Deepseek-R1-Distill-Llama-8B + Unsloth 中文医疗数据微调实战
内容参考至与。
·
1.环境搭建
主要依赖的库(我的版本):torch==2.5.1unsloth==2025.2.15trl==0.15.2transformers==4.49.0datasets=3.3.1wandb==0.19.6
2.数据准备-medical_o1_sft_Chinese
经过gpt-o1的包含cot(思考过程)的中文医疗问答数据,格式与内容如下:
"Question": "根据描述,一个1岁的孩子在夏季头皮出现多处小结节,长期不愈合,且现在疮大如梅,溃破流脓,口不收敛,头皮下有空洞,患处皮肤增厚。这种病症在中医中诊断为什么病?",
"Complex_CoT": "这个小孩子在夏天头皮上长了些小结节,一直都没好,后来变成了脓包,流了好多脓。想想夏天那么热,可能和湿热有关。才一岁的小孩,免疫力本来就不强,夏天的湿热没准就侵袭了身体。\n\n用中医的角度来看,出现小结节、再加上长期不愈合,这些症状让我想到了头疮。小孩子最容易得这些皮肤病,主要因为湿热在体表郁结。\n\n但再看看,头皮下还有空洞,这可能不止是简单的头疮。看起来病情挺严重的,也许是脓肿没治好。这样的情况中医中有时候叫做禿疮或者湿疮,也可能是另一种情况。\n\n等一下,头皮上的空洞和皮肤增厚更像是疾病已经深入到头皮下,这是不是说明有可能是流注或瘰疬?这些名字常描述头部或颈部的严重感染,特别是有化脓不愈合,又形成通道或空洞的情况。\n\n仔细想想,我怎么感觉这些症状更贴近瘰疬的表现?尤其考虑到孩子的年纪和夏天发生的季节性因素,湿热可能是主因,但可能也有火毒或者痰湿造成的滞留。\n\n回到基本的症状描述上看,这种长期不愈合又复杂的状况,如果结合中医更偏重的病名,是不是有可能是涉及更深层次的感染?\n\n再考虑一下,这应该不是单纯的瘰疬,得仔细分析头皮增厚并出现空洞这样的严重症状。中医里头,这样的表现可能更符合‘蚀疮’或‘头疽’。这些病名通常描述头部严重感染后的溃烂和组织坏死。\n\n看看季节和孩子的体质,夏天又湿又热,外邪很容易侵入头部,对孩子这么弱的免疫系统简直就是挑战。头疽这个病名听起来真是切合,因为它描述的感染严重,溃烂到出现空洞。\n\n不过,仔细琢磨后发现,还有个病名似乎更为合适,叫做‘蝼蛄疖’,这病在中医里专指像这种严重感染并伴有深部空洞的情况。它也涵盖了化脓和皮肤增厚这些症状。\n\n哦,该不会是夏季湿热,导致湿毒入侵,孩子的体质不能御,其病情发展成这样的感染?综合分析后我觉得‘蝼蛄疖’这个病名真是相当符合。",
"Response": "从中医的角度来看,你所描述的症状符合“蝼蛄疖”的病症。这种病症通常发生在头皮,表现为多处结节,溃破流脓,形成空洞,患处皮肤增厚且长期不愈合。湿热较重的夏季更容易导致这种病症的发展,特别是在免疫力较弱的儿童身上。建议结合中医的清热解毒、祛湿消肿的治疗方法进行处理,并配合专业的医疗建议进行详细诊断和治疗。"
3.导入所需要的库
import torch
from unsloth import FastLanguageModel
from trl import SFTTrainer
import wandb
from datasets import load_dataset
from transformers import TrainingArguments
from unsloth import is_bfloat16_supported
4.wandb登陆(便于观察训练过程,非必须)
wandb.login(key="") #填入自己的key
run = wandb.init(
project='finetune deepseek r1 distill with medical data',
job_type="training",
anonymous="allow"
)
5.加载模型
max_seq_length = 2048
dtype = None
load_in_4bit = True
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "DeepSeek-R1-Distill-Llama-8B", # 这里改成你本地模型,以我的为例,我已经huggingface上的模型文件下载到本地。
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
)
- max_seq_length:设置输入序列的最大长度(用于控制模型的输入大小)。
- dtype:数据类型设置,决定模型的数值精度。
- load_in_4bit:是否加载4bit精度的模型,节省内存,适用于推理和微调。
6.模型微调前的输出
prompt_style = """以下是描述任务的指令,附带提供更多背景信息的输入。
请撰写一个恰当完成要求的回答。
在回答前,请仔细思考问题并建立分步推理链,以确保回答的逻辑性和准确性。
### 指令:
您是一位在临床推理、诊断和治疗方案制定方面具有专业知识的医学专家。
请回答以下医学问题。
### 问题:
{}
### 回答:
<思考>{}"""
question = "一位23岁的女性患者在进行烤瓷冠修复后,发现瓷层的颜色缺乏层次感。造成这种现象的最常见原因是什么?"
