爬虫在deepseek加持下所向无敌
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。那么AI可以帮助做些什么呢?AI大模型时代下的爬虫人也需要紧跟智能的潮流,抓住模型发展的契机,使用AI创建新的爬虫定义新的爬虫范式!爬虫人花费了大量的时间在元素的定位和数据的解析获取上,
一、AI时代的爬虫人需要改变了
AI大模型时代下的爬虫人也需要紧跟智能的潮流,抓住模型发展的契机,使用AI创建新的爬虫定义新的爬虫范式!数据的解析、整理、格式化可以让大模型来提高处理的效率!
介绍一个开源llm爬虫框架:Crawl4AI是一个功能全面、性能优越的网络爬虫工具,特别适合需要处理大量网页数据并进行智能分析的场景。
1.1 还在编写xpath、css选择器定位数据吗
爬虫人花费了大量的时间在元素的定位和数据的解析获取上,我们为此招募了许多的xpath、css规则编写人,就为了适应上百、上千的web页面的数据处理。
首先我们需要明确的一个点就是,爬虫的数据处理与源码的获取不是一个概念,AI并不能帮助我们获取到所有的网站的源代码!为什么不能获取呢?由于现在的数据安全意识的增强,许多的站点都有反爬虫以及风控措施、模型不能直接与这些防护做对抗!
那么AI可以帮助做些什么呢?AI可以使用他的推理能力和智能体的能力,帮助用户使用自动化的工具打开一些简单的站点。可以帮助我们在源代码里面提取一些表格、列表等结构化的数据并处理后输出!
1.2 开源模型Crawl4AI
Crawl4AI是一个开源的网络爬虫和数据提取工具,专为大型语言模型(LLM)设计,旨在简化网页数据的抓取和提取过程。它通过异步操作、高效的数据处理和智能提取策略,为开发者提供了一个强大且灵活的工具,能够应对现代网页的复杂性和动态性。Crawl4AI不仅支持传统的爬虫功能,还融入了AI技术,使其在处理大规模数据和动态内容时表现出色。
Crawl4AI的核心目标是提供一个高效、灵活且易于集成的网络爬虫工具,特别适合与大型语言模型和AI应用配合使用。以下是Crawl4AI的主要特点:
-
异步操作:采用异步架构,能够同时处理多个URL,提高爬取效率,特别适合大规模数据抓取。
-
LLM友好:输出的数据格式(如JSON、Markdown)经过优化,易于LLM处理,方便集成到AI应用中。
-
动态内容处理:能够执行JavaScript,处理动态加载的内容,确保抓取的数据完整性。
-
智能数据提取:利用AI技术自动分析网页结构,生成数据提取规则,减少手动配置的工作量。
-
多浏览器支持:支持Chromium、Firefox和WebKit等多种浏览器,适应不同网站的兼容性需求。
-
灵活的配置:提供丰富的配置选项,如钩子函数、缓存管理、代理设置等,满足各种定制化需求。
1.3 功能代码解析
Crawl4AI的代码结构清晰,模块化设计便于维护和扩展。以下是对其主要功能和代码实现的解析:
- 异步爬虫(AsyncWebCrawler)
import asyncio from crawl4ai import AsyncWebCrawler async def main(): async with AsyncWebCrawler() as crawler: result = await crawler.arun(url="http://zhaomeng.net") print(result.markdown) asyncio.run(main())
代码解析:
-
AsyncWebCrawler类负责管理爬虫的生命周期,包括浏览器的启动和关闭。
-
arun方法执行爬取任务,返回一个CrawlResult对象,包含网页内容和其他元数据。
-
asyncio.run(main())用于运行异步主函数。
1.4 数据提取策略
Crawl4AI提供了多种数据提取策略,包括基于CSS/XPath的传统方法和基于LLM的智能提取。以下是使用LLM提取策略的示例:
