5分钟看懂Deepseek开源周之五:AI并行训练大杀器3FS----大模型江湖将再兴“血雨腥风”
3FS是一种并行文件系统,其核心优势在于能够充分利用现代固态硬盘(SSD)和远程直接内存访问(RDMA)网络的全部带宽。现代SSD具备高速读写能力,而RDMA网络可以实现远程节点之间的快速数据传输,3FS将二者的优势结合,为数据访问提供高效支持。3FS系统通过硬件性能榨取(SSD+RDMA)、架构创新(分离式设计)和全流程优化(训练-推理协同),系统性解决了大模型训练中的数据与通信瓶颈。
0前言
开源周来到了第五天,经过前四天的公布,相信大家已经提高了心理阈值。深度求索憋了那么久的大招也逐一释放出来,想必会让已经沉寂一时的大模型江湖再起腥风血雨。这种开源的阳谋毫无疑问会推动整个行业往着既定方向前进。2025年的深度求索已是现象级的存在,它身上出现了未来大厂的气质。
开源周的github主贴地址:
deepseek-ai/open-infra-index: Production-tested AI infrastructure tools for efficient AGI development and community-driven innovation https://github.com/deepseek-ai/open-infra-index/tree/main?tab=readme-ov-file
https://github.com/deepseek-ai/open-infra-index/tree/main?tab=readme-ov-file
1开源周第五天推文:
系统描述
3FS是一种并行文件系统,其核心优势在于能够充分利用现代固态硬盘(SSD)和远程直接内存访问(RDMA)网络的全部带宽。现代SSD具备高速读写能力,而RDMA网络可以实现远程节点之间的快速数据传输,3FS将二者的优势结合,为数据访问提供高效支持。
3FS系统通过硬件性能榨取(SSD+RDMA)、架构创新(分离式设计)和全流程优化(训练-推理协同),系统性解决了大模型训练中的数据与通信瓶颈。其技术路径不仅适配当前Transformer架构的演进需求,更为未来万亿参数级模型的训练提供了可扩展的存储基座,有望成为AI基础设施领域的“存储级加速器”,推动全行业模型训练效率与上限的跃升。
性能指标
- 聚合读取吞吐量:
在由180个节点组成的集群环境中,3FS的聚合读取吞吐量达到了6.6 TiB/s。
这意味着系统在大规模集群下能够以极快的速度同时读取数据,反映出其优秀的并行处理能力和数据传输效率,能满足大规模数据读取的需求。 通过并行化设计,聚合180节点的硬件资源,实现6.6 TiB/s的读取吞吐量,相当于每秒传输约82.5万本实体书的数据量。
节点:指集群中的单台服务器或计算单元,通常包含硬件资源(如CPU、内存、存储设备)和网络接口。
集群:由多个节点通过高速网络(如RDMA)互联形成的系统,具备协同处理任务、共享存储资源的能力。
- GraySort基准测试吞吐量:
在25节点集群里,3FS在GraySort基准测试中的吞吐量为3.66 TiB/min。
GraySort是衡量大规模数据集排序性能的行业基准测试,由Sort Benchmark委员会制定,常用于评估分布式系统的数据处理效率。Sort Benchmark Home Page
核心指标:在规定时间内完成数据排序的吞吐量(如TiB/min),同时需保证排序结果的正确性。
- KVCache查找峰值吞吐量:
每个客户端节点的KVCache(键值缓存)查找峰值吞吐量超过40 GiB/s。
KVCache(键值缓存):大语言模型(LLM)推理中的关键技术,用于缓存已生成的键(Key)和值(Value)向量,避免重复计算历史Token。
降低推理延迟:通过缓存历史计算结果,减少自注意力机制中的重复计算,提升实时交互响应速度(如聊天机器人)。
节省内存资源:替代传统DRAM缓存方案,利用SSD存储提供更大容量且成本更低。
3FS:Fire-Flyer File System将会如何改变AI行业?
