Spring AI应用:利用DeepSeek+嵌入模型+Milvus向量数据库实现检索增强生成--RAG应用(一)(超详细)
检索增强生成(Retrieval-Augmented Generation,RAG)是一种结合了检索和生成模型的方法,旨在提高生成模型在问答等任务中的效果。RAG模型由一个检索器和一个生成器组成,检索器用于从大规模文本库中检索相关信息,然后将这些信息传递给生成器来生成回答或解释。RAG模型结合了检索的准确性和生成的灵活性,旨在解决传统生成模型在生成长文本、知识推理等方面的不足之处。通过在生成过程中
目录
引言
随着人工智能技术的迅速发展,企业越来越关注如何利用先进的技术来提升自身的竞争力。在这个背景下,构建私有化RAG(检索增强生成)应用成为企业追求的目标之一。借助Spring AI、DeepSeek+嵌入模型和Milvus向量数据库,企业可以实现更为精准和高效的文本检索和生成,从而提升工作效率和用户体验。本文将探讨如何利用这些技术组件搭建私有化RAG应用,帮助企业在竞争激烈的市场中脱颖而出。
一、什么是RAG?
检索增强生成(Retrieval-Augmented Generation,RAG)是一种结合了检索和生成模型的方法,旨在提高生成模型在问答等任务中的效果。RAG模型由一个检索器和一个生成器组成,检索器用于从大规模文本库中检索相关信息,然后将这些信息传递给生成器来生成回答或解释。
RAG模型结合了检索的准确性和生成的灵活性,旨在解决传统生成模型在生成长文本、知识推理等方面的不足之处。通过在生成过程中利用检索到的信息,RAG能够生成更加准确和丰富的文本,并在问答任务中取得更好的效果。
总的来说,RAG模型是一种新颖的生成模型,能够有效利用检索信息来提升生成任务的表现。
二、如何实现RAG应用
1. 数据准备与知识库构建
-
目标:构建用于检索的外部知识库。
-
关键步骤:
-
数据收集:根据应用场景收集文档、网页、数据库等结构化或非结构化数据。
-
示例:医疗问答需收集医学文献、药品说明书等。
-
-
数据预处理:
-
分块(Chunking):将长文本切分为小片段。
-
清洗:去重、过滤噪音(如广告文本)。
-
向量化:将文本转换为向量(如使用nomic-embed-text、bge-m3)。
-
-
存储:
-
使用向量数据库(如FAISS、Pinecone、Milvus)存储向量化后的文本片段,加速检索。
-
传统数据库(如Elasticsearch、Mongodb)也可用于关键词检索。
-
-
2. 检索模型实现
-
目标:根据用户输入,从知识库中检索最相关的文本片段。
-
方法:
1、将用户输入的问题文本向量化。
2、使用向量数据库的向量检索相关文本片段。
3、提取相关的文本片段组装到聊天上下文。
3. 生成模型实现
-
目标:结合检索结果和用户输入,生成最终回答。
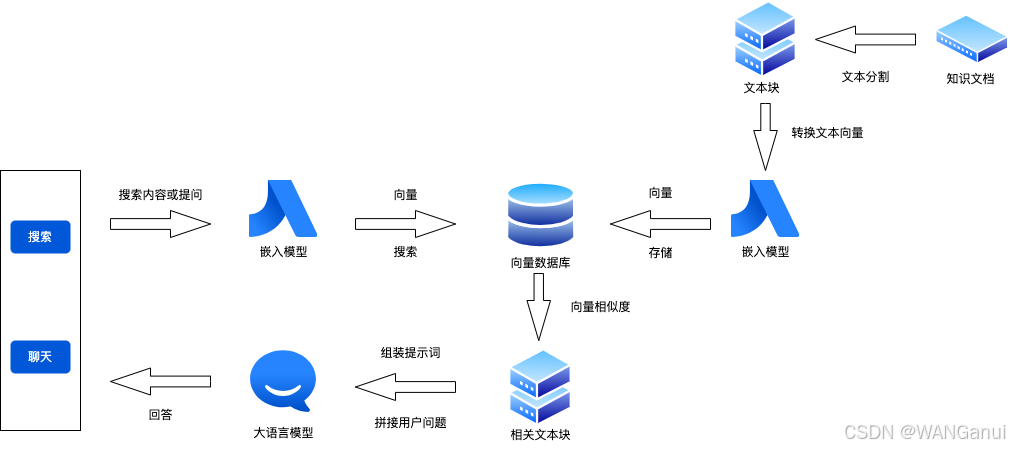
一张图了解RAG应用的基本实现逻辑。
三、 技术环境
Java环境:jdk17、Spring boot 3.x、Spring AI
大语言模型:基于Ollama的deepseek-r1
文本嵌入模型:基于Ollama的nomic-embed-text
向量数据库:Milvus | 高性能向量数据库,为规模而构建
本文前置条件
1、本地已安装大语言模型以及文本嵌入模型,如未安装请参照利用Ollama部署DeepSeek本地模型:从入门到实践_ollama deepseek modelfile-CSDN博客
2、已搭建基于Spring AI的Spring boot 后端项目,如未实现请参照
Spring AI进阶:使用DeepSeek本地模型搭建AI聊天机器人(一)_spring-ai 本地 deepseek-CSDN博客
3、已安装Docker环境。
四、什么是向量数据库?