from crawl4ai.extraction_strategy import LLMExtractionStrategy INSTRUCTION_TO_LLM = "Extract all rows from the main table as objects with 'CASNo','purity','MF','MW','SMILES','size', 'price' ,'stock' from the content." class Product(BaseModel): CASNo:str size: str price: str stock:str purity:str MF:str MW:str SMILES:str llm_strategy = LLMExtractionStrategy( provider="deepseek/deepseek-chat", api_token=apikey, schema=Product.model_json_schema(), extraction_type="schema", instruction=INSTRUCTION_TO_LLM, chunk_token_threshold=1000, overlap_rate=0.0, apply_chunking=True, input_format="markdown", extra_args={"temperature": 0.0, "max_tokens": 800}, ) async with AsyncWebCrawler() as crawler: result = await crawler.arun( url="https://www.chemshuttle.com/building-blocks/amino-acids/fmoc-r-3-amino-4-4-nitrophenyl-butyric-acid.html", extraction_strategy=extraction_strategy ) print(result.extracted_content)
解析:
-
LLMExtractionStrategy类利用LLM的语义理解能力,自动提取网页中的关键信息。
-
provider和api_token指定LLM服务提供商和API密钥。
-
schema定义需要提取的字段,instruction提供提取指导。
二、动态内容处理
Crawl4AI能够处理通过JavaScript动态加载的内容。以下是配置爬虫执行JavaScript的示例:
async with AsyncWebCrawler() as crawler: result = await crawler.arun( url="https://example.com", js_code="window.scrollTo(0, document.body.scrollHeight);", wait_for="document.querySelector('.content-loaded')" ) print(result.markdown)
解析:
-
add_hook方法注册钩子函数,可在爬取前、后等阶段执行自定义逻辑。
-
这种机制便于扩展功能,如日志记录或异常处理。
2.1 错误处理和健壮性
Crawl4AI实现了全面的错误处理机制,确保在网络不稳定或网页结构变化时稳定运行。以下是错误处理的示例:
try: result = await crawler.arun(url="https://example.com") except Exception as e: print(f"An error occurred: {e}")
解析:
-
内部捕获并处理网络错误、超时等异常,确保爬虫稳定性。
-
用户可通过try-except块处理爬取过程中的异常。
2.2 案例实战
背景导入:
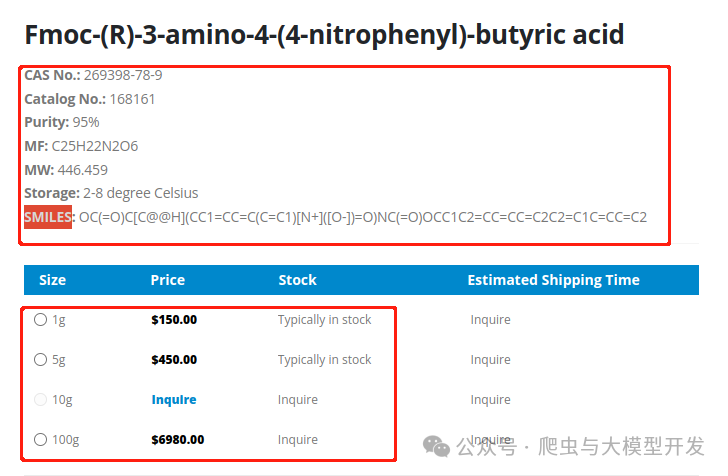
获取化学生物医药行业的站点的产品信息以及产品的价格、规格、纯度等信息
2.3.1 deepseek部署
-
ollama安装:https://ollama.com/
-
deepseek-r1本地部署
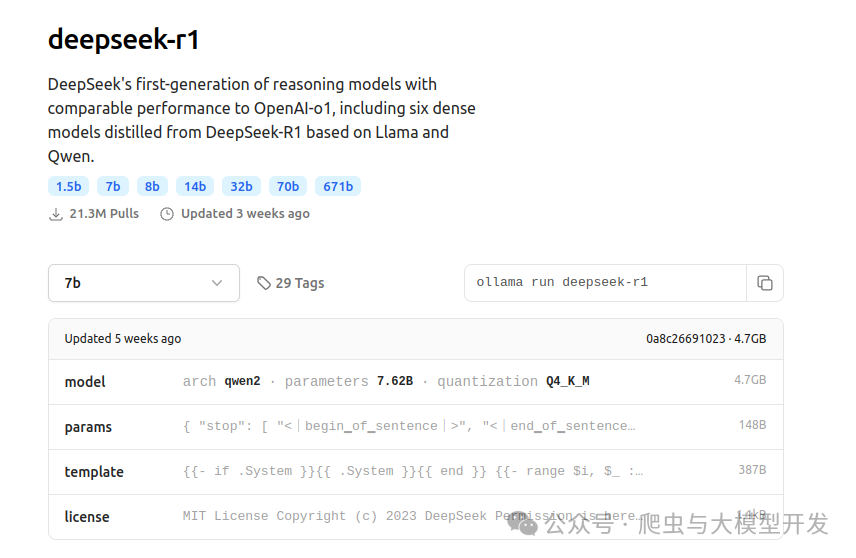
ollama run deepseek-r1:14b
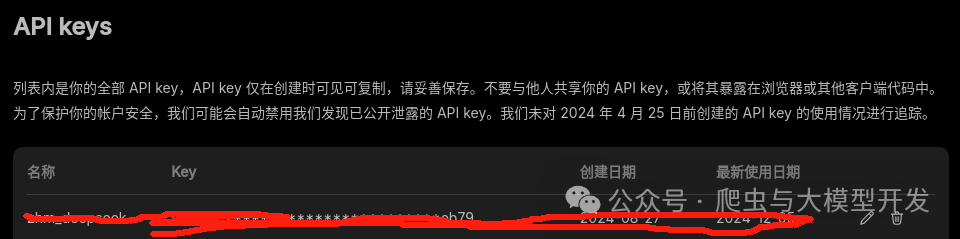
- 官网注册获取API
官网:https://platform.deepseek.com/usage
注册api_key
- 安装Crawl4AI
`pip install crawl4ai playwright install`
2.3.2 AI爬虫开发
上述的相关分析,和正常做一些爬虫业务需求是一样的,不会因为需要对接就有什么特别不太一样的,所以按正常的需求分析。
- 配置数据对象
class Product(BaseModel): CASNo:str size: str price: str stock:str purity:str MF:str MW:str SMILES:str
- 配置AI采集