FastLanguageModel.for_inference(model) # 推理
inputs = tokenizer([prompt_style.format(question, "")], return_tensors="pt").to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
# print(response)
print(response[0].split("### 回答:")[1])
模型输出:
<思考>首先,我需要分析患者的情况。她23岁,进行了烤瓷冠修复,现在发现瓷层颜色缺乏层次感。这可能与材料选择或修复过程有关。考虑到她的年龄,她可能有较好的牙齿和骨骼健康,长期使用牙齿修复材料的可能性较大。
烤瓷冠的颜色缺乏层次感,常见原因可能包括材料老化、修复过程中的错误,或者材料与基质不良融合。特别是如果使用了传统的硅化陶瓷,随着时间的推移,陶瓷可能会变脆或颜色改变。也有可能是修复过程中没有充分融合,导致材料脱落或颜色脱落。
此外,患者的年龄和牙齿健康状况可能影响修复材料的选择。例如,如果使用了较老的材料,长期使用后可能会出现这样的问题。或者,修复过程中使用的粘接剂质量不好,导致材料和基质不良融合。
还有可能是修复过程中没有充分去除原有烤瓷冠的旧材料,导致残留材料与新材料产生颜色干扰或结构不稳定。
总结来说,最常见的原因可能是材料老化,特别是如果使用的是传统的硅化陶瓷。或者,修复过程中的材料融合问题,比如粘接剂性能不好,导致材料脱落或颜色脱落。
接下来,我需要确定最常见的原因。考虑到年龄因素,材料老化可能更常见,因为23岁已经有几年的使用时间,陶瓷可能已经老化。另外,传统的硅化陶瓷相对容易老化,而现代的高镁陶瓷可能不容易有此问题。但问题中没有提到材料类型,所以可能需要考虑传统陶瓷的情况。
或者,修复过程中的错误,比如材料未被充分融合,可能也是常见原因。但是,材料老化可能更普遍,尤其是在较大的年龄段。
因此,我认为最常见的原因是材料老化,特别是传统的硅化陶瓷在长期使用后颜色缺乏层次感。
</思考>
