DeepseekR1,kimi,Chatgpt4o,grok3腾讯元宝,通义千问等模型对比评价及推荐。
自从过年期间deepseek爆火以来,我一直主要使用的他,很直观的能感受到他的逻辑能力,和反应能力,另外他能很好的理解用户的思路,即使用户只发了很少提示词,这一点就很棒,另外他不会回答你不需要的东西,也会乱回答。他的代码能力在国内模型里应该是可以排第一的,这里指的是deepseek官网的模型70b,而非其他厂家部署的。例图不过deepseek的缺点也很明显,在使用的过程中经常会系统繁忙,如果让他分
写在前面:感谢所有支持的收藏和粉丝,希望这些文章对你们有些许帮助!点点关注不迷路,免费的赞和收藏走起来!后续更新第一时间提示哦,每周会更新不同内容。
关于这些模型的应用心得,个人主观感受的优劣,差距(文末附排名)。
1.1有哪些模型
目前国内主流的是Deepseek,腾讯元宝,kimi,通义千问,豆包。链接可以点击直达大模型。
其次有百度的文心一言,清华系智谱清言,天工ai等,可以百度直接搜索。
这里的大模型均指是厂家自己训练出来的,而不是类似于那种api接口网页,一下就可以用很多大模型。
国内无法直接访问的有,chatgpt4o,grok3,Claude3.7,等这些编写代码的能力都很强,但无法直接访问,且收费不算便宜。
1.2模型的介绍(基于个人感受)
1.2.1关于deepseek
自从过年期间deepseek爆火以来,我一直主要使用的他,很直观的能感受到他的逻辑能力,和反应能力,另外他能很好的理解用户的思路,即使用户只发了很少提示词,这一点就很棒,另外他不会回答你不需要的东西,也会乱回答。他的代码能力在国内模型里应该是可以排第一的,这里指的是deepseek官网的模型70b,而非其他厂家部署的。
例图
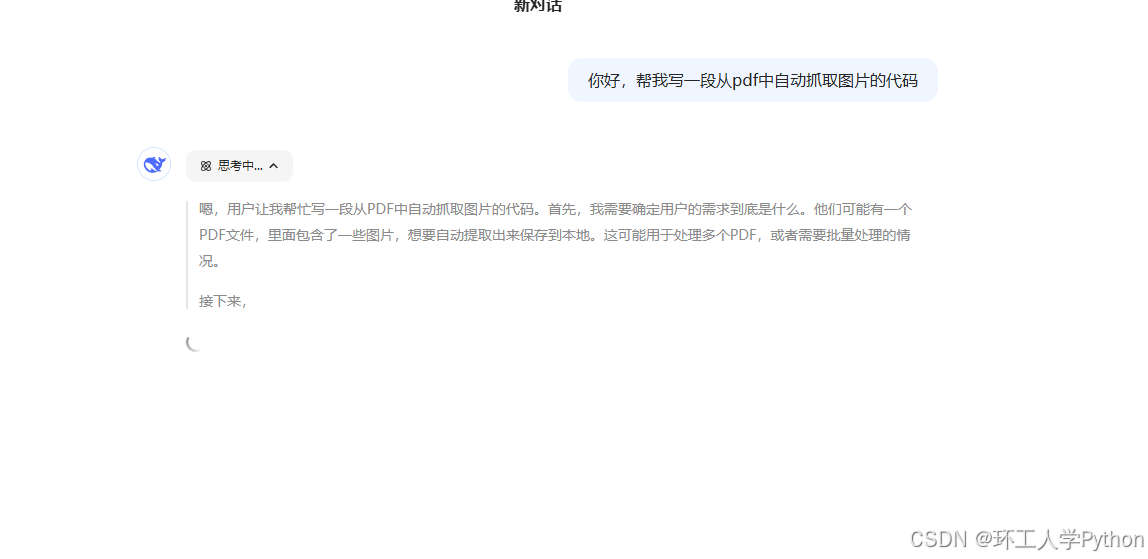
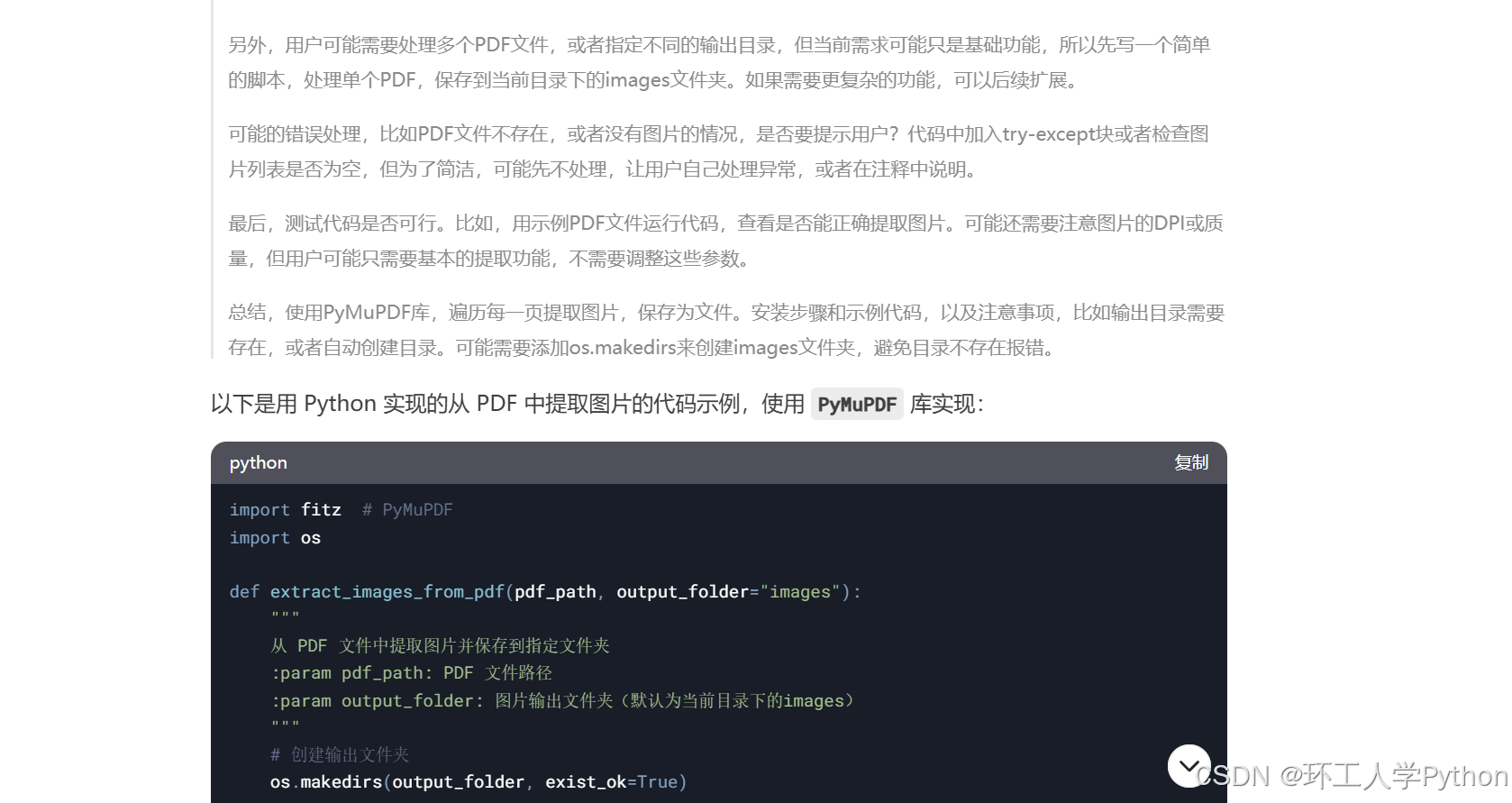
不过deepseek的缺点也很明显,在使用的过程中经常会系统繁忙,如果让他分析一些紧急的任务可能直接就炸杠了。同时输出长度是有限制的。经我个人尝试,在晚上10点之后会稍微流畅很多,系统繁忙的概率明显降低。
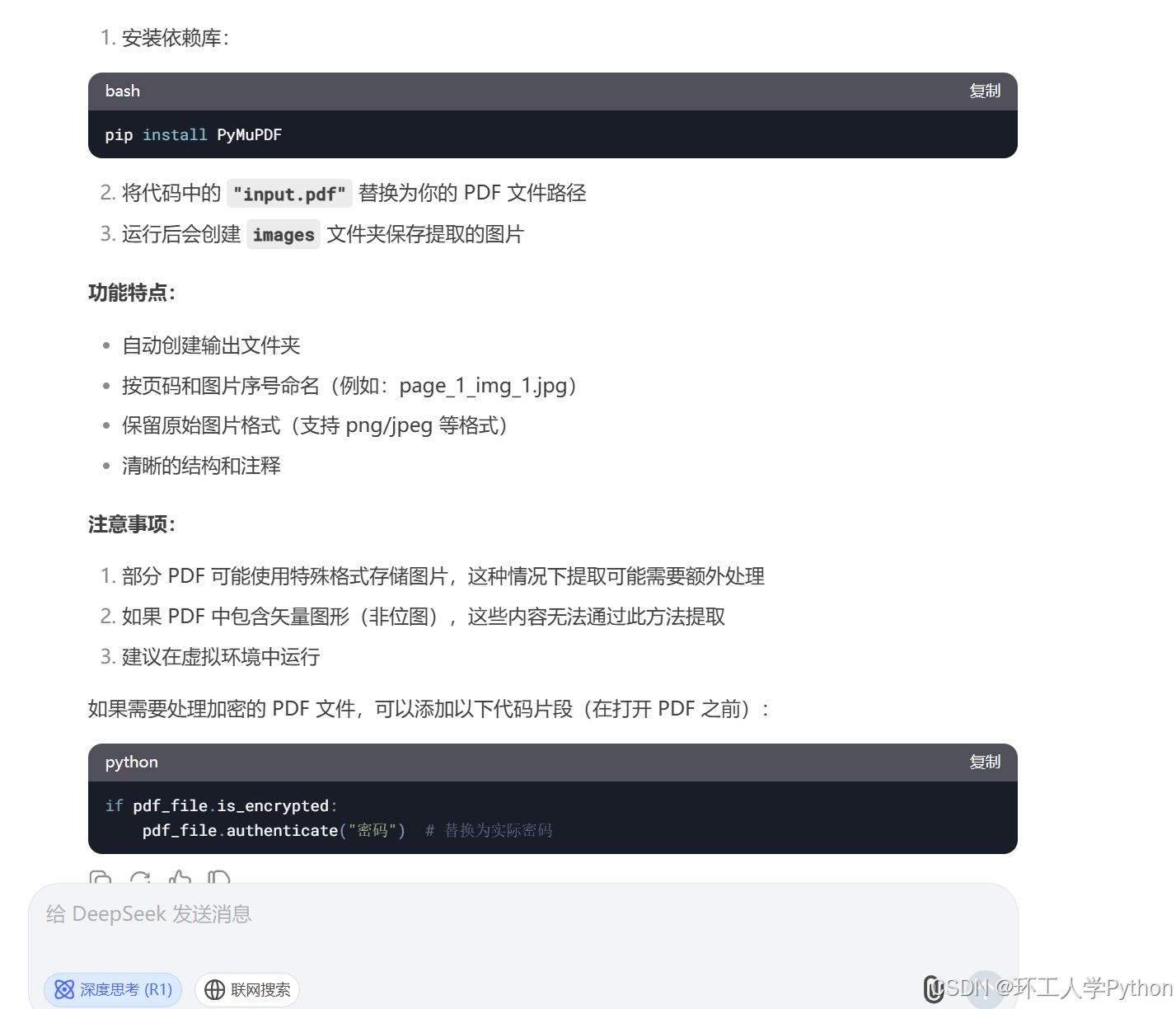
另外从年初使用至今,我能明显的感受的deepseek的回答变差了,有可能是降智了,这一点需要注意。可以算是一个好学生,代码课代表!
