自动化办公:利用Python和DeepSeek API高效制作Word文档(附源码)
前 言在日常工作中,利用 Python 和 DeepSeek API 可以自动化制作报告、培训、学习计划等文档。通过 Python 调用 DeepSeek API 并自动化生成 Word 文档,能够显著提升工作效率、降低成本,并为复杂场景提供灵活的解决方案。适用场景:技术文档生成、项目计划、报告生成、合同生成、教育材料等。准备工作deepseek api方式,需要提前创建一个api key获取De
前 言
在日常工作中,利用 Python 和 DeepSeek API 可以自动化制作报告、培训、学习计划等文档。
通过 Python 调用 DeepSeek API 并自动化生成 Word 文档,能够显著提升工作效率、降低成本,并为复杂场景提供灵活的解决方案。
适用场景:技术文档生成、项目计划、报告生成、合同生成、教育材料等。
准备工作
deepseek api方式,需要提前创建一个api key
获取DeepSeek API KEY
访问 DeepSeek 官方网站,注册账号并登录。
https://www.deepseek.com/

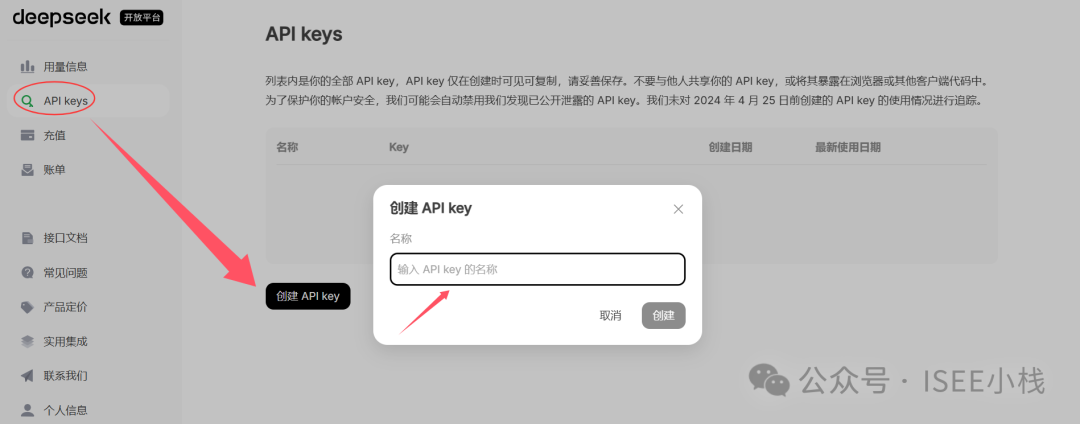
在用户中心或开发者页面中,点击左侧菜单【API Keys】,点击创建API key,并妥善保存。
创建成功后,一定要记录此处的API key。因为deepseek的平台不会再次展示API Keys的值
一定要记录
一定要记录
一定要记录
安装 Python 环境
访问python官方网站下载。
https://www.python.org/
这里不再赘述,小栈使用的版本是python3.9.16
安装 PyCharm
访问PyCharm官方网站下载。
https://www.jetbrains.com.cn/pycharm/download/?section=windows
下载专业版本
pycharm-professional-2024.3.2.exe
这里也不再赘述,小栈使用的版本是PyCharm 2024.3
调用deepseek
在上次分享中,已经详细讲述如何调用deepseek api,这里不再赘述,我们直接使用。
上次有朋友提出疑问 “请求体中messages 中的两个角色 (role) system 和 user 代表什么含义?” 我们这里会补充一下:
1. system:
该角色用于提供系统的背景信息或指令。它可以定义对话的上下文、角色、风格或任何特定的行为期望。通过设置 system 消息,您可以影响模型的行为和回答的质量。
2. user:
该角色表示用户的输入或提问。这是用户希望模型回应的具体内容,通常是对话的实际问题或请求。
安装三方库
安装三方库 openai
pip3 install openai
引用三方库
引用三方库 openai
from openai import OpenAI
实际调用
将注册deepseek创建的api key输入,就可以直接使用了,这里将 角色、指令 和 参数 一同 传入请求体。
比如现在要给一位只有业余时间的同学制定一份python学习计划,
现在定义 系统背景 和 用户提问:
role_system = "你是一名专业的Python程序员,专注python技术的培训学习。"``role_user = "在每日可用2小时(19:00-21:00)、脑力峰值下降30%的晚间时段,设计Python机器学习进阶计划(需兼容Anki记忆曲线),最终输出markdown格式"
这个可根据自己的实际情况定义,其实越清晰越好,本文只以python为例。
具体实际代码如下:
