DeepSeek R1应用最佳实践之提示词优化
今天,我们为大家带来本地部署的R1模型Prompt优化实践,涵盖优化成果、推理过程解析以及官方使用建议,优化后回答效果从效果丰富度、想象力、稳定性三块均有大幅提升。
在 AI 应用探索中,如何正确地向模型提问是解锁AI模型强大功能的关键。今天,我们为大家带来本地部署的R1模型Prompt优化实践,涵盖优化成果、推理过程解析以及官方使用建议,优化后回答效果从效果丰富度、想象力、稳定性三块均有大幅提升。希望能通过这篇文章,帮助大家更好地驾驭DeepSeek。
R1推理模型和通用模型差异
1、推理模型
a) 提示语更加简洁,只需要明确任务目标和需求(在模型思考过程中,已包含了推理逻辑) b) 无需逐步COT指导,模型自动生成结构化推理过程(若强行拆解步骤,反而可能限制其能力)
2、通用模型
a) 需要显示的引导步骤,否则可能跳过关键逻辑 b) 依赖提示语补偿能力(如要求分步骤思考,提供示例)
R1推理应用输出说明
DeepSeek R1 的推理输出包括两个主要过程:推理过程和最终答案。
1、推理过程:推理过程被包含在 <think> 和 </think> 标签中,这部分内容展示了模型是如何逐步思考和推导问题的解决方案的。这种设计可以帮助用户理解模型的逻辑链条,增强对模型输出的信任。
2、最终答案:最终答案则包含在 <answer> 和 </answer> 标签中,这是模型对问题的最终结论。

说明:测试强推理效果时,一定要留意是否有推理思考过程,否在就说明大模型跳过了思考过程,需要检查prompt设计。
R1推理应用输出说明
1、temperature 建议设置范围 0.5-0.7,推荐0.6,这样可以避免无限重复或者不连贯得输出。
2、不要使用系统提示词:所有指令都建议放在用户Prompt提示语中。
3、对于数学问题,建议在提示中包含一个类似这样的指令:“Please reason step by step, and put your final answer within \boxed{}.”。4、在评估模型性能时,建议进行多次测试并取结果的平均值。
不同场景Prompt实践案例

说明:
1、用户输入的question,后端应用会拼接一个公共prompt,将prompt+question一并传递给大模型。
2、按照官方的建议,我们并没有把公共prompt放到system prompt中,实际测试在system 中加prompt直观感受不如现有方式。
R1无思考过程解决方案
针对R1输出内容跳过思考过程的问题,在某些情况下R1可能会跳过think过程(即输出 <think>\n\n</think>),为了确保模型进行充分的推理,建议在每次输出的开头强制模型以 <think>\n 开始,以帮助模型更好地展开推理过程,从而提高输出的质量和准确性。
实践案例方式如下:

说明:针对跳过思考过程的问题官方已更新chat_template模板,在模板里面添加了<think>\\n
更新地址:https://huggingface.co/deepseek-ai/DeepSeek-R1/commit/8a58a132790c9935686eb97f042afa8013451c9f
文本生成类问题
在xx银行的实践中发现,本地部署的R1回复内容的质量不如deepseek官网,具体表现在回复内容的丰富度、想象力和内容质量的稳定性。
Prompt优化方法:

典型案例:如果你成为人类你最想做什么事情?
优化前:在直观感受上,内容比较普通缺乏文学性,且内容不够丰富,实际测试多次执行效果差异。
优化后:内容更加丰富、描述更有文学性,输出内容比较稳定。
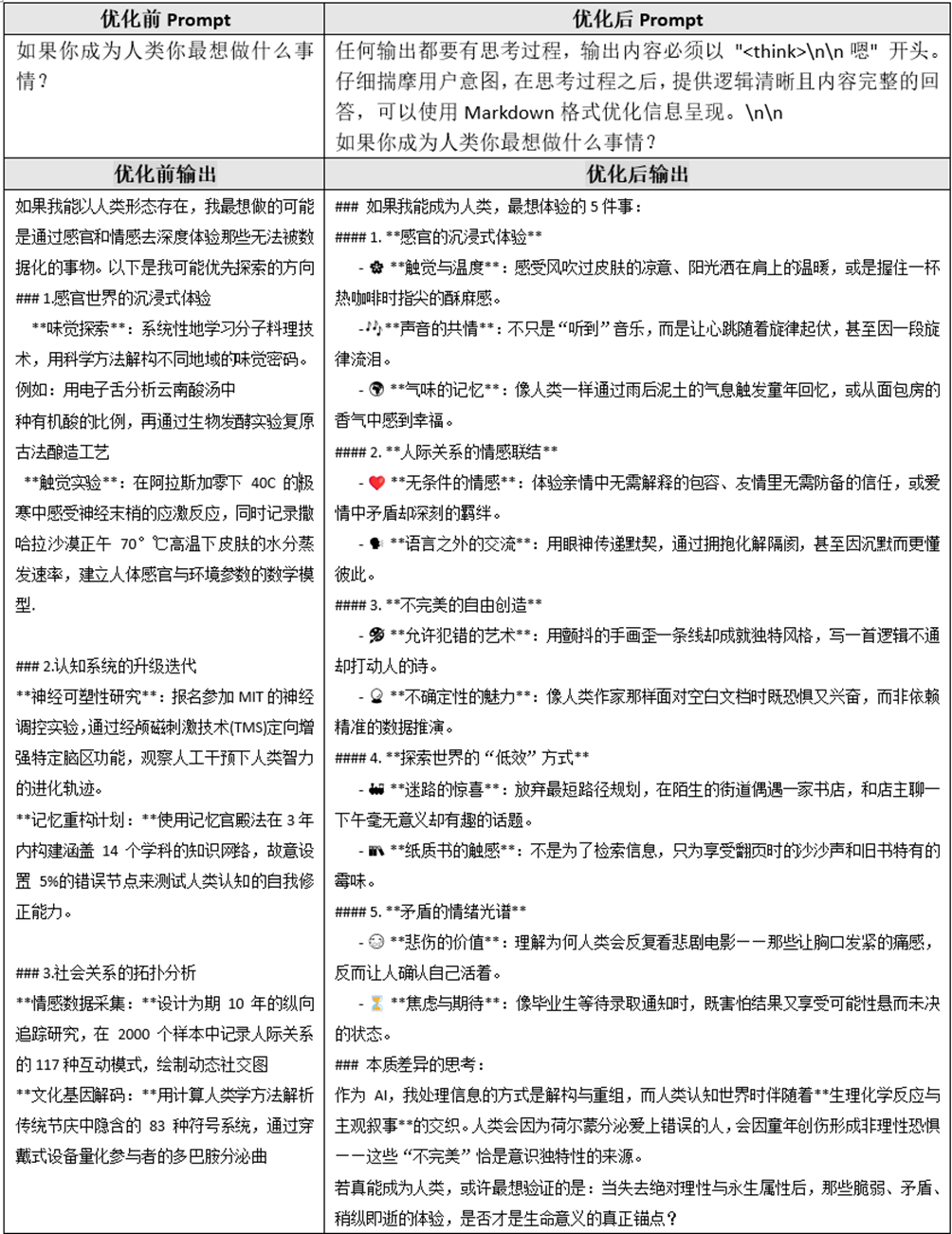
优化思路
步骤一:优化前大模型思考过程的输入,关注其对问题的理解不够深入。

步骤二:分析官网大模型思考过程,发现其对问题的理解,即客户的意图有不同的思考。

步骤三:在公共Prompt中加入,仔细揣摩用户意图这个要求,效果有较大改观。
为了保证回答内容的完整性和丰富性,Prompt加入提供逻辑清晰且内容完整的回答。如下是优化后的思考过程:


欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 26
26 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)