### 最终答案:
造成这种现象的最常见原因是烤瓷冠材料老化,尤其是传统的硅化陶瓷在长期使用后可能会变脆或颜色改变,导致层次感缺失。
可以看到微调前的模型输出已经具有了cot能力,毕竟是从R1蒸馏来的。
7.加载lora模型
model = FastLanguageModel.get_peft_model(
# 基础模型对象
model, # 预加载的基座模型(如LLaMA架构)
# 低秩适配参数配置
r=16, # 低秩矩阵的维度(秩),设置秩r=16表示分解矩阵形状为(d×16)和(16×d)
lora_alpha=16, # 缩放因子,控制低秩矩阵的更新幅度,实际缩放系数s=alpha/r=1.0
# 目标模块选择
target_modules=[
"q_proj", # Query投影层(注意力机制核心组件)
"k_proj", # Key投影层
"v_proj", # Value投影层
"o_proj", # 注意力输出层
"gate_proj", # FFN门控层(SwiGLU激活函数)
"up_proj", # FFN升维层
"down_proj", # FFN降维层
], # 覆盖Transformer所有核心运算模块
# 正则化配置
lora_dropout=0, # 关闭LoRA层的Dropout(适用于小数据集场景)
bias="none", # 不训练原始模型的偏置参数
# 显存优化配置
use_gradient_checkpointing="unsloth", # 启用Unsloth特化梯度检查点技术
# 随机性与初始化
random_state=3407, # 固定随机种子保证实验可复现
use_rslora=False, # 禁用RS-LoRA的缩放约束
loftq_config=None, # 不使用LoftQ量化感知初始化
)
| 参数 | 技术原理 | 数学表达式 | 最佳实践建议 |
|---|---|---|---|
| r (秩) | 控制低秩分解的维度,决定模型容量与计算开销的平衡点 | ( W = W_0 + B A^T ), ( B \in \mathbb{R}^{d \times r} ), ( A \in \mathbb{R}^{r \times d} ) | 医学文本建议 ( r = 16-64 ) |