1.2.2关于kimi
k老师是我很早就开始使用的大模型,他问世在gpt之后也是国内较早出现的优秀模型之一,主要功能有联网搜索功能,提示词,ppt等等。他给我的直观感受是,使用很流畅,有一定的代码编写能力,早期不愿意写代码,也能让他完成一些简单任务。如果是复杂任务的化,使用他的代码经常会报错。kimi最好用的是他的文本输出功能,主要在于提示词生成,ai图片生成提示词,ai视频生成提示词等都有很好的表现。
 近期kimi也上线了k1.5长思考的功能,类似于deepseek的思考过程,也很有意思,大家可以自行体验一下。在我这kimi应该可以算得上是班里的勤奋学生,中上水平。
近期kimi也上线了k1.5长思考的功能,类似于deepseek的思考过程,也很有意思,大家可以自行体验一下。在我这kimi应该可以算得上是班里的勤奋学生,中上水平。
1.2.3关于Qwen(通义千问)
Q老师是我最近才接触到的,主要是因为那段时间deepseek老是卡,想到国内互联网大厂肯定有充足的算力和应对高并发的经验,所以尝试了一下,整体感觉良好
关于代码能力,我发现Qwen在国内的语言模型中表现还算突出可以在deepseek之下排第二了。无论是简单的脚本编写还是稍微复杂一点的程序设计,它都能提供有效的帮助。不过,与deepseek相比,有时在面对特别复杂的编程挑战时,Qwen的表现可能稍显不足,可能会遇到一些难以解决的问题或者提供的解决方案不够完善。
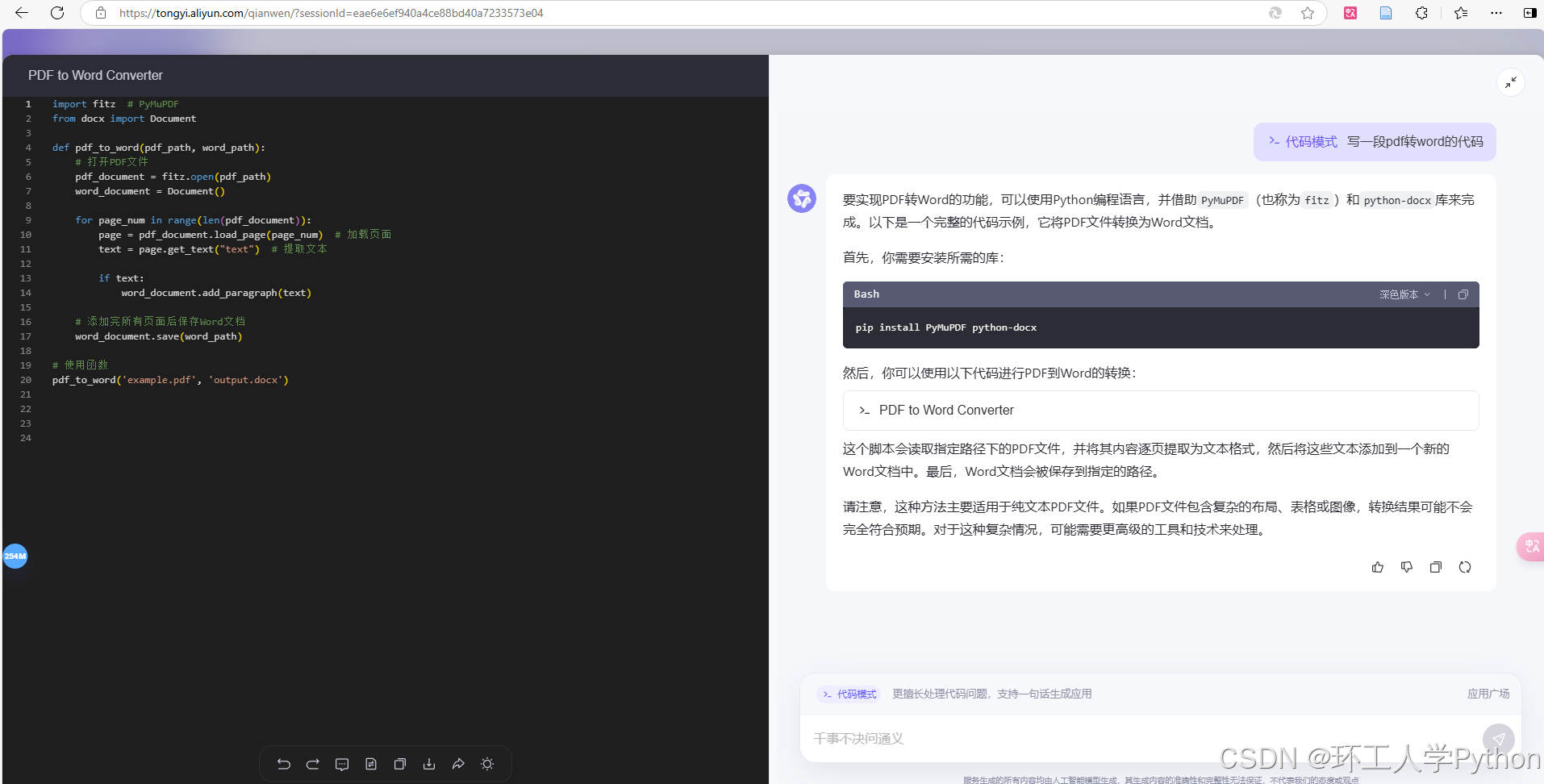
他有一个代码模式,这个模式下他可以直接给你生成代码,在旁边的页面而不是回答给你,修改代码也是在旁边的代码框里修改,但是缺点是每次让他修改他都是重头开始。