llm_strategy = LLMExtractionStrategy( provider="deepseek/deepseek-chat", api_token="sk-1561f1bf223f41df908dc96cd3e5b403", schema=Product.model_json_schema(), extraction_type="schema", instruction=INSTRUCTION_TO_LLM, chunk_token_threshold=1000, overlap_rate=0.0, apply_chunking=True, input_format="markdown", extra_args={"temperature": 0.0, "max_tokens": 800}, ) crawl_config = CrawlerRunConfig( extraction_strategy=llm_strategy, cache_mode=CacheMode.BYPASS, process_iframes=False, remove_overlay_elements=True, exclude_external_links=True, )
- 无头浏览器配置及采集
browser_cfg = BrowserConfig(headless=True, verbose=True) async with AsyncWebCrawler(config=browser_cfg) as crawler: try: result = await crawler.arun(url=URL_TO_SCRAPE, config=crawl_config) if result.success: data = json.loads(result.extracted_content) print("Extracted items:", data) llm_strategy.show_usage() else: print("Error:", result.error_message) except Exception as e: print(traceback.print_exc())
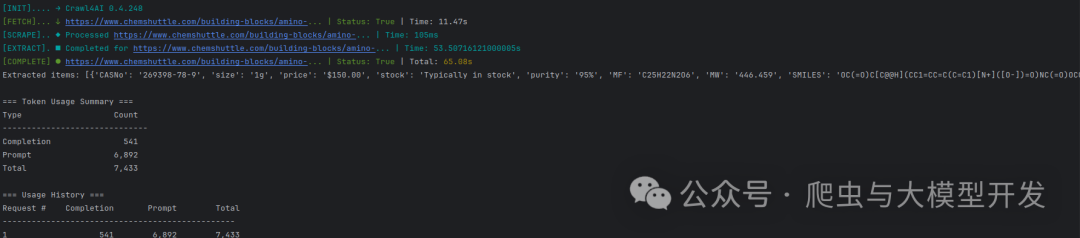
结果展示
数据展示:
Extracted items: [{'CASNo': '269398-78-9', 'size': '1g', 'price': '$150.00', 'stock': 'Typically in stock', 'purity': '95%', 'MF': 'C25H22N2O6', 'MW': '446.459', 'SMILES': 'OC(=O)C[C@@H](CC1=CC=C(C=C1)[N+]([O-])=O)NC(=O)OCC1C2=CC=CC=C2C2=C1C=CC=C2', 'error': False}, {'CASNo': '269398-78-9', 'size': '5g', 'price': '$450.00', 'stock': 'Typically in stock', 'purity': '95%', 'MF': 'C25H22N2O6', 'MW': '446.459', 'SMILES': 'OC(=O)C[C@@H](CC1=CC=C(C=C1)[N+]([O-])=O)NC(=O)OCC1C2=CC=CC=C2C2=C1C=CC=C2', 'error': False}, {'CASNo': '269398-78-9', 'size': '10g', 'price': 'Inquire', 'stock': 'Inquire', 'purity': '95%', 'MF': 'C25H22N2O6', 'MW': '446.459', 'SMILES': 'OC(=O)C[C@@H](CC1=CC=C(C=C1)[N+]([O-])=O)NC(=O)OCC1C2=CC=CC=C2C2=C1C=CC=C2', 'error': False}, {'CASNo': '269398-78-9', 'size': '100g', 'price': '$6980.00', 'stock': 'Inquire', 'purity': '95%', 'MF': 'C25H22N2O6', 'MW': '446.459', 'SMILES': 'OC(=O)C[C@@H](CC1=CC=C(C=C1)[N+]([O-])=O)NC(=O)OCC1C2=CC=CC=C2C2=C1C=CC=C2', 'error': False}]
完整代码如下
