
Spring AI应用:利用DeepSeek+嵌入模型+Milvus向量数据库实现检索增强生成--RAG应用(二)(超详细)
在本篇文章中,我们深入探讨了如何利用 Spring AI 和 Milvus 向量数据库 实现检索增强生成(RAG)应用。通过结合 Apache Tika 进行多格式文档解析、HanLP 和 LangChain4J 进行文本分片,以及 Spring AI 的 Advisors API 进行上下文增强,我们成功构建了一个能够从知识库中检索相关信息并生成准确回答的智能问答系统
目录
继上篇我们了解了向量数据库Milvus的基本知识(上篇地址:Spring AI应用:利用DeepSeek+嵌入模型+Milvus向量数据库实现检索增强生成--RAG应用(一)(超详细)-CSDN博客),本期将继续学习基于向量数据库如何实现检索增强生成。
那么在有了向量数据库后,我们现在需要做的就是将知识库相关文档内容解析,然后使用相关工具将文档内容分割,并转换成向量表示存储在Milvus中。
一、文件内容解析
在Java中,文件内容解析可以通过多种方式实现,具体取决于文件的格式和解析需求。如果我们要搭建知识库,文档的类型肯定是多样化的。那么有没有什么工具可以不考虑文档类型,又可以实现我们的需求呢?答案就是Apache Tika。
1、Apache Tika介绍
简介:
- 开发语言:Java
- 官方网站:Apache Tika
- 特点:Tika 是一个强大的内容分析工具包,支持从超过1000种文件类型中提取文本、元数据和其他结构化数据。它能够处理多种格式的文档,包括但不限于PDF、Word、Excel、PPT等。
- 使用场景:适用于需要处理多种不同格式文档的大规模信息抽取任务。
主要特性:
- 支持广泛的文档格式解析。
- 提供了丰富的元数据提取能力。
- 可以通过命令行或编程接口(如Java API)调用。
- 内置自然语言检测功能。
- 支持OCR(通过集成外部服务如Tesseract)来处理图像中的文字。
优点:
- 强大的多格式支持,几乎可以处理任何类型的文档。
- 易于与大数据生态系统集成(例如Hadoop)。
- 活跃的社区支持和持续更新。
缺点:
- 对于某些特定格式(如PDF),可能不如专用工具精确。
- 性能上可能不是最优,特别是在处理大量小文件时。
2、Apache Tika实践
接下来我们将学习如何在Spring Boot里使用Apache Tika解析文件内容,首先在pom.xml里引入相关依赖
<!-- Tika依赖 文件内容提取 -->
<dependency>
<groupId>org.apache.tika</groupId>
<artifactId>tika-core</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.tika</groupId>
<artifactId>tika-parsers-standard-package</artifactId>
<version>3.0.0</version>
</dependency>然后新建一个TikaUtil的服务类,编写一个文件解析的方法,代码如下:
package com.wanganui.tika;
import com.alibaba.fastjson.JSON;
import dev.langchain4j.data.document.Document;
import dev.langchain4j.data.document.DocumentSplitter;
import dev.langchain4j.data.document.splitter.DocumentSplitters;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.model.openai.OpenAiTokenizer;
import lombok.RequiredArgsConstructor;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.AutoDetectParser;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.Parser;
import org.apache.tika.sax.BodyContentHandler;
import org.springframework.stereotype.Component;
import org.springframework.web.multipart.MultipartFile;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
/**
* @author xtwang
* @des 文件内容提取工具
* @date 2025/2/25 下午4:57
*/
@Component
@RequiredArgsConstructor
public class TikaUtil {
public String extractTextString(MultipartFile file) {
try {
// 创建解析器--在不确定文档类型时候可以选择使用AutoDetectParser可以自动检测一个最合适的解析器
Parser parser = new AutoDetectParser();
// 用于捕获文档提取的文本内容。-1 参数表示使用无限缓冲区,解析到的内容通过此hander获取
BodyContentHandler bodyContentHandler = new BodyContentHandler(-1);
// 元数据对象,它在解析器中传递元数据属性---可以获取文档属性