说到缺点,就像其他语言模型一样,Qwen也面临着系统繁忙导致的响应迟缓问题。虽然这种情况不如deepseek那么频繁,但在高峰期使用时,依然能感受到服务响应时间的延长,这对急需得到答案的任务来说是个小麻烦。此外Qwen也有一些其他功能,但是这个ppt制作我个人感觉没有kimi效果好,另外关于ppt,用ai做的都能明显的感觉到一股模板味,建议还是自己做。
那么很明显,我们的小Qwen同学应该就是班里的富二代了,相当有实力的那种
1.2.4关于腾讯元宝
腾讯元宝,是腾讯开发的,他的模型是混元大模型,同时接入了deepseek(30b),也是我在deepseek无法使用的时候的平替,他自己的混元模型,行为模式和deepseek基本一致。如图

但是他写的代码经常报错,让他分析自然语言也还可以,但是目前就代码能力来说国内首选deepseek,和Qwen。我更喜欢使用他提供的deepseek模型,但是只有30b处理问题的能力稍逊于官网的,但是他很流畅基本不会卡,这点很好。
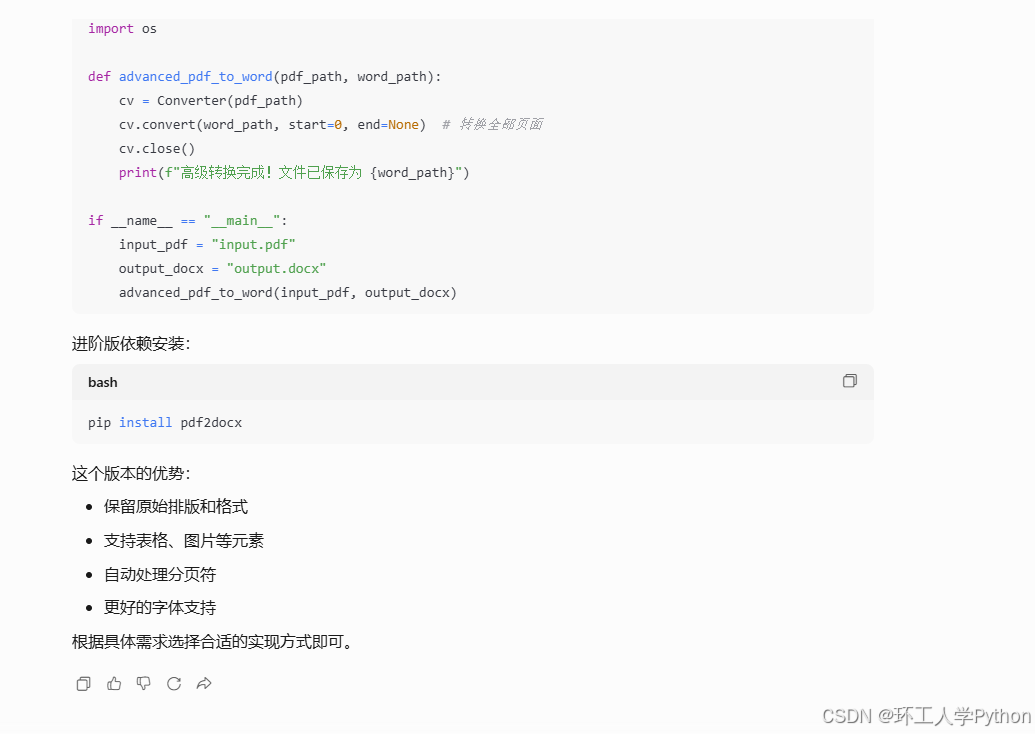
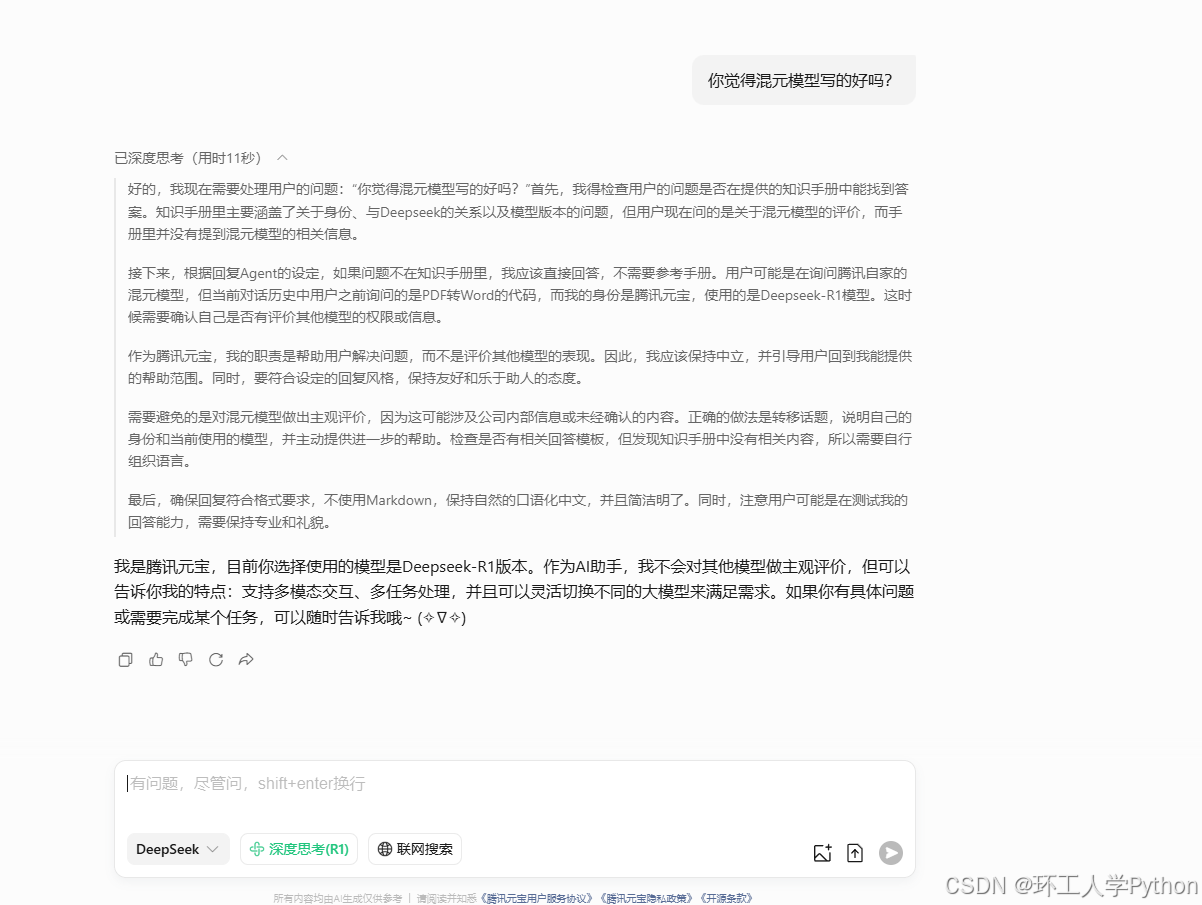
此外腾讯元宝还有智能体等,可以调用不同的模型,自己搭建工作流,让ai帮你完成任务。如图
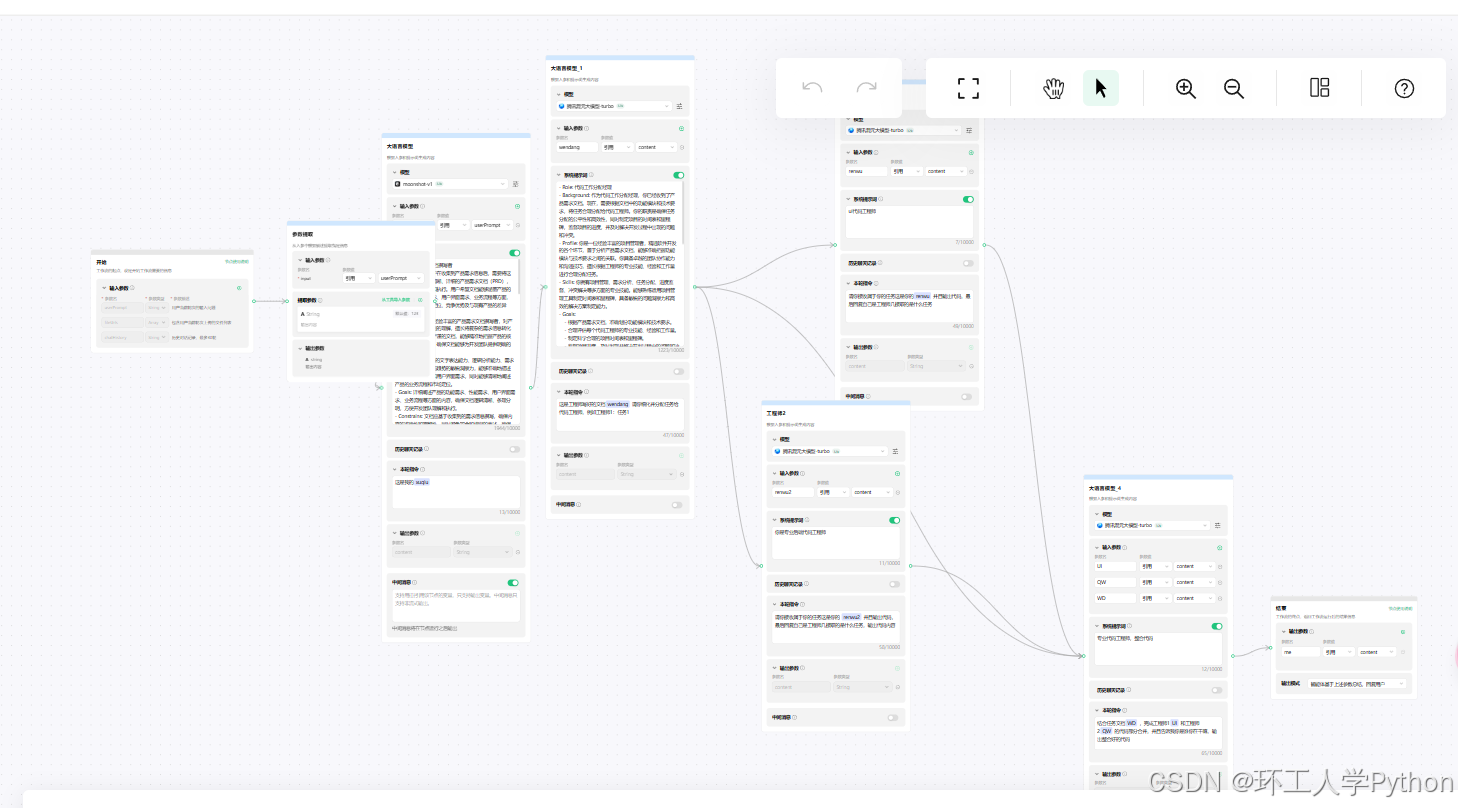
腾讯元宝应该也是班里的另一个富二代,同时学习刻苦,有很多奇思妙想,但是他人缘更好哈哈哈哈,更有人脉。
1.2.5关于豆包(我一般叫他豆书记)
豆包是抖音开发的一款ai大模型,使用手感很好不起球,耐洗(bushi),言归正传,豆书记做的客户端还是可以的,可以说是一个ai浏览器,对网络上的资源信息有一定的整合能力。也有一些不错的功能,但是我基本没有使用过。主要经过几轮问答你就会感受到他回复的有很多官话套话没啥实际作用
