超详细笔记——本地部署DeepSeek大模型和 RAG 知识库问答系统实录---Ollama+MaxKB+Python调用
在当今人工智能飞速发展的时代,大模型和知识库问答系统的应用越来越广泛。对于技术爱好者和开发者来说,能够在本地环境中部署和实践这些先进的技术,不仅有助于深入理解其原理,还能为实际项目开发提供宝贵的经验。本文将详细记录如何在笔记本电脑上,通过一系列步骤实现DeepSeek大模型与RAG知识库问答系统(MaxKB)的本地部署,并介绍如何使用Python对其进行调用。
前言
在当今人工智能飞速发展的时代,大模型和知识库问答系统的应用越来越广泛。对于技术爱好者和开发者来说,能够在本地环境中部署和实践这些先进的技术,不仅有助于深入理解其原理,还能为实际项目开发提供宝贵的经验。本文将详细记录如何在笔记本电脑上,通过一系列步骤实现DeepSeek大模型与RAG知识库问答系统(MaxKB)的本地部署,并介绍如何使用Python对其进行调用。
一、环境准备
(一)笔记本配置
笔者的配置如下:
CPU:11th Gen Intel® Core™ i7-11370H @ 3.30GHZ
内存:32G
GPU:NVIDIA RTX A2000 Laptop GPU
本次操作的笔记本操作系统为Windows 11。
(二)安装VMware虚拟机
-
下载地址
:前往VMware官方网站,找到适合个人使用的免费版本进行下载。当前下载的版本信息如图所示。
-
安装过程
:按照VMware安装向导的提示,逐步完成安装过程。安装完成后,即可准备在虚拟机中安装操作系统。
二、在虚拟机中安装Ubuntu系统
-
选择系统版本:本次选择安装Ubuntu桌面版系统,这样的设置是为将来在服务器或云服务器上进行部署做前期准备。因为Ubuntu系统在服务器环境中应用广泛,提前熟悉其操作和配置,有助于后续的部署工作。
-
安装步骤:在VMware虚拟机中,加载下载好的Ubuntu系统镜像文件,按照安装向导的指引,完成系统的安装过程,包括语言选择、分区设置、用户创建等步骤。安装完成后,Ubuntu系统即可在虚拟机中正常运行。
虚拟机配置如下: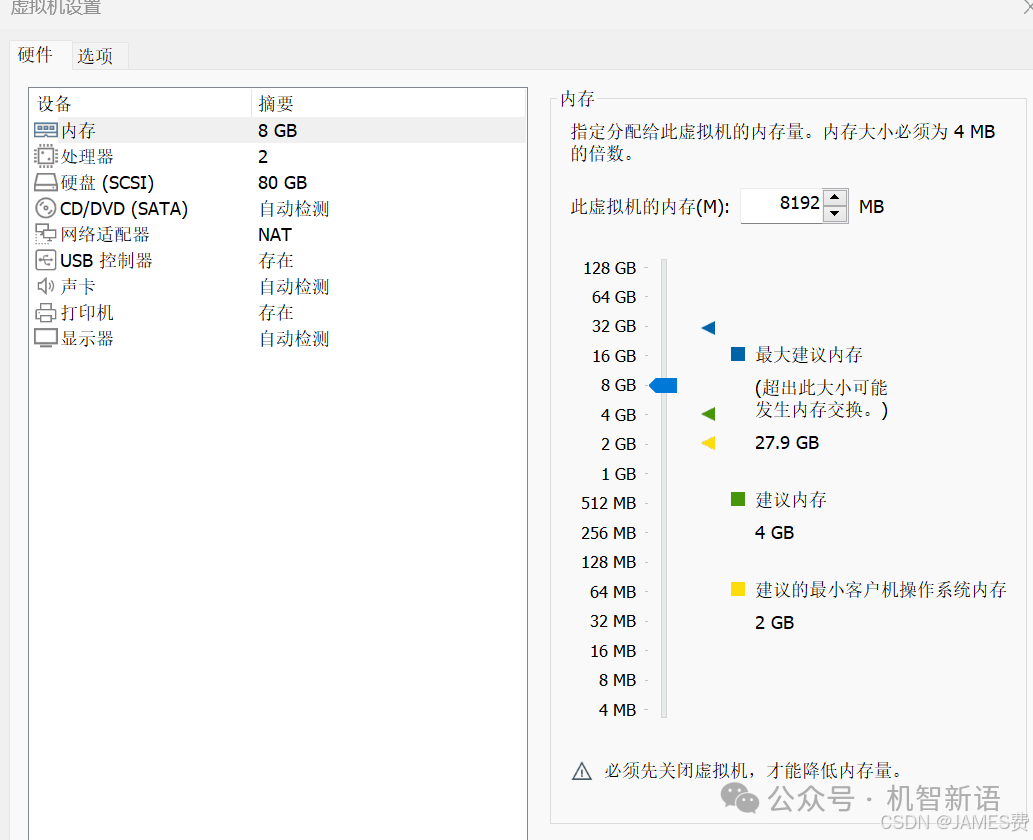
三、在Ubuntu系统中安装Docker