在人工智能时代,向量数据库已成为数据管理和AI模型不可或缺的一部分。向量数据库是一种专门设计用来存储和查询向量嵌入数据的数据库。这些向量嵌入是AI模型用于识别模式、关联和潜在结构的关键数据表示。随着AI和机器学习应用的普及,这些模型生成的嵌入包含大量属性或特征,使得它们的表示难以管理。这就是为什么数据从业者需要一种专门为处理这种数据而开发的数据库,这就是向量数据库的用武之地。
以下是目前市面上较为流行的向量数据库,这里做一个简单的对比介绍
| 特性/数据库 | Pinecone | MongoDB | Milvus | Chroma | Weaviate | Elasticsearch |
|---|---|---|---|---|---|---|
| 开源情况 | 闭源 | 开源 (25.2k stars) | 开源 (21.1k stars) | 开源 (7k stars) | 开源 (6.7k stars) | 开源 (64.4k stars) |
| 数据处理类型 | 向量数据 | 多种事务性和向量搜索 | 向量嵌入 | 嵌入式向量 | 向量数据 | 文本、数值、地理等多种数据类型 |
| 搜索速度 | 快速搜索 | 高效搜索 | 毫秒级搜索万亿级数据集 | 快速 | 毫秒内完成10-NN搜索 | 快速搜索,支持大规模扩展 |
| 主要应用案例 | AI解决方案 | 复杂数据管理任务 | 图像搜索、聊天机器人等 | LLM应用程序 | 文本、照片等转换为向量 | 文本、日志分析等 |
| 关键特性 | 简单API, 无需基础设施 | 集成数据库+向量搜索能力 | 统一用户体验, 弹性 | 支持查询、过滤等功能 | 云原生, 分布式 | 分布式架构, 自动恢复 |
| 其他特性 | 重复检测, 排名跟踪 | 数据存储高达16 MB, 加密 | Lambda结构, 社区支持 | LangChain, LlamaIndex支持 | 支持OpenAI等服务 | 跨数据中心复制 |
本期我们采用Milvus的单机版给大家做演示,Milvus文档:Milvus 向量数据库文档
特点:
- Milvus是一个开源的向量数据库,旨在促进向量嵌入、高效相似搜索和AI应用。它于2019年10月以开源Apache 2.0许可证发布,目前是LF AI & Data Foundation赞助的毕业项目。
- 该工具简化了非结构化数据的搜索,并提供了与部署环境无关的统一用户体验。为了提高弹性和适应性,Milvus 2.0重构版本中的所有组件都是无状态的。
- Milvus的应用案例包括图像搜索、聊天机器人和化学结构搜索。
Milvus的关键特性:
- 毫秒级搜索万亿级向量数据集
- 简单管理非结构化数据
- 可靠的向量数据库,始终可用
- 高度可扩展和适应性强
- 混合搜索
- 统一的Lambda结构
- 受到社区支持,得到行业认可
Milvus 提供三种部署模式,涵盖各种数据规模--从 Jupyter Notebooks 中的本地原型到管理数百亿向量的大规模 Kubernetes 集群:
- Milvus Lite 是一个 Python 库,可以轻松集成到您的应用程序中。作为 Milvus 的轻量级版本,它非常适合在 Jupyter Notebooks 中进行快速原型开发,或在资源有限的边缘设备上运行。了解更多信息。
- Milvus Standalone 是单机服务器部署,所有组件都捆绑在一个 Docker 镜像中,方便部署。了解更多。
- Milvus Distributed 可部署在 Kubernetes 集群上,采用云原生架构,专为十亿规模甚至更大的场景而设计。该架构可确保关键组件的冗余。了解更多。
五、安装Milvus
Milvus 提供了一个安装脚本,可将其安装为 docker 容器。该脚本可在Milvus 存储库中找到。要在 Docker 中安装 Milvus,只需运行
curl -sfL https://raw.githubusercontent.com/milvus-io/milvus/master/scripts/standalone_embed.sh -o standalone_embed.sh
bash standalone_embed.sh start
注意如果docker官方镜像可能下载速度较慢,可以用国内的镜像源站点,贴出我自己用的,大家可以参考一下
"registry-mirrors": [
"https://0vrv861z.mirror.aliyuncs.com",
"http://hub-mirror.c.163.com",
"https://docker.mirrors.ustc.edu.cn",
"https://registry.docker-cn.com",
"https://2a6bf1988cb6428c877f723ec7530dbc.mirror.swr.myhuaweicloud.com",
"https://docker.m.daocloud.io",
"https://hub-mirror.c.163.com",
"https://mirror.baidubce.com",
"https://your_preferred_mirror",
"https://dockerhub.icu",
"https://docker.registry.cyou",
"https://docker-cf.registry.cyou",
"https://dockercf.jsdelivr.fyi",
"https://docker.jsdelivr.fyi",