3FS系统针对当前大模型训练中面临的分布式数据读取效率低、节点通信瓶颈、存储与计算资源不匹配等核心问题,通过技术创新实现了关键突破。以下是其具体解决方案及对行业训练的促进作用:
一、解决数据读取瓶颈:突破存储性能天花板
- 分布式并行读取优化
现行大模型训练中,数据加载速度受限于存储系统的聚合带宽。3FS通过结合NVMe SSD的高IOPS(每秒输入输出操作数)和RDMA网络的低延迟特性,在180节点集群中实现了6.6 TiB/s的聚合读取吞吐量,远超传统分布式文件系统(如HDFS或Ceph)。这种能力可支撑千卡级训练集群的实时数据供给,避免GPU因等待数据而闲置。
- 小文件与多模态数据处理
在多模态训练场景(如图文对、视频-文本数据)中,海量小文件的元数据操作成为性能瓶颈。3FS通过分离式架构将元数据管理与数据存储解耦,通过链式复制(CRAQ)实现元数据强一致性,同时优化小文件合并读取策略,减少随机I/O开销。例如,在文本-图像混合训练中,可将图文对数据预打包为块存储,提升加载效率。
二、优化节点通信:降低分布式训练延迟
- RDMA网络深度集成
传统训练集群中,跨节点数据同步依赖TCP/IP协议栈,通信延迟高且占用CPU资源。3FS通过RDMA网络直接访问存储节点内存,绕过操作系统内核,将数据传输延迟降低至微秒级。例如,在参数服务器架构中,梯度聚合可通过RDMA直接写入3FS存储层,减少30%以上的通信时间。
- Checkpoint并行化与快速恢复
大模型训练需频繁保存检查点(Checkpoint),传统系统因单点写入易形成性能瓶颈。3FS支持多节点并行写入检查点,结合其高写入带宽(如25节点集群3.66 TiB/min的GraySort吞吐量),可将检查点保存时间缩短60%以上。同时,基于强一致性语义的快速恢复机制,能在大规模训练中断后快速重建训练状态。
三、端到端全流程优化:覆盖训练-推理全生命周期
- 训练数据预处理加速
3FS支持内存级缓存的数据预处理流水线,例如将原始数据转换为FFRecord格式时,可直接在存储层完成数据分片、压缩和加密,避免预处理与训练任务争抢计算资源。
- 推理阶段KVCache优化
针对大语言模型推理中的键值缓存(KVCache)需求,3FS提供超40 GiB/s的单节点缓存吞吐量,通过SSD-RDMA联合加速,将长文本推理的上下文加载时间从秒级降至毫秒级,支撑实时交互场景。
