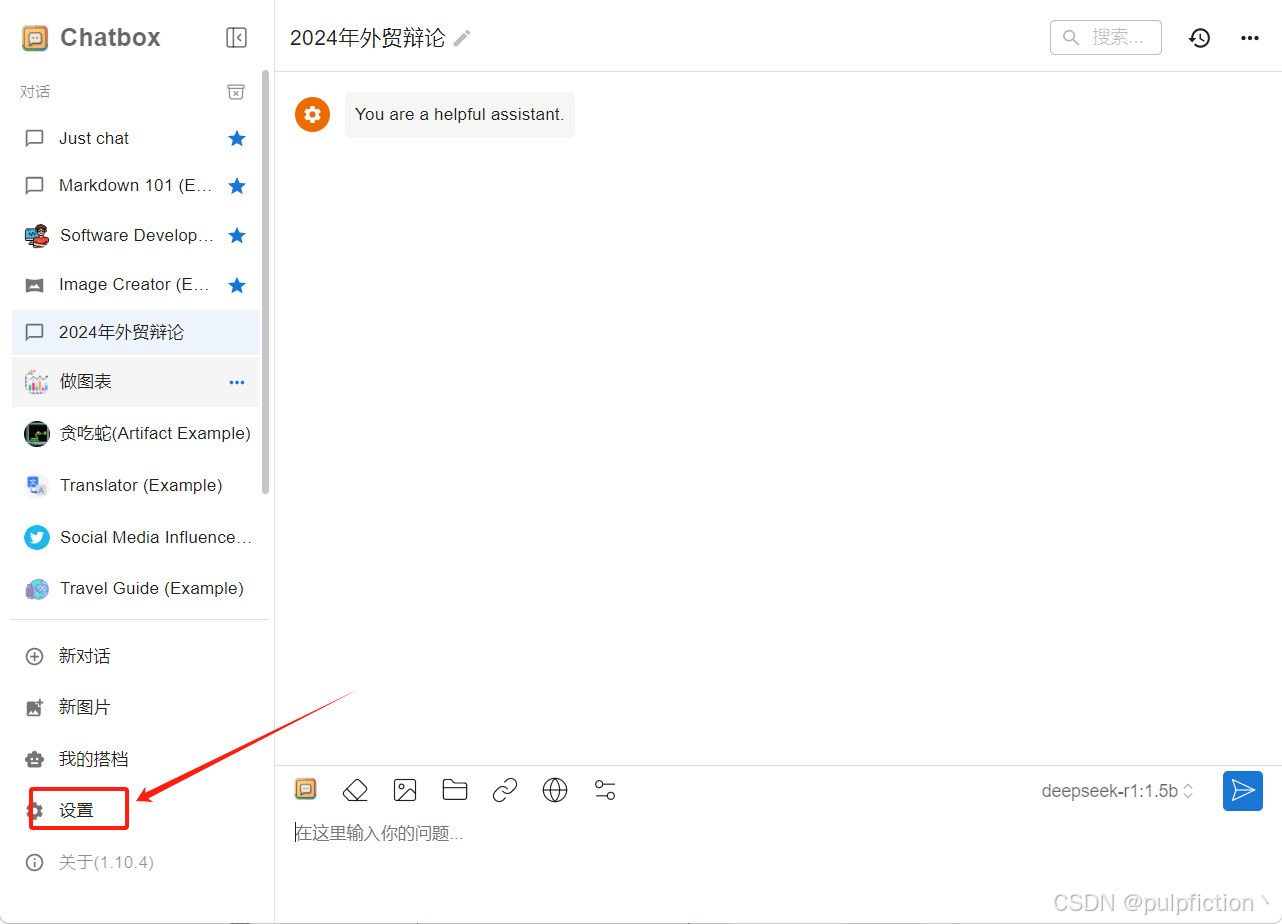
(4)选择ollama下载的deepseek模型点击保存即可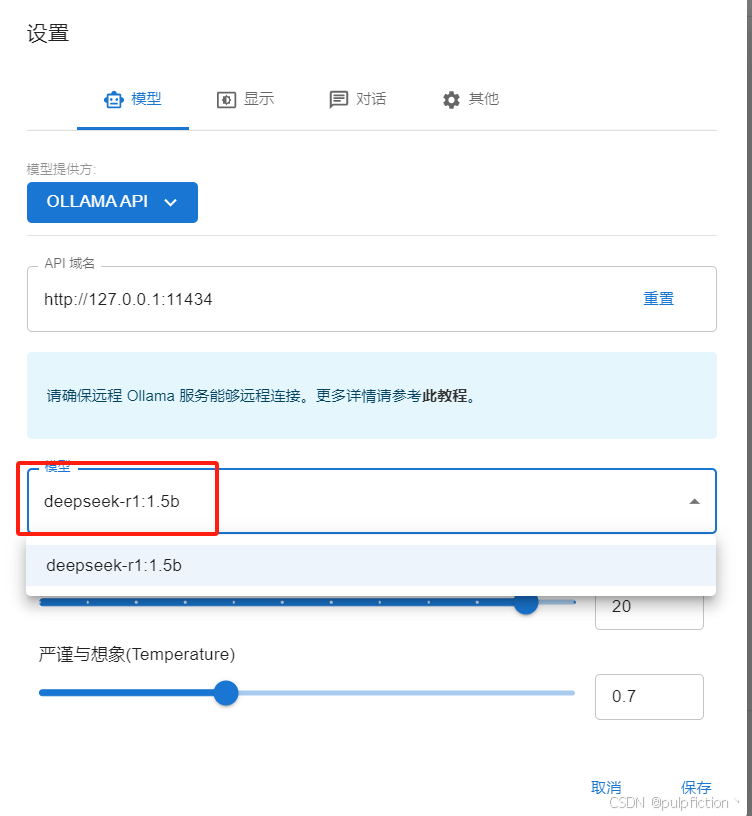
(5)开始对话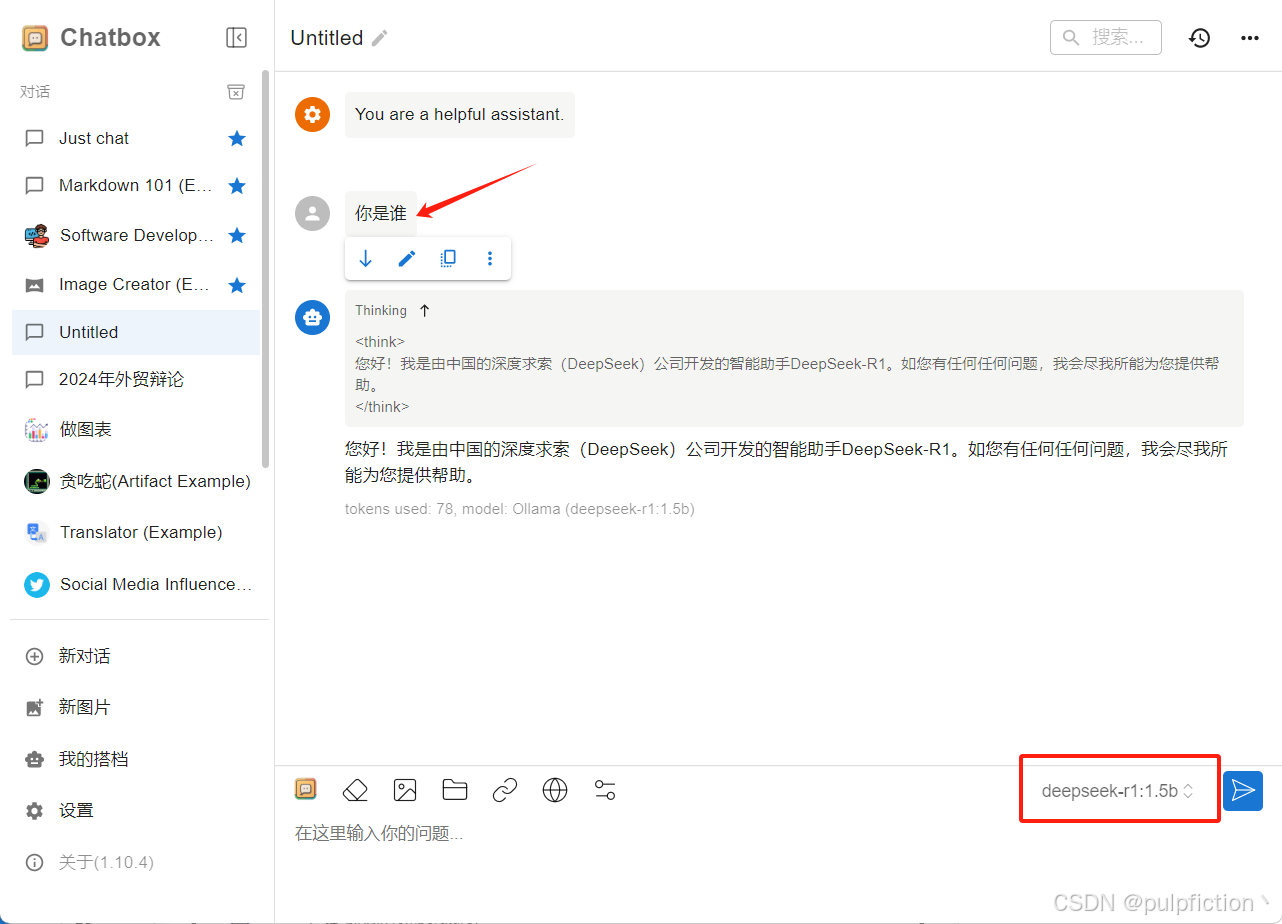
2.2 方法二:LLaMA-Factory 部署
1、克隆llama-factory GitHub 存储库