"https://dockertest.jsdelivr.fyi",
"https://mirror.aliyuncs.com",
"https://dockerproxy.com",
"https://mirror.baidubce.com",
"https://docker.m.daocloud.io",
"https://docker.nju.edu.cn",
"https://docker.mirrors.sjtug.sjtu.edu.cn",
"https://docker.mirrors.ustc.edu.cn",
"https://mirror.iscas.ac.cn",
"https://docker.rainbond.cc"
]安装完成后如下图显示则安装成功
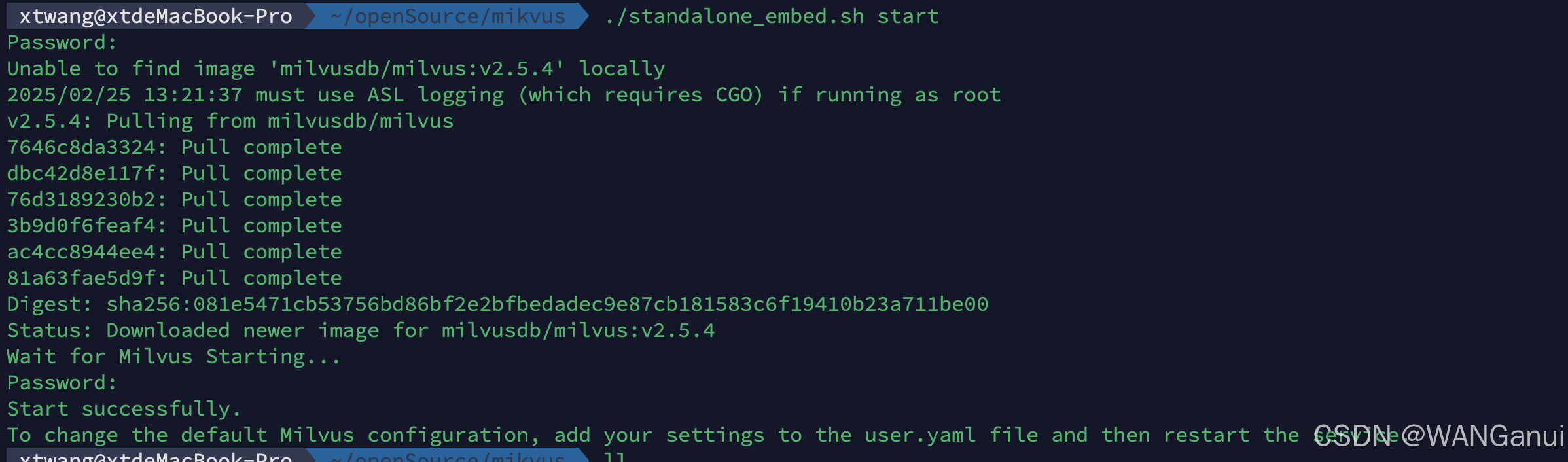
运行安装脚本后
- 一个名为 Milvus 的 docker 容器已在19530 端口启动。
- 嵌入式 etcd 与 Milvus 安装在同一个容器中,服务端口为2379。它的配置文件被映射到当前文件夹中的embedEtcd.yaml。
- 要更改 Milvus 的默认配置,请将您的设置添加到当前文件夹中的user.yaml文件,然后重新启动服务。
- Milvus 数据卷被映射到当前文件夹中的volumes/milvus。
你可以访问 Milvus WebUI,网址是http://127.0.0.1:9091/webui/ ,了解有关 Milvus 实例的更多信息。有关详细信息,请参阅Milvus WebUI。
六、Spring boot集成Milvus
1、在项目pom.xml中添加Spring AI 下的Milvus的依赖项
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-milvus-store</artifactId>
</dependency>2、application.yml中增加Milvus连接配置
# Milvus配置
milvus:
host: 127.0.0.1
port: 195303、新建MilvusConfig类,配置数据库连接客户端
package com.wanganui.vector.config;
import io.milvus.client.MilvusServiceClient;
import io.milvus.param.ConnectParam;
import io.milvus.v2.client.ConnectConfig;
import io.milvus.v2.client.MilvusClientV2;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @author xtwang
* @des Milvus向量数据库配置
* @date 2025/2/25 下午2:33
*/
@Configuration
public class MilvusConfig {
@Value("${milvus.host}")
private String host;
@Value("${milvus.port}")
private Integer port;
@Bean
public MilvusClientV2 milvusClientV2() {
String uri = "http://" + this.host + ":" + this.port.toString();
return new MilvusClientV2(ConnectConfig.builder().uri(uri).build());
}
@Bean
public MilvusServiceClient milvusServiceClient() {
ConnectParam connectParam = ConnectParam.newBuilder()
.withHost(host)
.withPort(port)
.build();
return new MilvusServiceClient(connectParam);
}
}
可以看到我这里配置了两个客户端,分别是MilvusServiceClient、MilvusClientV2,原因是Spring AI 集成了较早的Milvus,导致在Spring AI与Milvus交互时需要使用旧版的客户端,而MilvusClientV2是Milvus当前推荐使用的,包含一些较新的API。
基于上述步骤已成功在Spring Boot 应用中集成了Milvus向量数据库。
七、配置嵌入模型
如果不清楚如何下载嵌入模型,请参考此文档:使用Dify搭建DeepSeek本地知识库_dify deepseek-CSDN博客
application.yml中增加嵌入模型相关配置
spring:
# 添加Spring AI Ollama相关配置
ai:
ollama:
base-url: http://localhost:11434
# 聊天模型配置
chat:
options:
model: deepseek-r1:7b
temperature: 0.7
num-g-p-u: 1
# 嵌入模型配置
embedding:
options:
model: nomic-embed-text:latest八、Milvus实践
在上述操作完成后,我们来简单学习一下Milvus向量数据库的一些基本知识,详细说明请查看官方文档:Milvus 向量数据库文档。
1、数据库