四、对行业训练的全局提升价值
- 降低算力资源浪费
通过存储性能与训练任务的动态匹配,3FS可将GPU利用率提升20%-40%,尤其适用于长序列训练(如代码生成模型)中的高并发数据访问场景。
- 推动多中心协同训练
结合多云架构,3FS支持跨数据中心的数据按需跟随算力流转,例如将冷数据存储于低成本对象存储,热数据动态迁移至高性能集群,解决单一数据中心算力不足问题。
- 标准化数据管理范式
通过统一的存储接口(POSIX/S3)和全生命周期管理能力,3FS可简化从数据采集、清洗到训练/推理的流程,降低企业构建AI基础设施的技术门槛。
2.Fire-Flyer File System (3FS)
Fire-Flyer File System (3FS) 是专为应对AI训练和推理工作负载挑战而设计的高性能分布式文件系统。它利用现代SSD和RDMA网络提供共享存储层,简化分布式应用程序的开发。以下是3FS的主要特性与优势:
性能与可用性
- 分离式架构:结合数千块SSD的吞吐量和数百个存储节点的网络带宽,使应用程序能够以位置无关的方式访问存储资源。
- 强一致性:通过**链式复制与分配查询(CRAQ)**实现强一致性,使应用程序代码更简单且易于理解。
- 文件接口:开发由事务性键值存储(如FoundationDB)支持的无状态元数据服务。文件接口是通用且广泛使用的,无需学习新的存储API。
多样化工作负载
- 数据准备:将数据分析管道的输出组织为层次化目录结构,并高效管理大量中间结果。
- 数据加载器:通过支持计算节点之间的训练样本随机访问,消除预取或打乱数据集的需求。
- 检查点保存:支持大规模训练的高吞吐并行检查点保存。
- 推理KVCache:提供比基于DRAM的缓存更具成本效益的替代方案,同时提供高吞吐量和更大容量。
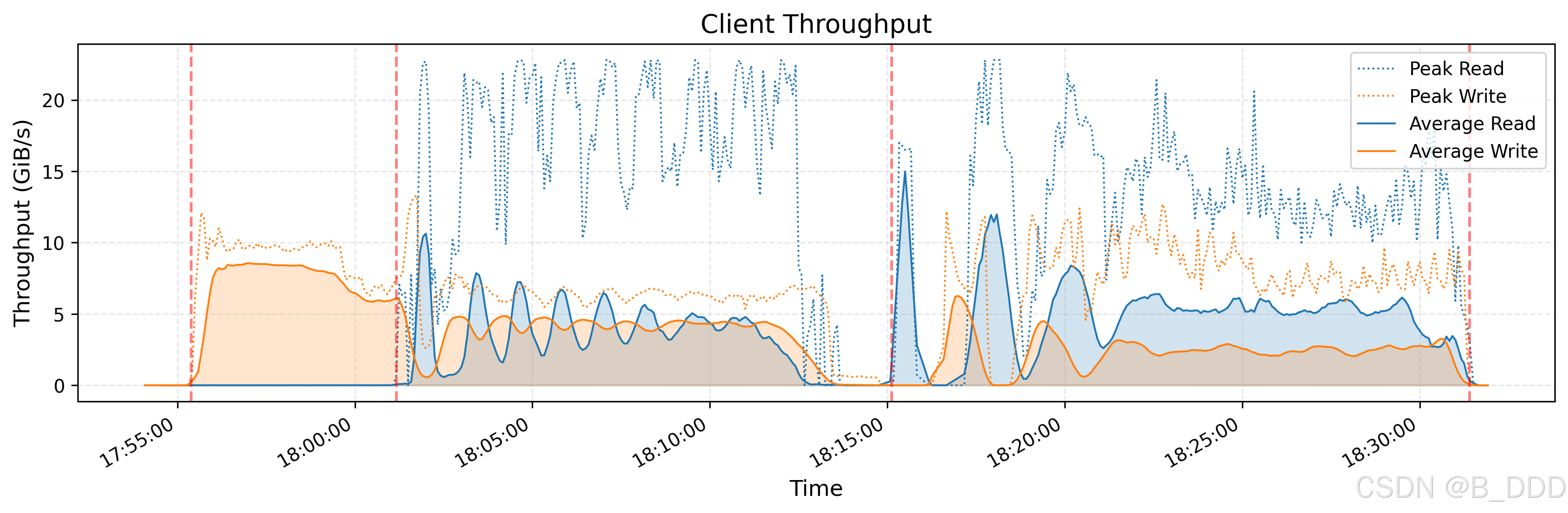
1.峰值吞吐量
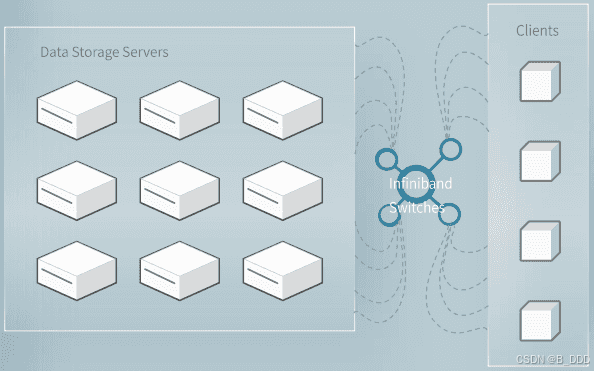
