基于云部署DeepSeek自动分析整合低粉爆款视频数据
基于云部署DeepSeek自动分析整合低粉爆款视频数据
大家好,我是小黄。
DeepSeek官网基本都是处于繁忙的状态,这让我们使用起来的体验感非常不好。最近小黄又发现了一个云算力平台——UCloud。
一、低粉爆款数据分析
最近很多做自媒体的小伙伴来问小黄说,现在的人工智能大模型越来越智能。能不能借助大模型来做自媒体呢?
答案是肯定的。下面小黄就给大家演示一下,如何借助deepseek来实现借助算力平台UCloud来实现自动采集和分析低粉爆款视频数据。
低粉爆款顾名思义就是粉丝量比较少的用户但是作品的数据却非常好的情况,我们可以参考这些作品数据,实现快速起号。
我们本次需要使用到篡改猴插件。

大家不会安装的可以自行搜索安装一下,我们本次重点介绍采集的脚本。
我们基于某红书的数据采集,效果如下:在页面友上角创建一个按钮,采集完成的数据会生成一个excel表格。我们可以根据表格快速找到我们想要参考的数据。
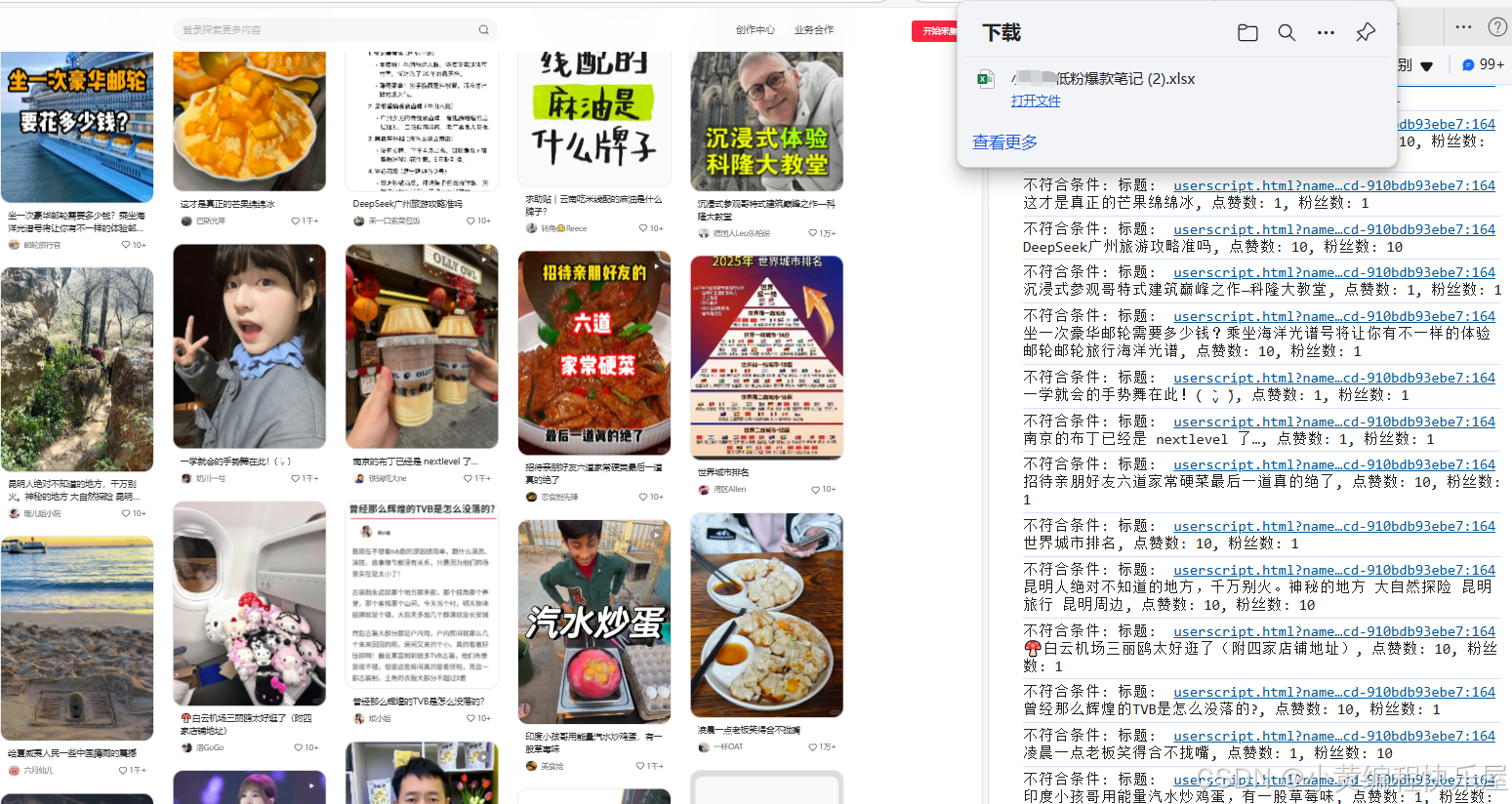
部分脚本:我们可以设置作品的最少点赞和作者的粉丝数,不符合的数据不进行保存
// ==UserScript==
// @name 小红书低粉爆款笔记采集
// @namespace http://tampermonkey.net/
// @version 0.7
// @description 点击按钮采集小红书点赞数大于5000且粉丝数少于3000的笔记数据,支持超时检测和错误处理
// @author XiaoHuangCodeing
// @match https://www.xiaohongshu.com/*
// @grant GM_xmlhttpRequest
// @grant GM_addStyle
// @require https://cdn.jsdelivr.net/npm/xlsx@0.18.5/dist/xlsx.full.min.js
// ==/UserScript==
(function () {
'use strict';
// 存储采集到的笔记数据
let noteData = [];
// 存储符合条件到的笔记数据
let targetData = [];