-
更新系统软件包
在Ubuntu系统中打开终端,输入以下指令更新系统软件包,确保系统处于最新状态:
sudo apt update
-
安装Docker依赖包
执行以下命令安装Docker所需的依赖包:
sudo apt install apt-transport-https ca-certificates curl software-
properties-common
-
添加Docker官方GPG密钥
通过以下指令添加Docker官方的GPG密钥,以确保软件包来源的安全性:
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --
dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg
-
设置Docker软件源
根据Ubuntu系统版本,设置对应的Docker软件源。例如,对于Ubuntu 22.04系统,执行以下命令:
echo "deb [arch=amd64 signed-by=/usr/share/keyrings/docker-archive-keyring.gpg]
https://download.docker.com/linux/ubuntu jammy
stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
-
更新软件包索引并安装Docker
再次更新系统软件包索引,并安装Docker引擎:
sudo apt update
sudo apt install docker-ce docker-ce-cli containerd.io
安装完成后,可以通过以下命令验证Docker是否安装成功:
sudo docker run hello-world
如果能正常输出Docker的欢迎信息,说明Docker已经成功安装在Ubuntu系统中。
四、通过Docker下载并启动MaxKB镜像
-
下载MaxKB镜像
在Ubuntu系统的终端中,执行以下命令下载MaxKB镜像:
sudo docker pull registry.fit2cloud.com/maxkb/maxkb
-
启动MaxKB镜像
使用以下指令启动MaxKB镜像,这里与官方手册略有不同,采用了
