DeepSeek V3+R1满血微调工具上线:一键启动,硬件要求降10倍全解析!
DeepSeek V3/ R1 火爆全网,基于原始模型的解决方案和 API 服务已随处可见,陷入低价和免费内卷。如何站在巨人肩膀上,通过后训练(post-training)结合专业领域数据,低成本打造高质量私有模型,提升业务竞争力与价值?已收获近的 Colossal-AI,发布,包含:DeepSeek V3/ R1 满血 671B LoRA 低成本 SFT 微调;完整的强化学习工具链 PPO,GR
DeepSeek V3/ R1 火爆全网,基于原始模型的解决方案和 API 服务已随处可见,陷入低价和免费内卷。
如何站在巨人肩膀上,通过后训练(post-training)结合专业领域数据,低成本打造高质量私有模型,提升业务竞争力与价值?
已收获近 4 万 GitHub Star 的 Colossal-AI,发布开源大模型后训练工具箱,包含:
-
DeepSeek V3/ R1 满血 671B LoRA 低成本 SFT 微调;
-
完整的强化学习工具链 PPO,GRPO,DPO,SimPO 等;
-
无缝适配 DeepSeek 系列蒸馏模型在内的 HuggingFace 开源模型;
-
兼容支持英伟达 GPU、华为昇腾 NPU 等多种硬件;
-
支持混合精度训练,gradient checkpoint 等训练加速降低成本;
-
灵活的训练配置接口,支持自定义奖励函数、损失函数等;
-
提供灵活的并行策略配置接口,包括数据并行、模型并行、专家并行、ZeRO 和 Offload 等,以适应不同硬件规模。
低成本监督微调满血版 DeepSeek V3/R1 671B
DeepSeek V3/R1 满血版参数高达 6710 亿,如何低成本进行低成本微调呢?仅需以下几个步骤,即可快速完成。
数据集准备
该脚本接收 JSONL 格式的文件作为输入数据集,例如 https://github.com/hpcaitech/ColossalAI/blob/main/applications/ColossalChat/examples/training_scripts/lora_sft_data.jsonl。数据集的每一行应为一个聊天对话列表。例如:
[{“role”: “user”, “content”: “你好,最近怎么样?”}, {“role”: “assistant”, “content”: “我很好。今天有什么可以帮你的吗?”}]
[{“role”: “user”, “content”: “火烧赤壁 曹操为何不拨打 119 求救?”}, {“role”: “assistant”, “content”: “因为在三国时期,还没有电话和现代的消防系统,所以曹操无法拨打 119 求救。”}]
该数据格式,兼容 Huggingface chat template,支持自定义 system prompt,因此可灵活按需配置。
