极简部署deepseek7B | 教程
在现代自然语言处理(NLP)领域,大型语言模型(LLM)如DeepSeek正变得越来越流行。这些模型能够生成连贯、上下文相关的文本,适用于各种应用,包括聊天机器人、内容生成和问答系统。本文将介绍如何在Ubuntu 22.04系统上,使用Python 3.10.12、Transformers 4.49.0和Torch 2.6.0加载和运行DeepSeek 7B模型。
在现代自然语言处理(NLP)领域,大型语言模型(LLM)如DeepSeek正变得越来越流行。这些模型能够生成连贯、上下文相关的文本,适用于各种应用,包括聊天机器人、内容生成和问答系统。本文将介绍如何在Ubuntu 22.04系统上,使用Python 3.10.12、Transformers 4.49.0和Torch 2.6.0加载和运行DeepSeek 7B模型。
系统环境准备
- 操作系统
Ubuntu 22.04
- 内存
32GB(建议,以确保流畅运行)
- 显卡
无(本指南使用CPU,GPU会显著提升性能)
- Python版本
3.10.12
- 配套库
Transformers 4.49.0
-
Torch 2.6.0
-
下载DeepSeek 7B模型
首先,需要从ModelScope平台下载DeepSeek 7B模型文件包。访问DeepSeek-R1-Distill-Qwen-7B模型页面,直接下载模型文件(避免使用Git克隆,以节省时间)。下载完成后,将文件解压到指定目录,例如/home/tool/deepseek/7b/DeepSeek-R1-Distill-Qwen-7B。
安装必要的Python库
确保系统中已安装Python 3.10.12,然后安装Transformers和Torch库。可以通过pip命令安装:
pip install transformers==4.49.0 torch==2.6.0加载模型
接下来,编写Python脚本(如deepseek_demo.py)来加载和运行模型。以下是脚本的核心部分:
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_path = "/home/tool/deepseek/7b/DeepSeek-R1-Distill-Qwen-7B" # 模型路径
device = "cpu" # 使用CPU,如有GPU可改为"cuda"
# 加载模型和分词器
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_path,
trust_remote_code=True,
torch_dtype=torch.float16, # 使用半精度浮点数以节省内存
device_map="auto"
).to(device)
# 生成响应函数
def generate_response(prompt):
messages = [{"role": "user", "content": prompt}]
inputs = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt"
).to(device)
outputs = model.generate(
inputs,
max_new_tokens=512,
do_sample=True,
temperature=0.8,
top_p=0.9
)
response = tokenizer.decode(outputs[0][len(inputs[0]):], skip_special_tokens=True)
return response
# 测试对话
if __name__ == "__main__":
while True:
user_input = input("用户:")
if user_input.lower() == "exit":
break
print("助手:", generate_response(user_input))运行脚本
在终端中运行脚本:
python3 deepseek_demo.py等待模型加载完成。由于模型较大且使用CPU进行推理,加载和响应时间可能较长。请耐心等待。
性能与优化
- 硬件限制
在仅有CPU的环境下,大型模型的推理速度较慢。若条件允许,建议使用GPU加速。
- 内存管理
确保系统有足够的内存,因为加载和运行大型模型会占用大量内存。
- 模型精度
使用
torch.float16(半精度浮点数)可以减少内存使用,但可能会略微影响精度。
注意事项
- 避免第三方框架
为确保系统资源有效利用,避免使用不必要的第三方资源框架,这些框架可能会增加系统负担。
- 库版本兼容性
本文使用的Transformers和Torch版本经过测试,可确保与DeepSeek 7B模型兼容。其他版本可能需要额外测试。
通过以上步骤,你可以在Ubuntu 22.04系统上成功加载和运行DeepSeek 7B模型。尽管在CPU上运行可能会较慢,但这一过程为理解和应用大型语言模型提供了宝贵的实践经验。未来,若条件允许,升级到GPU环境将显著提升性能和响应速度。
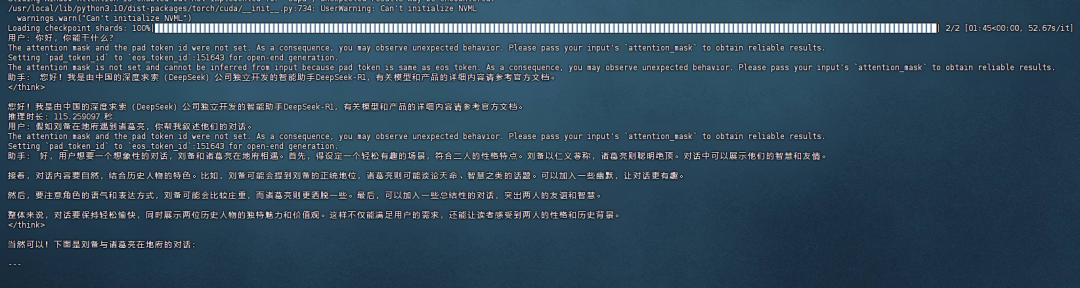
如图所示效果


作者介绍:
在这里,我尽情探索着无限的可能,
专注于分享,在繁忙之中寻觅并享受那难得的欢愉与放松;
不断前行,持续探索着各式各样的可能性。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)