--network=host参数,目的是让容器能够访问笔记本上的Ollama,使容器和宿主机的IP地址一致:
sudo docker run --network=host -d --name=Gmaxkb --restart=always -
v ~/.maxkb:/var/lib/postgresql/data -v ~/.python-
packages:/opt/maxkb/app/sandbox/python-packages
registry.fit2cloud.com/maxkb/maxkb
其中,-d参数表示在后台运行容器,--name=Gmaxkb为容器命名为Gmaxkb,--restart=always确保容器在系统重启后自动启动,-v参数用于挂载宿主机目录到容器内相应目录,以实现数据的持久化存储和共享。
完成上述操作后,即可在笔记本的Windows 11系统上,通过浏览器打开MaxKB。
五、在笔记本上部署Ollama
-
下载Ollama软件
前往Ollama官方网站,下载适合Windows系统的Ollama软件安装包。下载完成后,按照安装向导的提示完成安装。
-
设置环境变量
打开命令提示符(CMD)窗口,输入以下命令设置环境变量,使局域网内所有主机能够访问Ollama:
set OLLAMA_HOST=0.0.0.0
为了避免每次启动都需要手动输入该命令,建议将此环境变量添加到系统环境变量中。具体操作方法为:在“此电脑”上右键单击,选择“属性”,在弹出的窗口中点击“高级系统设置”,在“系统属性”窗口的“高级”选项卡下,点击“环境变量”按钮,在“系统变量”区域中点击“新建”,输入变量名“OLLAMA_HOST”,变量值“0.0.0.0”,点击“确定”保存设置。
3. 下载并启动DeepSeek模型
在CMD窗口中运行以下命令,让Ollama自动下载DeepSeek - r1:7b模型:
ollama run deepseek-r1:7b
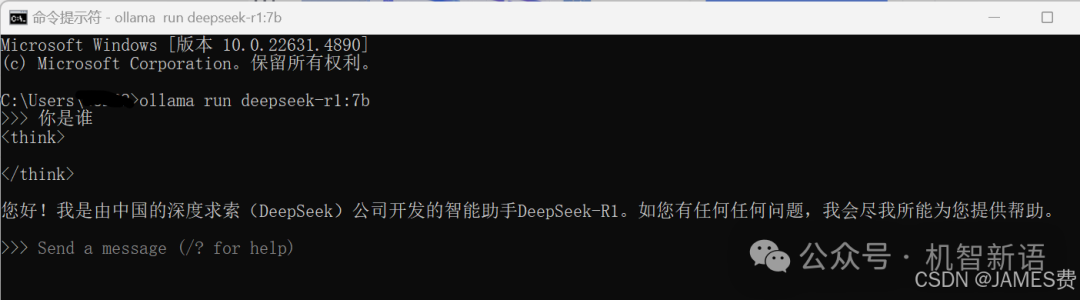
等待下载完毕后,会进入客户端,出现>>>提示符如上图,说明模型已成功下载。此时可关闭CMD窗口。
4. 启动Ollama的HTTP服务