与传统数据库引擎类似,您也可以在 Milvus 中创建数据库,并为某些用户分配管理这些数据库的权限。然后,这些用户就有权管理数据库中的 Collections。一个 Milvus 集群最多支持 64 个数据库。
2、Collections集合
在 Milvus 中,您可以创建多个 Collections 来管理数据,并将数据作为实体插入到 Collections 中。Collections 和实体类似于关系数据库中的表和表数据。
3、Schema 字段模式
字段模式是字段的逻辑定义。在定义集合模式和管理集合之前,首先需要定义它。Milvus 只支持在一个 Collection 中使用一个主键字段。
字段模式属性
| 属性 | 说明 | 说明 |
|---|---|---|
name |
要创建的 Collection 中字段的名称 | 数据类型: 必填 |
dtype |
字段的数据类型 | 必须填写 |
description |
字段描述 | 数据类型: 字符串: 可选 |
is_primary |
是否将字段设为主键字段 | 数据类型:布尔 ( 或 ):布尔型 (true 或false)。主键字段必须设置 |
auto_id (主键字段必须) |
启用或禁用自动 ID(主键)分配的开关。 | True 或False |
max_length (对 VARCHAR 字段必填) |
允许插入字符串的最大字节长度。请注意,多字节字符(如 Unicode 字符)可能占用一个以上的字节,因此请确保插入字符串的字节长度不超过指定的限制。 | [1, 65,535] |
dim |
向量的维数 | 数据类型:整数∈[1, 32768]。 密集向量场必须使用。稀疏向量场省略。 |
is_partition_key |
该字段是否为 Partition Key 字段。 | 数据类型:布尔类型 (true 或false)。 |
4、向量索引
利用存储在索引文件中的元数据,Milvus 以专门的结构组织数据,便于在搜索或查询过程中快速检索所需的信息。
Milvus 提供多种索引类型和指标,可对字段值进行排序,以实现高效的相似性搜索。下表列出了不同向量字段类型所支持的索引类型和度量。目前,Milvus 支持各种类型的向量数据,包括浮点嵌入(通常称为浮点向量或密集向量)、二进制嵌入(也称为二进制向量)和稀疏嵌入(也称为稀疏向量)。
| 度量类型 | 索引类型 |
|---|---|
|
|
度量类型说明:
-
L2(欧氏距离, Euclidean Distance):
- 计算两个向量之间的直线距离。
- 适用于那些希望找到与查询向量在空间中物理距离最近的点的场景。
- 当你的数据经过了归一化处理时,L2可能不是最佳选择,因为此时余弦相似度可能是更合适的度量。
-
IP(内积, Inner Product):
- 计算两个向量的内积。
- 常用于向量已经过归一化处理的情况,此时内积的值与余弦相似度成正比。
- 适合需要衡量向量方向相似性而非大小差异的应用场景。
-
COSINE(余弦相似度, Cosine Similarity):
- 计算两个向量夹角的余弦值。
- 特别适用于比较文档、词汇等高维度稀疏数据,因为它关注的是向量的方向而非幅度。
- 在文本挖掘、信息检索等领域非常有用,因为它能够忽略向量长度的影响,专注于方向上的相似性。
选择哪种度量类型主要取决于你的应用需求和数据特点。例如,在图像检索或推荐系统中,可能会根据具体情况选择L2或IP作为度量类型;而在文本分析中,余弦相似度往往是首选。理解你所处理的数据性质以及想要解决的问题,对于选择正确的度量类型至关重要。此外,不同度量类型的性能也可能因具体实现和优化而异,因此在实际部署前进行适当的测试是很重要的。
索引类型说明:
-
平面(FLAT):
- 不使用任何索引结构,提供精确搜索结果。
- 适用于数据量较小或对检索精度要求极高的情况。
-
IVF_FLAT:
- 倒排文件(Inverted File)结构的基础版本,通过聚类将向量分配到不同的桶中以加速搜索。
- 适合需要在大规模数据集中进行高效搜索但可以接受一定精度损失的情况。
-
IVF_SQ8:
- 在IVF的基础上采用标量量化(Scalar Quantization),将浮点数压缩为8位整数,减少存储空间并加快查询速度,但会带来一定的精度损失。
- 适用于希望节省存储空间且对搜索速度有较高要求的场景。
-
IVF_PQ:
- 使用乘积量化(Product Quantization)进一步压缩向量表示,非常适合处理非常大的数据集。
- 对于那些资源受限环境下的应用来说是个很好的选择,如移动设备、边缘计算等。
-
GPU_IVF_FLAT:
- 利用GPU加速的IVF_FLAT索引类型,可显著提升构建索引和查询的速度。
- 适用于拥有高性能GPU硬件资源,并需要快速处理大规模数据集的场合。
-
GPU_IVF_PQ:
- 结合了GPU加速与乘积量化技术,提供了更高的性能优势,特别是在处理超大规模数据时。
- 同样需要具备相应的GPU硬件支持,适用于对速度和效率有极高要求的应用。
-
HNSW (Hierarchical Navigable Small World graphs):
- 基于层次化可导航小世界网络的索引结构,能够提供快速而准确的最近邻搜索。
- 非常适合实时性要求高、需要快速响应的在线服务和应用场景。
-
DISKANN:
- 一种专门设计用于处理超大规模数据集的索引类型,能够在磁盘上有效地存储和搜索向量数据。
- 适用于数据量极大以至于无法完全加载进内存的情况,旨在平衡查询效率与存储成本。