Metadata metadata = new Metadata();
// 带有上下文相关信息的ParseContext实例,用于自定义解析过程。
ParseContext parseContext = new ParseContext();
parser.parse(file.getInputStream(), bodyContentHandler, metadata, parseContext);
// 获取文本
return bodyContentHandler.toString();
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
}完成后在MilvusController里添加一个控制器,用于文件上传解析
@Operation(summary = "解析文件内容")
@PostMapping("/extractFileString")
public ResponseEntity<String> extractFileString(MultipartFile file) {
return ResponseEntity.ok(tikaUtil.extractTextString(file));
}运行程序,访问swagger,选择一个文档测试解析功能
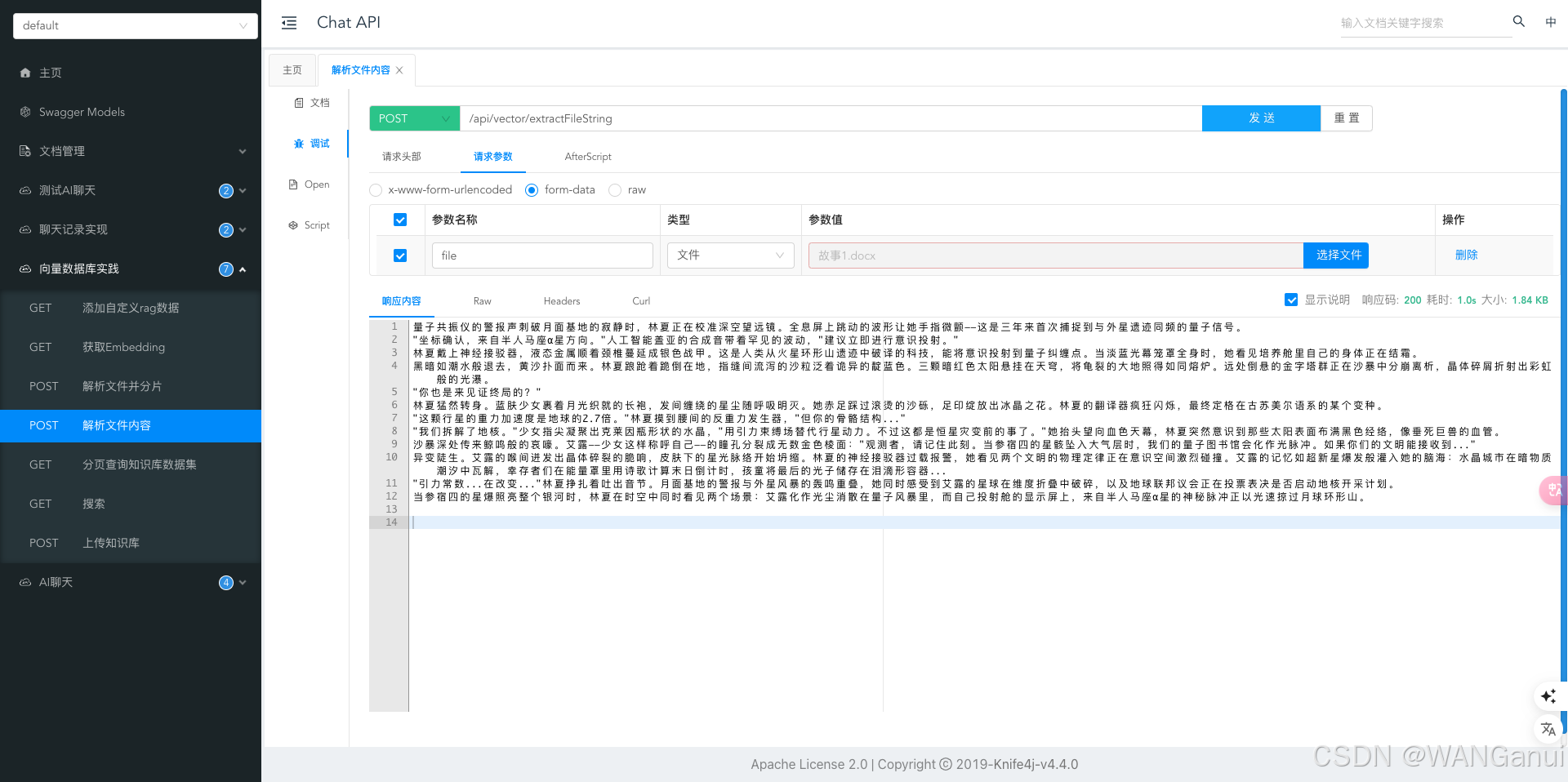
可以看到程序已成功解析出了word文档里的内容,接下来再试试其他文件格式
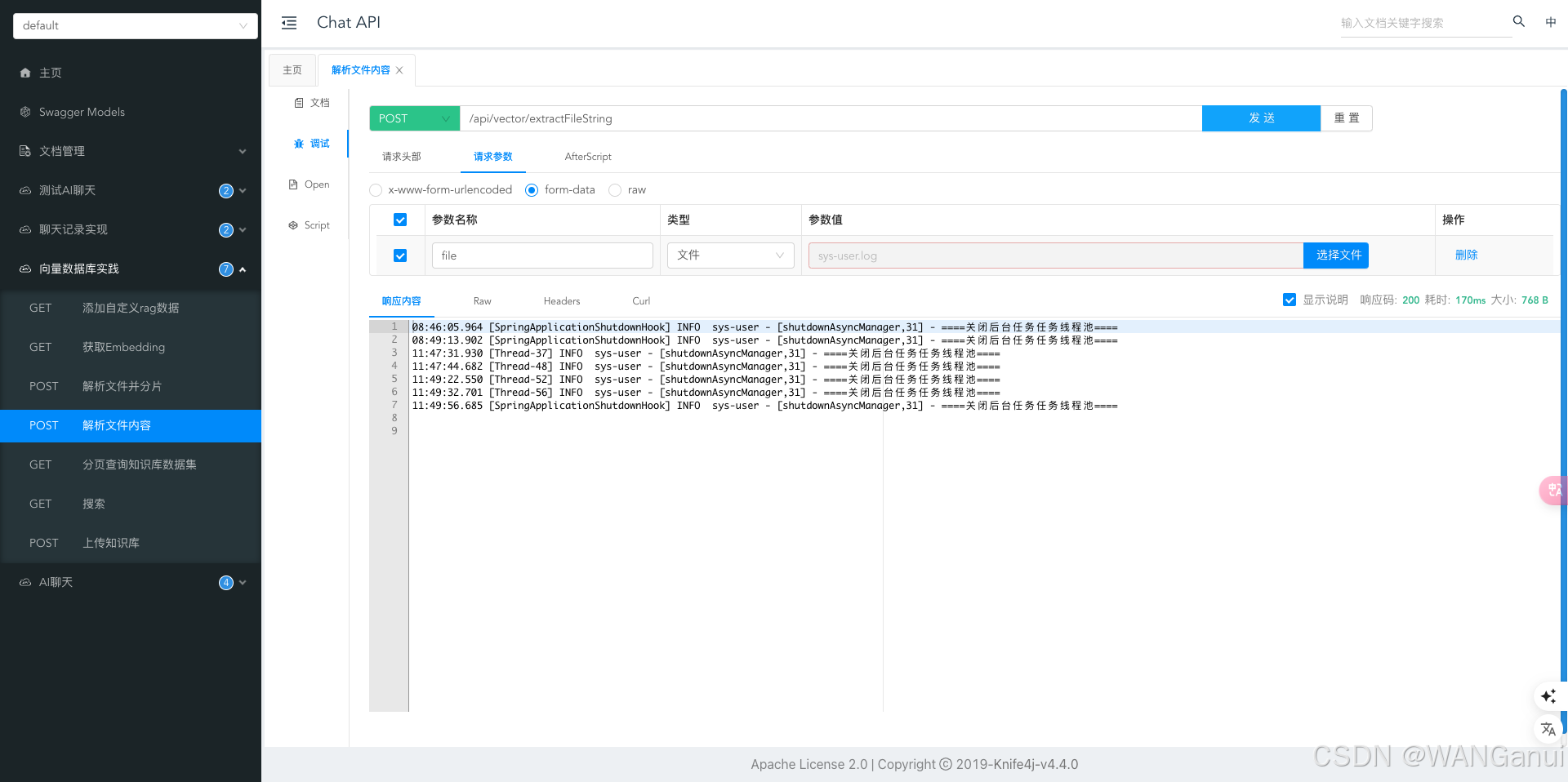 如上图我们的程序日志文件也可以解析。
如上图我们的程序日志文件也可以解析。
通过以上步骤可以基本实现不同文档类型的内容解析。但现在的问题是,一般的企业里相关文档内容都是比较多的。如果我们将解析出来的文本一股脑全往模型里塞,可能会导致上下文过长,达不到我们想要的效果。
为了解决这种情况,我们需要将文本分片,把内容切割成一个一个的文本块,再将文本块转换为向量表示存入向量数据库,这样大模型在检索的时候只需要将相关的文本块添加到上下文中,既能保证回答的准确性,也解决了上下文过长的问题。
二、文本分片(切割)
那么如何将过长的文本内容分割成文本块,又要保证每块内容的语义完整,这就需要用到自然语言处理(NLP)技术,可以考虑使用以下几种方法和技术:
1. 使用分词库
-
Stanford NLP: 提供了丰富的工具集用于处理各种自然语言处理任务,包括中文分词、命名实体识别等。可以利用其提供的Java API进行文本分割。
-
Jieba分词: 虽然Jieba最初是为Python设计的,但也有Java版本可用(如jieba-analysis)。它支持精确模式、全模式等多种分词模式,并且能够通过自定义词典来提高分词准确性。
-
HanLP: HanLP是一个高效的中文处理工具包,支持多种语言和功能,包括分词、词性标注、命名实体识别等。HanLP提供了Java接口,非常适合需要对中文文本进行处理的场景。
2. 基于机器学习的方法
-
CRF (条件随机场): CRF是一种序列标注模型,广泛应用于分词、词性标注等领域。可以通过训练特定领域的数据集来提高分词准确性。
-
深度学习框架: 如TensorFlow、PyTorch等虽然主要以Python为主,但也可以通过调用它们的Java API或者通过RESTful服务的方式与Java程序集成,使用预训练的语言模型(例如BERT)来进行更复杂的文本分析任务,包括基于上下文感知的分词。
3. 基于LangChain的文本分割工具
-
LangChain4J是一个用于开发语言模型应用的框架,Spring AI的直接竞争对手,它提供了多种工具和组件来处理文本数据,包括文档分割(Document Splitters)。文档分割器(DocumentSplitters)的主要目的是将大型文档分割成更小的块或片段,以便更有效地处理或分析。这些分割策略对于确保文本块适合于特定的语言模型输入限制(如最大token长度)非常重要。
那么在Java开发中,对于像Stanford NLP、HanLP这样的库,可以直接添加依赖项到你的pom.xml中,这样我们开发起来可以避开Python调用的繁杂过程。
3、集成HanLP和LangChain4J
接下来我们将使用HanLP分词库和LangChain4J两种方式来做一个文本分割的对比。
HanLP分词库还提供了语义分析、文本摘要、文本分类、情感分析等多种功能,感兴趣的同学可以查看官方文档:HanLP | 在线演示
在pom.xml里添加相关依赖
<!-- LangChain4J依赖 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai</artifactId>
<version>0.31.0</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>0.31.0</version>
</dependency>
<!-- HanLP中文分词 -->
<dependency>
<groupId>com.hankcs</groupId>
<artifactId>hanlp</artifactId>
<version>portable-1.8.6</version>
</dependency>在TikaUtil里增加对应的分词方法,代码如下
// 目标段落长度(汉字字符数)
private static final int TARGET_LENGTH = 200;
// 允许的段落长度浮动范围(±20字)
private static final int LENGTH_TOLERANCE = 20;
/**
* 使用langchain4j的分段工具
*
