
DeepSeek-Coder-DeekSeek在编码领域的大语言模型(内含建议训练概括图)
在当今数字化时代,大语言模型(LLMs)正以前所未有的速度推动着各个领域的发展,尤其是在编码领域,其带来的变革令人瞩目。DeepSeek-Coder是其中一款非常不错的的编码专用大语言模型。
在当今数字化时代,大语言模型(LLMs)正以前所未有的速度推动着各个领域的发展,尤其是在编码领域,其带来的变革令人瞩目。DeepSeek-Coder是其中一款非常不错的的编码专用大语言模型 。
一、模型架构与训练基础
DeepSeek-Coder 拥有三种不同规模的版本,分别为 13 亿、67 亿和 330 亿参数。这些模型构建在精心筛选的项目级代码语料库之上,采用独特的 “填空” 预训练目标,这一创新策略极大地增强了模型的代码填充能力。同时,将上下文窗口扩展至 16384 个词元,使得模型在处理大规模代码生成任务时游刃有余。
二、多任务性能卓越
- 代码生成
- 在 HumanEval 和 MBPP 基准测试中,DeepSeek-Coder-Base 表现出色。其中,330 亿参数版本在 HumanEval 上平均准确率达 50.3%,在 MBPP 上达 66.0%,相比类似规模的 CodeLlama-Base 340 亿参数模型,准确率分别提升了 9% 和 11%。即使是 67 亿参数版本,性能也超越了 CodeLlama-Base 340 亿参数模型。指令微调后的模型在 HumanEval 基准测试中超过了 GPT-3.5-Turbo,大幅缩小了与 GPT-4 的差距。
- 在 DS-1000 基准测试里,DeepSeek-Coder 在涵盖 Matplotlib、NumPy 等七个不同库的数据科学工作流程评估中,各库均取得较高准确率,证明了其在实际数据科学工作流程中生成优质代码以及准确运用库的能力。
- 通过构建的 LeetCode Contest 基准测试验证,DeepSeek-Coder 模型在实际编程问题处理上优于现有开源编码模型。DeepSeek-Coder-Instruct 330 亿参数模型成为唯一在该任务中超过 GPT-3.5-Turbo 的开源模型,尽管与 GPT-4-Turbo 仍有差距,但思维链(CoT)提示策略显著提升了其性能。
- 中间填充代码补全