打开新的CMD窗口,运行以下指令启动一个HTTP服务:
ollama serve
回车后会询问如下,点击允许。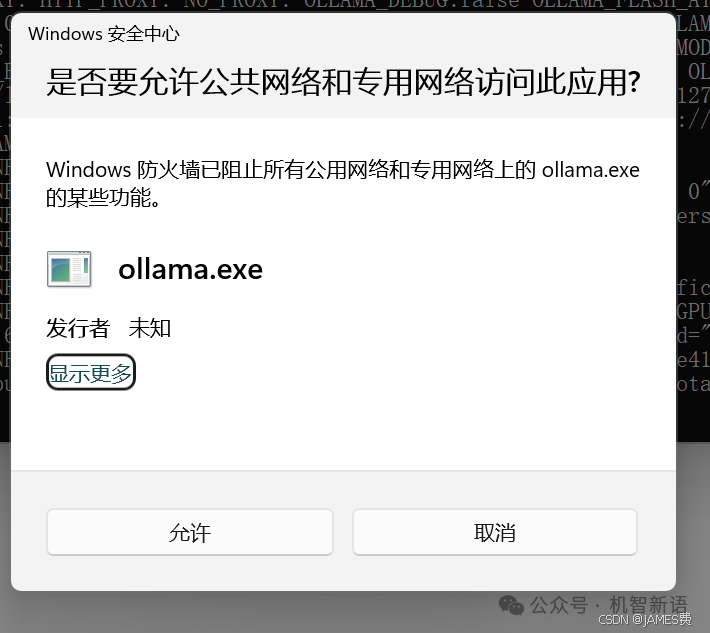
然后进入虚拟机中的Ubuntu系统,打开浏览器,在地址栏输入笔记本VMware创建的局域网地址加上端口11434(例如:http://192.168.50.1:11434/ ,这里的192.168.50.1需要根据实际的局域网地址进行修改)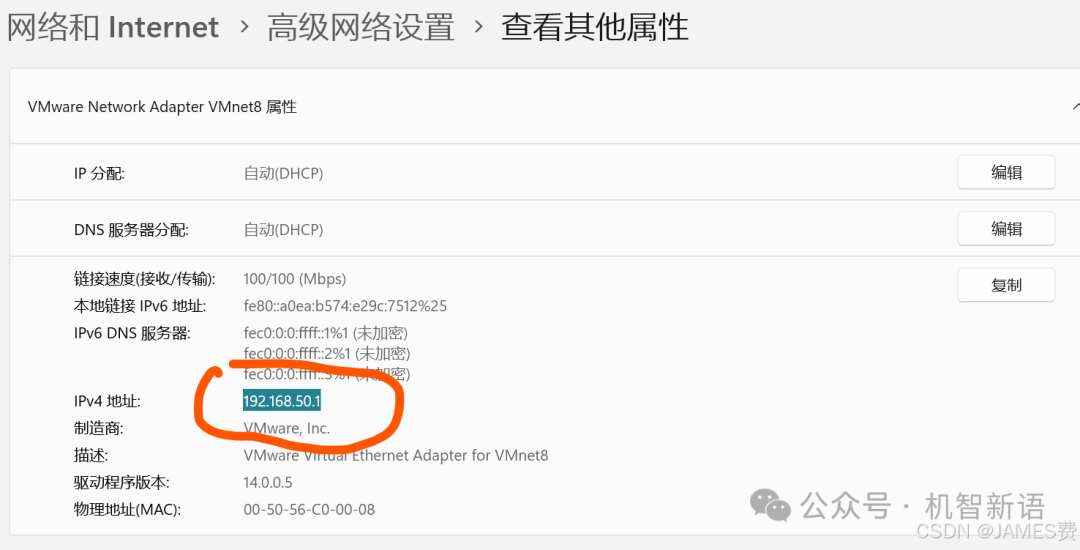
。如果页面显示“0llama is running”,则说明Ollama的HTTP服务已正常启动并可访问。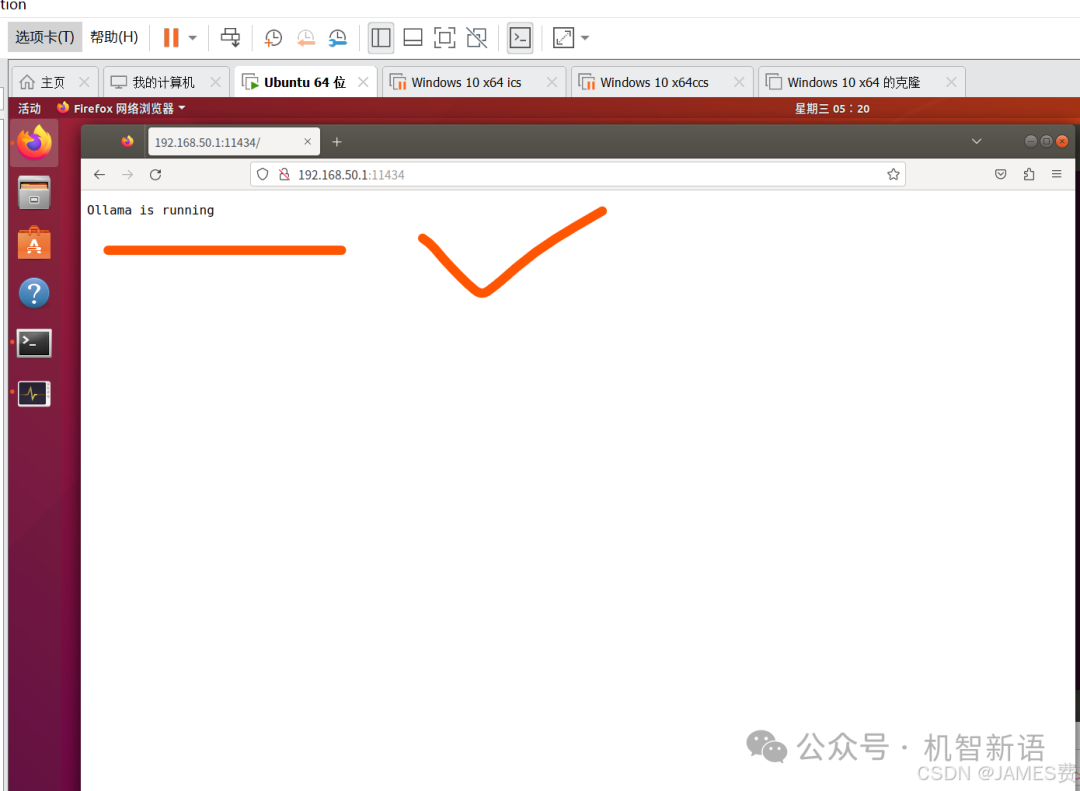
六、使用MaxKB创建知识库和应用
此部分maxKB官方文档有详细描述。
-
打开MaxKB登录界面
在笔记本的浏览器中输入MaxKB的登录地址:http://192.168.50.141:8080/ (这里的192.168.50.141是虚拟机Ubuntu上的IP地址,需根据个人实际情况进行修改)。进入MaxKB登录界面。
-
登录并修改密码
使用初始用户名“admin”和默认密码“MaxKB@123…”进行登录。登录成功后,系统会要求修改密码,按照提示修改为自己的密码。
-
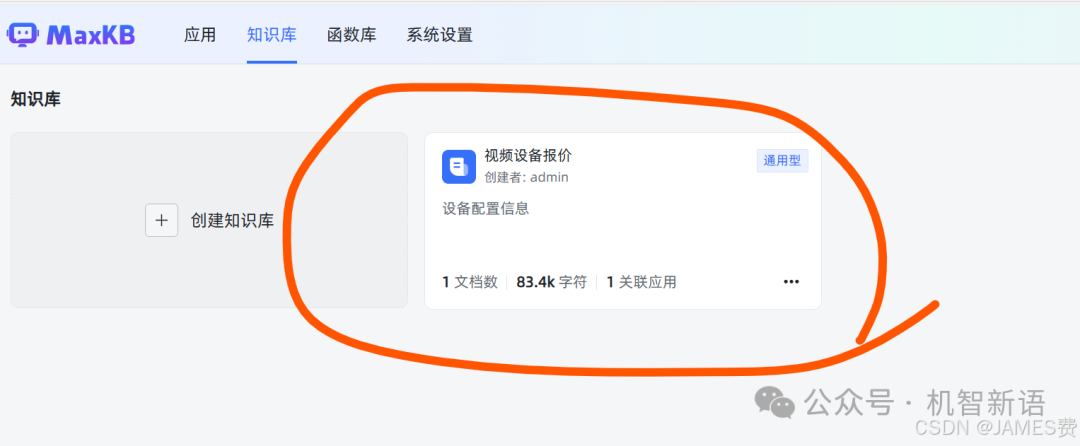
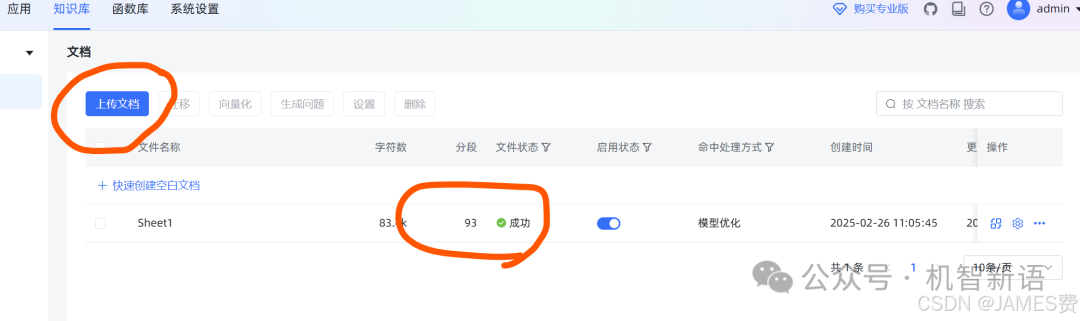
创建知识库
点击“创建知识库”按钮,本次上传了一个设备Excel表格作为知识库数据。上传完成后,系统会自动对文件进行向量化处理。
-
创建应用
进入应用创建页面,点击创建应用创建新的应用。
创建进入设置,进行以下两个操作:
-
添加大模型
:供应商选择Ollama,在相应位置添上Ollama的地址,Key可以随便填写,选择“共有”,点击保存。如果保存过程中没有报错,说明配置成功。
(1)添加模型ti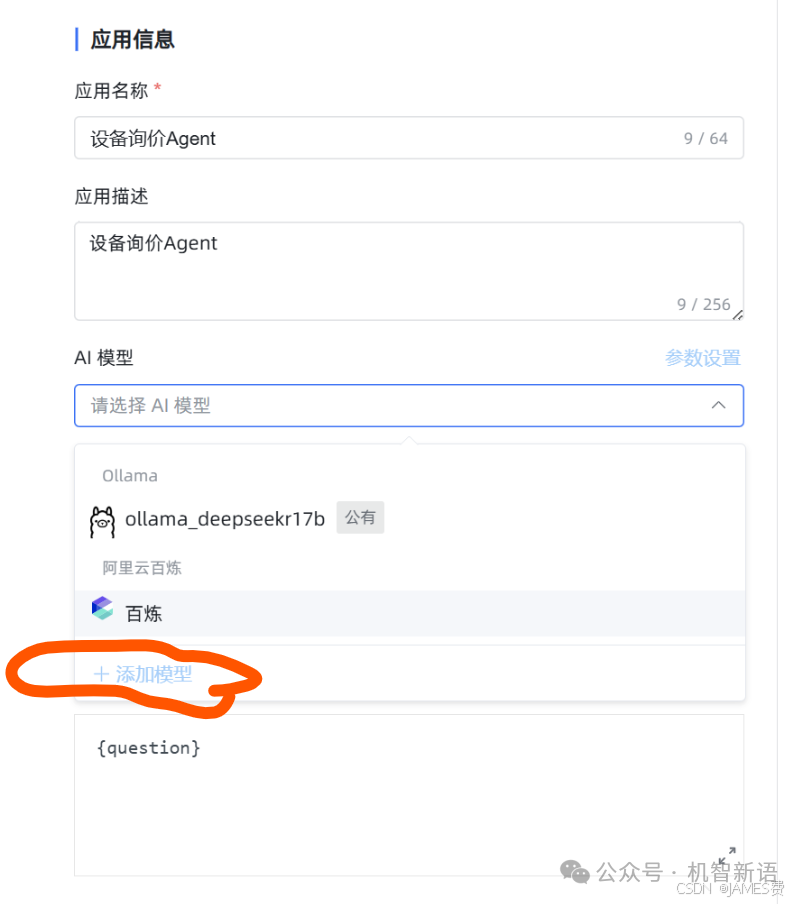
(2)选择ollama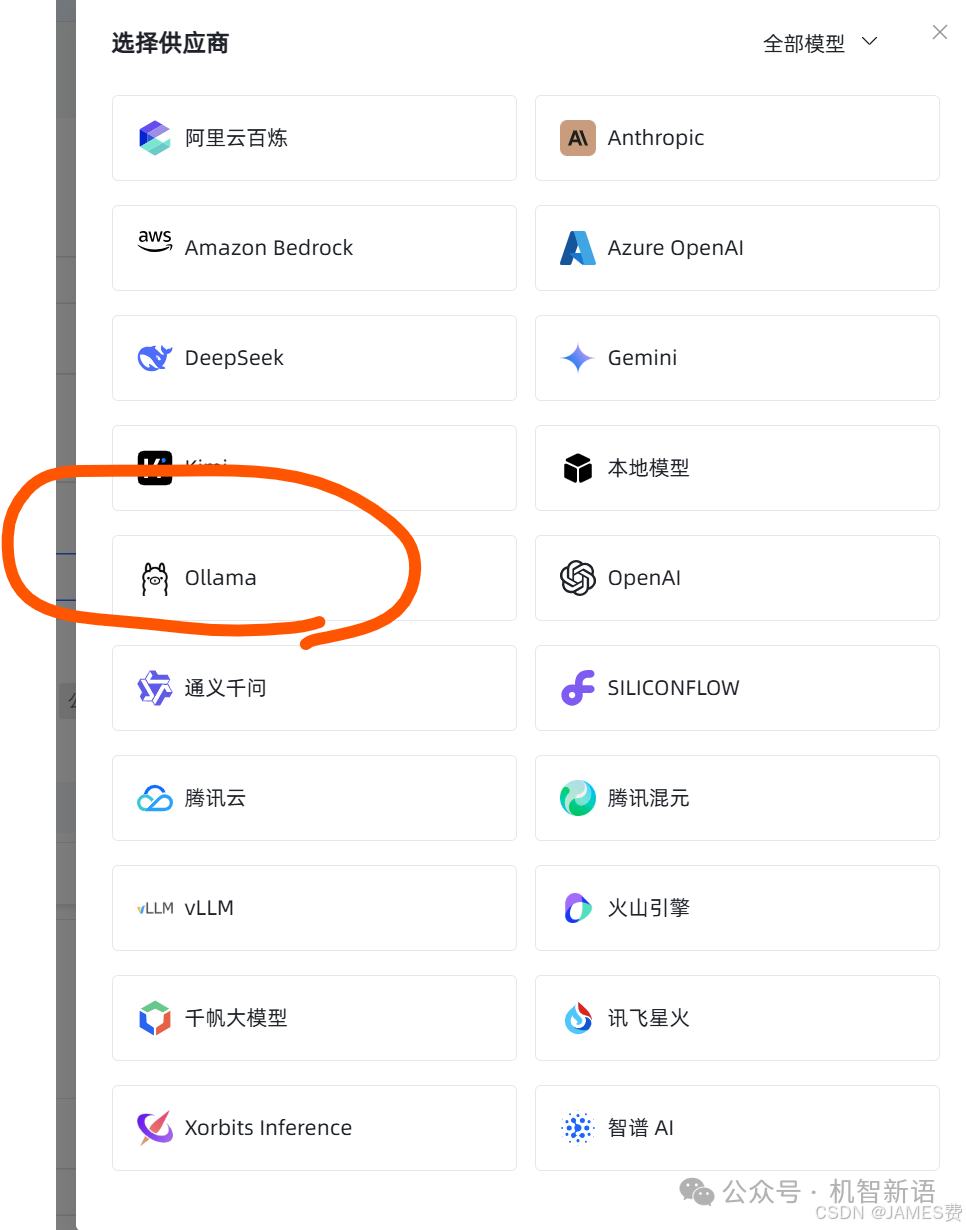