那么话又说回来,豆包也有一定的代码编写能力,他的写作能力也还不错,概括总结也不错,但是给人的感觉不如kimi和我们的D同学,在班里应该属于家境好但是不太愿意努力的那种学生,哈哈哈。
关于文心一言和智谱清言,我不做过多介绍,文心一言是国内出现最早的大模型ai,我第一次使用的ai模型就是他。同时需要知道的是智谱清言和kimi几乎是同时代出现的,做了很久他主要特点是GLM,你可以创建很多属于你个人的智能体,结合你提供的文献资源,完善了很多小功能,而且比其他模型更早给出ai画图ai生成视频功能,可能是公司相对小一些,没有很多人使用,大家有需求和兴趣可以取试试哦
1.2.6总结及个人推荐程度
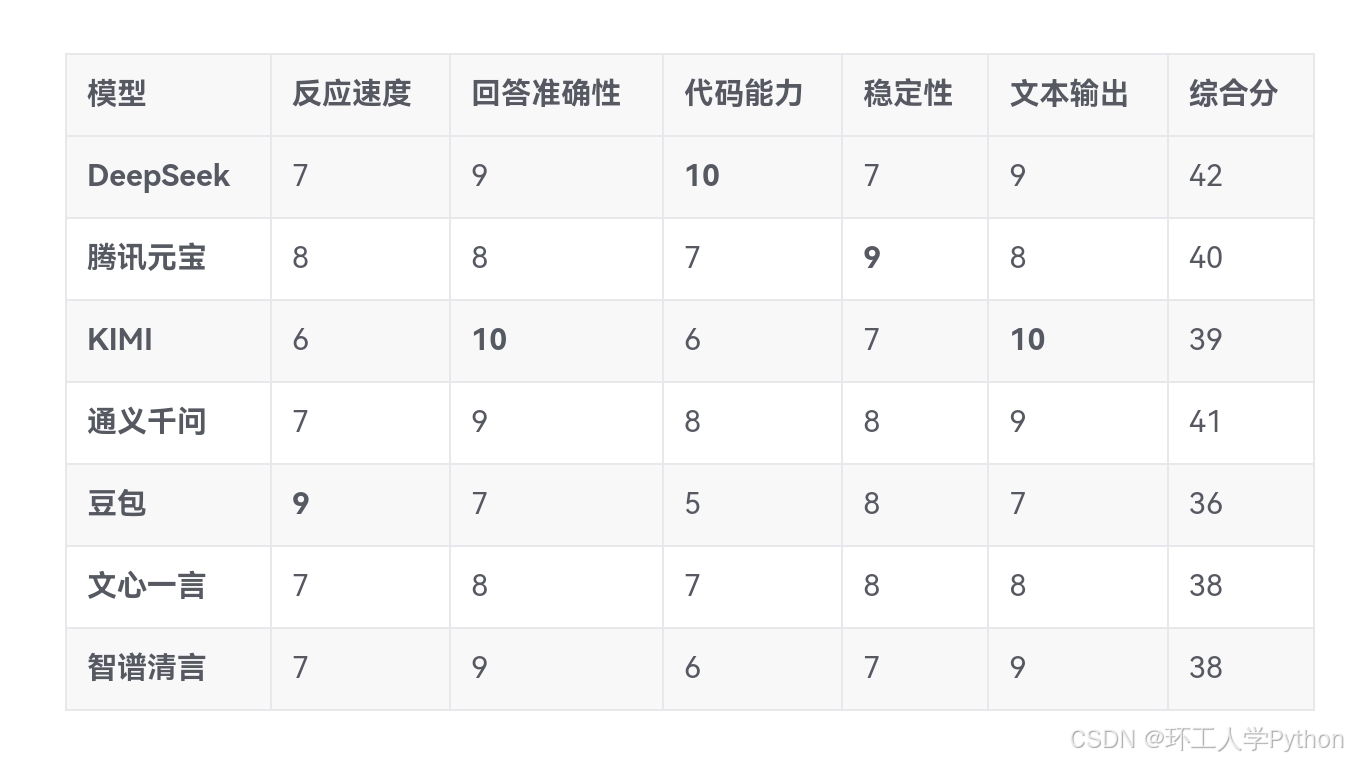
以下是根据 反应速度、回答准确性、代码能力、稳定性、文本输出 五大维度,对国内主流自研大模型的星级评分(满分10分):
模型 反应速度 回答准确性 代码能力 稳定性 文本输出 综合分
1.2.6.1评分标准说明
• 反应速度:模型响应延迟(从输入到输出的耗时)
• 回答准确性:对事实性问题、逻辑推理的准确率
• 代码能力:代码生成、调试、注释的实用性
• 稳定性:服务可用性、抗高并发能力
• 文本输出:生成文本的逻辑性、流畅度、创意性
1.2.6.2模型特性与场景推荐
1. DeepSeek
◦ 优势:代码生成能力国内领先,技术文档解读精准,适合开发者。
◦ 短板:长文本处理易截断,高并发时响应延迟明显。
◦ 场景:编程辅助、数据分析、算法优化。
2. 腾讯元宝
◦ 优势:多模态交互流畅(图文混合输入),服务稳定性强。
◦ 短板:复杂逻辑推理能力较弱,创意内容生成模板化。
◦ 场景:C端轻量级应用(客服、内容摘要)。
3. KIMI