选择合适的索引类型主要取决于你的具体需求,包括数据规模、查询速度要求、存储限制以及是否愿意接受一定程度的查询精度损失等因素。根据不同的应用场景,可能需要进行适当的测试和调优来确定最佳配置。
5、实践
在理解了Milvus的基本知识后,接下来我们通过代码实践一下Milvus的一些基本操作。
5.1创建集合
第一步:新建一个MilvusArchive类,用于管理向量数据库的基本配置以及一些表结构配置,具体代码如下:
package com.wanganui.vector.config;
/**
* @author xtwang
* @des Milvus 向量数据库业务参数
* @date 2025/2/25 下午2:54
*/
public class MilvusArchive {
/**
* 向量数据库名称
*/
public static final String DB_NAME = "default";
/**
* 集合名称
*/
public static final String COLLECTION_NAME = "rag_collection";
/**
* 分片数量
*/
public static final int SHARDS_NUM = 1;
/**
* 分区数量
*/
public static final int PARTITION_NUM = 1;
/**
* 特征向量维度
*/
public static final Integer FEATURE_DIM = 768;
/**
* 字段
*/
public static class Field {
/**
* id
*/
public static final String ID = "id";
/**
* 文本特征向量
*/
public static final String FEATURE = "feature";
/**
* 文本
*/
public static final String TEXT = "text";
/**
* 文件名
*/
public static final String FILE_NAME = "file_name";
/**
* 元数据
*/
public static final String METADATA = "metadata";
}
}
为了实现私有化知识库,我们在集合里设计了5个字段,分别是ID、特征向量、原始文本、上传的文件名、原始文本的元数据。
第二步:新建一个MilvusService接口,并定义一个hasCollection的抽象接口,用于校验集合是否存在,不存在则创建集合,具体代码如下:
package com.wanganui.vector.service;
import io.milvus.v2.service.vector.response.InsertResp;
import io.milvus.v2.service.vector.response.QueryResp;
import io.milvus.v2.service.vector.response.SearchResp;
import org.springframework.ai.document.Document;
import org.springframework.ai.vectorstore.SearchRequest;
import java.util.List;
/**
* @author xtwang
* @des Milvus服务接口
* @date 2025/2/25 下午3:09
*/
public interface MilvusService {
/**
* 检查集合是否存在,不存在则创建集合
*/
void hasCollection();
}
再创建一个MilvusServiceImpl的实现类来实现MilvusService的接口,具体代码如下:
package com.wanganui.vector.service;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.google.gson.Gson;
import com.google.gson.JsonObject;
import com.wanganui.vector.config.MilvusArchive;
import io.milvus.v2.client.MilvusClientV2;
import io.milvus.v2.common.DataType;
import io.milvus.v2.common.IndexParam;
import io.milvus.v2.service.collection.request.*;
import io.milvus.v2.service.index.request.CreateIndexReq;
import io.milvus.v2.service.vector.request.DeleteReq;
import io.milvus.v2.service.vector.request.InsertReq;
import io.milvus.v2.service.vector.request.QueryReq;
import io.milvus.v2.service.vector.request.SearchReq;
import io.milvus.v2.service.vector.request.data.FloatVec;
import io.milvus.v2.service.vector.response.InsertResp;