import asyncio import json import os import traceback from typing import List from crawl4ai import AsyncWebCrawler, BrowserConfig, CacheMode, CrawlerRunConfig from crawl4ai.extraction_strategy import LLMExtractionStrategy from pydantic import BaseModel, Field # URL_TO_SCRAPE = "https://nstchemicals.com/product/s-pro-xylane-cas-868156-46-1/" # INSTRUCTION_TO_LLM = "Extract all rows from the main table as objects with 'specs', 'price' from the content." URL_TO_SCRAPE = "https://www.chemshuttle.com/building-blocks/amino-acids/fmoc-r-3-amino-4-4-nitrophenyl-butyric-acid.html" INSTRUCTION_TO_LLM = "Extract all rows from the main table as objects with 'CASNo','purity','MF','MW','SMILES','size', 'price' ,'stock' from the content." class Product(BaseModel): CASNo:str size: str price: str stock:str purity:str MF:str MW:str SMILES:str async def main(): llm_strategy = LLMExtractionStrategy( provider="deepseek/deepseek-chat", api_token="api-key", schema=Product.model_json_schema(), extraction_type="schema", instruction=INSTRUCTION_TO_LLM, chunk_token_threshold=1000, overlap_rate=0.0, apply_chunking=True, input_format="markdown", extra_args={"temperature": 0.0, "max_tokens": 800}, ) crawl_config = CrawlerRunConfig( extraction_strategy=llm_strategy, cache_mode=CacheMode.BYPASS, process_iframes=False, remove_overlay_elements=True, exclude_external_links=True, ) browser_cfg = BrowserConfig(headless=True, verbose=True) async with AsyncWebCrawler(config=browser_cfg) as crawler: try: result = await crawler.arun(url=URL_TO_SCRAPE, config=crawl_config) if result.success: data = json.loads(result.extracted_content) print("Extracted items:", data) llm_strategy.show_usage() else: print("Error:", result.error_message) except Exception as e: print(traceback.print_exc()) if __name__ == "__main__": asyncio.run(main())
AI大模型学习路线
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
扫描下方csdn官方合作二维码获取哦!

这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 11
11 0
0- 0



 已为社区贡献267条内容
已为社区贡献267条内容

所有评论(0)