在中间填充(FIM)代码补全任务中,采用特定训练策略的 DeepSeek-Coder 模型表现突出。在与 SantaCoder、StarCoder 和 CodeLlama 等模型对比时,基于三种编程语言的单行填充基准测试结果显示,DeepSeek-Coder-Base 13 亿参数模型虽参数规模小,却超越了部分更大规模模型。并且,模型规模与性能呈正相关,基于效率和准确性的平衡,推荐部署 DeepSeek-Coder-Base 67 亿参数模型用于代码补全工具。 - 跨文件代码补全
使用 CrossCodeEval 数据集评估发现,DeepSeek-Coder-Base 67 亿参数模型在跨文件代码补全任务中,在多种语言上始终优于 CodeGeex2、StarCoder - Base、CodeLlama - Base 等模型。实验设置特定的序列长度和上下文长度,并以完全匹配率和编辑相似度为指标。同时,不使用代码库预训练时模型在部分语言上性能下降,凸显了代码库级预训练的有效性。 - 基于程序的数学推理
运用程序辅助数学推理(PAL)方法,在 GSM8K、MATH 等七个基准测试中,DeepSeek-Coder 模型表现卓越。特别是 330 亿参数版本,在各基准测试中成绩显著,展示了在复杂数学计算和问题解决应用中的巨大潜力。
三、持续优化与发展
为增强 DeepSeek-Coder 的能力,大模型也继续在持续优化。为提升零样本指令能力,使用高质量指令数据对 DeepSeek-Coder-Base 模型进行微调,造就了在编码任务中超越 GPT-3.5 Turbo 的 DeepSeek-Coder-Instruct 330 亿参数模型。为进一步提升自然语言理解能力,基于 DeepSeek-LLM 70 亿参数检查点,利用包含自然语言、代码和数学数据的 20 亿词元多样化数据集进行额外预训练,诞生了 DeepSeek-Coder-v1.5。该模型不仅保留了高水平编码性能,自然语言理解能力也得以增强。
展望未来,基于更大规模的通用大语言模型会继续发展,相信DeepSeek持续开发并公开分享更强大的以代码为中心的大语言模型,为编码领域带来更多的创新与突破。其后续发展将会为广大开发者和相关领域带来更高效、智能的编码体验,推动整个行业迈向新的高度。
四、训练概括图
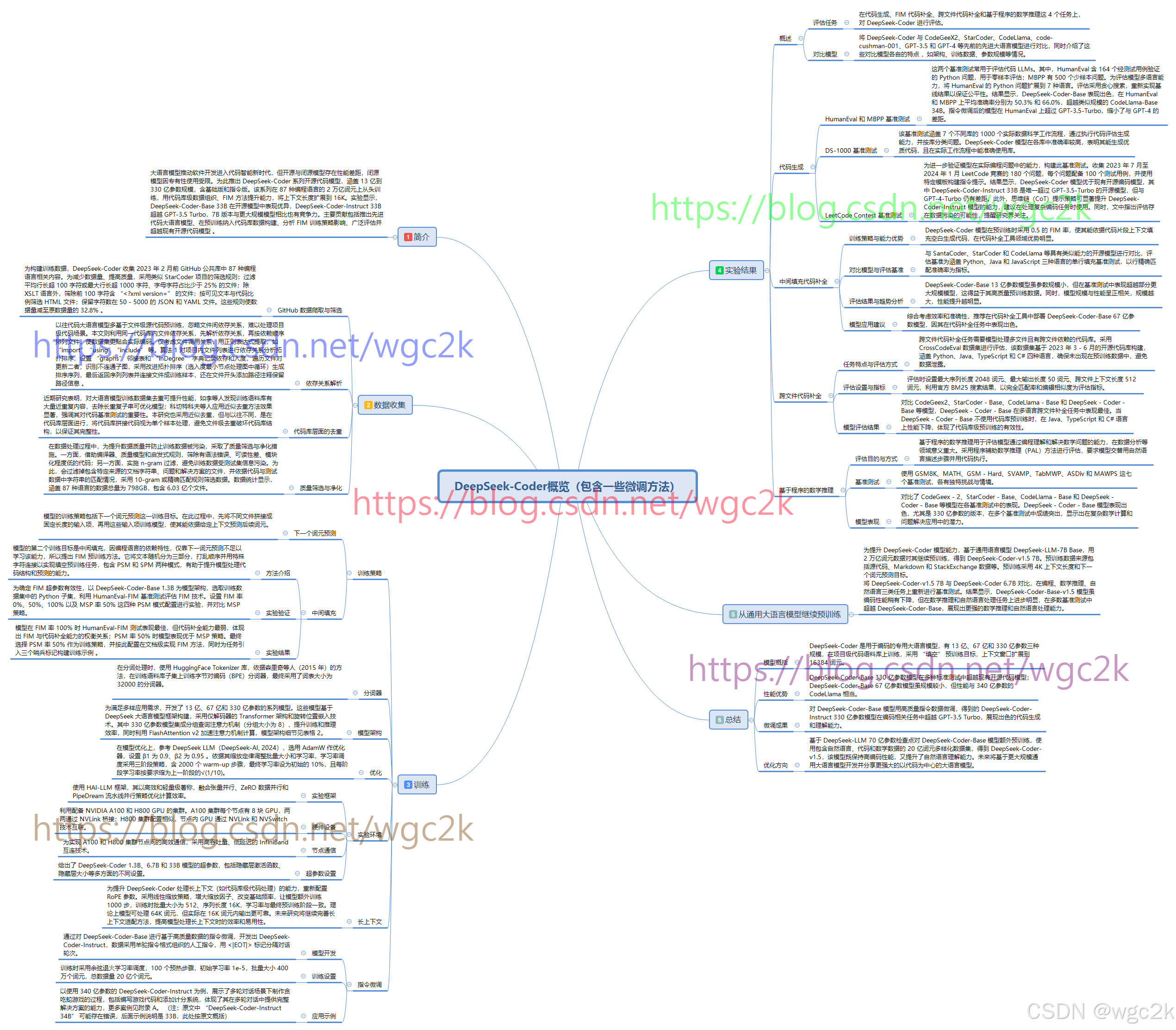

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 35
35 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)