// 存储粉丝数据
let fansData = [];
let exportout = false; // 是否导出数据
// 定义筛选条件
const MIN_LIKES = 5000; // 最小点赞数
const MAX_FOLLOWERS = 3000; // 最大粉丝数
const MAX_NUM = 10; // 最大采集数量
let seratchNum = 0; // 采集数量
// 定义超时时间(单位:毫秒)
const TIMEOUT_DURATION = 10000; // 00 秒
// 添加按钮样式
GM_addStyle(`
#collect-button {
position: fixed;
top: 20px;
right: 20px;
z-index: 1000;
padding: 10px 20px;
background-color: #ff2442;
color: white;
border: none;
border-radius: 5px;
cursor: pointer;
font-size: 14px;
}
#collect-button:hover {
background-color: #e0213a;
}
`);
// 添加按钮到页面
const button = document.createElement('button');
button.id = 'collect-button';
button.innerText = '开始采集';
document.body.appendChild(button);
// 按钮点击事件
button.addEventListener('click', () => {
button.innerText = '采集中...';
button.disabled = true;
exportout = true;
noteData = []; // 重置数据
targetData = [];
fansData = [];
seratchNum = 0 ;
getNoteInfo();
setTimeout(() => {
if (noteData.some(item => item.粉丝数 === '加载中...')) {
