DeepSeek开源周第五日:压轴炸场!3FS与smallpond
是一款专为应对AI训练与推理而设计的高性能分布式文件系统一个基于DuckDB和3FS构建的轻量级数据处理框架。

今天是DeepSeek开源周的最后一天,收官压轴带来了两个重磅开源项目:
-
3FS(Fire-Flyer File System):是一款专为应对AI训练与推理而设计的高性能分布式文件系统
-
smallpond:一个基于DuckDB和3FS构建的轻量级数据处理框架
3FS
3FS(Fire-Flyer File System)是一款专为应对AI训练与推理工作负载挑战而设计的高性能分布式文件系统。其通过现代SSD和RDMA网络构建共享存储层
核心特点
-
分布式架构:整合数千块SSD的吞吐能力与数百个存储节点的网络带宽,支持应用以无地域感知方式访问存储资源。
-
强一致性:基于链式复制分片查询(CRAQ)实现强一致性,简化应用代码逻辑与推理过程。
-
文件接口:构建基于事务型键值存储(如FoundationDB)的无状态元数据服务,提供通用文件接口,无需学习新存储API。
多样化工作负载
-
数据预处理:高效管理数据分析流水线的层级目录结构与海量中间输出。
-
数据加载器:支持跨计算节点随机访问训练样本,消除预取与数据混洗需求。
-
Checkpointing:支持大规模训练的高吞吐量并行Checkpoints。
-
推理KVCache:替代DRAM缓存的高性价比方案,兼具高吞吐与超大容量特性。
高性能
-
峰值吞吐
下图展示了大规模3FS集群的读取压力测试吞吐表现。该集群包含180个存储节点,每个节点配备2×200Gbps InfiniBand网卡与16块14TiB NVMe SSD。测试使用500+客户端节点(每节点配置1×200Gbps InfiniBand网卡),在训练任务背景流量下实现总读取吞吐约6.6 TiB/s。
** **
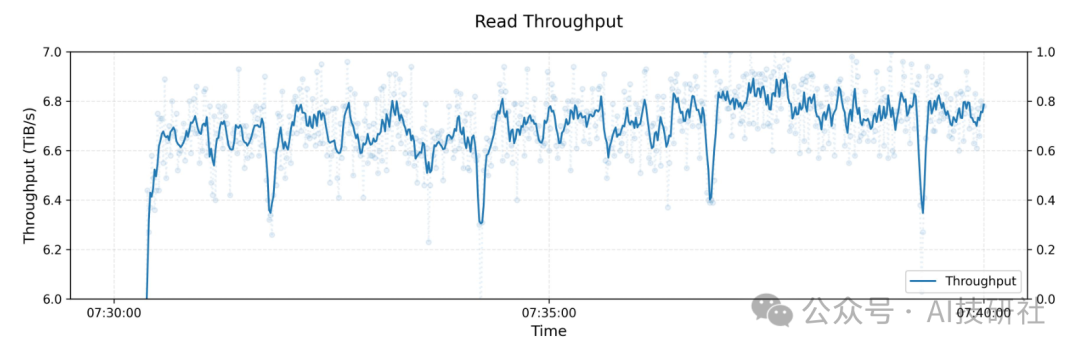
-
GraySort
基于GraySort基准(大规模数据集排序性能测试)评估smallpond实现。方案采用两阶段流程:
1.通过键前缀分片实现数据洗牌
2.分区内排序 两阶段数据读写均基于3FS完成。
测试集群包含25个存储节点(2 NUMA域/节点,1存储服务/NUMA域,2×400Gbps网卡/节点)与50个计算节点(2 NUMA域,192物理核心,2.2 TiB内存,1×200Gbps网卡/节点)。对8,192个分区的110.5 TiB数据进行排序耗时30分14秒,平均吞吐达3.66 TiB/分钟。
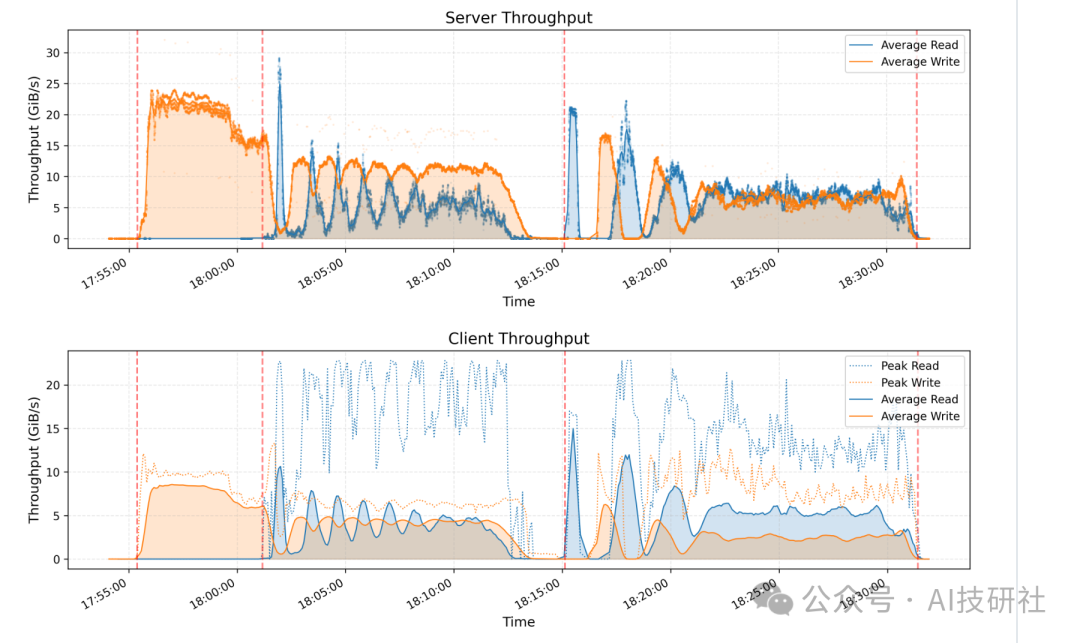
-
KVCache
KVCache 技术用于优化大语言模型推理过程,避免重复计算缓存的键值向量。下图展示了所有 KVCache 客户端的读取吞吐量峰值与平均值,峰值吞吐量达 40 GiB/s。同时也展示了垃圾回收过程中的移除操作 IOPS 指标。
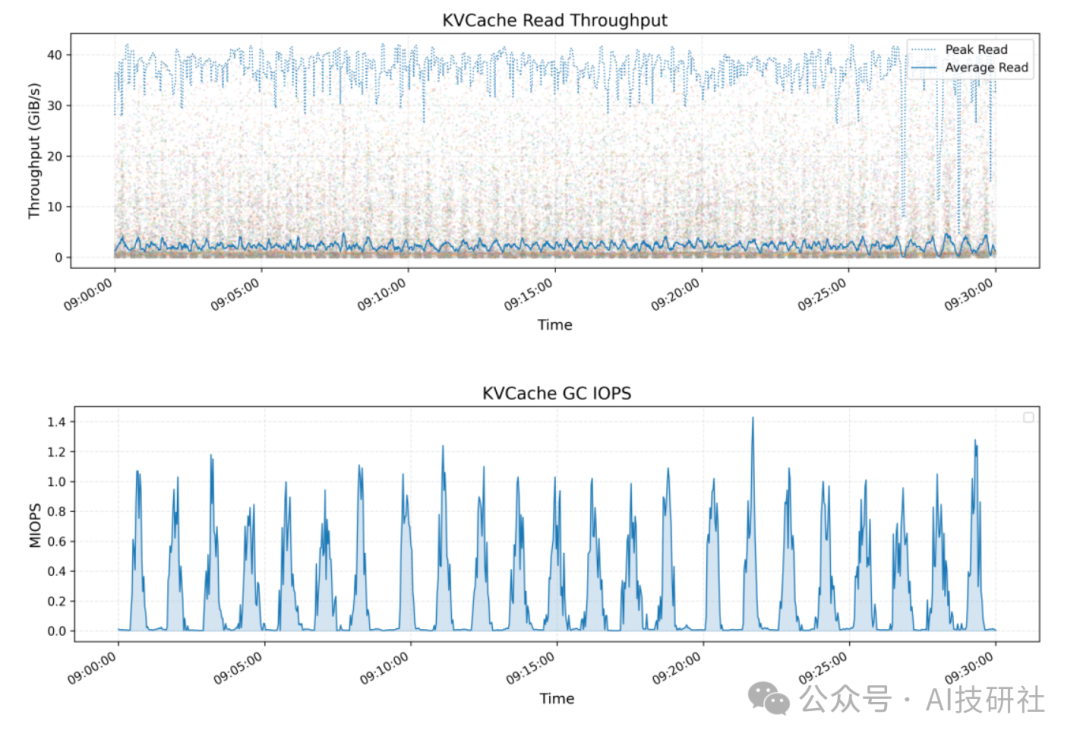
Smallpond
smallpond:一个基于DuckDB和3FS构建的轻量级数据处理框架。
核心特性
-
高性能:基于DuckDB的高性能数据处理
-
高扩展:可扩展至PB级数据集
-
操作简单:无需长期运行服务,操作简单
作为收官之作|为什么这两个项目如此重要呢?
-
解决AI训练数据存储痛点
大模型训练往往需要海量数据,传统存储系统成为瓶颈,3FS+smallpond完美解决
-
提升推理效率
AI推理需要访问海量数据,KVCache功能让推理速度大大提升,响应快、成本低
-
降低使用门槛
简单接口设计,对开发者友好
官方GitHub地址:
https://github.com/deepseek-ai/3FS
https://github.com/deepseek-ai/smallpond
DeepSeek开源周本期分享到此结束,欢迎大家持续关注,后续为大家分享更精彩内容!!!

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 11
11 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)