* @param content 输入的大文本
* @return 段落列表,每个段落至少包含minLength个字符
*/
public List<String> splitParagraphsLangChain(String content) {
DocumentSplitter splitter = DocumentSplitters.recursive(TARGET_LENGTH, LENGTH_TOLERANCE, new OpenAiTokenizer());
List<TextSegment> split = splitter.split(Document.document(content));
return split.stream().map(TextSegment::text).toList();
}
/**
* 使用HanLP进行句子分割
*
* @param text 输入的大文本
* @return 段落列表,每个段落至少包含minLength个字符
*/
public static List<String> splitParagraphsHanLP(String text) {
List<String> paragraphs = new ArrayList<>();
if (text == null || text.isEmpty()) {
return paragraphs;
}
// 1. 使用 HanLP 分词并分句
List<String> sentences = splitSentences(text);
// 2. 动态合并句子到段落
paragraphs = mergeSentencesIntoParagraphs(sentences);
return paragraphs;
}
// 使用 HanLP 分词实现分句
private static List<String> splitSentences(String text) {
List<String> sentences = new ArrayList<>();
StringBuilder currentSentence = new StringBuilder();
List<Term> terms = HanLP.segment(text);
for (Term term : terms) {
currentSentence.append(term.word);
// 使用正则表达式匹配句子结束标点(支持中英文标点)
if (term.word.matches("[。!?;.!?;]+")) {
sentences.add(currentSentence.toString());
currentSentence.setLength(0);
}
}
// 添加最后一个句子(如果没有标点结尾)
if (!currentSentence.isEmpty()) {
sentences.add(currentSentence.toString());
}
return sentences;
}
// 动态合并句子到段落
private static List<String> mergeSentencesIntoParagraphs(List<String> sentences) {
List<String> paragraphs = new ArrayList<>();
StringBuilder currentParagraph = new StringBuilder();
int currentLength = 0;
for (String sentence : sentences) {
int sentenceLength = countChineseChars(sentence);
// 处理超长句子(强制分割)
if (sentenceLength > TARGET_LENGTH + LENGTH_TOLERANCE) {
if (currentLength > 0) {
paragraphs.add(currentParagraph.toString());
currentParagraph.setLength(0);
currentLength = 0;
}
// 按标点二次分割超长句
List<String> subSentences = splitLongSentence(sentence);
paragraphs.addAll(subSentences);
continue;
}
// 合并到当前段落的条件
if (currentLength + sentenceLength <= TARGET_LENGTH + LENGTH_TOLERANCE) {
currentParagraph.append(sentence);
currentLength += sentenceLength;
} else {
// 当前段落达到长度,保存并重置
paragraphs.add(currentParagraph.toString());
currentParagraph.setLength(0);
currentParagraph.append(sentence);
currentLength = sentenceLength;
}
}
// 添加最后一个段落
if (currentLength > 0) {
paragraphs.add(currentParagraph.toString());
}
return paragraphs;
}
// 处理超长句子:按逗号、分号等二次分割
private static List<String> splitLongSentence(String sentence) {
List<String> validParts = new ArrayList<>();
