国产大模型实战:基于DeepSeek+LlamaIndex构建全离线企业级知识库系统
本地知识库的一个可落地实现方案,既可以使用本地DeepSeek,也可以用在线的。
·
视频链接:国产大模型实战:基于DeepSeek+LlamaIndex构建全离线企业级知识库系统_哔哩哔哩_bilibili
LlamaIndex是一个将大语言模型(Large Language Models,LLMs)和外部数据连接在一起的工具,主要用于解决大模型在处理外部知识时的长度限制问题。通过查询和检索的方式,LlamaIndex能够提取和集中最有效的信息,与大模型的输入一起提供给模型,从而让模型获得更多的信息。此外,LlamaIndex还支持多轮对话,不断提纯外部数据,以在有限的输入长度限制下传达更多信息。
前提:本地已安装DeepSeek。
一、安装配置python环境
下载安装python3.9.13,版本一定要用3.9,不可高或低,其他版本兼容性不行,程序会报错。
python3.9.13下载地址
Python Release Python 3.9.13 | Python.org
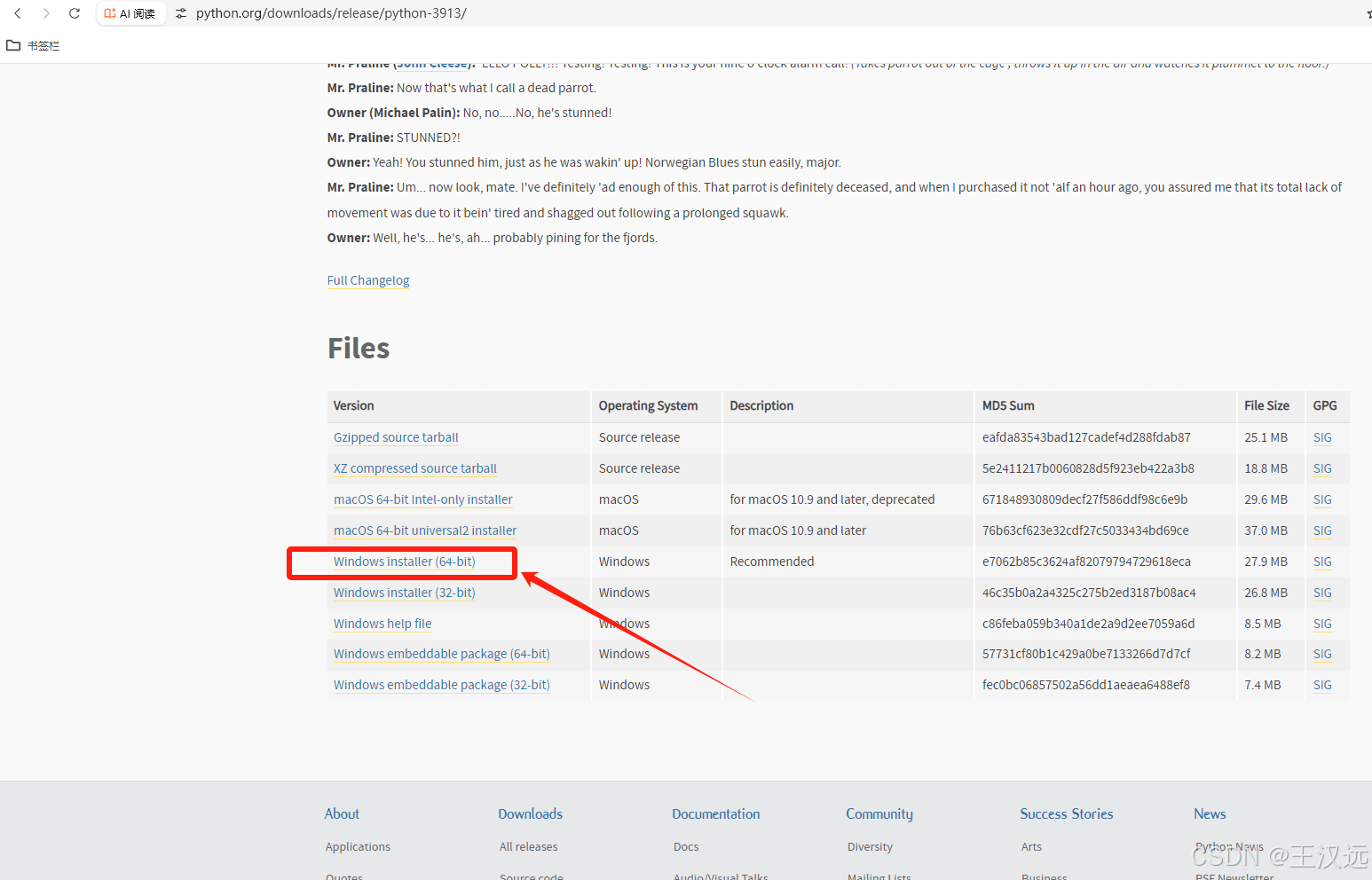
安装python:
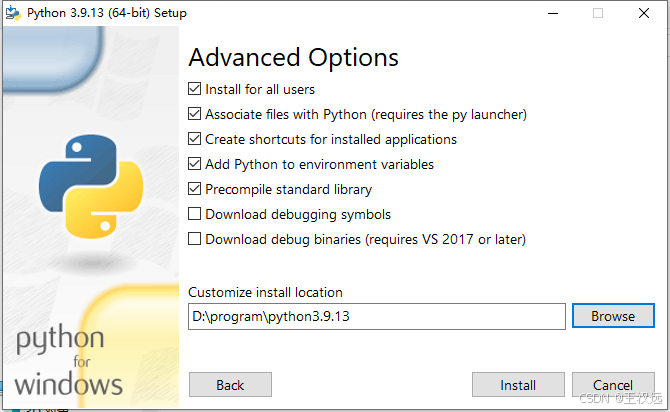
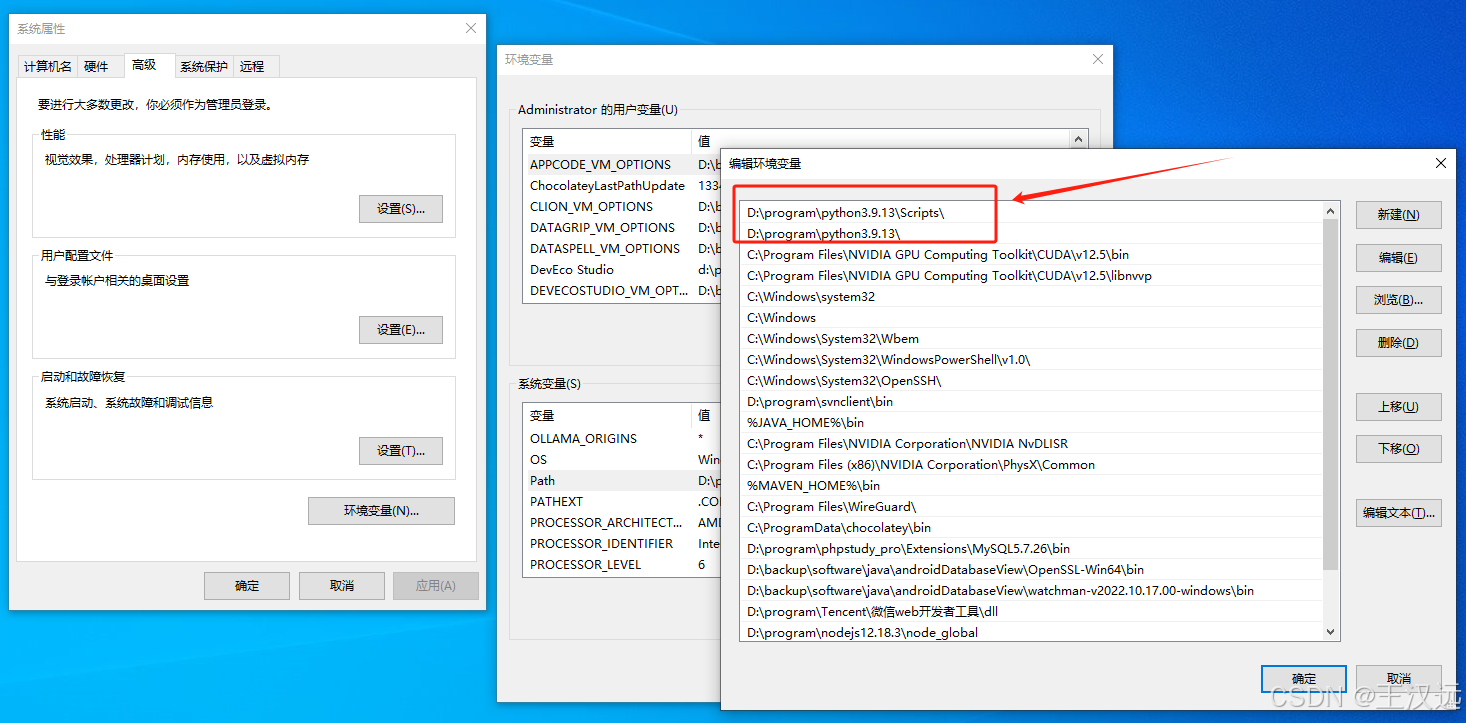
确保环境变量设置的Path:D:\program\python3.9.13\Scripts\;D:\program\python3.9.13\已经有了,如果没有就手动加上,而且必须在其它python变量的上面。
二、配置LlamaIndex连接本地模型
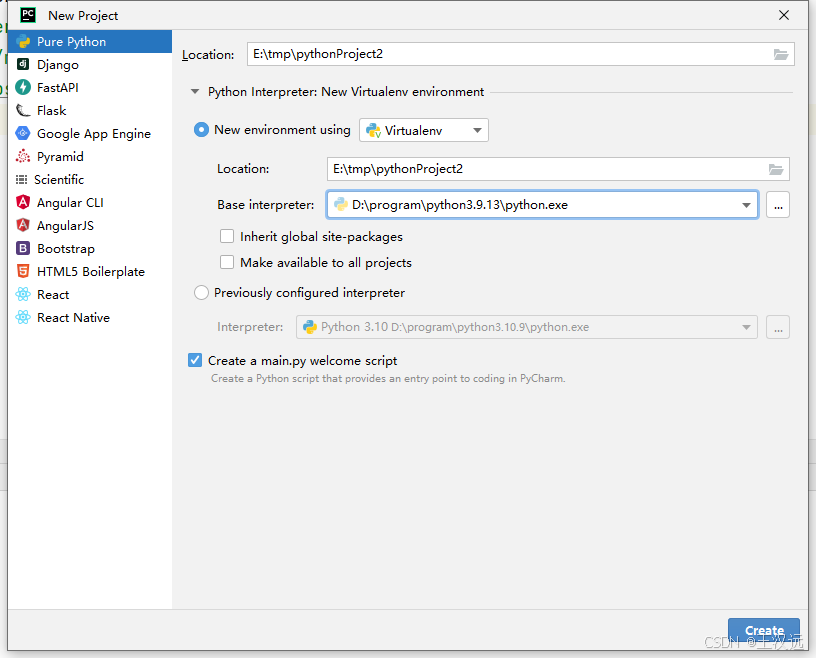
1、新建python项目
2、安装 LlamaIndex 等环境依赖
在 Python 环境中安装 LlamaIndex 和 Ollama 接口库:
# 升级pip到最新版(解决旧版pip的依赖解析问题)
python -m pip install --upgrade pip
# 安装Llama-Index 0.12.x 系列
pip install "llama-index>=0.12.0" "llama-index-llms-ollama>=0.5.2" python-ollama sentence-transformers docx2txt llama-index-embeddings-huggingface ollama 3、调用本地 DeepSeek 模型
