LLMOps实战(一):DeepSeek+RAG 协同构建企业知识库全流程指南
LLMOps实战(一):DeepSeek+RAG 协同构建企业知识库全流程指南
一、开篇:当大模型遇到知识边界
首先解释下什么是 LLMOps,Large Language Model Operations是专注于大语言模型全生命周期管理的工程实践,涵盖从模型开发、部署、监控到持续优化的系统性流程。其核心目标是提升LLM应用的可靠性、效率与可控性,解决大模型在实际落地中的技术与管理挑战。
那什么是 RAG 呢? RAG 即检索增强生成(Retrieval Augmented Generation),它结合了信息检索和大语言模型(LLM)的能力,有效地解决了大语言模型知识更新不及时、缺乏特定领域信息等问题。
传统的大语言模型虽然具备强大的语言理解和生成能力,但它的知识是基于训练数据的,存在一定的时效性和局限性。RAG 的核心思想是在大语言模型生成回答之前,先从外部知识库中检索与用户问题相关的信息,然后将这些信息作为额外的上下文提供给大语言模型,帮助其生成更准确、更有针对性的回答——通用大模型本质是概率生成器,而企业需要的是能精确调用领域知识的"增强型大脑"。
二、RAG 实现流程概述
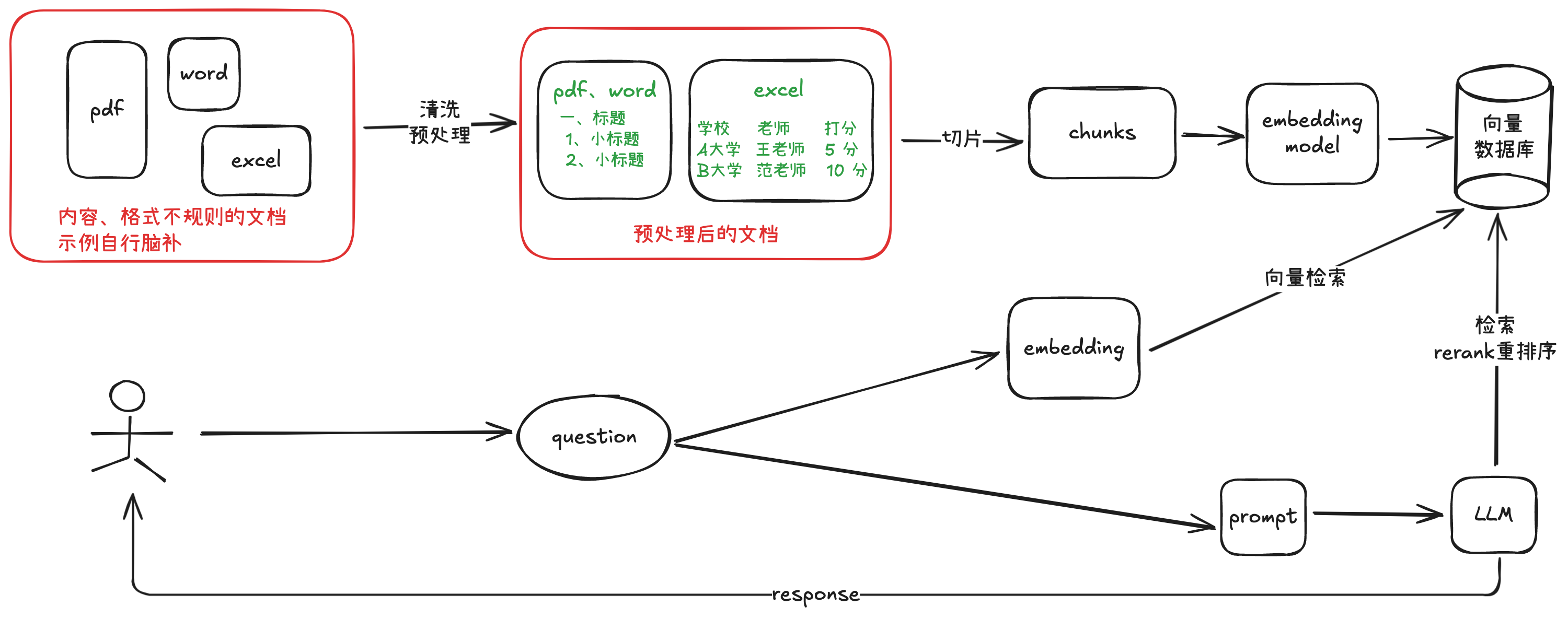
2.1 数据准备
- 收集数据:确定所需的知识领域,收集相关的文本数据,如文档、文章、报告、网页等。这些数据可以来自企业内部的知识库、公开的数据集、专业的文献库等。
- 数据清洗和预处理:对收集到的数据进行清洗,去除噪声、重复数据和无效信息。然后进行预处理,如分词、词性标注、命名实体识别等,以便后续的索引和检索。
2.2 构建向量数据库
- 文本向量化:使用文本嵌入模型(如 OpenAI 的 text-embedding-ada-002、BGE-M3 等)将预处理后的文本数据转换为向量表示。这些向量能够捕捉文本的语义信息,使语义相近的文本在向量空间中距离更近,至于怎么相近需要理解 transformer 自注意力机制原理,后面会讲到。
