5分钟看懂Deepseek开源周之一:推理革命!DeepSeek开源FlashMLA黑科技:长文本处理提速5.76倍,中小公司也能玩转千亿模型
在一个普通的2月21日周五,把硅谷资本搅得天翻地覆的深度求索突然发布乐一个开源周的预告,一下子抓住了全行业的眼球。看得出来,这一周要来一波大的!
前言
在一个普通的2月21日周五,把硅谷资本搅得天翻地覆的深度求索突然发布乐一个开源周的预告,一下子抓住了全行业的眼球。看得出来,这一周要来一波大的!
开源第一天:FlashMLA机制
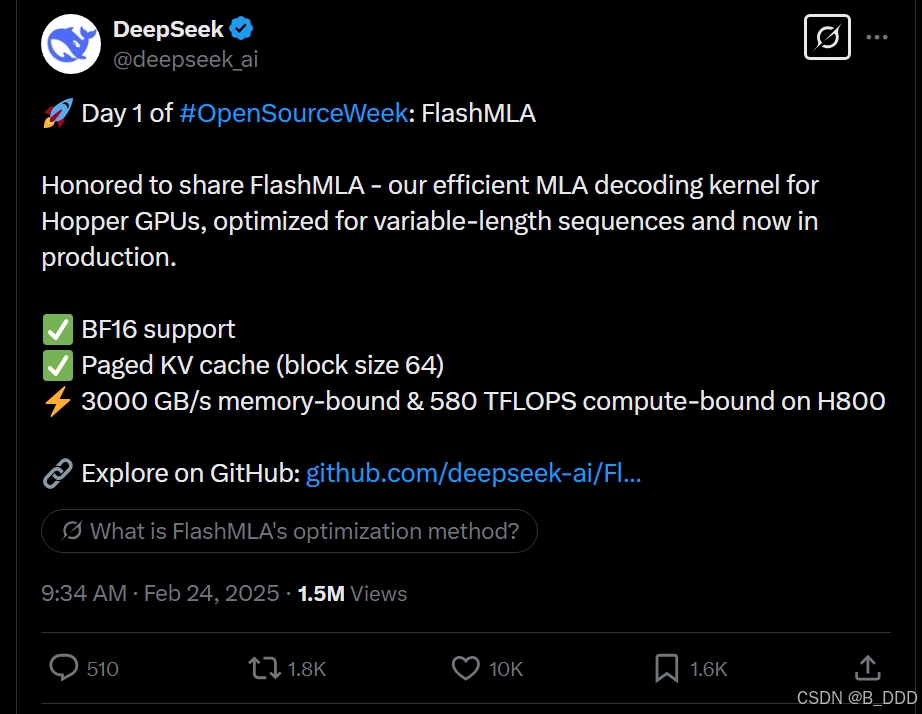
很荣幸分享 FlashMLA —— 我们为 Hopper GPU 开发的高效 MLA 解码内核,针对变长序列进行了优化,现已投入生产。
- 支持 BF16 格式
- 分页 KV 缓存(块大小 64)
- 在 H800 GPU 上,内存受限性能达到 3000 GB/s,计算受限性能达到 580 TFLOPS
在 GitHub 上探索:github.com/deepseek-ai/FlashMLA![]() https://github.com/deepseek-ai/FlashMLA
https://github.com/deepseek-ai/FlashMLA
FlashMLA
FlashMLA 是一个专为 Hopper GPU 设计的高效 MLA(多头注意力机制)解码内核,针对可变长度序列服务进行了优化。当前已发布的功能包括:
-
多精度支持
支持 BF16 和 FP16 数据格式,通过低精度计算减少内存占用和计算开销,同时保持合理的数值精度。例如,BF16 格式可在保证模型精度的前提下,将内存占用降低约 50%。 -
分页 KV 缓存技术
采用块大小为 64 的分页键值缓存(Paged kvcache),动态分配内存资源,有效减少内存碎片化问题,提升变长序列处理的效率。该设计特别适用于长文本生成场景,实测可减少 50% 的内存浪费。 -
性能表现
在 Hopper 架构的 H800 GPU 上,FlashMLA 实现了接近硬件极限的性能:内存带宽达 3000 GB/s(接近 H800 理论上限的 89.5%),计算吞吐量达 580 TFLOPS(Tensor Core 利用率超 75%)。这一优化使得它在处理长序列时比传统方法效率提升显著。
Hopper架构的核心技术革新
Hopper架构是英伟达于2022年推出的新一代GPU架构,专为高性能计算(HPC)、生成式AI和大规模深度学习设计。其核心创新包括:
- Transformer Engine
- 针对大语言模型(如GPT-4)的专用优化,支持动态混合精度(FP8/FP16),显存占用减少50%,训练吞吐量提升2倍。
- 稀疏计算优化,跳过无效Attention权重,减少30%浮点运算量,实测1750亿参数的GPT-3训练时间从34天缩短至11天(基于H100集群)。
- HBM3高带宽内存
- 显存带宽达3.35TB/s(H100)或3.9TB/s(H800高配版),对比前代A100(1.6TB/s)提升2倍以上,支持单卡承载超2000亿参数模型。
- 采用台积电CoWoS 2.5D封装技术,结合异步内存拷贝和错误恢复机制,保障大规模集群稳定运行。
- 第四代NVLink互连技术
- 单GPU双向带宽达900GB/s(H100),支持256块GPU全互联,分布式训练梯度同步延迟降至纳秒级,适应百亿亿次计算需求(如欧洲LUMI超算)。
H800是英伟达针对中国市场定制的Hopper架构产品,主要面向受美国出口管制的AI训练与推理场景。其核心特点如下:
- 性能缩水与优化平衡
- 带宽限制:卡间通信带宽从H100的900GB/s降至400GB/s(SXM版),PCIe版进一步降至128GB/s,显存带宽缩水至2TB/s(PCIe版)。
- 双精度计算阉割:FP64计算能力仅1 TFLOPS(H100为34 TFLOPS),限制科学计算等高精度场景应用。
- 显存优势:配备80GB或96GB HBM3显存,带宽仍显著高于A100(1.6TB/s),适合大规模模型推理。
- 应用场景与市场定位
- 训练与推理:支持FP8混合精度训练(关键操作用FP8,敏感层保留BF16/FP32),优化资源消耗,适合企业级AI模型开发。
- 灵活部署:PCIe版支持2-8卡灵活配置,适配传统服务器和小型工作站,功耗降至300-350W(SXM版700W)。
- 性价比选择:在大规模集群中,SXM版性价比更优;中小规模场景下,PCIe版提供低成本替代方案。
| 型号 | 架构 | 显存带宽 | 互联带宽 | 典型应用 | 中国市场定位 |
|---|---|---|---|---|---|
