Java技术栈升级:结合DeepSeek和RAGFlow打造智能问答系统
接下来,让我们了解一下搭建私有知识库所需的工具。这里主要介绍两款开源工具:DeepSeek和RAGFlow。通过以上步骤,我们已经成功搭建了一个基于RAGFlow和DeepSeek的私有知识库。这个系统不仅能够保障数据隐私,还能提升工作效率,并且具备强大的智能问答功能。随着时间的推移,你可以继续扩展知识库、更新模型,打造一个持续进化的智能平台。
Java技术栈升级:结合DeepSeek和RAGFlow打造智能问答系统
前言
在当今数字化时代,AI技术正以惊人的速度改变着我们的工作和生活。无论是企业还是个人,都渴望能够高效地管理和利用知识资源。今天,就让我们一起探索如何利用开源项目DeepSeek和RAGFlow,搭建一个属于自己的AI私有知识库,让你的知识管理更加智能、高效!
为何选择本地部署?
对于个人而言,免费的在线知识库可能已经足够使用。但对于企业来说,数据隐私、定制化需求以及可扩展性是至关重要的。本地部署可以确保数据安全,同时根据企业需求灵活定制,还能支持大规模数据处理。因此,搭建一个私有知识库,无疑是企业数字化转型的明智选择。
RAG技术原理
RAG(Retrieval-Augmented Generation)是一种结合了信息检索和文本生成的技术。它的工作原理是:当你提出一个问题时,系统会先从知识库中检索出与问题相关的信息,然后基于这些信息生成准确且高质量的回答。相比传统的生成模型,RAG技术在问答场景中更加精准,能够更好地满足企业对知识管理的需求。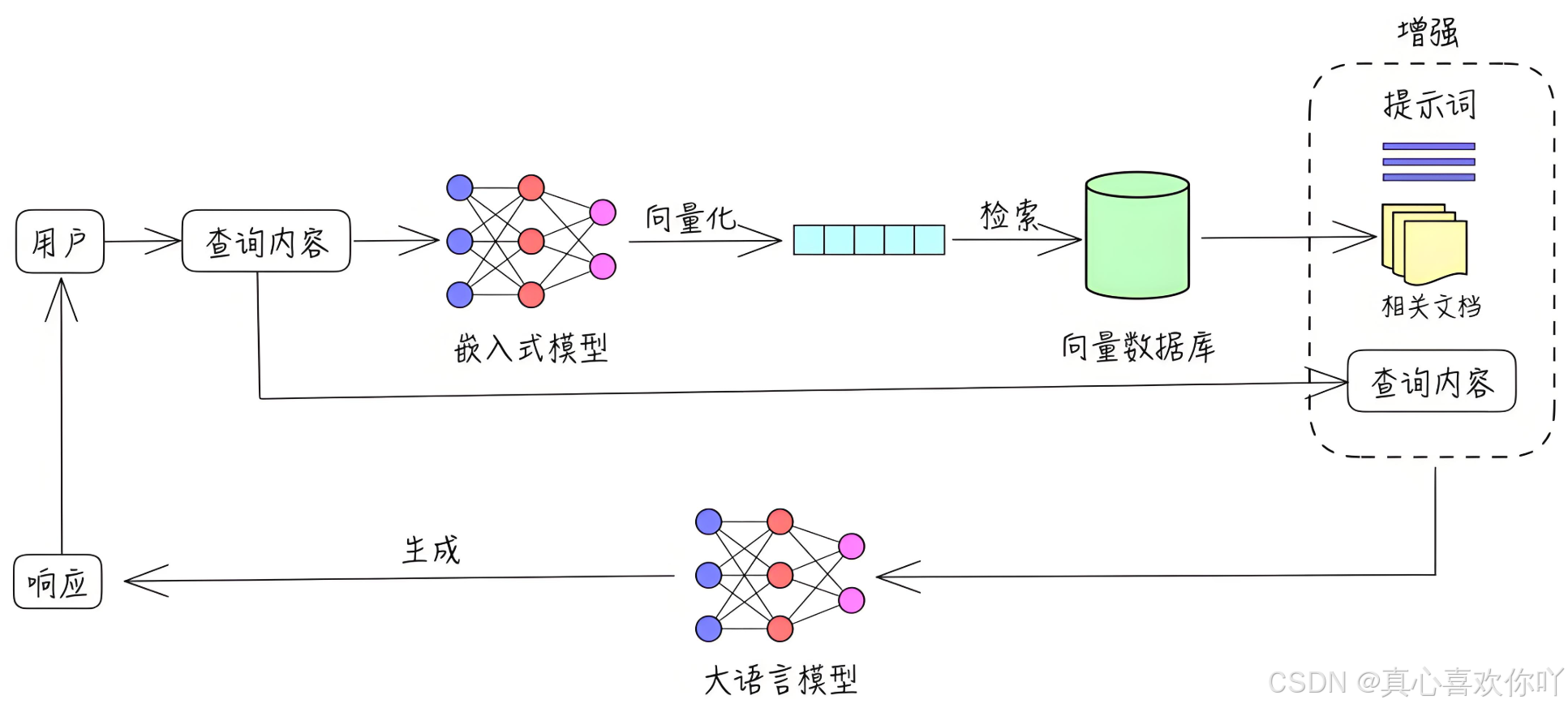
RAG技术的优势
- 精准回答:RAG技术通过检索相关文档后再生成回答,避免了传统生成模型可能出现的“胡说八道”问题。
- 可扩展性强:无论是企业内部的文档、数据库,还是外部的知识资源,都可以整合到RAG系统中,随时扩展知识库。
- 引用可靠:RAG系统会引用原始文档内容,确保回答的准确性和可靠性,让使用者更有信心。
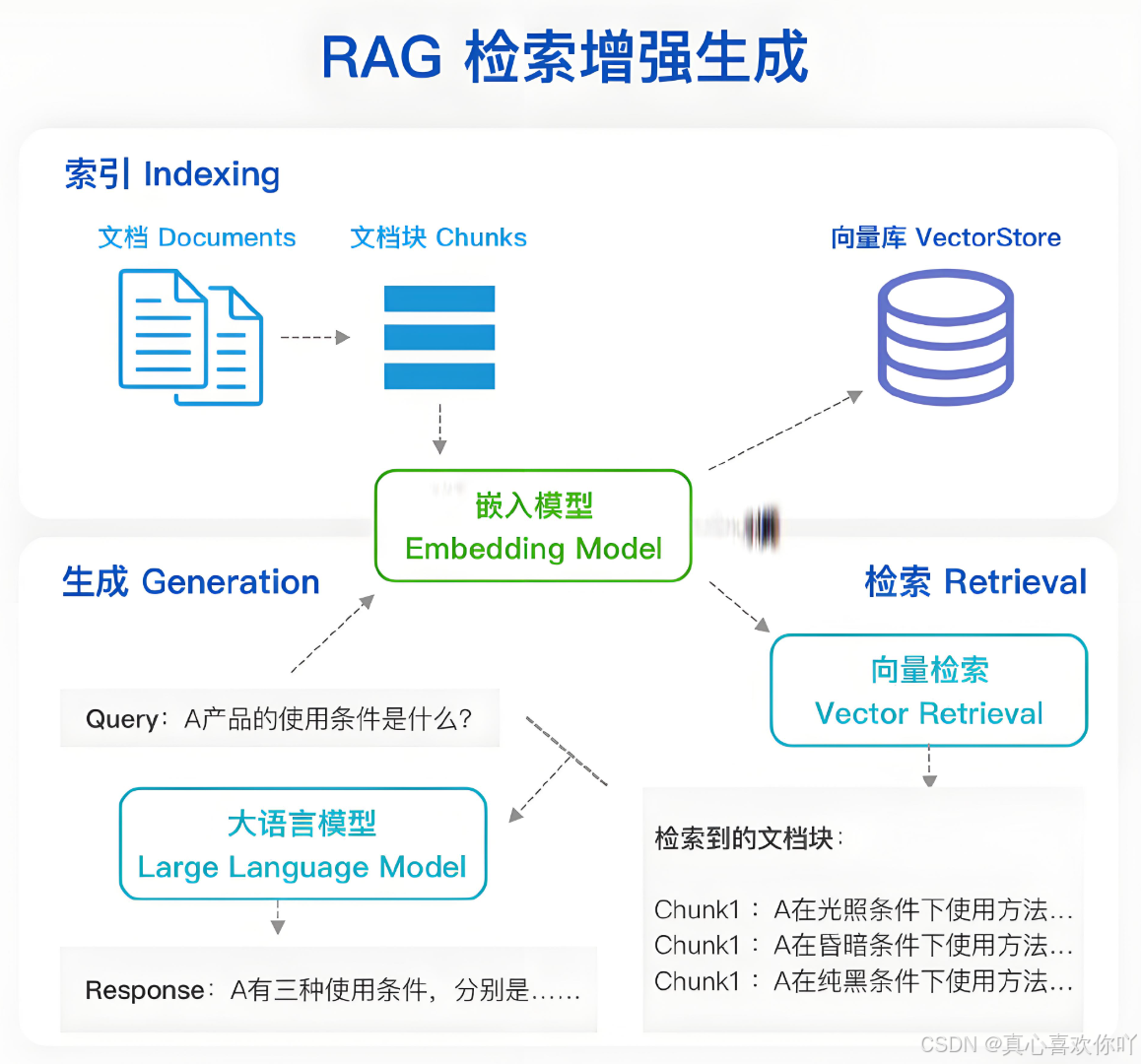
工具介绍
接下来,让我们了解一下搭建私有知识库所需的工具。这里主要介绍两款开源工具:DeepSeek和RAGFlow。
DeepSeek
DeepSeek是一款强大的语言模型,能够提供高质量的文本生成能力。它支持多种部署方式,包括本地部署和云服务,方便用户根据自身需求进行选择。
RAGFlow
RAGFlow是一个开源的RAG引擎,专注于深度文档理解。它可以为企业和个人提供一套精简的RAG工作流程,支持复杂格式数据的问答,并且能够引用原始文档内容,确保回答的准确性和可靠性。
搭建步骤
步骤1:环境准备
在开始搭建之前,我们需要确保服务器或本地机器满足以下要求:
- 操作系统:Linux或Windows
- 内存:至少16GB,建议32GB以上
- 存储空间:至少500GB的空闲磁盘空间