console.log('采集超时,导出已采集的数据');
exportToExcel(targetData);
button.innerText = '开始采集';
button.disabled = false;
}
}, TIMEOUT_DURATION);
});
// 获取笔记信息
function getNoteInfo() {
const noteItems = document.querySelectorAll('.note-item'); // 获取所有笔记项
noteItems.forEach((note, index) => {
const title = note.querySelector('.title span')?.innerText || '未知标题'; // 标题
const author = note.querySelector('.author .name')?.innerText || '未知作者'; // 作者
const likesText = note.querySelector('.like-wrapper .count')?.innerText || '0'; // 点赞数文本
const likes = parseCount(likesText); // 解析点赞数
const cover = note.querySelector('.cover img')?.src || '未知封面'; // 封面图链接
const link = note.querySelector('.cover')?.href || '未知链接'; // 笔记链接
const authorLink = note.querySelector('.author')?.href || '未知作者链接'; // 作者主页链接
完整的脚本大家可以通过关注小黄回复:低粉爆款获取。
二、优云智算
优云智算(Compshare)是 UCloud 优刻得旗下的算力共享平台1。主要为 AI 应用、模型推理与微调、科学计算等多场景提供高性价比算力1。具有以下优势1:
- 性能卓越:采用 GPU 显卡直通技术,可让用户 100% 利用 GPU 性能,相比传统容器形式,性能损耗降低 30%。