StringBuilder current = new StringBuilder();
int currentLength = 0;
// 按标点分割句子
String[] parts = sentence.split("[,;;,]");
for (String part : parts) {
int partLength = countChineseChars(part);
if (currentLength + partLength > TARGET_LENGTH + LENGTH_TOLERANCE) {
// 当前部分过长,保存并重置
validParts.add(current.toString());
current.setLength(0);
currentLength = 0;
}
// 补回分割符号
current.append(part).append(",");
currentLength += partLength;
}
// 添加最后一个部分
if (!current.isEmpty()) {
validParts.add(current.toString());
}
return validParts;
}
// 统计中文字符数(忽略标点、英文)
private static int countChineseChars(String text) {
return (int) text.chars()
.filter(c -> Character.UnicodeScript.of(c) == Character.UnicodeScript.HAN)
.count();
}接下来在MilvusController中,分别添加对应的控制器方法,代码如下
@Operation(summary = "解析文件内容-LangChina分片")
@PostMapping("/splitParagraphsLangChain")
public ResponseEntity<List<String>> splitParagraphsLangChain(MultipartFile file) {
return ResponseEntity.ok(tikaUtil.splitParagraphsLangChain(tikaUtil.extractTextString(file)));
}
@Operation(summary = "解析文件内容-HanLP分片")
@PostMapping("/splitParagraphsHanLP")
public ResponseEntity<List<String>> splitParagraphsHanLP(MultipartFile file) {
return ResponseEntity.ok(tikaUtil.splitParagraphsHanLP(tikaUtil.extractTextString(file)));
}运行程序,访问swagger测试对应接口,首先我们用段落分明、符号清晰的文档来测试结果

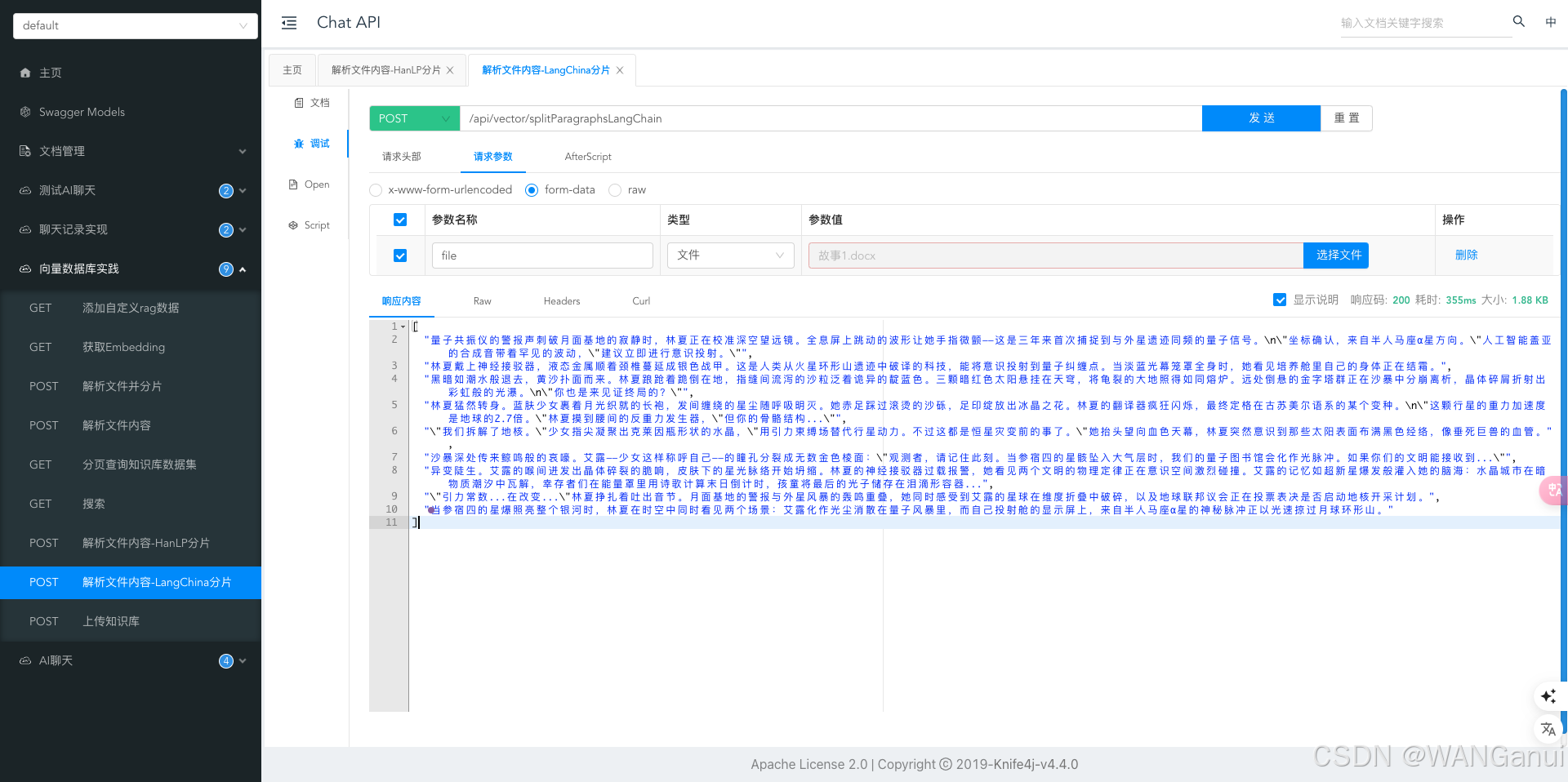
从两个工具文本分割的结果可以看出以下几点
-
段落分割:
- 两种方式都将原始文本分割为了5个主要部分,每个部分都以林夏的经历为线索推进故事。
- 分割点的选择基本相同,均依据故事情节的发展,如信号接收、意识投射、遇到艾露、文明交流与冲突、结局揭示等关键情节节点进行划分。
-
内容完整性:
- 在两种分割方式中,每一个段落都包含了相对完整的情节单元,使得读者可以在每一段中获取到一个情节发展的大致脉络。
- 文本中的细节描述和对话都被保留下来,保证了故事叙述的连贯性和完整性。
-
细节处理:
- 虽然整体结构相似,但在具体句子或短语的断句上可能存在细微差异,不过基于提供的信息,我们无法直接观察到这些细节上的不同,因为两者的文本输出几乎完全相同。
然后我们再使用标点符号以及段落不明显的文档分别测试
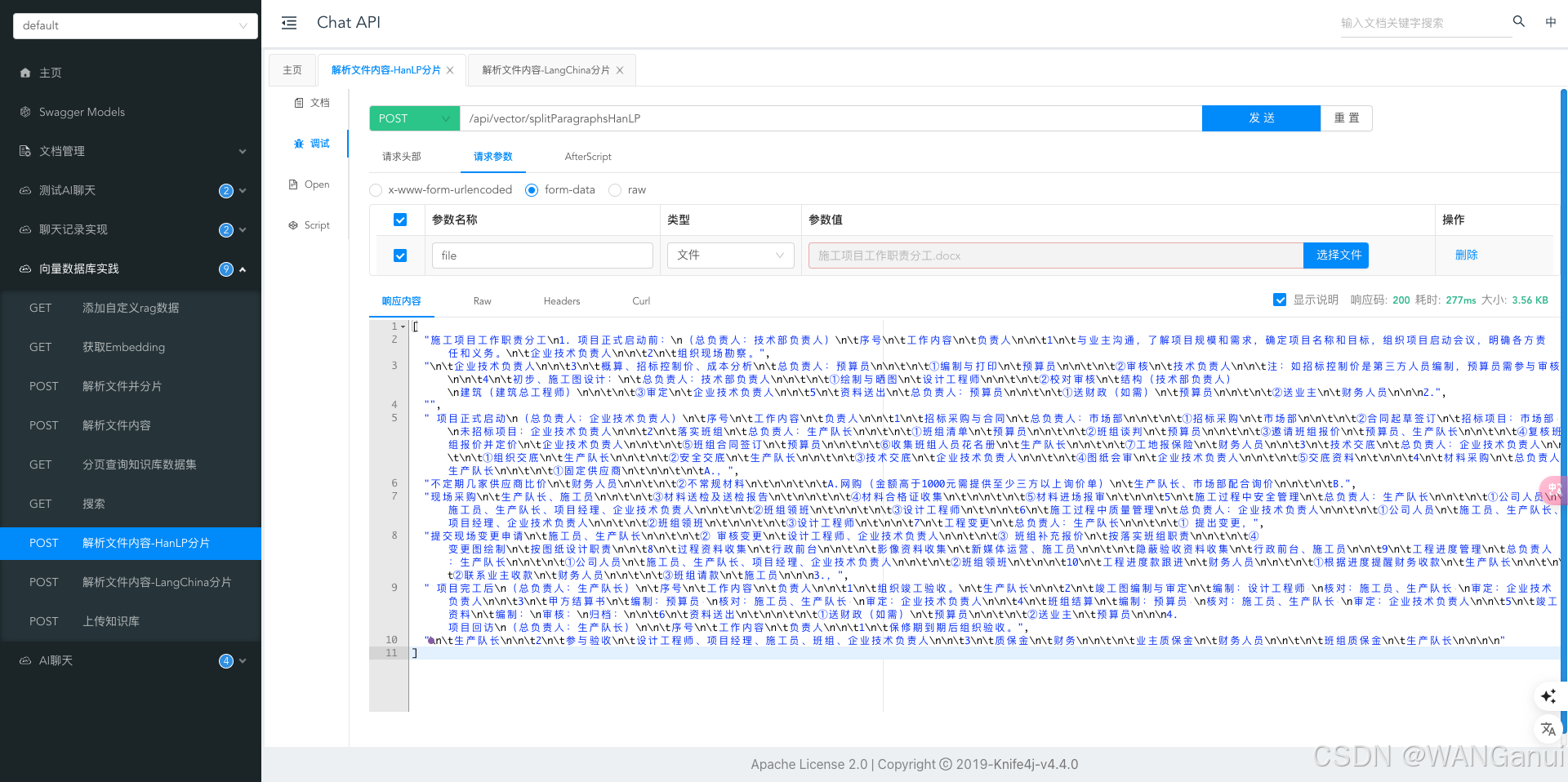

从对比结果来看,LangChain和HanLP两种工具在处理文本分割时产生了不同的效果。以下是对这两种工具分割结果的分析:
LangChain分割结果特点:
- 项目阶段划分清晰:LangChain能够很好地识别并分割出“项目正式启动前”、“项目正式启动”、“项目完工后”以及“项目回访”这几个主要阶段,并且每个阶段都有明确的开始和结束标志。
- 细节内容保留完整:对于每一个工作职责和负责人的描述,LangChain都能准确地进行分段,保持了原文档中信息的完整性。
- 格式一致性好:在整个分割过程中,LangChain维持了原始文档的结构化格式,使得阅读和理解变得容易。
HanLP分割结果特点:
- 部分阶段混合:HanLP在某些情况下未能完全将不同阶段的内容区分开来,例如“项目正式启动”部分内容与前面或后面的内容有所混杂。
- 细节处理较为精细:虽然在大段落分割上不如LangChain清晰,但HanLP在处理具体的工作职责细分时表现出了较好的细节捕捉能力,比如对“概算、招标控制价、成本分析”的进一步细分处理得比较细致。
- 格式略有不一致:相较于LangChain,HanLP生成的部分段落开头可能缺少明确的阶段标识,导致在快速浏览时不容易立即分辨出当前段落属于哪个阶段。
总结:
- 如果需要一个清晰、结构化的输出,尤其是当文档包含多个明显不同的章节或阶段时,LangChain可能是更好的选择。
- 对于那些更关注于文本内部细节而非整体结构的应用场景,HanLP可能会提供更加细腻的分割结果。
根据实际需求的不同,可以选择更适合的工具来进行文本分割处理。如果目的是为了后续的信息提取或自动化处理,考虑两者的特点选择合适的工具会更加有效。本人对分词库的相关技术了解有限,文中代码或描述如有错误或遗漏,欢迎大家指正,谢谢!