- Docker:RAGFlow和DeepSeek都支持Docker部署,确保Docker版本 >= 24.0.0,Docker Compose版本 >= v2.26.1
如果尚未安装Docker,可以参考官方文档进行安装。
步骤2:安装Ollama
Ollama是一个轻量级的模型管理工具,可以帮助我们更方便地部署和管理DeepSeek模型。以下是安装步骤:
-
下载安装脚本:
curl -fsSL https://ollama.com/install.sh -o ollama_install.sh -
替换官方下载地址,以便更快地下载模型:
sed -i 's|https://ollama.com/download/|https://github.com/ollama/ollama/releases/download/v0.5.7/|' ollama_install.sh -
运行安装脚本:
sh ollama_install.sh
步骤3:运行DeepSeek 8B模型
安装完Ollama后,我们就可以运行DeepSeek模型了。以下是具体步骤:
-
下载DeepSeek 8B模型:
ollama pull deepseek-r1:8b -
启动模型:
ollama run deepseek-r1:8b
步骤4:运行RAGFlow
RAGFlow支持Docker部署,非常简单。以下是详细的安装步骤:
-
检查系统配置:确保
vm.max_map_count不小于262144。可以通过以下命令查看当前值:sysctl vm.max_map_count如果值小于262144,可以临时修改为:
sudo sysctl -w vm.max_map_count=262144如果需要永久修改,还需要在
/etc/sysctl.conf文件中添加以下内容:vm.max_map_count=262144 -
克隆RAGFlow仓库:
git clone https://github.com/infiniflow/ragflow.git -
创建并启动容器:进入
docker文件夹,运行以下命令启动RAGFlow服务:cd ragflow/docker docker compose -f docker-compose.yml up -d -
检查服务器状态:运行以下命令查看服务器日志,确认服务是否正常启动:
docker logs -f ragflow-server如果看到以下提示,说明服务器启动成功:
____ ___ ______ ______ __ / __ \ / | / ____// ____// /____ _ __ / /_/ // /| | / / __ / /_ / // __ \| | /| / / / _, _// ___ |/ /_/ // __/ / // /_/ /| |/ |/ / /_/ |_|/_/ |_|\____//_/ /_/ \____/ |__/|__/ * Running on all addresses (0.0.0.0) * Running on http://127.0.0.1:9380 * Running on http://x.x.x.x:9380 INFO:werkzeug:Press CTRL+C to quit
步骤5:登录并配置RAGFlow