下图演示了大型 3FS 集群上读取压力测试的吞吐量。该集群由 180 个存储节点组成,每个节点配备 2×200Gbps InfiniBand 网卡和 16 个 14TiB NVMe SSD。大约使用了 500+ 个客户端节点进行读取压力测试,每个客户端节点配置了 1 个 200Gbps InfiniBand 网卡。最终的聚合读取吞吐量达到大约 6.6 TiB/s,后台流量来自训练作业。
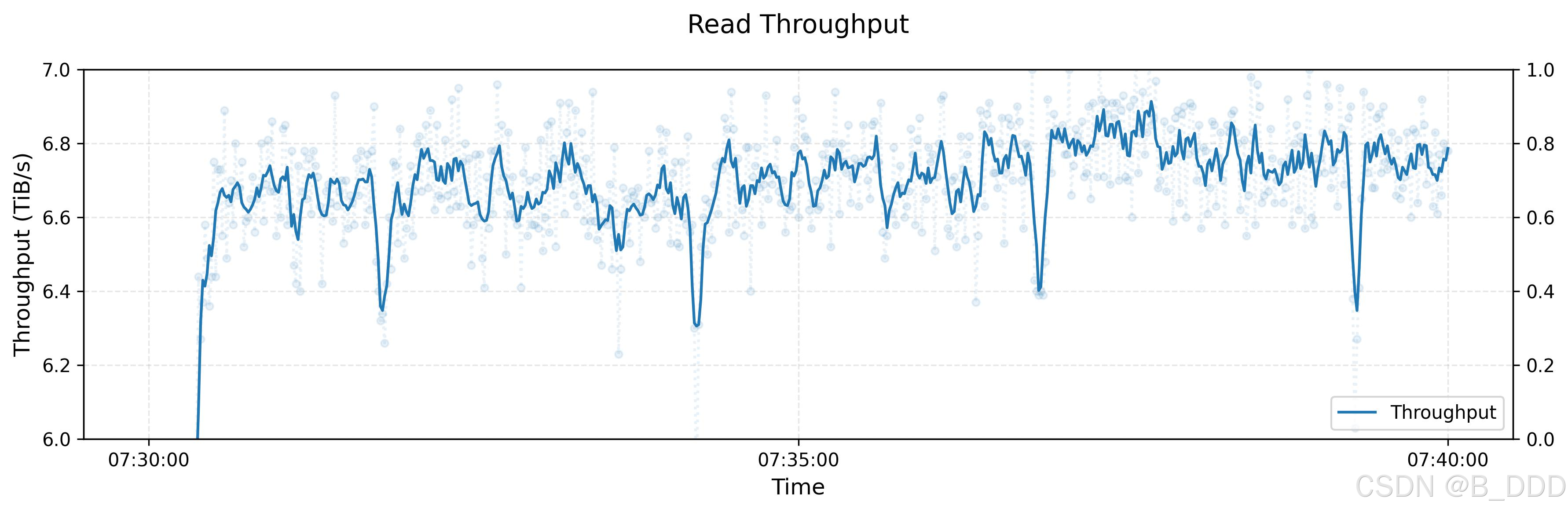
图表描述:
- 标题:读取吞吐量
- X轴:时间,从大约07:30:00到07:40:00。
- Y轴:吞吐量,单位为TiB/s(Tebibytes per second),范围从6.0 TiB/s到7.0 TiB/s。
关键点:
集群配置:
- 集群由180个存储节点组成。
- 每个存储节点配备2×200Gbps InfiniBand NIC和十六个14TiB NVMe SSD。
- 大约500多个客户端节点用于读取压力测试,每个客户端节点配置有1x200Gbps InfiniBand NIC。
吞吐量性能:
- 最终聚合读取吞吐量达到约6.6 TiB/s,背景流量来自训练任务。
- 图表显示了10分钟内的吞吐量波动。
- 有一些明显的吞吐量下降,可能是由于网络拥塞、系统负载或其他背景活动引起的。
详细分析:
- 初始阶段(07:30:00 - 07:32:00):吞吐量迅速从约6.0 TiB/s增加到接近6.6 TiB/s。
- 稳定阶段(07:32:00 - 07:40:00):吞吐量围绕6.6 TiB/s波动,有些变化。峰值和低谷分别表示高和低性能的时期。
- 吞吐量下降:在07:33:00、07:36:00和07:39:00左右有明显的吞吐量下降。这些下降可能是由于背景流量或系统活动引起的。
结论:
该图表展示了大型3FS集群在压力测试条件下的读取吞吐量性能。尽管存在一些波动,但系统仍能保持较高的吞吐量,显示出其处理大量读取负载的能力,即使在有背景流量的情况下也是如此。偶尔的下降表明可能需要进一步优化以确保更一致的性能。
2. GraySort基准测试
我们使用 GraySort 基准测试来评估 smallpond,该基准测试衡量大规模数据集的排序性能。我们的实现采用两阶段方法:(1) 使用 key 的前缀位通过 shuffle 对数据进行分区,以及 (2) 分区内排序。两个阶段都从 3FS 读/写数据。