◦ 优势:200万字长上下文支持,信息检索准确性高。
◦ 短板:响应速度较慢,代码能力局限于简单脚本。
◦ 场景:长文献解析、知识库问答、研报分析。
4. 通义千问
◦ 优势:多模态生成均衡(文本/图像/视频),工具调用灵活。
◦ 短板:代码调试能力弱于DeepSeek,部分回答冗余。
◦ 场景:通用办公助手、跨模态内容创作。
5. 豆包
◦ 优势:响应速度最快,对话风格轻松活泼。
◦ 短板:专业性不足,复杂问题易“胡编乱造”。
◦ 场景:社交娱乐、简单信息查询。
6. 文心一言
◦ 优势:中文古诗词生成、文化类问答表现突出。
◦ 短板:代码生成错误率较高,实时信息更新滞后。
◦ 场景:教育、文化传播、营销文案。
7. 智谱清言
◦ 优势:学术论文解析能力较强,支持公式推导。
◦ 短板:多轮对话易偏离主题,稳定性波动较大。
◦ 场景:科研辅助、教育解题。
1.3国外大模型简单介绍
1.3.1关于chatgpt
gpt是第一个进入全球视野的AI大模型,他有着很强的代码,逻辑推理能力。作为目前全球领先的大语言模型,ChatGPT在复杂任务处理精度和多模态扩展性上具有显著优势,尤其适合对输出质量要求较高的专业场景。其使用成本与合规要求可能成为规模化应用的瓶颈,但在中国本土化适配方面存在改进空间。
逻辑推理与问题解决:擅长处理多步骤复杂任务(如数学证明、代码调试),能拆解问题并提供系统性解决方案。对模糊指令的意图理解较强,常通过追问澄清需求细节。
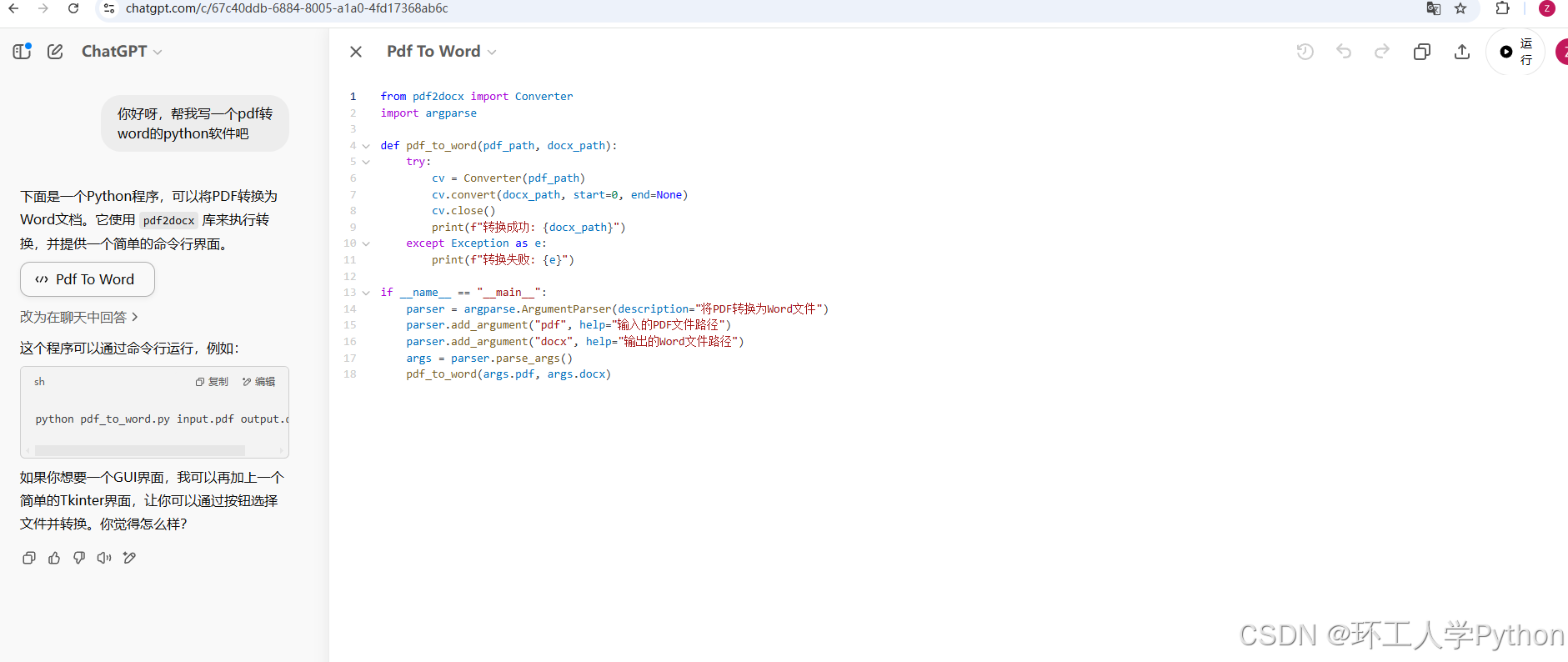
代码能力:支持Python、JavaScript等主流语言,可生成完整可运行脚本(含异常处理、性能优化建议)。提供代码注释和原理说明,适合教学场景。