三、上传文档到向量数据库
上述步骤中,我们学习了如何从文件中提取文件内容,以及如何将长内容进行文本分割。接下来我们将学习如何将分割后的文本转换为向量表示后存入向量数据库中。
1、在MilvusService接口类中新增一个批量插入接口,并在实现类中实现具体逻辑
/**
* 批量插入数据
*
* @param vectorParam 向量参数
* @param text 文本
* @param metadata 元数据
* @param fileName 文件名
*/
InsertResp batchInsert(List<float[]> vectorParam, List<String> text, List<String> metadata, List<String> fileName);/**
* 批量插入数据
*
* @param vectorParam 向量参数
* @param text 文本
* @param metadata 元数据
* @param fileName 文件名
*/
@Override
public InsertResp batchInsert(List<float[]> vectorParam, List<String> text, List<String> metadata, List<String> fileName) {
if (vectorParam.size() == text.size() && vectorParam.size() == metadata.size() && vectorParam.size() == fileName.size()) {
List<JsonObject> jsonObjects = new ArrayList<>();
for (int i = 0; i < vectorParam.size(); i++) {
JsonObject jsonObject = new JsonObject();
// 数组转换成JsonElement
jsonObject.add(MilvusArchive.Field.FEATURE, new Gson().toJsonTree(vectorParam.get(i)));
jsonObject.add(MilvusArchive.Field.TEXT, new Gson().toJsonTree(text.get(i)));
jsonObject.add(MilvusArchive.Field.METADATA, new Gson().toJsonTree(metadata.get(i)));
jsonObject.add(MilvusArchive.Field.FILE_NAME, new Gson().toJsonTree(fileName.get(i)));
jsonObjects.add(jsonObject);
}
InsertReq insertReq = InsertReq.builder()
// 集合名称
.collectionName(MilvusArchive.COLLECTION_NAME)
.data(jsonObjects)
.build();
return milvusClientV2.insert(insertReq);
}
return null;
}2、新建一个TikaVo类,用作传输文档解析分片后的结果
package com.wanganui.tika;
import io.swagger.v3.oas.annotations.media.Schema;
import lombok.Data;
import lombok.experimental.Accessors;
import java.io.Serializable;
import java.util.List;
/**
* @author xtwang
* @des tika返回对象
* @date 2025/2/26 上午10:30
*/
@Accessors(chain = true)
@Schema(description = "tika返回对象")
@Data
public class TikaVo implements Serializable {
@Schema(description = "文本内容")
private List<String> text;
@Schema(description = "元数据")
private List<String> metadata;
}
3、在TikaUtil服务中新建一个用于解析并分片的方法
/**
* 文件内容提取
*
* @param file 上传的文件
* @return 文件内容
*/
public TikaVo extractText(MultipartFile file) {
try {
// 创建解析器--在不确定文档类型时候可以选择使用AutoDetectParser可以自动检测一个最合适的解析器
Parser parser = new AutoDetectParser();
// 用于捕获文档提取的文本内容。-1 参数表示使用无限缓冲区,解析到的内容通过此hander获取
BodyContentHandler bodyContentHandler = new BodyContentHandler(-1);
// 元数据对象,它在解析器中传递元数据属性---可以获取文档属性
Metadata metadata = new Metadata();
// 带有上下文相关信息的ParseContext实例,用于自定义解析过程。
ParseContext parseContext = new ParseContext();
