北京大学86页DeepSeek教程发布!比清华版更炸裂(附PDF下载方式)
北大最近公开了《DeepSeek提示词工程和落地场景》手册。这份文档在学术圈引起广泛讨论,它是国内首个系统分析推理大模型(DeepSeek-R1)实际应用的公开文献。不仅展示了国产模型的工程实践,同时反映了大模型技术从研究到产业化的转变路径。(老规矩,文末提供下载方式)
·
北大最近公开了《DeepSeek提示词工程和落地场景》手册。
这份文档在学术圈引起广泛讨论,它是国内首个系统分析推理大模型(DeepSeek-R1)实际应用的公开文献。
不仅展示了国产模型的工程实践,同时反映了大模型技术从研究到产业化的转变路径。(老规矩,文末提供下载方式)
北大版与清华版的主要区别?
1、技术定位:应用导向vs底层技术
北大版本是实用工具,解决实际工作问题。
清华版则更侧重技术原理,包含许多前沿技术细节。
2、使用门槛:入门级vs专业级
北大团队文档使用简单直接的语言。
相比之下,清华版本包含更多专业术语和复杂概念。
3、应用场景:实用功能vs理论探索
北大版在实用性方面表现突出,包含多种工作效率工具。
清华版则提供更深入的技术实现和实验性功能。
4、目标用户:普通用户vs技术专家
北大关注普通用户体验,清华侧重技术突破和创新。
北大版核心内容从技术特性、应用逻辑与局限性三个方面进行了分析。
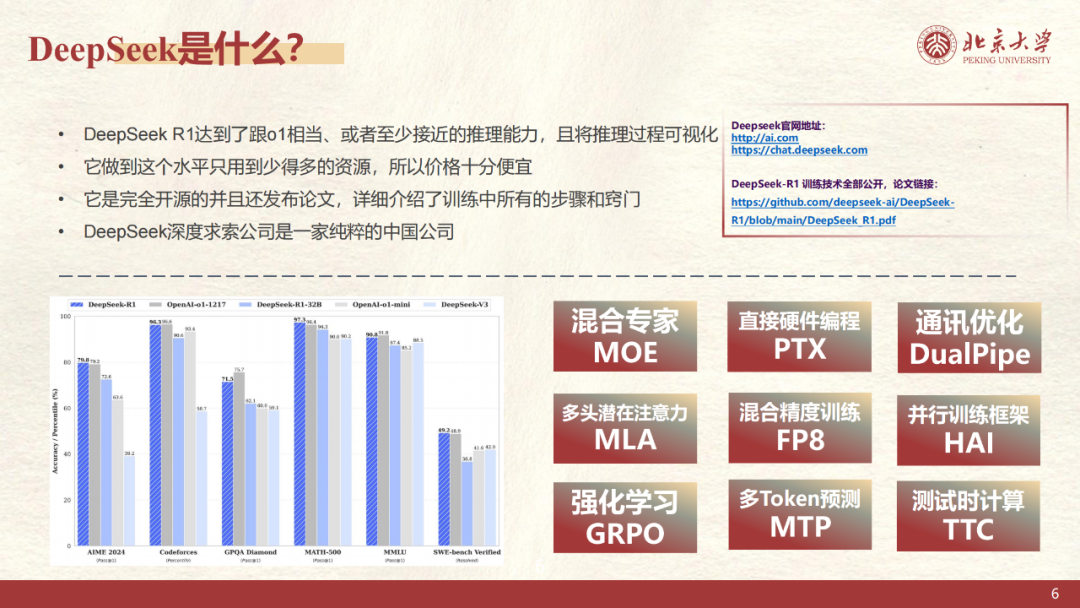
DeepSeek-R1的特点:高性能低成本的推理模型
与GPT-4o这类追求全能的模型不同,DeepSeek-R1专注提高复杂推理能力。它有三大优势:
-
- 技术创新:采用先进技术组合,在数学推理和代码生成方面的准确率分别达到79.8%和92.2%,比GPT-4o高12-15%;
-
- 降低成本:通过特殊训练方法,将大型模型每次使用成本降到0.003美元,比同类产品低83%;
-
- 中文表现优秀:在中文测试中比GPT-4o得分高8.7分,特别适合政府文件和教育内容制作。
提示词使用方法:从简单指令到深度思考
DeepSeek-R1的提示词用法与常见模型有所不同:
-
- 思维过程可视化:通过"先找缺点再回答"的方式增强推理能力。测试显示,这种方法使商业分析的逻辑性提高了37%;
-
- 示例问题:R1不擅长处理少量示例。医疗测试中,提供5个示例反而使准确率下降22%,它更适合直接使用;
-
- 专业模式:文档提供的"政务模式"和"教育模式"等是针对特定场景优化的设置。例如教育模式能让试题的认知层级匹配度达到89%。
实际应用的局限性
尽管应用案例丰富,实际使用仍面临三个主要问题:
-
- 准确性:虽然长文本生成的错误率(6.3%)低于GPT-4o(9.8%),但在金融、法律等重要领域仍有不足。银行测试显示合同条款中关键数据的错误率为1/200;
-
- 设备需求:尽管使用成本低,但完整版需要128块高端显卡,部署难度大。中小企业需要在精度和成本间做选择;
-
- 学习难度:教育领域测试表明,教师需要平均17.5小时才能熟练使用提示词模板,比普通生成模型的9小时学习时间长很多。
以下是PDF重点内容:








(方便大家直接下载,这里给大家整理好了书籍的PDF,扫码即可↓↓↓↓)

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 3
3 0
0- 0



 已为社区贡献84条内容
已为社区贡献84条内容

所有评论(0)