from llama_index.llms.ollama import Ollama
# 配置本地 Ollama 服务端点
llm = Ollama(
base_url="http://localhost:11434",
model="deepseek-r1:1.5b", # 与本地部署的模型名称一致
temperature=0.5, # 控制生成结果的随机性
)
# 测试模型响应
response = llm.complete("你好,介绍一下你自己。")
print(response.text)二、搭建知识库
国内镜像下载Embedding模型:
from huggingface_hub import snapshot_download
model_path = snapshot_download(
repo_id="sentence-transformers/all-MiniLM-L6-v2",
local_dir="D:/models/all-MiniLM-L6-v2",
endpoint="https://hf-mirror.com" # 强制指定镜像源
)结合 LlamaIndex 的文档加载和索引功能,可将本地文件(如 PDF、TXT)与 DeepSeek 模型集成:
import os
from llama_index.core import Settings, VectorStoreIndex, SimpleDirectoryReader, StorageContext, load_index_from_storage
from llama_index.llms.ollama import Ollama
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from tenacity import retry, stop_after_attempt, wait_exponential
os.environ["HF_HUB_OFFLINE"] = "1"
# 配置模型
Settings.embed_model = HuggingFaceEmbedding(
model_name="D:/models/all-MiniLM-L6-v2"
)
Settings.llm = Ollama(
base_url="http://localhost:11434",
model="deepseek-r1:1.5b",
temperature=0.5,
request_timeout=300 # 超时时间
)