文本生成质量:长文本结构严谨,段落间逻辑衔接自然,较少出现重复或偏离主题。学术写作中引用文献格式(如APA)准确率较高。
稳定性与响应速度:云端服务全年无休,99%以上时间可即时响应(依赖网络连接质量)。复杂任务平均响应时间3-8秒,简单交互通常在2秒内完成。
多模态扩展:GPT-4版本支持图像/音频输入,例如:识别图片中的手写代码并转写为可执行程序解析流程图自动生成技术文档
他这个代码画布我很喜欢,Qwen同学和他是有点像的。好像还可以运行,修复代码,代码审查什么的,但是到目前位置我一次都没有直接在网页中运行成功过(难泵)
缺点很明显:
一方面是国内基本无法使用,除非你去找镜像网站或者自己用魔法,其次他在国外访问确实很稳定,但是在国内完全就却决于你的梯子稳不稳了。另一方面,gpt3.5免费使用但是能力有限,相较之下不如我们的D同学,gpt4o能力超强,但是是真的贵,20美元一个月吧。这哥们在班里属于是很能干,但是平时请不动的同学。
1.3.2关于claude3.7
claude3有很多版本,目前最强的是最近发布的3.7Sonnet。我靠,这位在代码编写方面更是重量级,他写出来的代码基本没问题,适用于不想反复修改代码的小白,如果给他评分代码能力应该是100分,满分10分的话哈哈哈。但是值得差评的是!在国内几乎无法使用,此外就算你翻出去了,你用国内手机号注册的账号好像还是无法使用。。

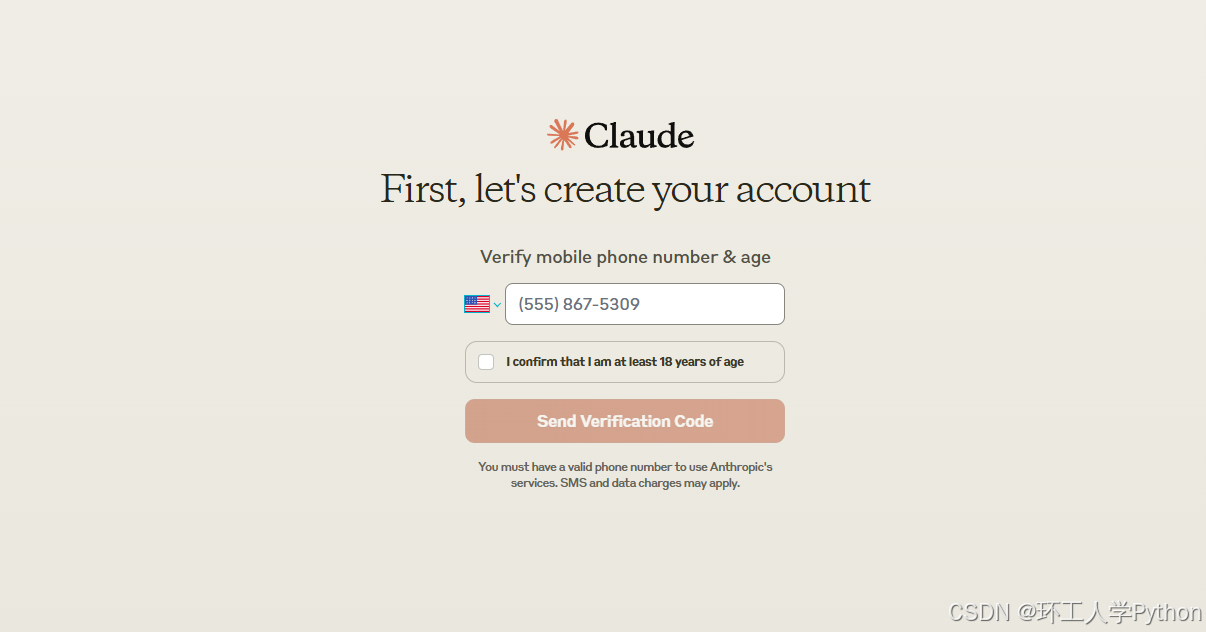
登陆完还要验证手机号,这波直接炸杠了,老铁。这哥们在班里,自己学自己的,也不管老师讲啥,反正自己考985。
1.3.3关于grok3