import io.milvus.v2.service.vector.response.QueryResp;
import io.milvus.v2.service.vector.response.SearchResp;
import jakarta.annotation.PostConstruct;
import lombok.RequiredArgsConstructor;
import org.apache.commons.lang3.StringUtils;
import org.springframework.ai.document.Document;
import org.springframework.ai.document.DocumentMetadata;
import org.springframework.ai.ollama.OllamaEmbeddingModel;
import org.springframework.ai.vectorstore.SearchRequest;
import org.springframework.stereotype.Service;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
import java.util.List;
/**
* @author xtwang
* @des MilvusServiceImpl
* @date 2025/2/25 下午3:10
*/
@Service
@RequiredArgsConstructor
public class MilvusServiceImpl implements MilvusService {
private final MilvusClientV2 milvusClientV2;
private final OllamaEmbeddingModel ollamaEmbeddingModel;
/**
* 检查集合是否存在
*/
@Override
public void hasCollection() {
Boolean b = milvusClientV2.hasCollection(HasCollectionReq.builder().collectionName(MilvusArchive.COLLECTION_NAME).build());
if (!b) {
this.createCollection();
}
}
/**
* 创建集合
*/
public void createCollection() {
// 创建字段
CreateCollectionReq.CollectionSchema schema = milvusClientV2.createSchema()
// 创建主键字段
.addField(AddFieldReq.builder()
// 字段名
.fieldName(MilvusArchive.Field.ID)
// 字段描述
.description("主键ID")
// 字段类型
.dataType(DataType.Int64)
// 是否为主键
.isPrimaryKey(true)
// 设置主键自增
.autoID(true)
.build())
.addField(AddFieldReq.builder()
// 字段名
.fieldName(MilvusArchive.Field.FILE_NAME)
// 字段描述
.description("文件名")
// 字段类型
.dataType(DataType.VarChar)
// 设置字段为可空
.isNullable(true)
.build())
// 创建特征向量字段
.addField(AddFieldReq.builder()
// 字段名
.fieldName(MilvusArchive.Field.FEATURE)
// 字段描述
.description("特征向量")
// 字段类型
.dataType(DataType.FloatVector)
// 设置向量维度
.dimension(MilvusArchive.FEATURE_DIM)
.build())
.addField(AddFieldReq.builder()
// 字段名
.fieldName(MilvusArchive.Field.TEXT)
// 字段描述
.description("文本")
// 字段类型
.dataType(DataType.VarChar)
// 设置字段为可空
.isNullable(true)
.build())
.addField(AddFieldReq.builder()
// 字段名
.fieldName(MilvusArchive.Field.METADATA)
// 字段描述
.description("元数据")
// 字段类型
.dataType(DataType.VarChar)
// 设置字段为可空
.isNullable(true)
.build());
// 创建集合
CreateCollectionReq collectionReq = CreateCollectionReq.builder()
// 集合名称
.collectionName(MilvusArchive.COLLECTION_NAME)
// 集合描述
.description("自定义知识库")
// 集合字段
.collectionSchema(schema)
// 分片数量
.numShards(MilvusArchive.SHARDS_NUM)
.build();