测试集群包括 25 个存储节点(2 个 NUMA 域/节点、1 个存储服务/NUMA、2×400Gbps NIC/节点)和 50 个计算节点(2 个 NUMA 域、192 个物理内核、2.2 TiB RAM 和 1×200 Gbps NIC/节点)。在 30 分 14 秒内完成 8192 个分区的 110.5 TiB 数据排序,平均吞吐量达到 3.66 TiB/min。
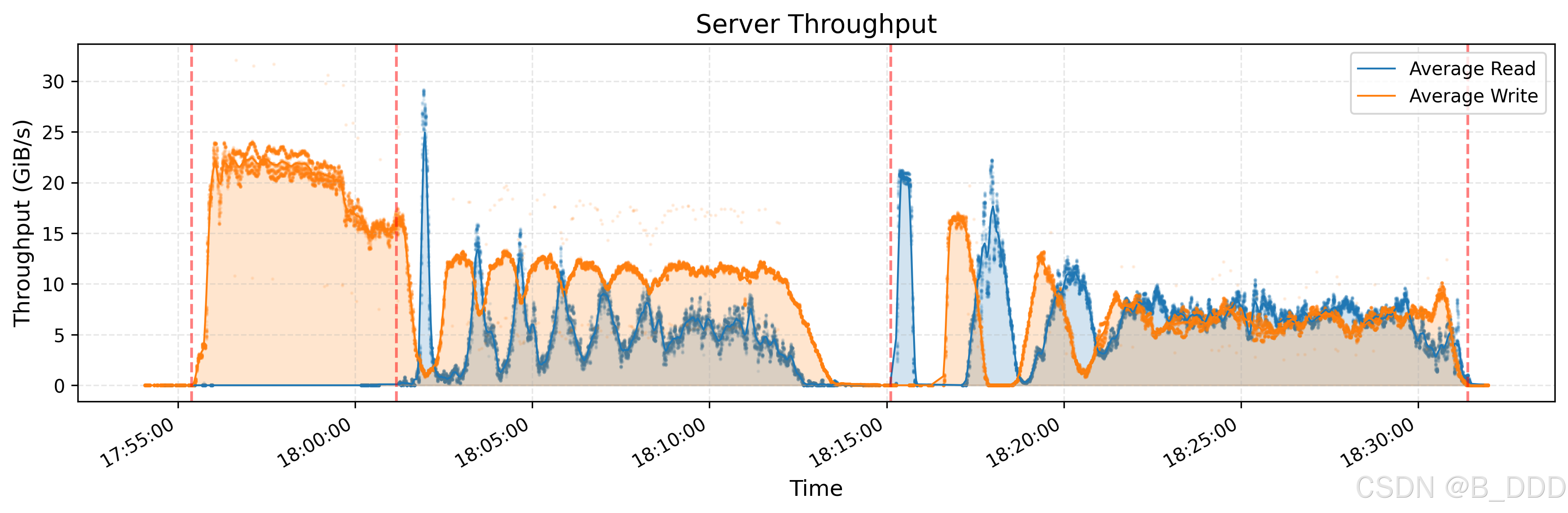
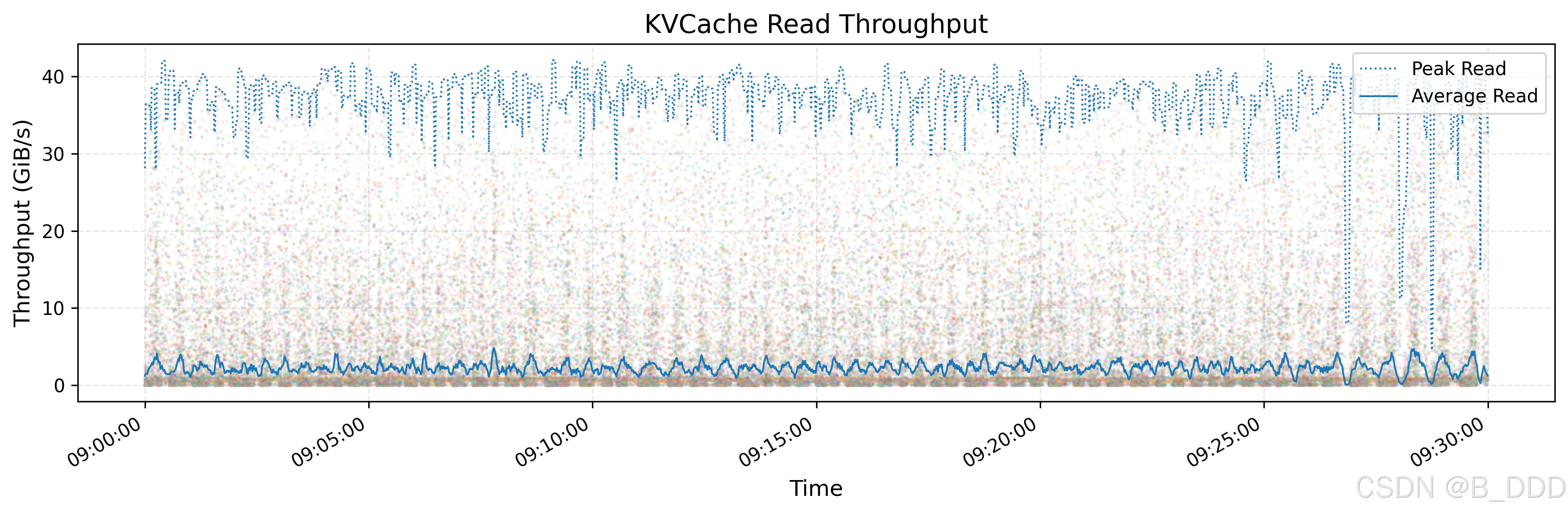
3. KVCache
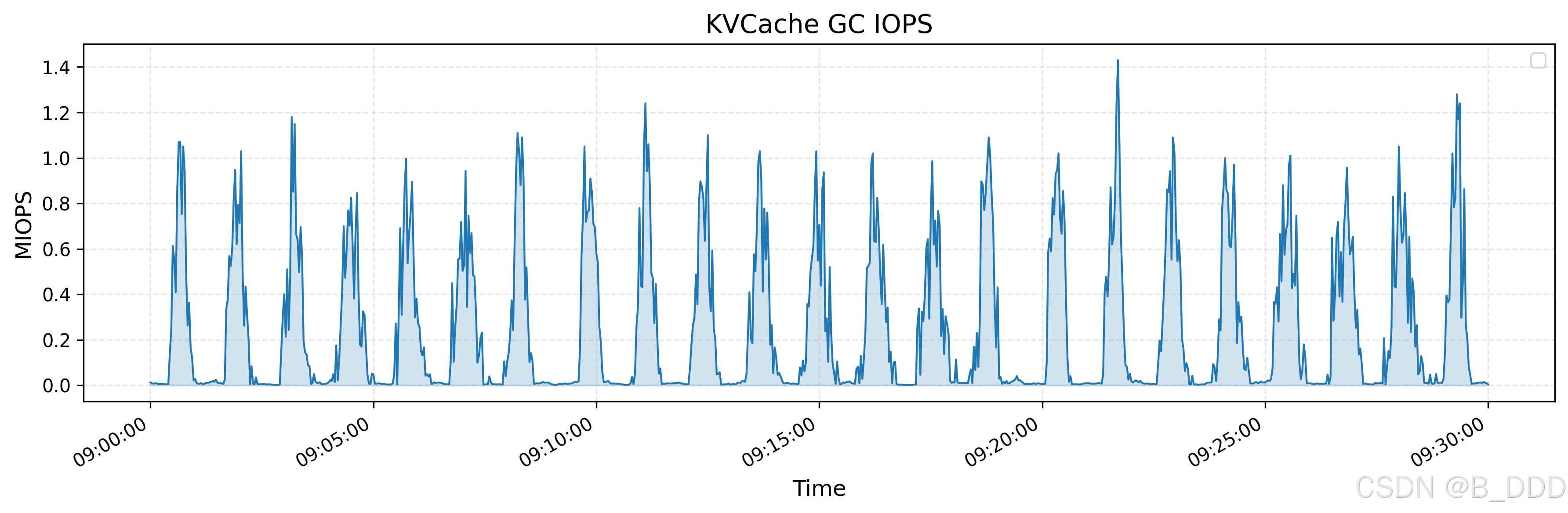
KVCache 是一种用于优化 LLM 推理过程的技术。它通过在解码器层中缓存先前标记的键和值向量来避免冗余计算。 上图显示了所有 KVCache 客户端的读取吞吐量,突出显示了峰值和平均值,峰值吞吐量高达 40 GiB/s。下图显示了同一时间段内从垃圾回收 (GC) 中删除作的 IOPS。
官方安装指引
3FS/deploy/README.md at main · B3DDD/3FS![]() https://github.com/B3DDD/3FS/blob/main/deploy/README.md
https://github.com/B3DDD/3FS/blob/main/deploy/README.md
本节提供了使用 cluster ID 设置六节点集群的手动部署指南。
硬件规格
| Node | OS | IP | Memory | SSD | RDMA |
|---|---|---|---|---|---|
| meta | Ubuntu 22.04 | 192.168.1.1 | 128GB | - | RoCE |
| storage1 | Ubuntu 22.04 | 192.168.1.2 | 512GB | 14TB × 16 | RoCE |
| storage2 | Ubuntu 22.04 | 192.168.1.3 | 512GB | 14TB × 16 | RoCE |
| storage3 | Ubuntu 22.04 | 192.168.1.4 | 512GB | 14TB × 16 | RoCE |