- 存储向量:将生成的向量存储到向量数据库中,如 Pinecone、Milvus 等。向量数据库支持高效的向量相似度搜索,能够快速找到与查询向量最相似的向量。
2.3 检索模块
- 用户查询向量化:当用户提出问题时,将问题文本转换为向量,使用的嵌入模型(embedding 模型) 要与构建向量数据库时一致。
- 相似度搜索:在向量数据库中进行相似度搜索,找到与用户查询向量最相似的向量对应的文本片段。通常使用余弦相似度等度量方法来计算向量之间的相似度。
- 筛选和排序:对检索到的文本片段进行筛选和排序,选择最相关、最有价值的信息作为上下文。可以根据相似度得分、文本的权威性、时效性等因素进行筛选和排序。
2.4 生成模块
- 提供上下文:将筛选后的文本片段作为额外的上下文与用户的问题一起输入到大语言模型中。
- 生成回答:大语言模型根据输入的问题和上下文信息,生成相应的回答。大语言模型可以是开源的(如 deepseek、Llama 3、ChatGLM 等)或商业的(如 豆包、 GPT-4、通义千问等)。
2.5 后处理
- 答案优化:对大语言模型生成的回答进行优化,如检查语法错误、调整表述方式、去除不必要的信息等,以提高回答的质量。
- 评估和反馈:对生成的回答进行评估,如使用人工评估或自动评估指标(如准确率、召回率、F1 值等)来衡量回答的质量。根据评估结果,对检索和生成过程进行调整和优化,以不断提高系统的性能。
三、RAG核心原理
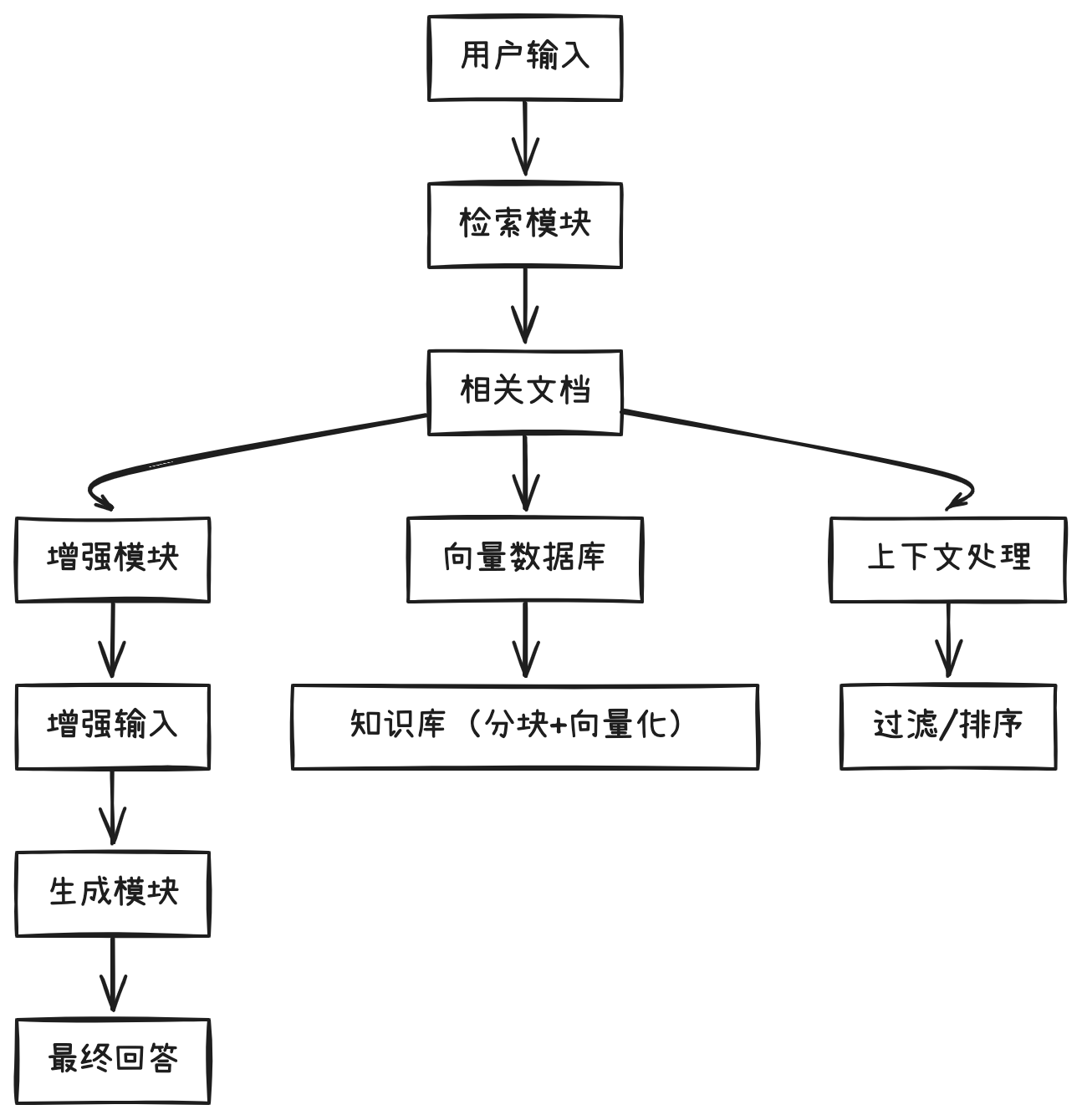
2.1 架构三要素:检索-生成-修正
如果把RAGFlow比作一个智能问答系统,它的工作流程可以拆解为三个核心环节:
- 检索层:像图书馆管理员,根据用户问题快速定位相关文档
- 生成层:扮演作家角色,基于检索结果创作回答
- 修正层:担任校对编辑,确保内容准确合规
这三者的协作关系可以用一个形象的比喻说明:
- 检索层是"眼睛",负责找到关键信息
- 生成层是"嘴巴",负责组织语言表达
- 修正层是"大脑",负责逻辑校验
2.2 向量检索的数学魔法
在RAGFlow中,所有文档都会被转化为数字向量。这个过程就像给每个词语发一张"身份证",比如"人工智能"可能对应[0.8, -0.3, 0.5]这样的坐标,先简单理解,后面单独讲解向量过程。
当用户提问时,系统会做三件事:
- 将问题转换为向量(问题向量)
- 在向量数据库中查找最相似的文档向量
- 提取对应文档作为回答依据
这里的相似度计算采用余弦相似度公式:
cosθ = (A·B) / (|A| × |B|)当两个向量夹角趋近于0时,相似度趋近于1,意味着语义高度相关。
2.3 生成模型的增强策略与传统生成模型的区别
|
维度 |
传统生成模型(如GPT) |
RAG |
|
知识来源 |
依赖训练时的静态知识 |
动态检索外部知识库 |
|
可解释性 |
黑箱生成,难以追踪依据 |
可追溯引用文档,解释性强 |
|
更新成本 |
需重新训练或微调 |
仅更新知识库,无需动模型 |
|
长尾问题 |
对训练未覆盖的问题易产生幻觉 |
通过检索补充知识,减少幻觉 |
|
适用场景 |
通用对话、创意生成 |
专业领域(医疗、法律)、事实性问答 |
2.4 核心优势
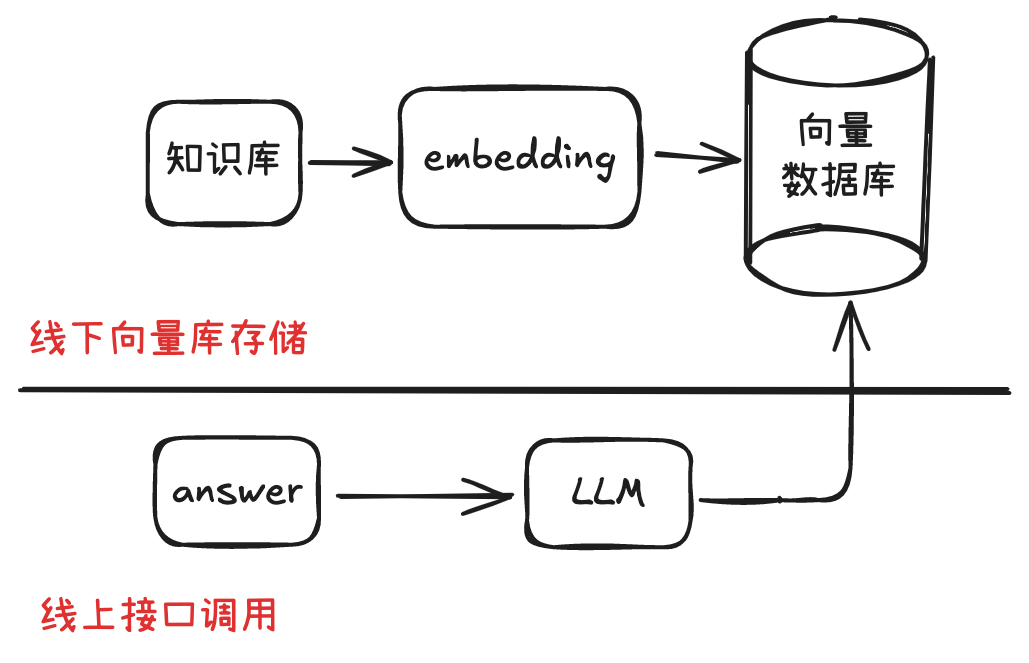
- 动态知识注入:知识库可实时更新(如添加最新新闻、产品文档、最新更新的制度、政策文件等)。
- 降低训练成本:无需为特定领域重新训练大模型。
- 可控性与安全:将 embedding 过程和向量数据库存储在本地,通过接口调用 LLM 做检索输出,大大提高原始数据的安全性。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 22
22 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)