parser.parse(file.getInputStream(), bodyContentHandler, metadata, parseContext);
// 获取文本
String text = bodyContentHandler.toString();
// 元数据信息
String[] names = metadata.names();
// 将元数据转换成JSON字符串
Map<String, String> map = new HashMap<>();
for (String name : names) {
map.put(name, metadata.get(name));
}
return splitParagraphs(text);
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
/**
* 使用langchain4j的分段工具
*
* @param content 文本内容
*/
private TikaVo splitParagraphs(String content) {
DocumentSplitter splitter = DocumentSplitters.recursive(TARGET_LENGTH, LENGTH_TOLERANCE, new OpenAiTokenizer());
List<TextSegment> split = splitter.split(Document.document(content));
return new TikaVo().setText(split.stream().map(TextSegment::text).toList()).setMetadata(split.stream().map(textSegment -> JSON.toJSONString(textSegment.metadata())).toList());
}4、在MilvusController类中新增一个上传知识库的控制器,将解析分片后的文本内容逐一转换成向量表示,再调用批量插入方法保存到向量数据库。
@Operation(summary = "上传知识库")
@PostMapping("/uploadFile")
public ResponseEntity<InsertResp> uploadFile(MultipartFile file) {
// 获取文件内容
TikaVo tikaVo = tikaUtil.extractText(file);
if (tikaVo != null && Objects.nonNull(tikaVo.getText())) {
List<float[]> embedList = new ArrayList<>();
List<String> textList = tikaVo.getText();
List<String> metadataList = tikaVo.getMetadata();
List<String> fileNameList = new ArrayList<>();
for (String s : tikaVo.getText()) {
embedList.add(ollamaEmbeddingModel.embed(s));
fileNameList.add(file.getOriginalFilename());
}
return ResponseEntity.ok(milvusService.batchInsert(embedList, textList, metadataList, fileNameList));
}
return ResponseEntity.ok(null);
}5、完成后运行程序,访问swagger页面,测试功能是否正常
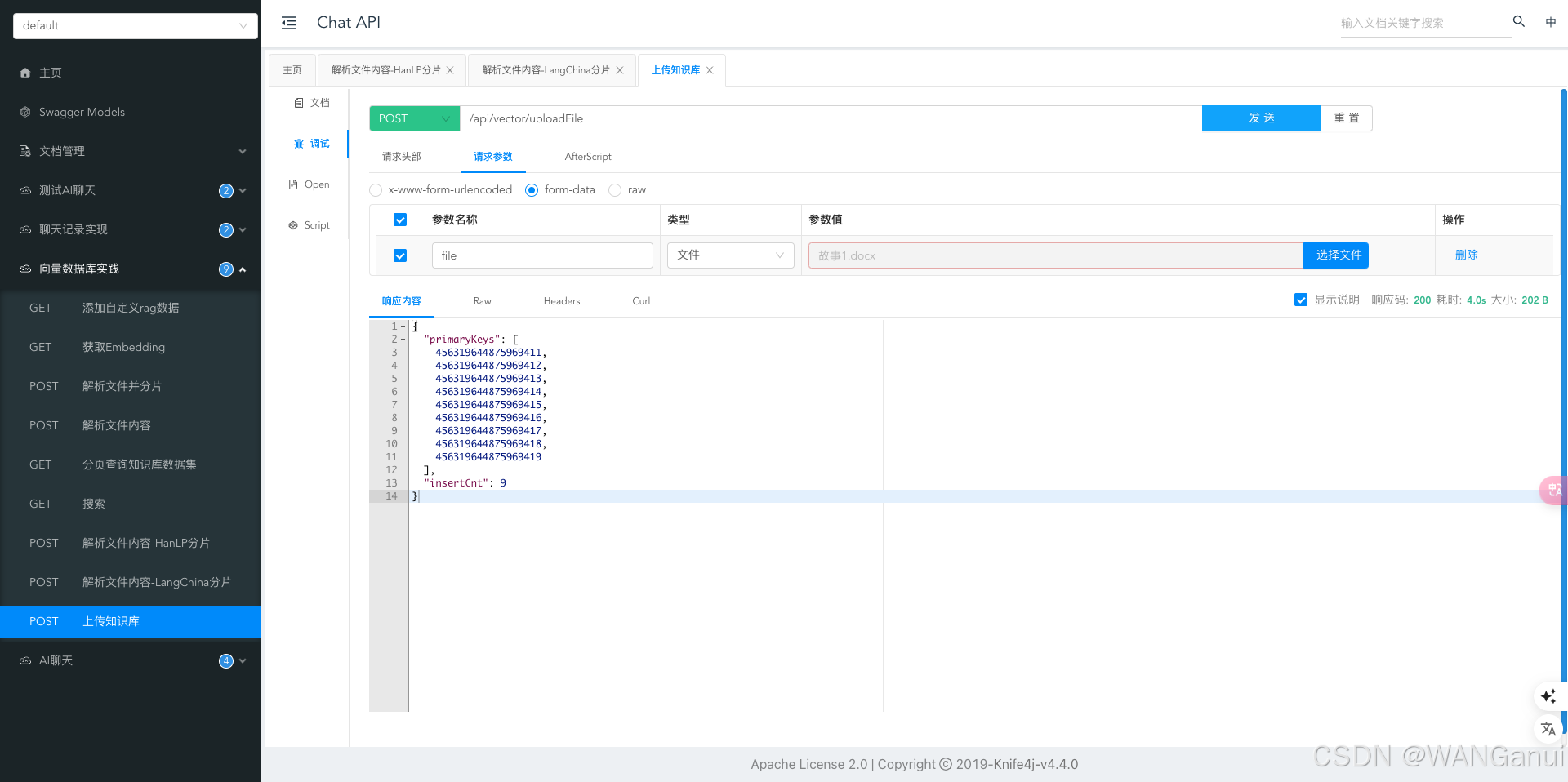
可以看到文档被分成了多个文本块,然后存入了向量数据库,接下来我们调用一下搜索接口,测试一下相关文本能不能搜索出来
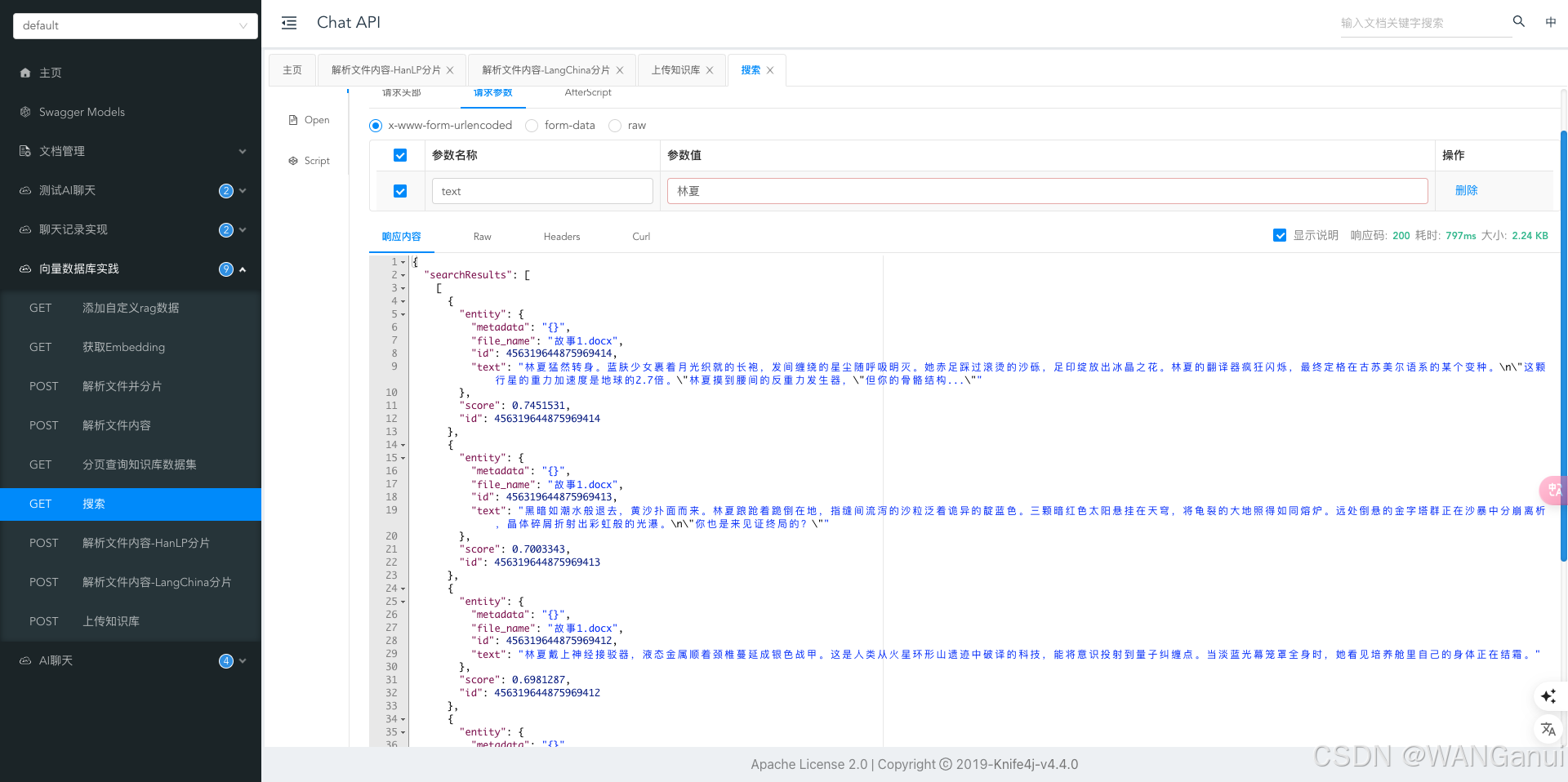 从上图可以看出,相关的文本块已按照相似度排序返回。
从上图可以看出,相关的文本块已按照相似度排序返回。
四、Advisors API
我们前面学习了这么多知识,铺垫了这么多东西,现在终于要进入正题了。那么怎么来实现检索增强生成呢?通俗来说就是将用户的问题先转换为向量表示,再从向量数据库中搜索相关文本块,然后将搜索结果组装到用户会话的上下文中传递给大语言模型,大模型再根据这些内容做出准确的回答。
这个逻辑的前两步我们已经实现了,那么如何将文本块添加到聊天上下文呢,这就需要使用到Spring AI的Advisors API,我们来学习一下这门技术。
在Spring AI 的官网中是这样介绍的:Spring AI 的Advisors API 提供了一种灵活而强大的方法来拦截、修改和增强 Spring 应用程序中 AI 驱动的交互。通过利用Advisors API,开发人员可以创建更复杂、可重用和可维护的 AI 组件。主要优势包括封装重复出现的生成式 AI 模式、转换发送到和来自语言模型 (LLM) 的数据,以及提供跨各种模型和用例的可移植性。
说的通俗一点你可以理解为它就是AOP,只不过是专注于 AI 模型交互的上下文处理。
1、Advisors 的核心功能与设计目标
-
请求/响应拦截与修改
Advisors 通过链式结构拦截并动态修改发送给 AI 模型的请求(AdvisedRequest)和模型返回的响应(AdvisedResponse)。例如,可以增强输入数据的上下文或过滤敏感内容。 -
功能模块化与复用
-
封装重复逻辑:如日志记录、历史会话管理(
MessageChatMemoryAdvisor)或敏感词校验(SafeGuardAdvisor)等通用功能可封装为可复用的 Advisor。 -