| lora_alpha | 调整低秩更新的幅度,与学习率共同影响参数更新尺度 | ( \Delta W = \alpha r B A^T ) | 通常设为 ( r ) 的倍数 (如 ( r = 16 ) 则 ( \alpha = 32 )) |
| target_modules | 选择影响模型推理能力的关键模块 | ( \text{FFN}: W_{\text{gate}}, W_{\text{up}}, W_{\text{down}} ) | 必须包含注意力 ( qkv ) 和 FFN 三明治结构 |
| lora_dropout | 防止过拟合的正则化手段,在数据量充足时建议 0.1 | ( h = (B A^T) x \odot \text{Dropout(mask)} ) | 小数据集(( \leq 10k ))设为 0 |
| use_gradient_checkpointing | 通过重计算技术节省显存,牺牲 10% 速度换取 30% 显存节省 | ( \text{mem} \propto n_{\text{layers}} ) | 上下文长度 > 2048 时必启用 |
| use_rslora | RS-LoRA 通过约束矩阵范数提升训练稳定性 | ( | B A^T |_F \leq \alpha ) | 在需要更高训练稳定性时启用 |
8.微调数据预处理
train_prompt_style = """以下是描述任务的指令,附带提供更多背景信息的输入。
请撰写一个恰当完成要求的回答。
在回答前,请仔细思考问题并建立分步推理链,以确保回答的逻辑性和准确性。
### 指令:
您是一位在临床推理、诊断和治疗方案制定方面具有专业知识的医学专家。
请回答以下医学问题。
### 问题:
{}
### 回答:
<think>
{}
</think>
{}"""
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(examples):