| storage4 | Ubuntu 22.04 | 192.168.1.5 | 512GB | 14TB × 16 | RoCE |
| storage5 | Ubuntu 22.04 | 192.168.1.6 | 512GB | 14TB × 16 | RoCE |
RDMA 配置
- 为 RDMA 网卡分配 IP 地址。每个节点都支持多个 RDMA 网卡(InfiniBand 或 RoCE)。
- 使用 检查节点之间的 RDMA 连接。
ib_write_bw.
第三方依赖
在生产环境中,建议在专用节点上安装 FoundationDB 和 ClickHouse。
| Service | Node |
|---|---|
| ClickHouse | meta |
| FoundationDB | meta |
基础数据库
- 确保 FoundationDB 客户端的版本与服务器版本匹配,或者复制相应的版本以保持兼容性。
libfdb_c.so- 在安装了 FoundationDB 的节点上找到该文件和 。
fdb.clusterlibfdb_c.so/etc/foundationdb/fdb.cluster/usr/lib/libfdb_c.so
设计说明解读:
3FS/docs/design_notes.md 位于 main ·B3DDD/3FS 型![]() https://github.com/B3DDD/3FS/blob/main/docs/design_notes.md 3FS系统由四个组件组成:集群管理器、元数据服务、存储服务和客户端。所有组件都连接在一个远程直接内存访问(RDMA)网络(如InfiniBand或RoCE)中。
https://github.com/B3DDD/3FS/blob/main/docs/design_notes.md 3FS系统由四个组件组成:集群管理器、元数据服务、存储服务和客户端。所有组件都连接在一个远程直接内存访问(RDMA)网络(如InfiniBand或RoCE)中。
元数据服务和存储服务会向集群管理器发送心跳信号。集群管理器处理成员变更,并将集群配置分发给其他服务和客户端。系统会部署多个集群管理器,其中一个会被选为主要管理器。当主要管理器出现故障时,会有另一个管理器被提升为主要管理器。集群配置通常存储在可靠的分布式协调服务中,如ZooKeeper或etcd。