数据转换:优化输入数据格式(如提示词模板化)或后处理输出结果(如 JSON 结构化)。
-
-
跨模型兼容性
通过抽象接口(如CallAroundAdvisor和StreamAroundAdvisor),Advisors 可适配不同 AI 模型(如 OpenAI、HuggingFace),提升代码可移植性。
2、内建 Advisors 的分类与用途
Spring AI 提供多种预置 Advisors,覆盖常见 AI 交互场景:
-
上下文记忆管理
-
MessageChatMemoryAdvisor:将用户与模型的对话历史添加到请求的
messages参数中,需模型支持多轮对话(在我另一篇博客中有实践:Spring AI进阶:AI聊天机器人之ChatMemory持久化(二)_springai chatclient 向量数据库-CSDN博客)。 -
PromptChatMemoryAdvisor:将历史记录封装到系统提示词(
systemPrompt),适用于不直接支持messages参数的模型。
-
-
检索增强生成(RAG)
QuestionAnswerAdvisor:在用户提问时,从向量数据库检索相关文档片段并附加到输入中,提升回答准确性(本次将要用到的技术)。 -
安全与日志
-
SafeGuardAdvisor:拦截包含敏感词的请求,阻止调用 AI 模型。
-
SimpleLoggerAdvisor:记录请求与响应的日志,便于调试。
-
-
长期记忆存储
VectorStoreChatMemoryAdvisor:将对话历史存储到向量数据库,支持通过chat_memory_conversation_id关联会话,需注意避免因 ID 管理不当导致数据冗余。
3、自定义 Advisors 的实现
用户可通过实现 CallAroundAdvisor 或 StreamAroundAdvisor 接口创建自定义逻辑。以下是一个 Re-Reading(Re2)Advisor 的示例,用于在请求前重复用户问题以提升模型理解:
public class ReReadingAdvisor implements CallAroundAdvisor, StreamAroundAdvisor {
@Override
public AdvisedResponse aroundCall(AdvisedRequest request, CallAroundAdvisorChain chain) {
// 修改请求:将原始问题追加到提示词模板
String modifiedText = String.format("%s\n请再仔细阅读问题: %s", request.userText(), request.userText());
AdvisedRequest modifiedRequest = AdvisedRequest.from(request)
.withUserText(modifiedText)
.build();
return chain.nextAroundCall(modifiedRequest);
}
}通过 before 方法预处理请求,或通过 aroundCall 控制链式调用流程。
五、实现检索增强生成
学习了Spring AI的Advisors API,接下来我们把它运用到实际开发中,本次我们就不自定义Advisors的实现了,直接使用Spring AI提供的QuestionAnswerAdvisor来实现我们的需求。
1、Spring AI的向量存储依赖
在使用QuestionAnswerAdvisor时需要明确向量存储库以及相关能力接口,Spring AI提供了两种依赖方式来引入对向量数据库Milvus的支持
自动装配的依赖
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-milvus-store-spring-boot-starter</artifactId>
</dependency>手动配置的依赖
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-milvus-store</artifactId>
</dependency>本次演示我们使用的是手动配置的依赖项。
2、实现Spring AI向量存储能力
新建一个MilvusVectorStore类实现VectorStore接口,在实现类中注入MilvusService和OllamaEmbeddingModel,通过我们自己写的向量数据库操作接口来实现Spring AI的向量数据库操作能力,代码如下
package com.wanganui.chat;
import com.alibaba.fastjson.JSON;
import com.wanganui.vector.service.MilvusService;
import lombok.RequiredArgsConstructor;
import org.jetbrains.annotations.NotNull;
import org.springframework.ai.document.Document;
import org.springframework.ai.ollama.OllamaEmbeddingModel;
import org.springframework.ai.vectorstore.SearchRequest;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.ai.vectorstore.filter.Filter;
import org.springframework.stereotype.Component;