- 使用便捷:每个实例配备独立外网 IP,便于服务器资源管理;还支持 GitHub 和 Hugging Face 等学术资源的访问加速,无需复杂配置即可快速拉取资源。
- 配置灵活:提供多种 GPU 数量和配置选项,GPU 从 1 到 8 卡不等,CPU 内存从 16C64GB 到 124C940GB,系统盘为 200GB 的 SSD 云盘,网络为 100MB 共享带宽。
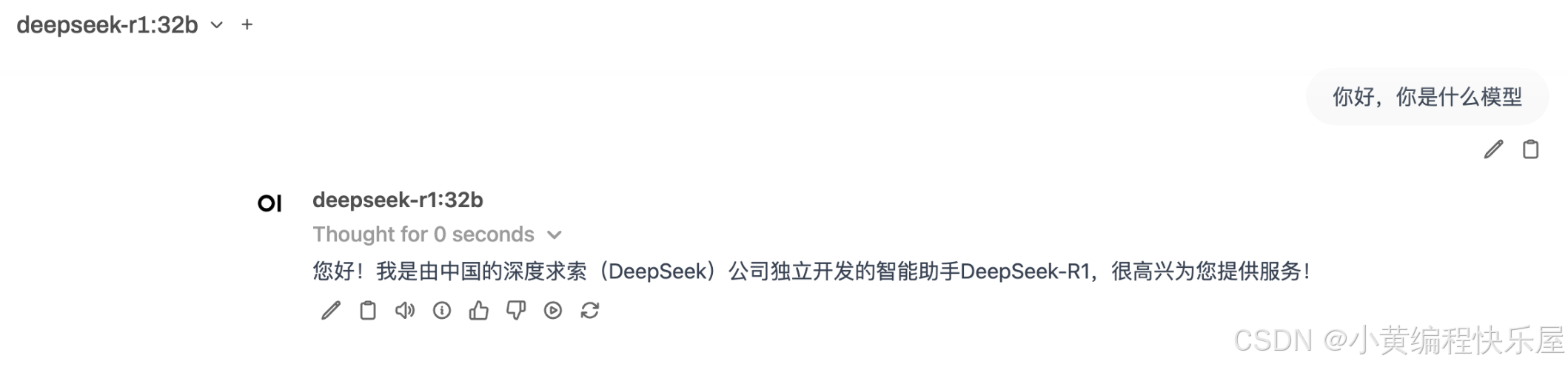
三、使用ollama部署deepSeek
登陆平台后选择对应的模型进行部署


1. 运行 Ollama
ollama serve
2.运行模型(可选)
B的意思是10亿,32b表示运行有320亿参数的deepSeek模型。这个模型对于我们的日常使用已经基本够了。
ollama run deepseek-r1:32b
3.使用web前端页面访问
进行上面的运行,我们其实已经可以使用deepseek模型了,但是只能在命令行中使用,这样使用起来不是很舒服,平台也很贴心的提供了前端WebUi。
启动 Open WebUI 服务,指定端口和主机:
open-webui serve --port 6080 --host 0.0.0.0
4. 用户名和密码设置
在启动 Open WebUI 后,您需要设置用户名和密码。请按以下步骤进行设置:
- 创建用户名和密码,均设置为
123。邮箱为:pony@123.com
这样我们就已经部署了一个我们自己的deepseek大模型了;大家直接向deepseek提问生成一个自动采集油猴脚本。然后再根据测试效果去修正即可。
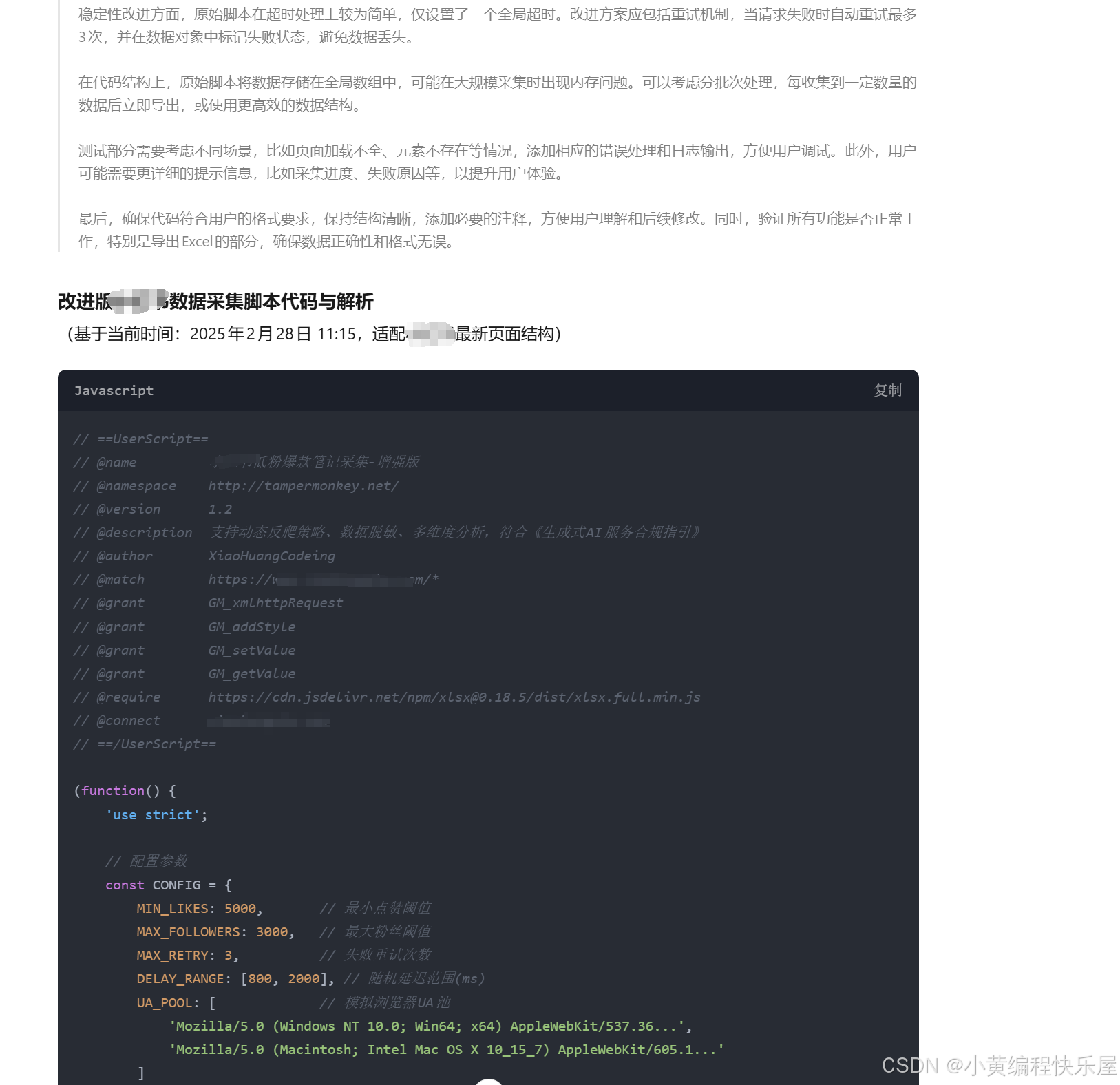
最终生成的效果脚本就是我们上面介绍的脚本。
认知易,行动难,大家快去体验一下吧!当下,为回馈广大用户,特别为高校师生与企业人员带来了一份贴心福利。参与体验,即可享受 95 折的优惠,还能获得 10 元赠金。此外,更有 4090 显卡免费使用一整天的机会,期待能为大家带来更优质的体验!

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 21
21 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)