- 登录:打开浏览器,访问
http://localhost:9380,进入RAGFlow的Web界面。 - 检查Ollama状态:确保Ollama服务正常运行,以便后续与DeepSeek进行连接。
步骤6:整合RAGFlow与DeepSeek
- 连接RAGFlow与DeepSeek:在RAGFlow的配置界面中,找到“模型提供商”设置项,将DeepSeek的API地址填入RAGFlow中。这样,RAGFlow就可以在检索到相关信息后,调用DeepSeek进行问答生成。
- 调整配置参数:根据实际需求,调整RAGFlow和DeepSeek的配置参数,例如设置检索优先级、调整模型推理速度与质量等。
步骤7:私有知识库创建配置
- 创建知识库:通过RAGFlow的Web界面,输入问题并测试系统的回答是否准确。确保系统能够根据上传的文档和DeepSeek的推理能力给出正确的答案。
- 配置知识库模型:
- 调整RAGFlow中的检索引擎,选择更合适的检索算法。
- 针对DeepSeek进行性能优化,设置合理的硬件资源。
步骤8:测试优化
- 上传文件:向RAGFlow中添加新的文档,扩展知识库的内容。RAGFlow会自动更新向量索引,以确保信息检索的准确性。
- 测试知识库文档:随着数据的积累,可以定期对DeepSeek进行再训练,以提高问答系统的准确性和智能性。你可以看到回答会引用你上传的文件内容。
步骤9:创建Agent
创建一个SQL助手Agent,它类似于一个智能调度员,能够连接外部知识库、API接口,甚至执行自定义任务,让RAG系统更加高效和智能。
实际应用场景案例
企业内部知识管理
某科技公司使用RAGFlow和DeepSeek搭建了企业内部的知识库,将员工的文档、项目资料和常见问题整合在一起。通过智能问答系统,员工可以快速找到所需信息,大大提高了工作效率。
客服智能问答
一家电商企业利用这套系统搭建了客服知识库,将常见问题和解决方案整合进去。客服人员可以通过智能问答快速获取答案,提升客户满意度。
总结
通过以上步骤,我们已经成功搭建了一个基于RAGFlow和DeepSeek的私有知识库。这个系统不仅能够保障数据隐私,还能提升工作效率,并且具备强大的智能问答功能。随着时间的推移,你可以继续扩展知识库、更新模型,打造一个持续进化的智能平台。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 14
14 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)