import java.util.List;
/**
* @author xtwang
* @des 自定义向量数据库相关接口实现
* @date 2025/2/26 上午11:06
*/
@Component
@RequiredArgsConstructor
public class MilvusVectorStore implements VectorStore {
private final MilvusService milvusService;
private final OllamaEmbeddingModel ollamaEmbeddingModel;
@Override
public void add(List<Document> documents) {
if (!documents.isEmpty()) {
for (Document document : documents) {
milvusService.insert(ollamaEmbeddingModel.embed(document), document.getText(), JSON.toJSONString(document.getMetadata()), null);
}
}
}
@Override
public void delete(List<String> idList) {
if (!idList.isEmpty()) {
// idList转换为id数组
String[] ids = idList.toArray(new String[0]);
milvusService.delete(ids);
}
}
@Override
public void delete(Filter.Expression filterExpression) {
milvusService.delete(filterExpression.toString());
}
@Override
public List<Document> similaritySearch(@NotNull SearchRequest request) {
return milvusService.search(request);
}
}
然后在聊天客户端配置ChatConfig中将能力提供给Spring AI
package com.wanganui.chat;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.client.advisor.MessageChatMemoryAdvisor;
import org.springframework.ai.chat.client.advisor.QuestionAnswerAdvisor;
import org.springframework.ai.ollama.OllamaChatModel;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @author xtwang
* @des AI聊天配置
* @date 2025/2/11 上午9:39
*/
@Configuration
public class ChatConfig {
@Bean
public ChatClient chatClient(OllamaChatModel ollamaChatModel, RedisChatMemory redisChatMemory, MilvusVectorStore milvusVectorStore) {
return ChatClient.builder(ollamaChatModel)
.defaultSystem("你是一个RAG知识库问答机器人,致力于解决用户提出的问题,并给出详细的解决方案")
.defaultAdvisors(new MessageChatMemoryAdvisor(redisChatMemory), new QuestionAnswerAdvisor(milvusVectorStore))
.build();
}
}
3、测试大模型
运行程序,通过聊天接口测试之前上传到向量数据库的文档能否被Spring AI检索出来
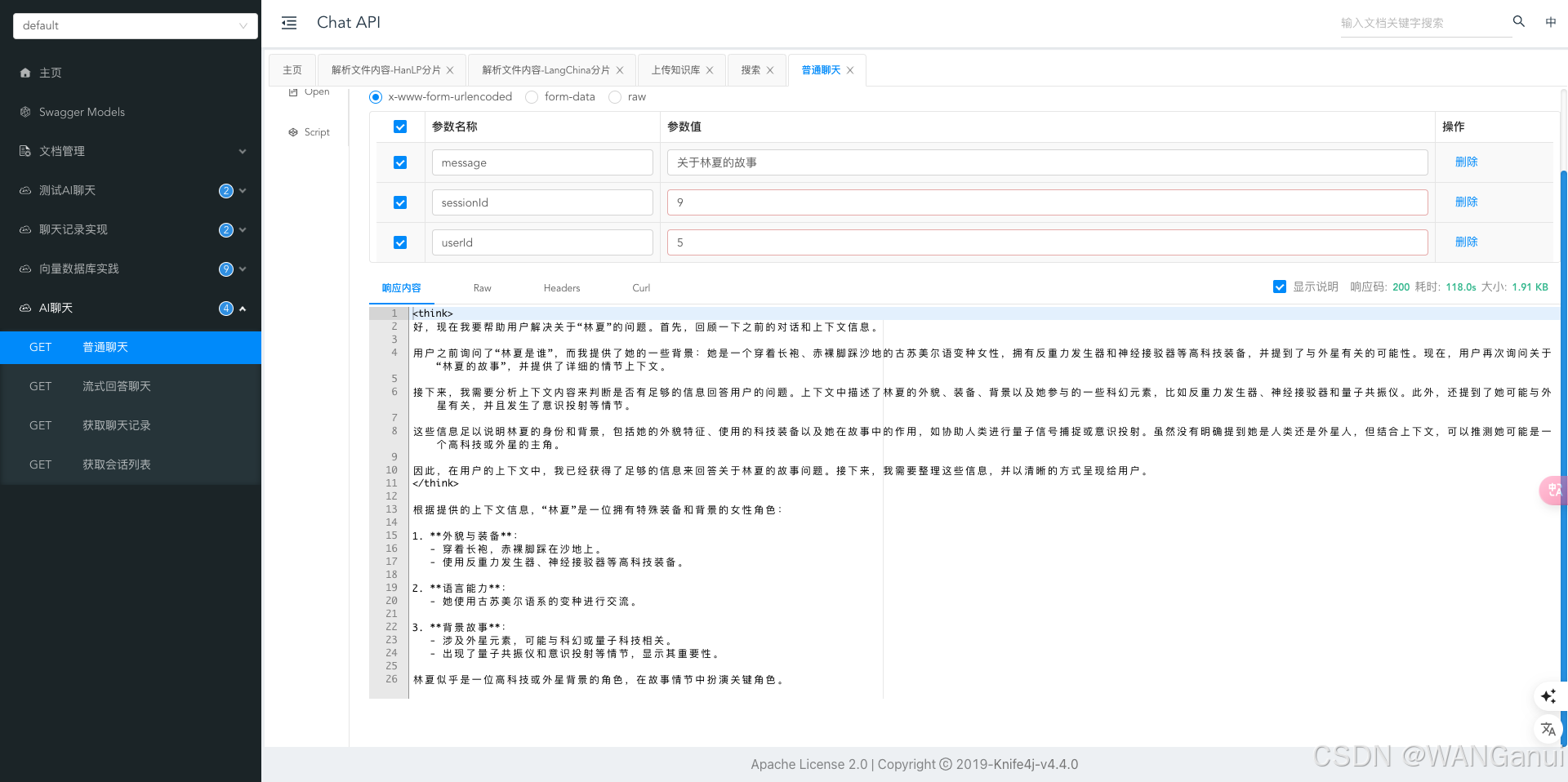
可以看到,Spring AI已成功从向量数据库中检索出了相关文本添加到了上下文中,并且根据文本作出了准确的回答。
六、总结
在本篇文章中,我们深入探讨了如何利用 Spring AI 和 Milvus 向量数据库 实现检索增强生成(RAG)应用。通过结合 Apache Tika 进行多格式文档解析、HanLP 和 LangChain4J 进行文本分片,以及 Spring AI 的 Advisors API 进行上下文增强,我们成功构建了一个能够从知识库中检索相关信息并生成准确回答的智能问答系统。
通过本文的学习,我们掌握了如何利用 Spring AI 和 Milvus 向量数据库构建一个高效的检索增强生成系统。无论是企业知识库管理还是智能问答系统,这一技术组合都展现了强大的潜力。希望本文能为开发者提供有价值的参考,助力 AI 应用的创新与落地。
参考资料:
Apache Tika::Apache Tika
LangChain4J:introduction | LangChain中文网
HanLP:HanLP | 在线演示
Spring AI:Milvus :: Spring AI 参考 - Spring 框架

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 21
21 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)