在我们的生产环境中,我们使用与文件元数据相同的键值存储来减少依赖。 文件元数据操作(如打开或创建文件/目录)会被发送到实现文件系统语义的元数据服务。元数据服务是无状态的,因为文件元数据存储在事务性键值存储(如FoundationDB)中。
客户端可以连接到任何元数据服务。 每个存储服务管理几个本地固态硬盘(SSD),并提供一个数据块存储接口。存储服务实现了带分配查询的链式复制(CRAQ),以确保强一致性。
CRAQ的全写单读方法有助于释放SSD和RDMA网络的吞吐量。一个3FS文件会被分割成大小相等的数据块,这些数据块会在多个SSD上进行复制。 我们为应用程序开发了两种客户端:FUSE客户端和原生客户端。大多数应用程序使用FUSE客户端,因为其采用门槛较低。对性能要求较高的应用程序则集成原生客户端。
3Smallpond
特征
- 🚀 由 DuckDB 提供支持的高性能数据处理
- 🌍 可扩展以处理 PB 级数据集
- 🛠️作简单,无需长时间运行的服务
Python3.8-3.12
pip install smallpond快速安装
# Download example data
wget https://duckdb.org/data/prices.parquetimport smallpond
# Initialize session
sp = smallpond.init()
# Load data
df = sp.read_parquet("prices.parquet")
# Process data
df = df.repartition(3, hash_by="ticker")
df = sp.partial_sql("SELECT ticker, min(price), max(price) FROM {0} GROUP BY ticker", df)
# Save results
df.write_parquet("output/")
# Show results
print(df.to_pandas())我们使用 GraySort 基准测试(脚本)在包含 50 个计算节点和 25 个运行 3FS 的存储节点的集群上评估了 smallpond。基准测试在 30 分 14 秒内对 110.5TiB 数据进行排序,平均吞吐量为 3.66TiB/min。