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
2、创建虚拟环境并指定版本(可选)
# 我创建的虚拟环境名称为deepLearningPytorch
conda create -n your_env_name python=3.x
3、激活虚拟环境,安装Pytorch及CUDA环境,可以直接到Pytorch官网复制代码直接安装。

# 激活虚拟环境
activate deepLearningPytorch
# 安装Pytorch及CUDA环境
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
4、导航到 llama-factory GitHub 存储库目录并安装llama-factory
# 导航到 llama-factory GitHub 存储库目录
cd LLaMA-Factory
# 安装LLaMA-Factory
pip install -e ".[torch,metrics]"
5、打开可视化界面并下载模型
llamafactory-cli webui
(1) 选择模型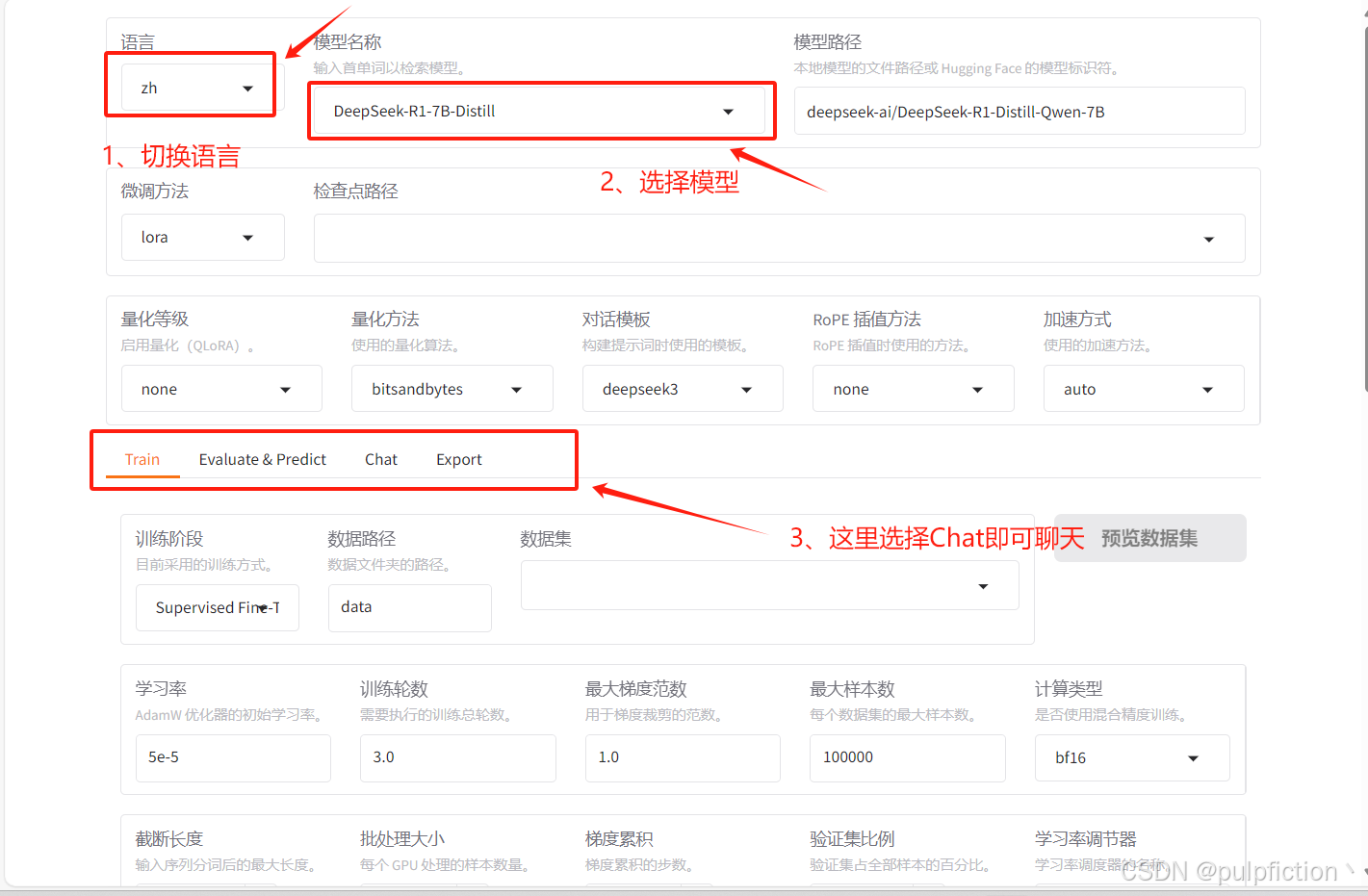
(2)运行模型之前需要先加载模型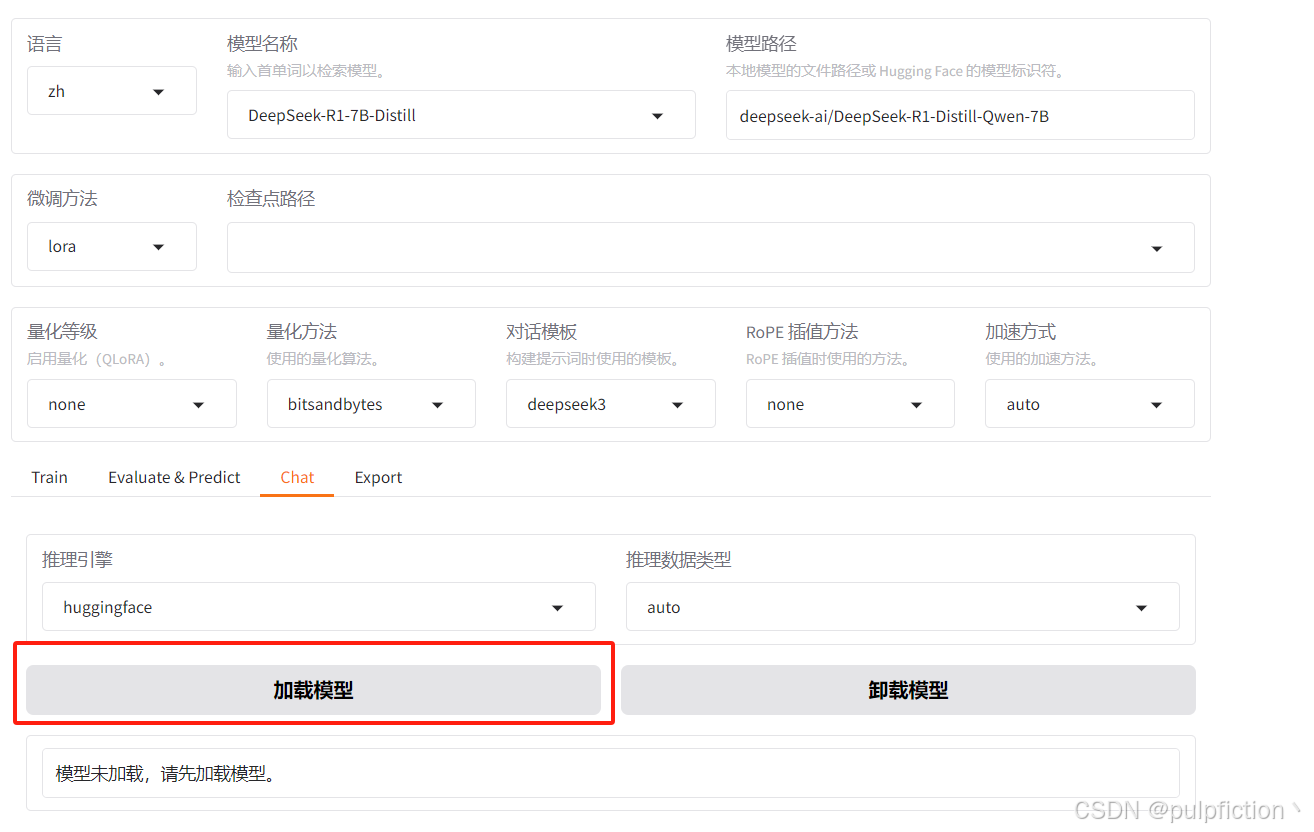