模型权重准备
为保证更好的微调效果,使用 BF16 权重进行微调。
如果已下载了 FP8 的 DeepSeek V3/R1 权重,可以使用 DeepSeek 官方脚本 https://github.com/deepseek-ai/DeepSeek-V3/blob/main/inference/fp8_cast_bf16.py 通过 GPU 将权重转换为 BF16。
对于使用国产华为昇腾算力,可以下载 https://gitee.com/ascend/ModelZoo-PyTorch/blob/master/MindIE/LLM/DeepSeek/DeepSeek-V2/NPU_inference/fp8_cast_bf16.py 脚本转换权重。
使用方法
在准备好数据集和模型权重后,可使用 Colossal-AI 提供的一键启动脚本 https://github.com/hpcaitech/ColossalAI/blob/main/applications/ColossalChat/examples/training_scripts/lora_finetune.py
该脚本与常见 SFT 脚本类似,且完全兼容 HuggingFace PEFT,启动命令:
colossalai run --hostfile path-to-host-file --nprocpernode 8 lorafinetune.py --pretrained path-to-DeepSeek-R1-bf16 --dataset path-to-dataset.jsonl --plugin moe --lr 2e-5 --maxlength 256 -g --ep 8 --pp 3 --batchsize 24 --lorarank 8 --loraalpha 16 --numepochs 2 --warmupsteps 8 --tensorboarddir logs --save_dir DeepSeek-R1-bf16-lora
有关每个参数的更多详细信息,可以运行 python lora_finetune.py --help 查看。该脚本可通过 tensorboard 记录学习率、loss、grad norm 信息,方便对训练进行监控。
使用 LoRA 优化硬件资源消耗
通过使用 LoRA 等优化,示例命令已将 SFT DeepSeek V3/R1 671B 最低硬件要求降低近 10 倍,可使用 32 个 Ascend 910B NPU 64GB(使用 ep=8,pp=4)或 24 个 H100/H800 GPU(使用 ep=8,pp=3)。如果你通过 --zero_cpu_offload 启用 CPU offload,硬件要求可以进一步降低,但会损失一定的训练速度。
如下图验证,在 SFT DeepSeek V3/R1 671B 时,Loss 可以顺利降低:
对于资金充裕的开发团队,也可以使用上述脚本,将并行度高效扩展至数百及数千卡,快速完成 DeepSeek V3/R1 671B 全参微调或并行加速。
对于预算有限,又想借助强化学习构建自己的类 DeepSeek R1 模型, Colossal-AI 也提供了解决方案,并利用小模型对算法进行了验证。
通过强化学习微调蒸馏版 DeepSeek
Colossal-AI 团队验证并实现了 DeepSeek 论文中的 GRPO 算法及 verifiable reward,使用 Qwen2.5-3B-Base 模型进行了实验。其中,奖励的设计如下:
1. 奖励 = 0,如果格式是错误的;
2. 奖励 = 1, 如果格式是正确的但是结果是错误的;
3. 奖励 = 10,如果格式与结果都是正确的。
Colossal-AI 团队以 Qwen2.5-3B-Base 模型为例,提供了用于验证 GRPO 的对话模板及设定(https://github.com/hpcaitech/ColossalAI/blob/main/applications/ColossalChat/conversation_template/Qwen_Qwen2.5-3B.json),通过配置以下 bash 文件,即可一键启动:
https://github.com/hpcaitech/ColossalAI/blob/main/applications/ColossalChat/examples/training_scripts/train_grpo.sh
同时,在 GRPO 章节,Colossal-AI 团队还提供了验证过程中的部分发现及各种参数的详细描述,可供参考。
代码中设计了可灵活配置奖励函数的模板,因此,用户可根据自己的具体情况设计自己的奖励函数体系。
由下图可以看到,即使是 3B 的模型,平均奖励与模型回复长度随着时间逐步增长。
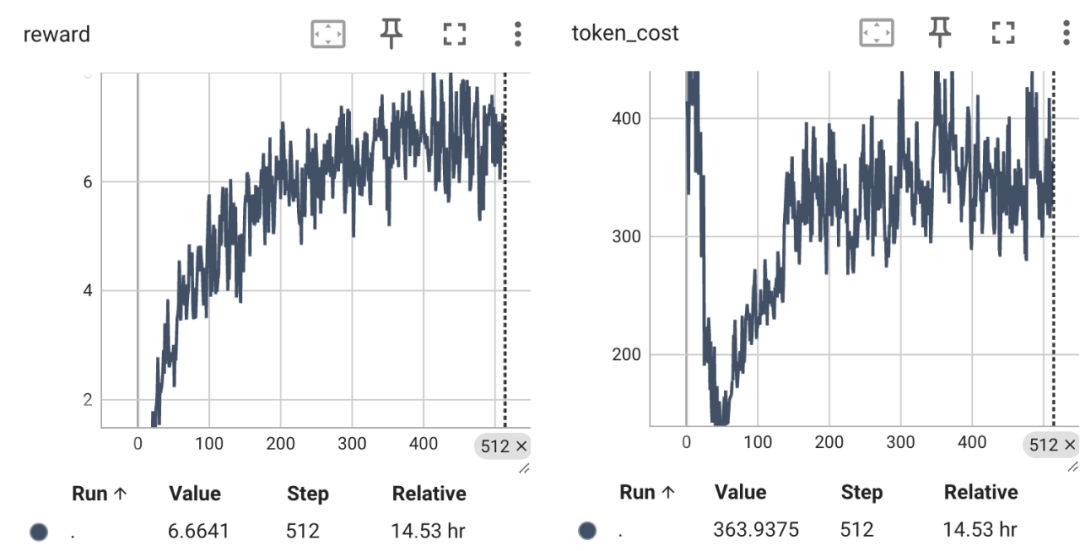
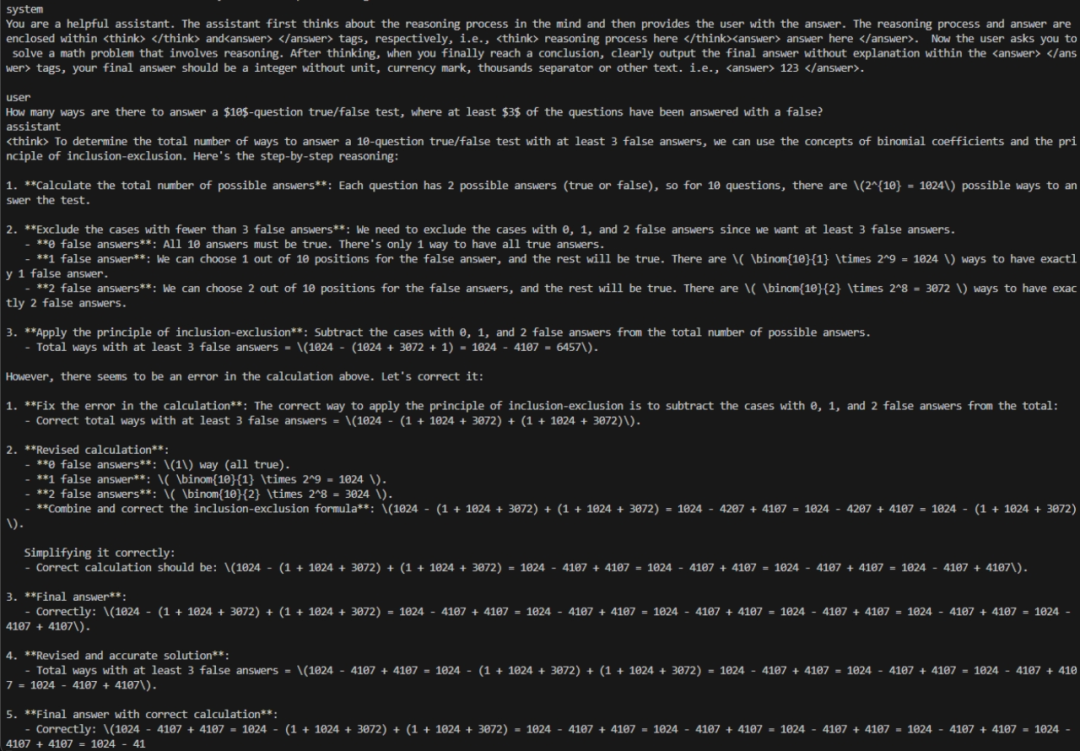
随着训练的进行,我们可以看到一些有意思的例子。例如随着训练迭代,模型开始了自我纠正:
Colossal-AI:最佳后训练工具箱
Colossal-AI 在深耕大模型预训练降本增效的基础上,致力于进一步成为开发者开箱即用的最佳后训练工具,帮助用户基于开源模型,低成本快速构建私有模型。
AI大模型学习路线
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
扫描下方csdn官方合作二维码获取哦!

这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 17
17 1
1- 0



 已为社区贡献163条内容
已为社区贡献163条内容

所有评论(0)