详细信息可以在 3FS - 灰度排序中找到。
DuckDB 是一款轻量级、高性能的 嵌入式分析型数据库,专为 OLAP(联机分析处理)场景设计,以其高效的数据处理能力和易用性在数据科学和嵌入式领域广受关注。以下是其核心特性及使用场景的详细介绍:
一、核心特性
嵌入式架构
DuckDB 采用进程内数据库设计,无需独立服务进程,可直接嵌入到应用程序中。例如,在 Python 或 R 中通过简单导入库即可使用,类似 SQLite 但针对分析优化。列式存储与压缩
数据按列存储,结合轻量级压缩算法(如字典编码、位压缩),显著降低存储空间需求并提升查询效率,适合大规模数据分析。高性能与低延迟
优化执行引擎支持向量化查询和并行处理,内存优先设计减少磁盘 I/O,适用于交互式分析与实时数据处理。完整 SQL 支持
兼容标准 SQL 语法,支持复杂查询、事务(ACID)、窗口函数等,可直接迁移现有 SQL 代码。多语言集成
提供 Python、R、Java 等 API,无缝集成到数据科学工具链(如 Pandas、Jupyter)。二、适用场景
交互式数据分析
适用于快速探索性分析(EDA)、数据可视化及实时报表生成,尤其在单机环境下处理 GB 到 TB 级数据。嵌入式应用开发
可嵌入 IoT 设备或移动应用,实现本地数据存储与分析,无需依赖远程数据库服务。轻量级数据仓库
支持 ETL 流程,整合多源数据(CSV、Parquet、JSON 等),并提供高效查询能力。数据科学工作流
与 Python/R 深度集成,替代传统文件读取,直接通过 SQL 加速数据预处理和特征工程。三、技术架构亮点
执行引擎:采用 Push-based 流水线模型,优化查询并行度。
存储设计:数据分块存储,每块包含列的最小/最大值索引,加速过滤扫描。
事务管理:基于 MVCC 实现可串行化隔离,支持并发读写。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 34
34 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)