(3)模型加载成功,即可运行
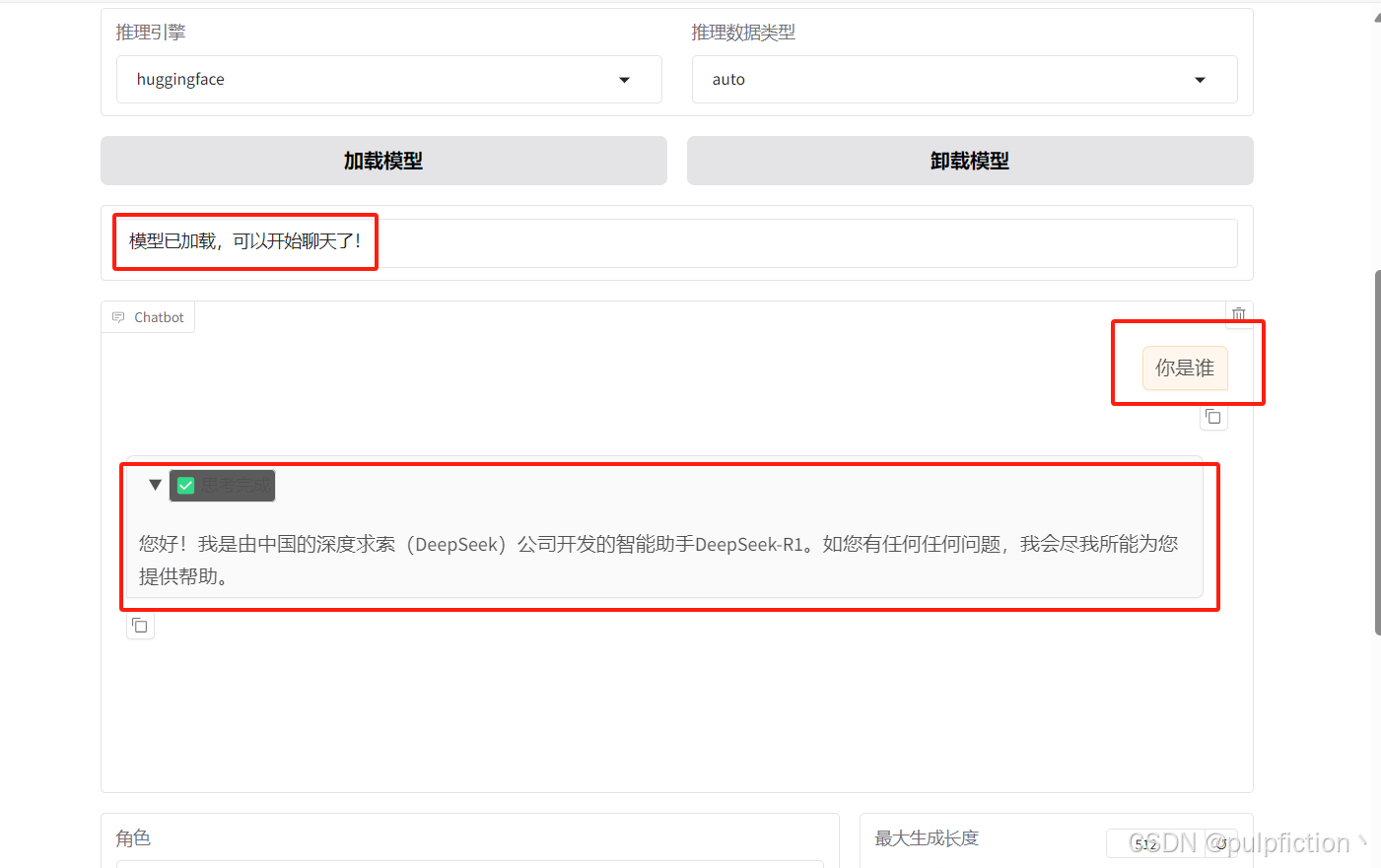
(4) llama-factory还可以对模型进行训练、微调、导出等。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 30
30 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)