from openai import OpenAI``# 初始化客户端``client = OpenAI(api_key="deepseek创建的api key", base_url="https://api.deepseek.com")``# 系统角色和用户输入`` ``# role_system = "你是一名专业的Python开发工程师,最终输出markdown格式"``role_system = "你是一名专业的Python程序员,专注python技术的培训学习。"``role_user = "在每日可用2小时(19:00-21:00)、脑力峰值下降30%的晚间时段,设计Python机器学习进阶计划(需兼容Anki记忆曲线),最终输出markdown格式"`` `` ``response = client.chat.completions.create(` `model="deepseek-chat",` `messages=[` `{"role": "system", "content": role_system},` `{"role": "user", "content": role_user},` `],` `temperature=1.0,` `top_p=0.9,` `max_tokens=500,` `stream=False``)``# 输出``markdown_text = response.choices[0].message.content``print(markdown_text)
结果:
## Python 机器学习进阶计划 (晚间时段,兼容 Anki 记忆曲线)`` ``**目标:** 在每日 2 小时 (19:00-21:00) 的晚间时段,利用脑力峰值下降 30% 的特点,高效学习 Python 机器学习进阶知识,并结合 Anki 记忆曲线进行知识巩固。`` ``**计划周期:** 8 周`` ``**每周安排:**`` ``* **周一至周五:** 学习新知识 + Anki 复习``* **周六:** 项目实践 + Anki 复习``* **周日:** 休息 + 自由复习`` ``**每日时间安排 (19:00-21:00):**`` ``* **19:00-19:30:** Anki 复习 (复习前一天学习内容)``* **19:30-20:30:** 学习新知识 (视频/书籍/文档)``* **20:30-21:00:** 代码实践 + 笔记整理 + Anki 卡片制作`` ``**学习路线:**`` ``**第一阶段 (1-2 周): 机器学习基础回顾与强化**`` ``* **目标:** 巩固机器学习基础概念,为进阶学习打下坚实基础。``* **学习内容:**` `* 机器学习基本概念 (监督学习、无监督学习、强化学习)` `* 常用机器学习算法 (线性回归、逻辑回归、决策树、随机森林、SVM 等)` `* 模型评估指标 (准确率、召回率、F1 值、ROC 曲线等)` `* 特征工程 (特征选择、特征缩放、特征编码等)``* **资源推荐:**` `* 书籍: 《机器学习实战》` `* 视频: 吴恩达机器学习课程 (Coursera)` `* 网站: Scikit-learn 官方文档``* **Anki 卡片制作:**` `* 机器学习基本概念` `* 常用机器学习算法原理、优缺点、应用场景` `* 模型评估指标计算公式、意义` `* 特征工程常用方法`` ``**第二阶段 (3-4 周): 深度学习入门**`` ``* **目标:** 掌握深度学习基本概念和常用模型。``* **学习内容:**` `* 神经网络基础 (感知机、多层感知机、激活函数、损失函数、优化算法)` `* 卷积神经网络 (CNN) 原理及应用` `* 循环神经网络 (RNN) 原理及应用` `* 深度学习框架
以上结果输出的是markdown格式
生成Word文档
markdown格式的直接写入Word,条理比较清晰,但格式需要做处理。在Python中,我们需要用到以下三方库:
1. markdown: Markdown 解析
2. python-docx:Word操作
3. beautifulsoup4:Html解析
这里可能有朋友会有疑问,说明一下为什么不直接使用Markdown 的解析能力,从而增加了辅助工具BeautifulSoup?