milvusClientV2.createCollection(collectionReq);
// 创建索引
IndexParam indexParam = IndexParam.builder()
// 索引字段名
.fieldName(MilvusArchive.Field.FEATURE)
// 索引类型
.indexType(IndexParam.IndexType.IVF_FLAT)
// 索引距离度量
.metricType(IndexParam.MetricType.COSINE)
.build();
CreateIndexReq createIndexReq = CreateIndexReq.builder()
.collectionName(MilvusArchive.COLLECTION_NAME)
.indexParams(Collections.singletonList(indexParam))
.build();
milvusClientV2.createIndex(createIndexReq);
}
}
5.2插入数据
在MilvusService类中新增一个insert()方法,并在实现类中实现新增逻辑,具体代码如下:
/**
* 插入数据
*
* @param vectorParam 向量参数
* @param text 文本
* @param metadata 元数据
* @param fileName 文件名
*/
InsertResp insert(float[] vectorParam, String text, String metadata, String fileName);/**
* 插入数据
*/
@Override
public InsertResp insert(float[] vectorParam, String text, String metadata, String fileName) {
// 校验集合是否存在
this.hasCollection();
JsonObject jsonObject = new JsonObject();
// 数组转换成JsonElement
jsonObject.add(MilvusArchive.Field.FEATURE, new Gson().toJsonTree(vectorParam));
jsonObject.add(MilvusArchive.Field.TEXT, new Gson().toJsonTree(text));
jsonObject.add(MilvusArchive.Field.METADATA, new Gson().toJsonTree(metadata));
jsonObject.add(MilvusArchive.Field.FILE_NAME, new Gson().toJsonTree(fileName));
InsertReq insertReq = InsertReq.builder()
// 集合名称
.collectionName(MilvusArchive.COLLECTION_NAME)
.data(Collections.singletonList(jsonObject))
.build();
return milvusClientV2.insert(insertReq);
}然后创建一个MilvusController类,注入OllamaEmbeddingModel、MilvusService依赖,编写一个添加自定义RAG数据的控制器,并将输入的文本通过嵌入模型转换为向量数据,将向量数据存入向量数据库。具体代码如下:
package com.wanganui.controller;
import com.alibaba.fastjson.JSON;
import com.wanganui.tika.TikaUtil;
import com.wanganui.tika.TikaVo;
import com.wanganui.vector.service.MilvusService;
import io.milvus.v2.service.vector.response.InsertResp;
import io.milvus.v2.service.vector.response.QueryResp;
import io.milvus.v2.service.vector.response.SearchResp;
import io.swagger.v3.oas.annotations.Operation;
import io.swagger.v3.oas.annotations.tags.Tag;
import lombok.RequiredArgsConstructor;
import org.springframework.ai.ollama.OllamaEmbeddingModel;
import org.springframework.http.ResponseEntity;
import org.springframework.util.Assert;
import org.springframework.web.bind.annotation.*;
import org.springframework.web.multipart.MultipartFile;
import java.util.*;
/**
* @author xtwang
* @des 向量数据库实践
* @date 2025/2/25 下午5:02
*/