| H100 | Hopper | 3.35TB/s | 900GB/s | 大规模训练、HPC | 国际版,受限出口 |
| H800 SXM | Hopper | 3.35TB/s | 400GB/s | 大型AI训练 | 专供中国 |
| H800 PCIe | Hopper | 2TB/s | 128GB/s | 中小型推理 | 灵活部署 |
| H20 | Hopper | 带宽受限 | 未知 | 中等训练/推理 | 新一代中国定制 |
快速开始
安装
python setup.py install测试标准
python tests/test_flash_mla.py在H800 SXM5 GPU上,结合CUDA 12.8的使用,FlashMLA在内存受限配置下可实现高达3000 GB/s的显存带宽,在计算受限配置下达到580 TFLOPS的算力峰值。
示例
from flash_mla import get_mla_metadata, flash_mla_with_kvcache
tile_scheduler_metadata, num_splits = get_mla_metadata(cache_seqlens, s_q * h_q // h_kv, h_kv)
for i in range(num_layers):
...
o_i, lse_i = flash_mla_with_kvcache(
q_i, kvcache_i, block_table, cache_seqlens, dv,
tile_scheduler_metadata, num_splits, causal=True,
)
...这个示例展示了在神经网络的前向传播过程中,如何使用 FlashMLA 来高效地计算多头线性注意力(Multi-head Linear Attention):
初始化元数据:
- - get_mla_metadata 函数用于生成 FlashMLA 所需的调度元数据
- cache_seqlens 是 KV 缓存中各序列的长度
- s_q * h_q // h_kv 计算 query 头数与 key/value 头数的比例
- h_kv 是 key/value 的头数
在模型层中应用 FlashMLA:
- 在模型的每一层中调用 flash_mla_with_kvcache 函数
- q_i 是当前层的查询张量
- kvcache_i 是 KV 缓存
- block_table 是 KV 缓存的块表,用于分页 KV 缓存
- dv 可能是值向量的维度
- causal=True 表示使用因果注意力机制(只关注序列中当前位置之前的位置)
- 函数返回注意力输出 o_i 和对数和指数 lse_i
这个示例特别展示了 FlashMLA 如何与 KV 缓存结合使用,这在大型语言模型的推理过程中非常重要,因为它可以避免重复计算先前位置的 key 和 value,从而显著提高推理速度。
依赖项
- 必须是Hopper GPU
- CUDA 12.3 及以上版本
但强烈建议使用 CUDA 12.8 或更高版本 以获得最佳性能。 - PyTorch 2.0 及以上版本
PyTorch 2.0 引入了动态形状支持和性能优化,显著提升大规模模型训练效率
致谢
FlashMLA 的灵感来源于 FlashAttention 2&3 和 CUTLASS 项目。
社区支持
以下是不同硬件厂商对应的 FlashMLA 版本及资源链接:
-
MetaX
- 官网链接:MetaX
- FlashMLA 版本:MetaX-MACA/FlashMLA
-
摩尔线程(Moore Threads)
- 官网链接:Moore Threads
- FlashMLA 版本:MooreThreads/MT-flashMLA
-
海光 DCU(Hygon DCU)
- 官网链接:海光开发者
- FlashMLA 版本:OpenDAS/MLAttention
-
天数智芯(Intellifusion)
- 官网链接:天数智芯
- FlashMLA 版本:Intellifusion/tyllm(Gitee)
-
燧原科技(Iluvatar Corex)
- 官网链接:Iluvatar Corex
- FlashMLA 版本:Deep-Spark/FlashMLA
-
AMD Instinct
- 官网链接:AMD Instinct
- FlashMLA 版本:AITER/MLA

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 14
14 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)