# 超时重连
@retry(stop=stop_after_attempt(3), wait=wait_exponential(multiplier=1, min=4, max=10))
def safe_query(engine, question):
return engine.query(question)
# 持久化存储索引存储目录
PERSIST_DIR = "D:/ds_emb"
if not os.path.exists(PERSIST_DIR):
# 读取D:/ds/目录下的所有文档
documents = SimpleDirectoryReader("D:/ds/").load_data()
# 构建向量索引
index = VectorStoreIndex.from_documents(documents)
# 持久化向量索引到本地
index.storage_context.persist(persist_dir=PERSIST_DIR)
print("✅ 已创建新索引并持久化存储")
else:
# 从本地获取向量索引
storage_context = StorageContext.from_defaults(persist_dir=PERSIST_DIR)
index = load_index_from_storage(storage_context)
print("✅ 已加载现有索引")
# 增量更新前检查新文档
# if os.path.exists("D:/ds_new/"):
# new_docs = SimpleDirectoryReader("D:/ds_new/").load_data()
# if len(new_docs) > 0:
# index.insert_nodes(new_docs)
# index.storage_context.persist(persist_dir=PERSIST_DIR)
# print("✅ 已更新索引并持久化存储")
query_engine = index.as_query_engine()
try:
answer = safe_query(query_engine, "总结文档中的核心观点。")
print(answer)
except Exception as e:
print(f"查询失败: {str(e)}")
print("建议检查:1. Ollama服务状态 2. 模型是否存在 3. 网络连接")

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)