@RestController
@RequestMapping("/api/vector")
@Tag(name = "向量数据库实践", description = "向量数据库实践")
@RequiredArgsConstructor
public class MilvusController {
private final OllamaEmbeddingModel ollamaEmbeddingModel;
private final MilvusService milvusService;
@Operation(summary = "添加自定义rag数据")
@GetMapping("/addCustomRagData")
public ResponseEntity<InsertResp> addCustomRagData(@RequestParam String text) {
Assert.notNull(text, "text不能为空");
float[] embed = ollamaEmbeddingModel.embed(text);
// 插入数据
InsertResp insert = milvusService.insert(embed, text, JSON.toJSONString(new HashMap<>().put("custom", text)), "custom");
return ResponseEntity.ok(insert);
}
}
完成后运行程序,测试接口是否正常
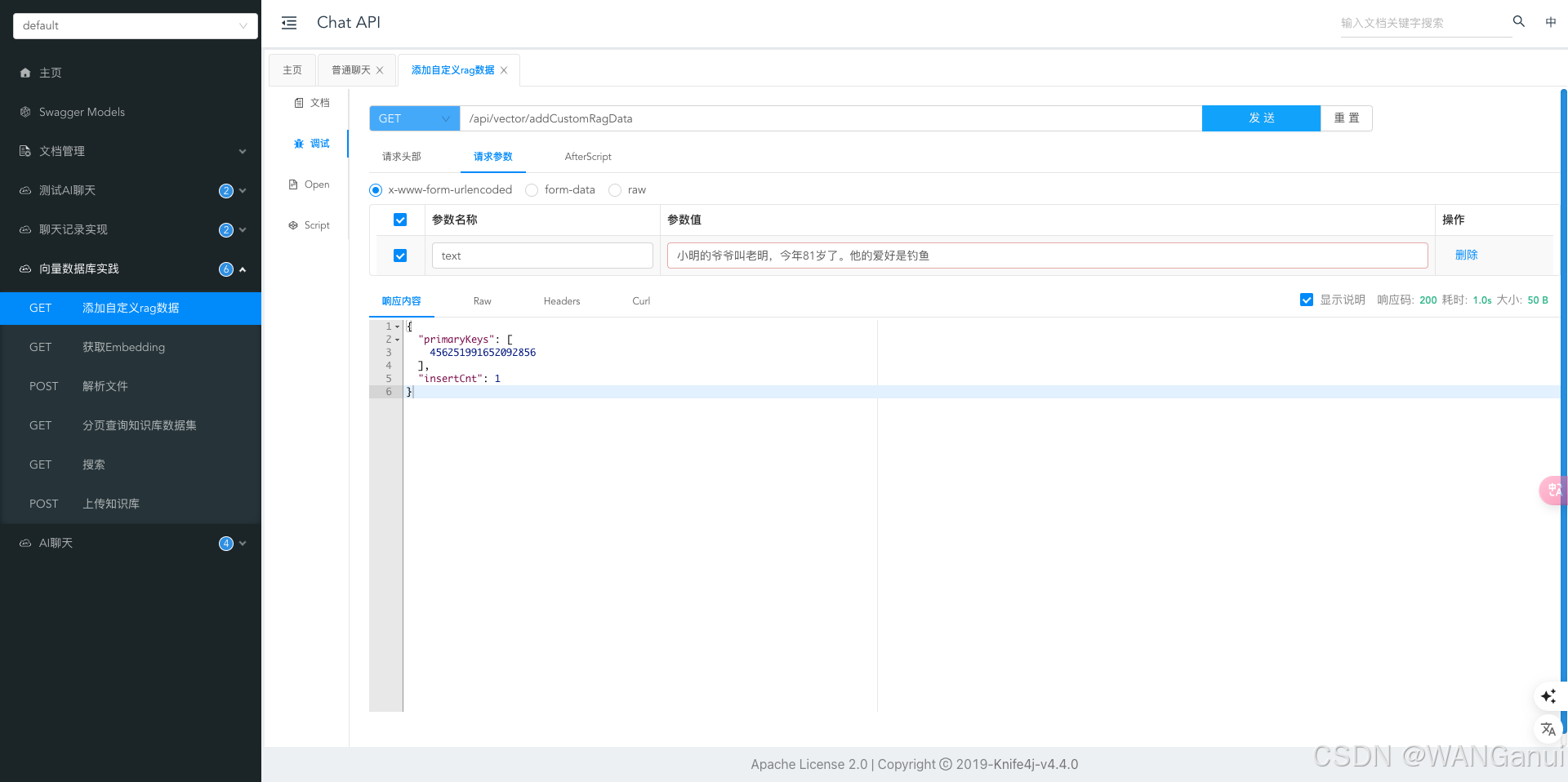
可以看到我们成功添加了一条文本数据,返回了数据的主键信息。
5.3搜索
在插入数据完成后,我们来学习如何实现数据的检索,首先在MilvusService接口内新增一个搜索的抽象接口定义,并在实现类中实现搜索逻辑。具体代码如下:
/**
* 搜索数据
*
* @param vectorParam 向量参数
*/
SearchResp search(float[] vectorParam);/**
* 搜索数据
*
* @param vectorParam 向量参数
*/
@Override
public SearchResp search(float[] vectorParam) {
this.loadCollection();
FloatVec floatVec = new FloatVec(vectorParam);
SearchReq searchReq = SearchReq.builder()
// 集合名称
.collectionName(MilvusArchive.COLLECTION_NAME)
// 搜索距离度量
.metricType(IndexParam.MetricType.COSINE)
// 搜索向量
.data(Collections.singletonList(floatVec))
// 搜索字段
.annsField(MilvusArchive.Field.FEATURE)
// 返回字段
.outputFields(Arrays.asList(MilvusArchive.Field.ID, MilvusArchive.Field.TEXT, MilvusArchive.Field.METADATA, MilvusArchive.Field.FILE_NAME))
// 搜索数量
.topK(5)
.build();
return milvusClientV2.search(searchReq);
}这里我们使用向量相似度搜索,取最相近的5条数据,并设置了基本的返回字段(注意:Milvus在搜索时需要先将集合加载到内存中)
然后在MilvusController中新增一个搜索控制器,将用户输入的搜索文本转换为密集向量数组,完成后运行程序查看搜索是否生效
@Operation(summary = "搜索")
@GetMapping("/search")
public ResponseEntity<SearchResp> search(@RequestParam String text) {
Assert.notNull(text, "text不能为空");
float[] embed = ollamaEmbeddingModel.embed(text);
// 搜索数据
return ResponseEntity.ok(milvusService.search(embed));
}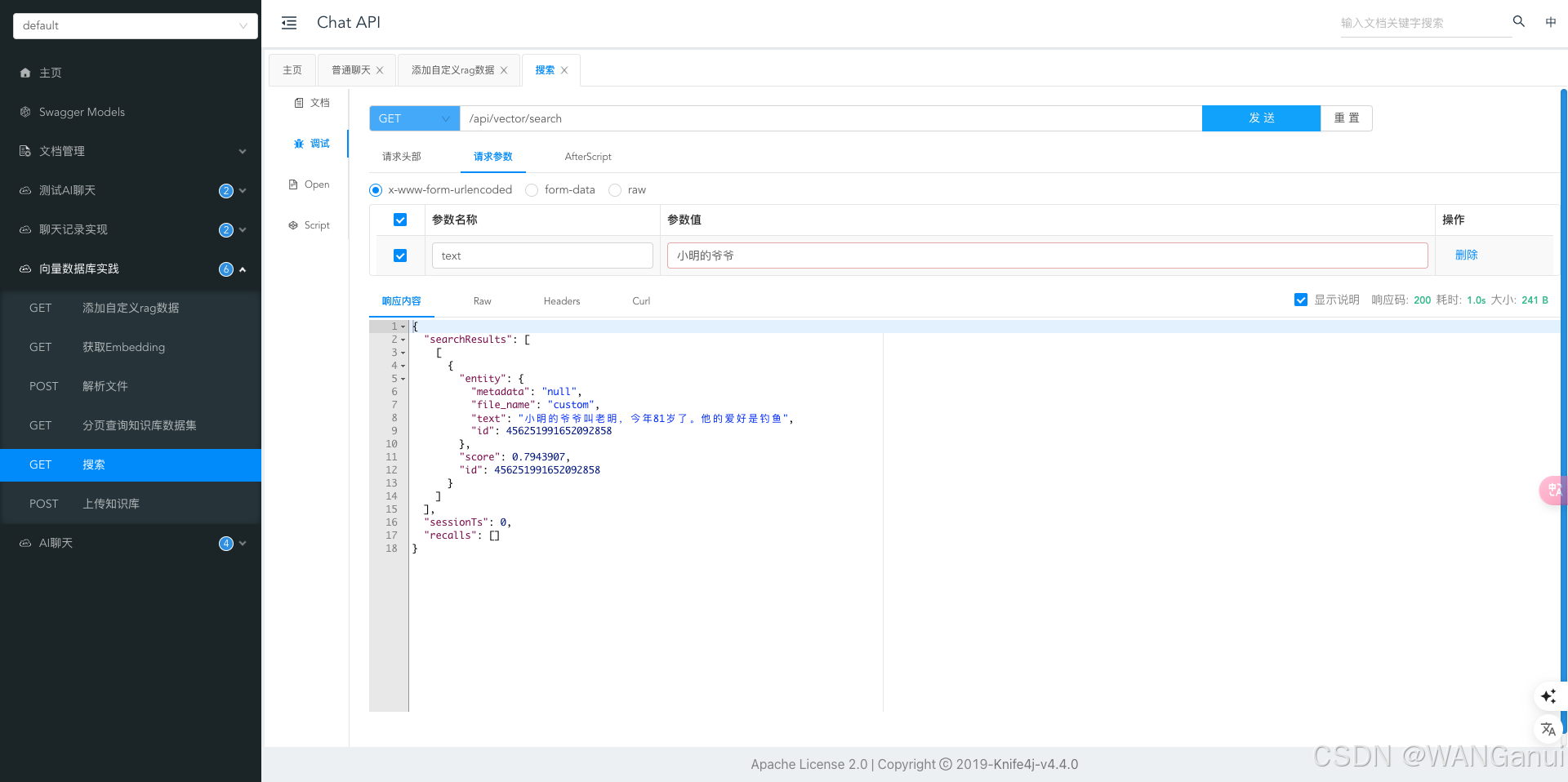
可以看到已成功搜索出了结果。
九、总结
从上述步骤可以得出一个结论,如果要实现知识库的搭建,单靠输入文本的方式还是满足不了需求,企业知识库会有大量的文档,我们需要将各类文档的内容提取出来,下篇我们将学习如何从文件中提取文本以及如何将文本分割,敬请期待~。
参考资料:
Spring AI:简介 :: Spring AI 参考 - Spring 框架
Ollama:Ollama
Milvus:Milvus 向量数据库文档
示例代码:ai-chat: Spring AI 相关技术介绍
下篇地址:Spring AI应用:利用DeepSeek+嵌入模型+Milvus向量数据库实现检索增强生成--RAG应用(二)(超详细)-CSDN博客

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 32
32 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)