(3)输入地址和key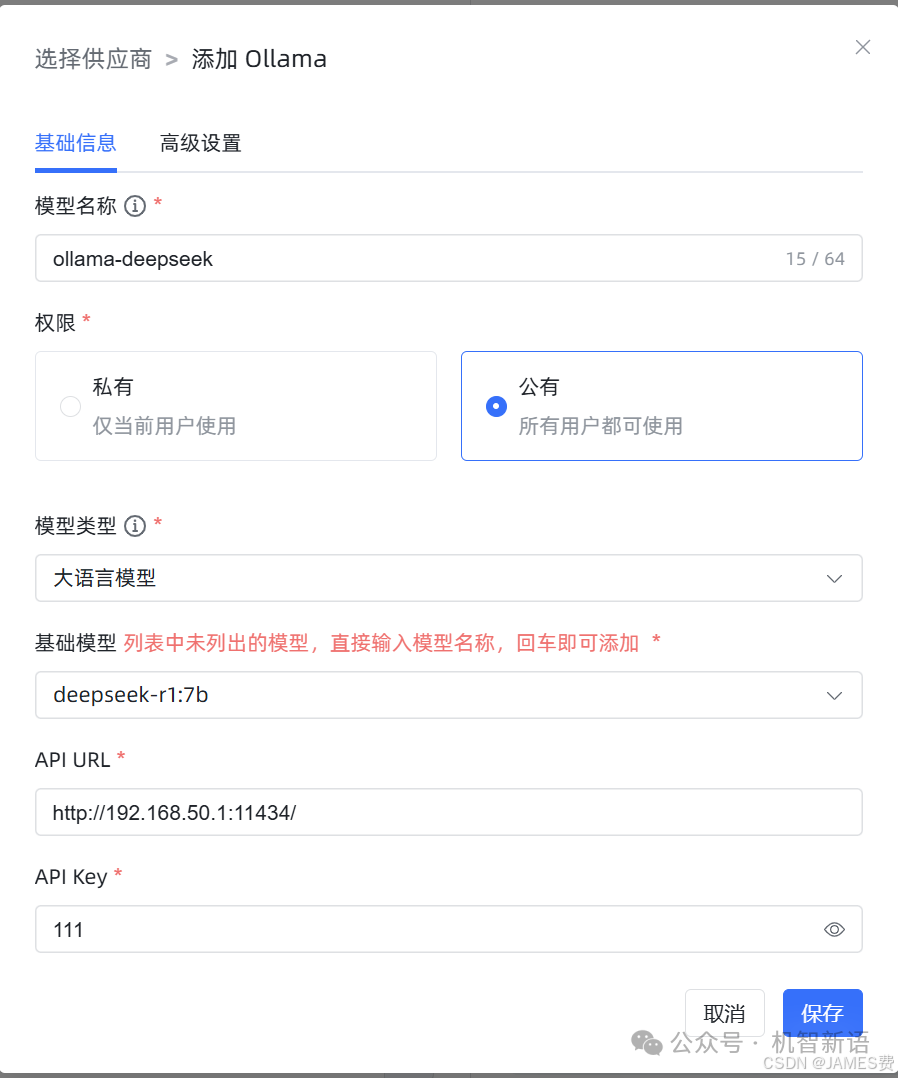
-
关联知识库
:点击“添加”按钮,关联刚才创建的知识库。
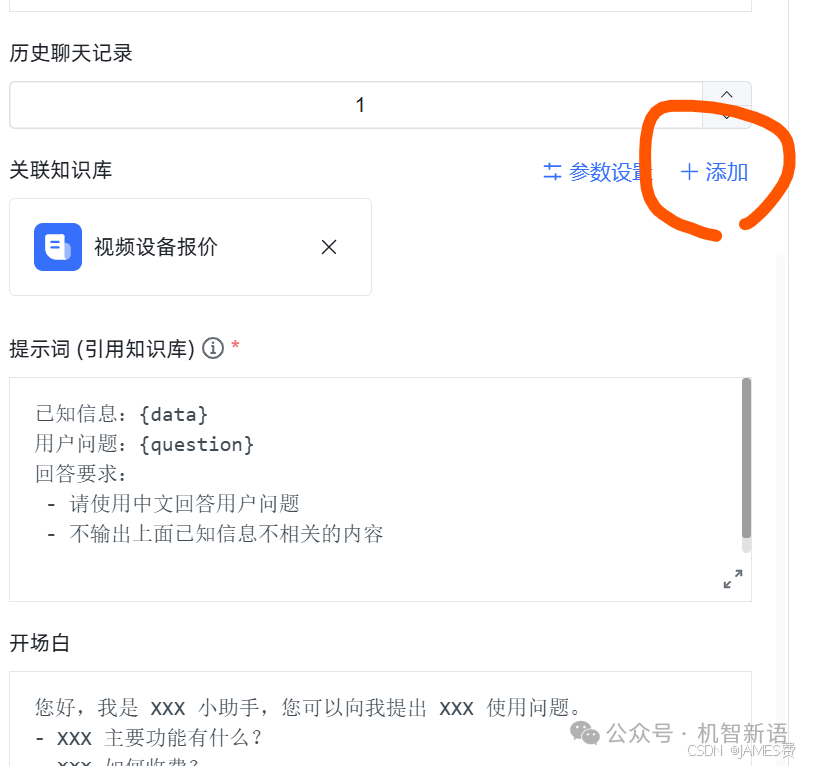
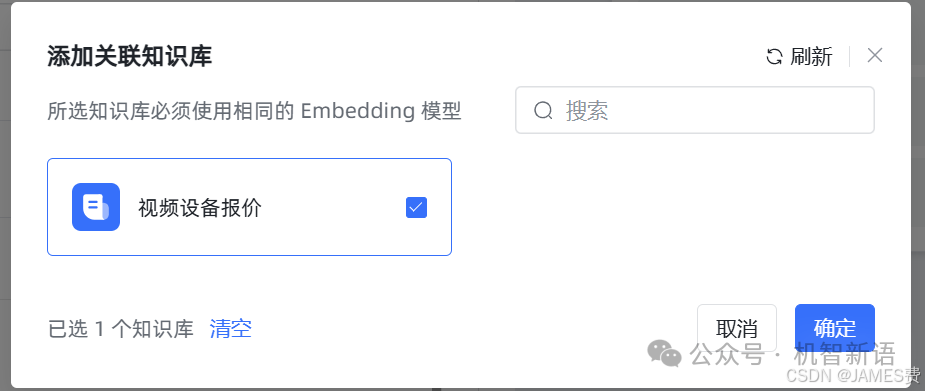
完成上述操作后,即可输入问题进行测试。测试通过后,点击保存并发布应用。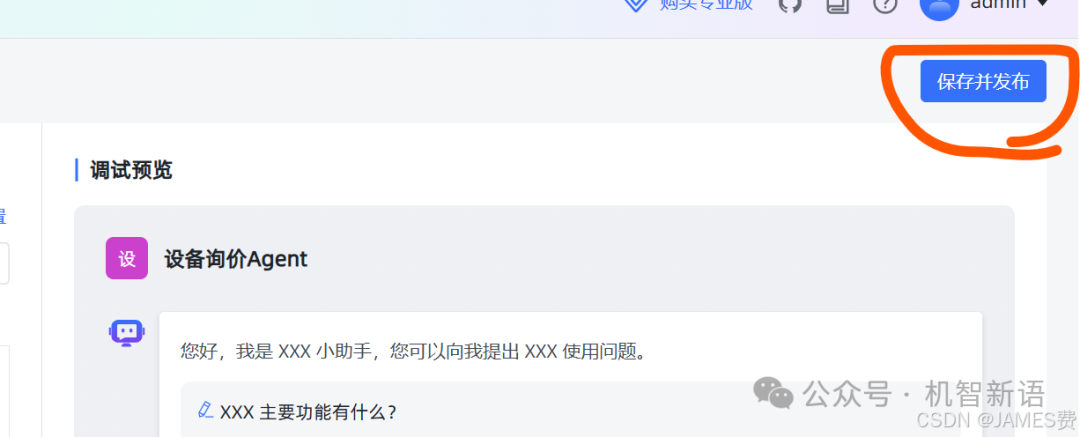
七、Python调用MaxKB
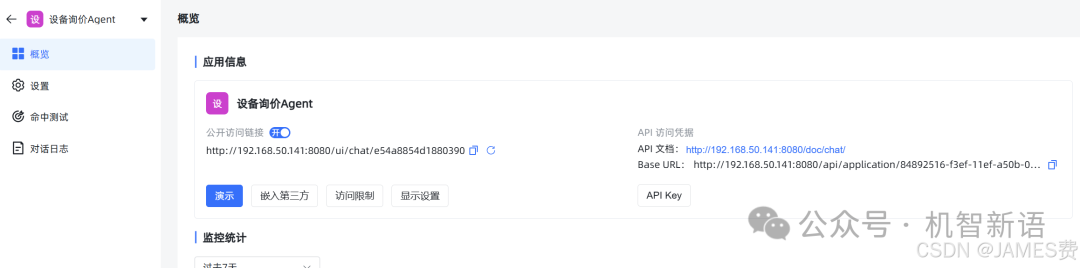
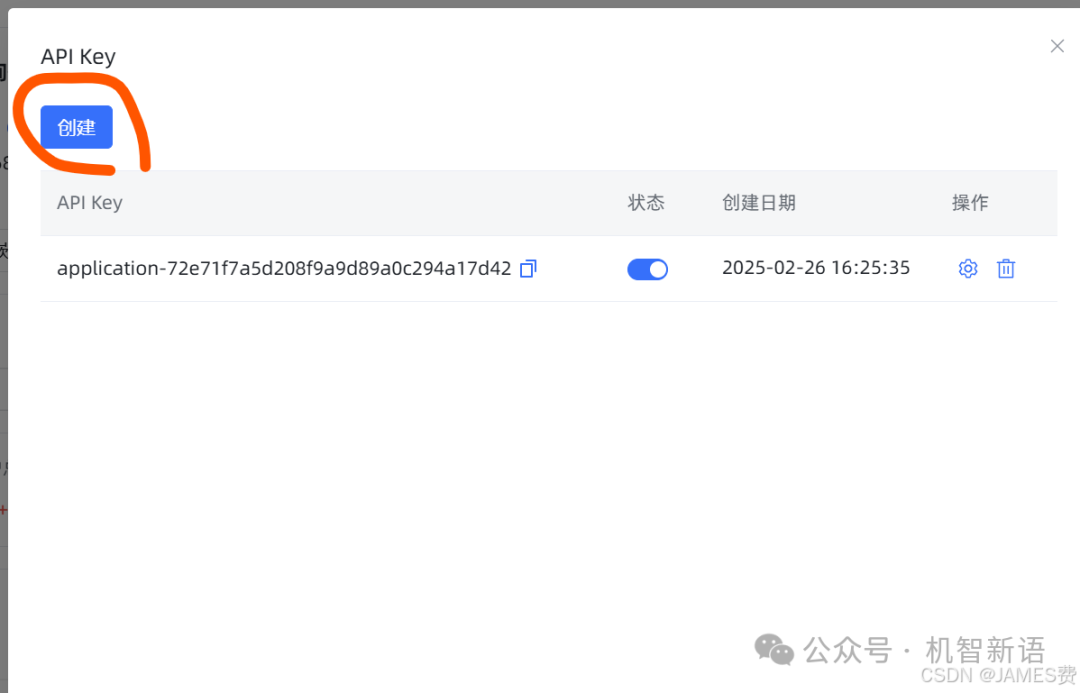
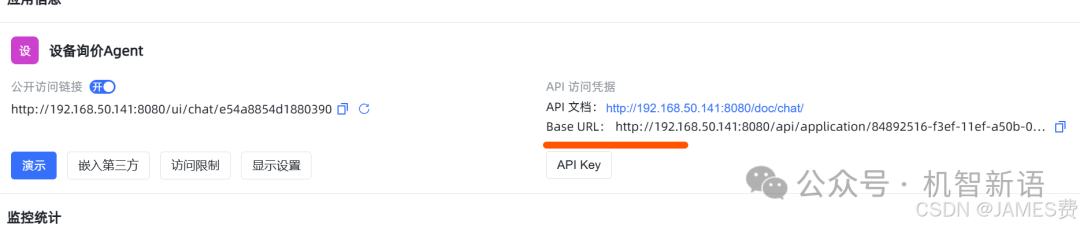
-
获取API key和Base url
进入应用设置中的“概览”页面,点击“API key”按钮创建一个API key。同时,记录下Base url,这两个值将用于Python程序中的配置。
-
Python代码实现
以下是完整的Python代码,通过该代码可以实现对MaxKB的调用:
# -*- coding: utf-8 -*-
"""
Created on Wed Feb 26 16:25:44 2025
@author: 18268
"""
import requests
# 定义headers
headers = {
'accept': 'application/json',
'AUTHORIZATION': 'application-72e71f7a5d208f9a9d89a0c294a17d42' # api key,需替换为实际的API key
}
# 获取 profile id
def get_profile_id():
profile_url = 'http://192.168.50.141:8080/api/application/84892516-f3ef-11ef-a50b-0242ac110002' # 需替换为自己的baseurl
response = requests.get(profile_url, headers=headers)
if response.status_code == 200:
return response.json()['data']['id']
else:
print("获取profile id失败")
return None
# 获取 chat id
def get_chat_id(profile_id):
chat_open_url = f'http://192.168.50.141:8080/api/application/{profile_id}/chat/open' # 需改为自己的ip
response = requests.get(chat_open_url, headers=headers)
if response.status_code == 200:
return response.json()['data']
else:
print("获取chat id失败")
return None
# 发送聊天消息(流式)
def send_chat_message(chat_id, payload):
chat_message_url = f'http://192.168.50.141:8080/api/application/chat_message/{chat_id}'# 需改为自己的ip
try:
# 开启流式传输
response = requests.post(chat_message_url, headers=headers, json=payload, stream=True)
response.raise_for_status()
# 逐块读取响应数据
for line in response.iter_lines():
if line:
try:
# 去掉 "data: " 前缀
line = line.lstrip(b'data: ')
data = line.decode('utf-8')
# 假设服务器返回的是JSON格式的数据
import json
json_data = json.loads(data)
content = json_data.get('data', json_data).get('content')
if content:
# 打印 content 内容
print(content, end='', flush=True)
except json.JSONDecodeError:
print(f"无法解析JSON数据: {line}")
except requests.RequestException as e:
print(f"发送消息失败: {e}")
# 主函数
def main(message, re_chat=False, stream=True):
profile_id = get_profile_id()
if profile_id:
print("获取profile id成功")
print(profile_id)
chat_id = get_chat_id(profile_id)
if chat_id:
print("获取chat id成功")
print(chat_id)
chat_message_payload = {
"message": message,
"re_chat": re_chat,
"stream": stream
}
send_chat_message(chat_id, chat_message_payload)
else:
print("获取chat id失败")
else:
print("获取profile id失败")
if __name__ == "__main__":
# 在此自定义消息内容和参数
message = "AR实景系统专用PC的价格"
main(message, re_chat=False, stream=True)
将代码中的AUTHORIZATION字段值替换为实际创建的API key,profile_url、chat_open_url和chat_message_url中的IP地址替换为虚拟机Ubuntu的实际IP地址,即可运行该代码,实现通过Python调用MaxKB进行问答操作。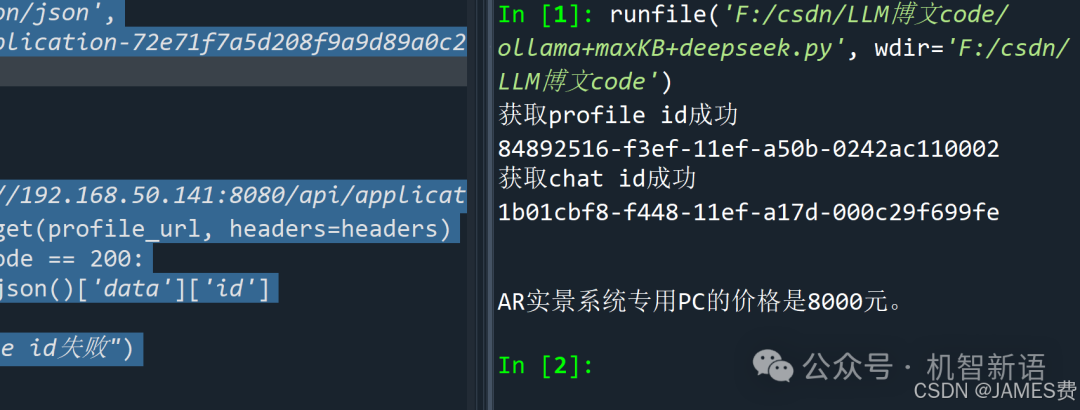
八、总结
通过以上一系列详细的步骤,我们成功在笔记本本地完成了DeepSeek大模型和RAG知识库问答系统(MaxKB)的部署,并实现了通过Python对其进行调用。这个过程不仅涉及到操作系统的安装与配置、虚拟机的使用、容器化技术(Docker)的应用,还包括大模型的下载与部署、知识库问答系统的搭建以及Python编程实现与系统的交互。希望本文能为对这方面技术感兴趣的读者提供有益的参考和实践指导,帮助大家更好地探索和应用人工智能技术。在实际操作过程中,可能会遇到各种问题,需要大家根据具体情况进行排查和解决。祝大家在技术探索的道路上不断取得新的成果!
我的DeepSeek部署资料已打包好(自取↓)
https://pan.quark.cn/s/7e0fa45596e4
但如果你想知道这个工具为什么能“听懂人话”、写出代码 甚至预测市场趋势——答案就藏在大模型技术里!
❗️为什么你必须了解大模型?
1️⃣ 薪资爆炸:应届大模型工程师年薪40万起步,懂“Prompt调教”的带货主播收入翻3倍
2️⃣ 行业重构:金融、医疗、教育正在被AI重塑,不用大模型的公司3年内必淘汰
3️⃣ 零门槛上车:90%的进阶技巧不需写代码!会说话就能指挥AI
(附深度求索BOSS招聘信息)
⚠️警惕:当同事用DeepSeek 3小时干完你3天的工作时,淘汰倒计时就开始了。
那么,如何系统的去学习大模型LLM?
作为一名从业五年的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?老师啊,我自学没有方向怎么办?老师,这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!当然这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~
👉大模型学习指南+路线汇总👈
我们这套资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。

👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。
👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。
👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。
👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 8
8 0
0- 0



 已为社区贡献108条内容
已为社区贡献108条内容

所有评论(0)