这个是马斯克发布的最新的超级ai,同样的无法直接在国内使用,据他说是世界上最牛的ai大模型。听说Grok 3 的训练依托于 20 万块英伟达 H100 GPU 构建的“Colossus”超级计算集群(位于美国孟菲斯),计算能力较前代 Grok 2 提升 10 倍。其训练数据集扩展至法律文件、多模态内容等更广泛领域,并通过强化学习优化推理路径出来的。有很强的推理与自我纠错能力。其代码能力也相当不错,免费使用但是目前每天只能问他2次还是3次(使用深度思考能力)。只能等到第二天刷新。

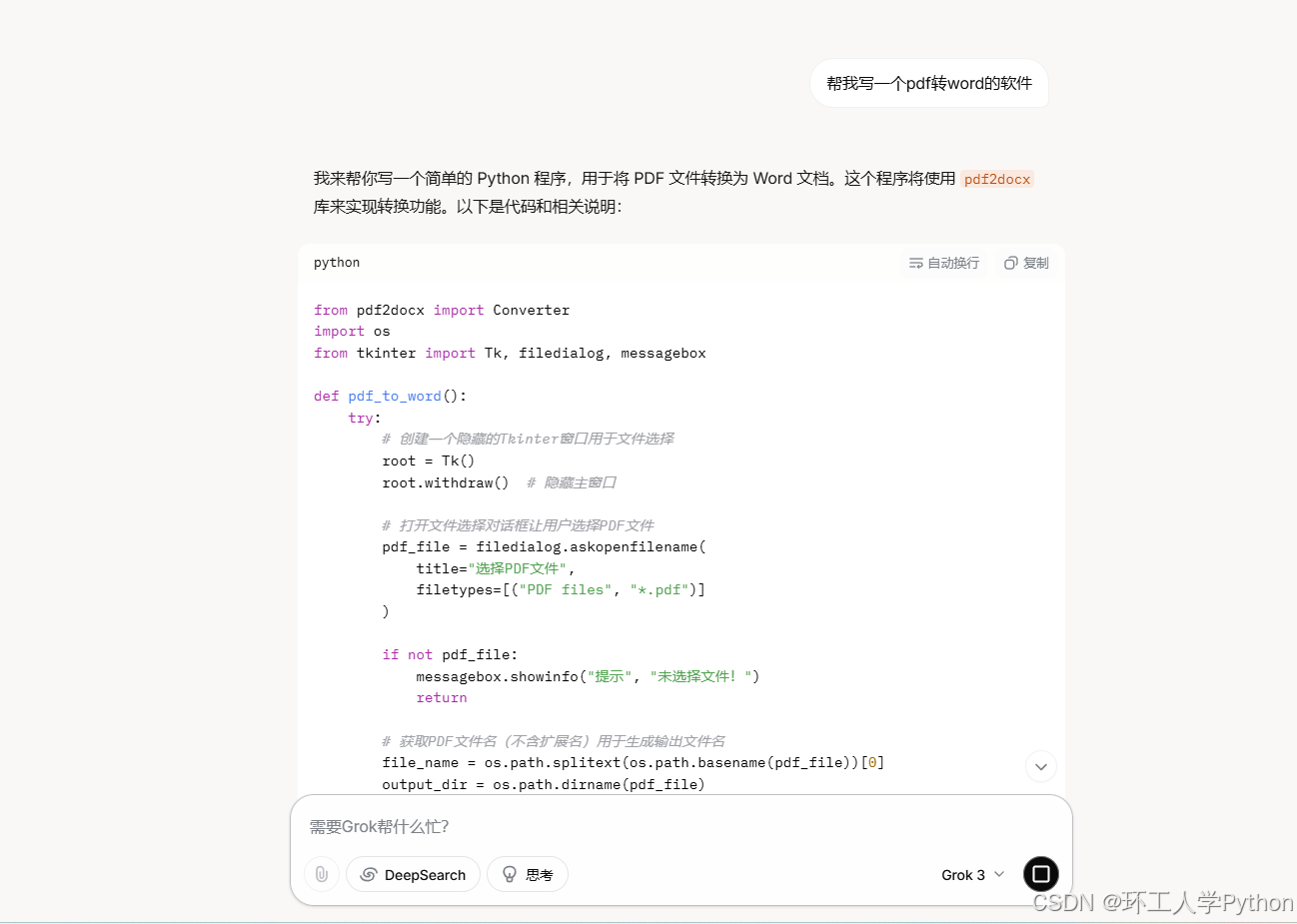
他的回答超级快,这是我没有点思考功能,如果点了深度思考功能估计会慢一点。目前我对他的使用还比较少,主要还是在应用我们的大D同学,实在碰到解决不了的问题才会去请这三位帮忙。
1.3.4总结及个人推荐程度
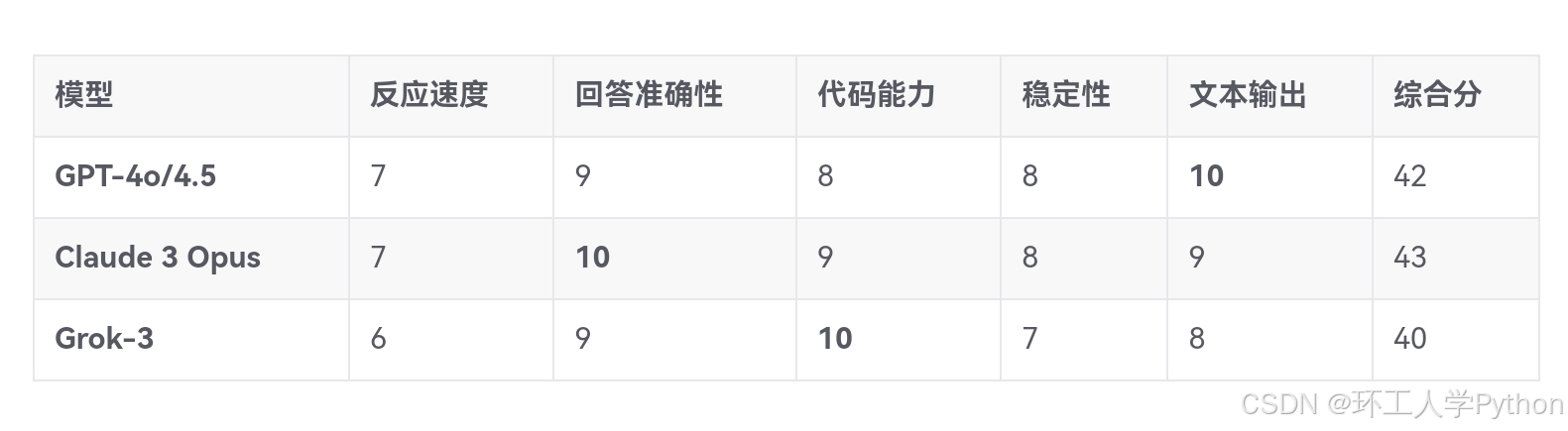
模型 反应速度 回答准确性 代码能力 稳定性 文本输出 综合分
1.4总结排序
代码开发场景
推荐排序:Cluade3.7>DeepSeek >通义千问 > 腾讯元宝 > kimi>豆包
学术研究场景
推荐排序:KIMI > 通义千问 > 智谱清言 > DeepSeek
通用办公场景
推荐排序:Deepseek>腾讯元宝 > 通义千问 > KIMI > 豆包
这篇文章从各个方面详细的介绍了目前国内外主流的AI大模型,详细的介绍了每个模型的优缺点使用限制等等,图文并茂,可以帮助读者,选择合适的ai模型在日常工作中。
另外以上内容均以我个人体验总结,如您觉得有不同的意见,或者想法可以在评论区分享哦。关于模型的使用,有不懂的地方也可以私聊我!

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 29
29 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)