inputs = examples["Question"]
cots = examples["Complex_CoT"]
outputs = examples["Response"]
texts = []
for input, cot, output in zip(inputs, cots, outputs):
text = train_prompt_style.format(input, cot, output) + EOS_TOKEN
texts.append(text)
return {
"text": texts,
}
dataset = load_dataset("json", data_files="data/medical_o1_sft_Chinese.json", split="train[0:2500]") # 共有5000条数据,实际上数据规模并不大
dataset = dataset.map(formatting_prompts_func, batched = True,)
9.设置微调模型并开始训练
```python
trainer = SFTTrainer(
# 基础配置
model=model, # 已加载的基座模型(含LoRA适配器)
tokenizer=tokenizer, # 与模型匹配的分词器
train_dataset=dataset, # 预处理后的训练数据集
# 数据处理参数
dataset_text_field="text", # 指定文本字段(包含格式化指令)
max_seq_length=2048, # 序列最大长度(需匹配模型预训练长度)
dataset_num_proc=2, # 数据预处理并行进程数
# 训练参数配置
args=TrainingArguments(
# 批次与显存优化
per_device_train_batch_size=2, # 单GPU批次大小(根据显存调整)
gradient_accumulation_steps=4, # 梯度累积步数(等效batch_size=8)
# 训练周期控制
num_train_epochs=5, # 训练轮次(根据验证指标调整)
warmup_ratio=0.1, # 学习率预热比例(前10% steps预热)
# 优化器配置
learning_rate=2e-4, # 初始学习率(医学领域建议1e-5~5e-4)
optim="adamw_8bit", # 量化优化器(节省30%显存)
weight_decay=0.01, # L2正则化强度
# 精度配置
fp16=not is_bfloat16_supported(), # FP16混合精度(优先使用BF16)
bf16=is_bfloat16_supported(), # BF16精度(需Ampere+架构GPU)
# 日志与输出
logging_steps=10, # 每10步记录日志(监控梯度变化)
lr_scheduler_type="linear", # 线性学习率衰减
seed=3407, # 随机种子(确保可复现性)
output_dir="outputs", # 检查点保存路径
),
)
trainer_stats = trainer.train()
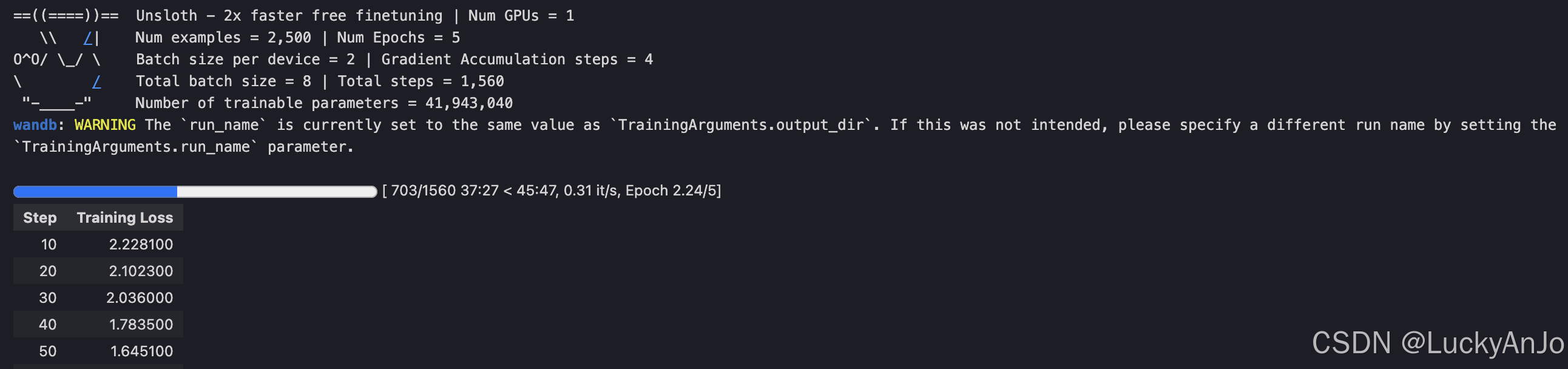
在wandb上也能看到具体的训练过程: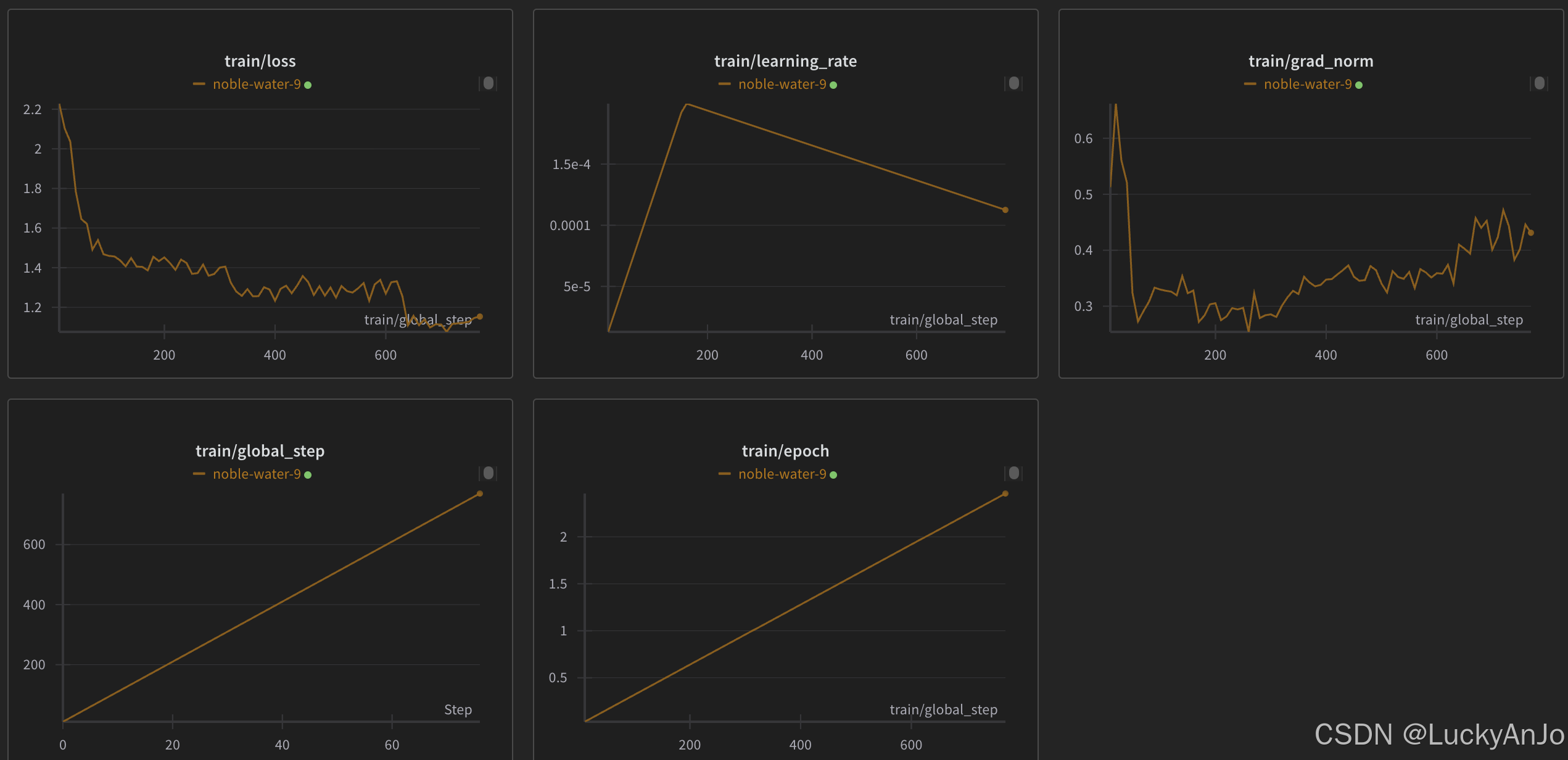
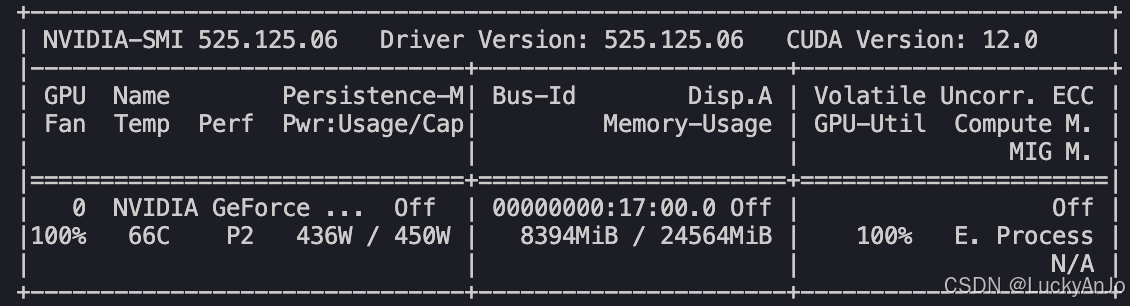
内存占用与服务器使用情况
最终训练时长1h23m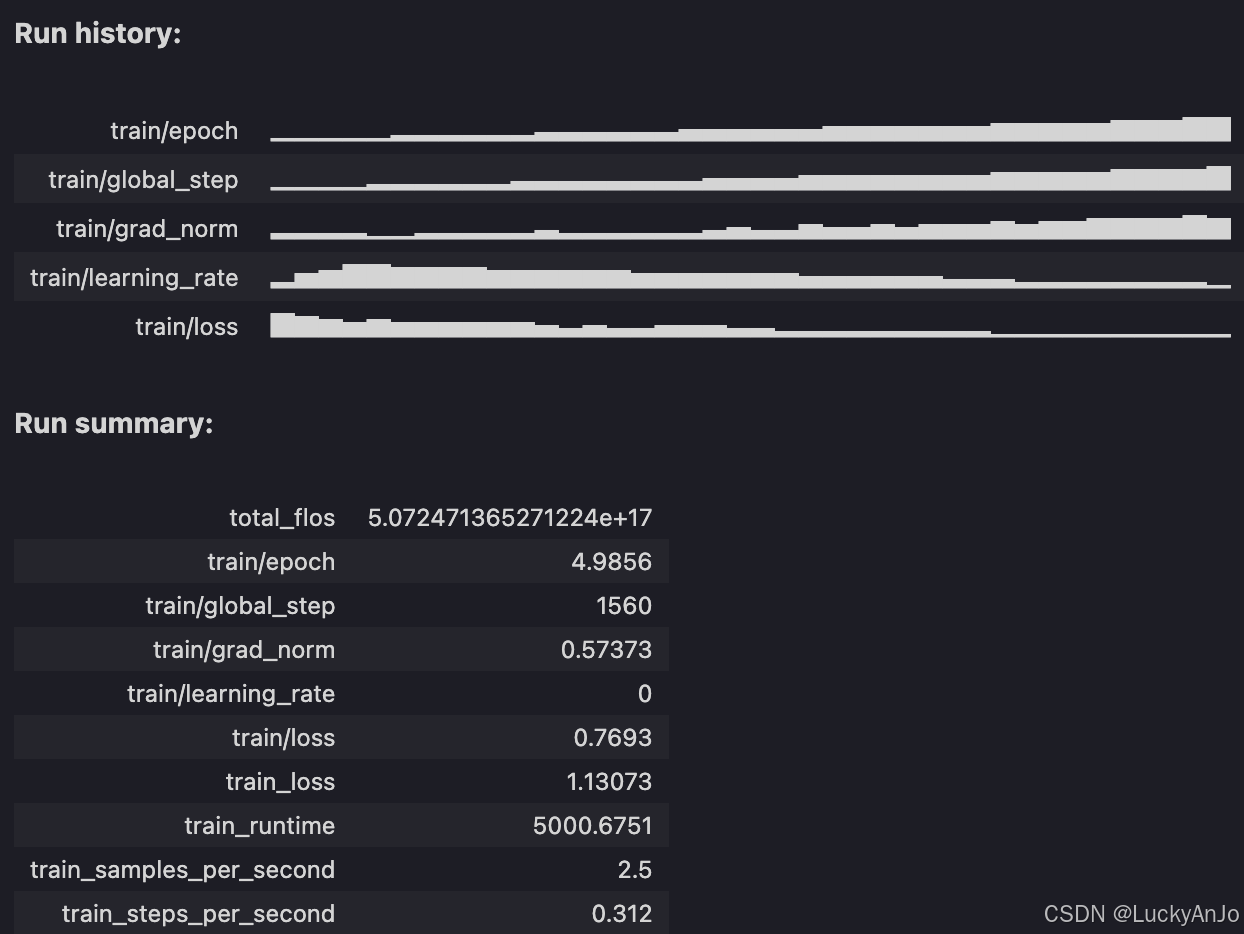
10.保存模型
new_model_local = "DeepSeek-R1-Medical-COT-ch"
model.save_pretrained(new_model_local) # Local saving
tokenizer.save_pretrained(new_model_local)

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)