如果单纯使用Markdown 的解析处理会比较复杂,里面有部分Html标签,个人感觉用BeautifulSoup辅助更加方便。
安装三方库
安装三方库markdown python-docx beautifulsoup4:
pip install markdown python-docx beautifulsoup4
引入三方库
将添加的 角色 和 优化的指令传入请求体:
import markdown``from docx import Document``from bs4 import BeautifulSoup
代码实现
这里我们直接封闭一个函数:
import markdown``from docx import Document``from docx.shared import Pt``from docx.enum.text import WD_ALIGN_PARAGRAPH``from bs4 import BeautifulSoup`` ``def markdown_to_word(markdown_text, output_file):` `# 解析 Markdown 为 HTML` `html_content = markdown.markdown(markdown_text)`` ` `# 创建 Word 文档` `doc = Document()`` ` `# 设置默认字体和样式` `style = doc.styles['Normal']` `font = style.font` `font.name = 'Times New Roman'` `font.size = Pt(12)`` ` `# 将 HTML 转为文本解析(不保留标签)` `soup = BeautifulSoup(html_content, "html.parser")`` ` `# 遍历解析后的内容` `for element in soup:` `if element.name == "h1":` `# 一级标题,居中显示` `paragraph = doc.add_heading(element.text, level=1)` `paragraph.alignment = WD_ALIGN_PARAGRAPH.CENTER` `doc.add_paragraph()` `elif element.name == "h2":` `# 二级标题` `paragraph = doc.add_heading(element.text, level=2)` `paragraph.alignment = WD_ALIGN_PARAGRAPH.CENTER` `doc.add_paragraph()` `elif element.name == "h3":` `# 三级标题` `paragraph = doc.add_heading(element.text, level=3)` `paragraph.alignment = WD_ALIGN_PARAGRAPH.LEFT` `doc.add_paragraph()` `elif element.name == "p":` `# 普通段落` `doc.add_paragraph(element.text)` `elif element.name == "ul":` `# 无序列表` `for li in element.find_all("li", recursive=False):` `doc.add_paragraph(li.text, style="List Bullet")` `elif element.name == "ol":` `# 有序列表` `for li in element.find_all("li", recursive=False):` `doc.add_paragraph(li.text, style="List Number")` `elif element.name == "blockquote":` `# 引用` `doc.add_paragraph(element.text, style="Intense Quote")` `elif element.name == "code":` `# 代码块` `doc.add_paragraph(element.text, style="Code")`` ` `# 保存生成的 Word 文档` `doc.save(output_file)` `return f"生成 {output_file} 成功!"
生成Word文档
我们把以上两部分结合,调用 deepseek 后直接 调用写入word函数
def main():` `output_file = 'XXX_Python业余学习计划.docx'` `result = markdown_to_word(markdown_text, output_file)` `print(result)`` ``if __name__ == '__main__':` `main()
结果:

这样是不是更加方便了呢 ,再也不用输出结果、复制、粘贴、调整Word格式了!大大节省了时间!
,再也不用输出结果、复制、粘贴、调整Word格式了!大大节省了时间!
总 结
通过 Python 调用 DeepSeek API 并自动化生成 Word 文档具有以下好处:
1. 提高效率
自动化生成:无需手动编写或复制粘贴内容,节省大量时间和精力。
批量处理:可以快速生成多个文档,适用于需要大量文档的场景(如报告、合同、教程等)。
2. 内容一致性
标准化输出:通过 API 生成的内容格式统一,避免人为错误或格式不一致的问题。
动态更新:如果内容需要更新,只需修改 API 请求或模板,文档会自动同步更新。
3. 灵活性和可定制性
动态内容生成:可以根据不同需求生成定制化内容(如个性化报告、数据分析结果等)。
模板化设计:结合 Word 模板,可以灵活控制文档的样式、布局和结构。
4. 集成性强
与其他工具集成:可以与 Python 生态系统中的其他工具(如 Pandas、Matplotlib 等)结合,生成包含数据、图表和文本的复杂文档。
自动化工作流:可以嵌入到自动化脚本或工作流中,实现端到端的文档生成和分发。
5. 节省成本
减少人工干预:降低对人工编写文档的依赖,减少人力成本。
资源优化:通过 API 调用,可以按需生成文档,避免资源浪费。
6. 可扩展性
模块化设计:代码可以模块化,方便扩展和重用。
支持多种格式:除了 Word 文档,还可以生成 PDF、HTML 等其他格式。
有一点,使用Python 调用 DeepSeek API是消费的,但价格很亲民,这点请知悉!
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。
4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。
👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 27
27 0
0- 0



 已为社区贡献264条内容
已为社区贡献264条内容

所有评论(0)