一文搞明白DeepSeek【满血版】和【贫血版】差异,以及【X86架构】和【C86架构】(搭配国产卡)服务器,硬件配置参数要求 [文末有福利]【建议收藏】
关于671B转译和量化过程中智商降低多少的问题,是一个开放性问题,转译和量化一定是跟原版的智商是有区别的,智商下降多少,取决于技术团队转译和量化时的取舍和操作,比如同样做Q4量化,一个大牛和一个菜鸟两个人量化出来的671B模型智商肯定差异很大,所以说转译满血版一定比量化满血版智商高,这个认知是错误的。第二选择是转换为BF16精度,用支持该精度的GPU来推理,精度几乎无损,但系统开销会增大,推理效率
目录
3.2、C86架构(搭配国产卡)服务器DeepSeek业务配置推荐

1、DeepSeek大模型版本的”满血“与”贫血”
1.1、“满血”与“贫血”的来源
目前各大厂都宣传支持满血版DeepSeek,但由于搭配的算力卡能力不同,“满血”也会打折扣。DeepSeek V3/R1官方推荐的推理精度是FP8和BF16,而官方只提供FP8权重的满血模型,BF16权重模型需要自行转换。理论上讲,用原生支持FP8精度的GPU来执行推理任务,可以达到最佳满血效果。第二选择是转换为BF16精度,用支持该精度的GPU来推理,精度几乎无损,但系统开销会增大,推理效率会降低。更差的选择,是把满血模型量化为int8甚至int4的残血版,虽然推理效率很高,但是模型精度会大大损失。这也就是为什么很多人觉得,采用同样的提示词提问,市面上那些满血版DeepSeek,输出的结果都不如DeepSeek官方。其实就是这些“私服”的运营方为了降低算力成本,对满血模型进行的精度转换或量化。
1.2、“满血”到底是咋回事
满血版定义:671B参数的deepseek不管是V3/R1,只要满足671B参数就叫满血版。满血版划分:通常可细分为:原生满血版(FP8计算精度)、转译满血版(BF16或者FP16计算精度)、量化满血版(INT8、INT4、Q4、Q2计算精度)等版本,但是大家宣传都不会宣传XX满血版,只会宣传满血版。
- 原生满血版:deepseek官方支持的FP8混合精度,不要怀疑,官方的我们认为就是最好的,因为目前没有人比官方更懂deepseek。
- 转译满血版:因为官方的deepseek采用的是FP8混合精度,但是大部分的国产卡是不支持FP8精度的。所以要适配deepseek,采用BF16或者FP16来计算,这个方式理论上对精度影响很小,但是对计算和显存的硬件需求几乎增加一倍。 关于显存计算,如果要部署671B的官方版大模型,用FP8混合精度,最小集群显存是750GB左右;如果采用FP16或者BF16,大概需要1.4T以上。截至目前,从公开资料显示,支持FP8精度的国产AI芯片。只有算能、摩尔线程和瀚博半导体,这三家是公开资料显示宣称支持FP8,其他家没有明确公开资料支持FP8,因为如果自己芯片不支持宣传支持,会有法律麻烦。
- 量化满血版:很多厂家的AI卡只支持INT8、FP16、FP32等格式,如果用FP16,单机需要1.4T显存以上,绝大多数国产AI单机没有那么大显存,为了单台机器能跑671B deepseek,被逼无奈选择量化,量化就是通过减少计算精度,达到减少显存占用和提高吞吐效率的目的,当然任何量化都是以降低智商为代价的。
举个形象的例子,比如FP8我们说计算保留小数点后7位数字,INT8我们说计算保留数据点后2位数字。FP8的计算就是:3.1415926*3.1415926=9.8696040,IN8的计算精度 3.14*3.14=9.86 这两个结果我们认为近似等价,但是会发现FP8更精准,在大模型里我们近似认为精度越高,智商越高。所以我们近似认为FP8的智商更高。

这里面有一个争议点,很多人说BF16或者FP16计算的671B大模型的智商跟原版FP8智商一样,并没有降低,从原理上来说,确实可以保持一致,但是真正转译过程中会导致一些差异化,智商会有些许下降,智商下降多少取决于转译厂商的技术团队水平。
关于671B转译和量化过程中智商降低多少的问题,是一个开放性问题,转译和量化一定是跟原版的智商是有区别的,智商下降多少,取决于技术团队转译和量化时的取舍和操作,比如同样做Q4量化,一个大牛和一个菜鸟两个人量化出来的671B模型智商肯定差异很大,所以说转译满血版一定比量化满血版智商高,这个认知是错误的。
原生满血版是最好的,其他版本一切皆有可能,是不是有可能转译出比原生满血版智商更高的满血版呢?也是有这个可能的,只是这种概率极低极低。Deepseek满血版一体机满天飞,怎么区别他们优劣呢?这个问题特别简单,实践是检验真理的唯一标准。
测试方法:基于deepseek官宣线上版本和开源版本模型完全一致的现状。把同一个问题,先问官方deepseek官网地址,再问一体机,如果思考过程和答案一致,那说明是智商一致,否则就是降低的版本,至少比官网降低了智商。
2、DeepSeek-R1系列模型不同量化精度下配置要求
2.1、大模型选型原则
大模型选型核心原则:在硬件能力范围内选择最大且不爆显存的模型。
模型参数量的增加会显著提升推理和训练效果,但同时也需要更高的显存(GPU 内存)和系统内存(RAM)支持。若显存不足,模型无法加载;若内存不足,则可能引发系统崩溃或性能断崖式下降。因此,"适配性最优解" 的本质是寻找硬件资源与模型规模间的临界点。
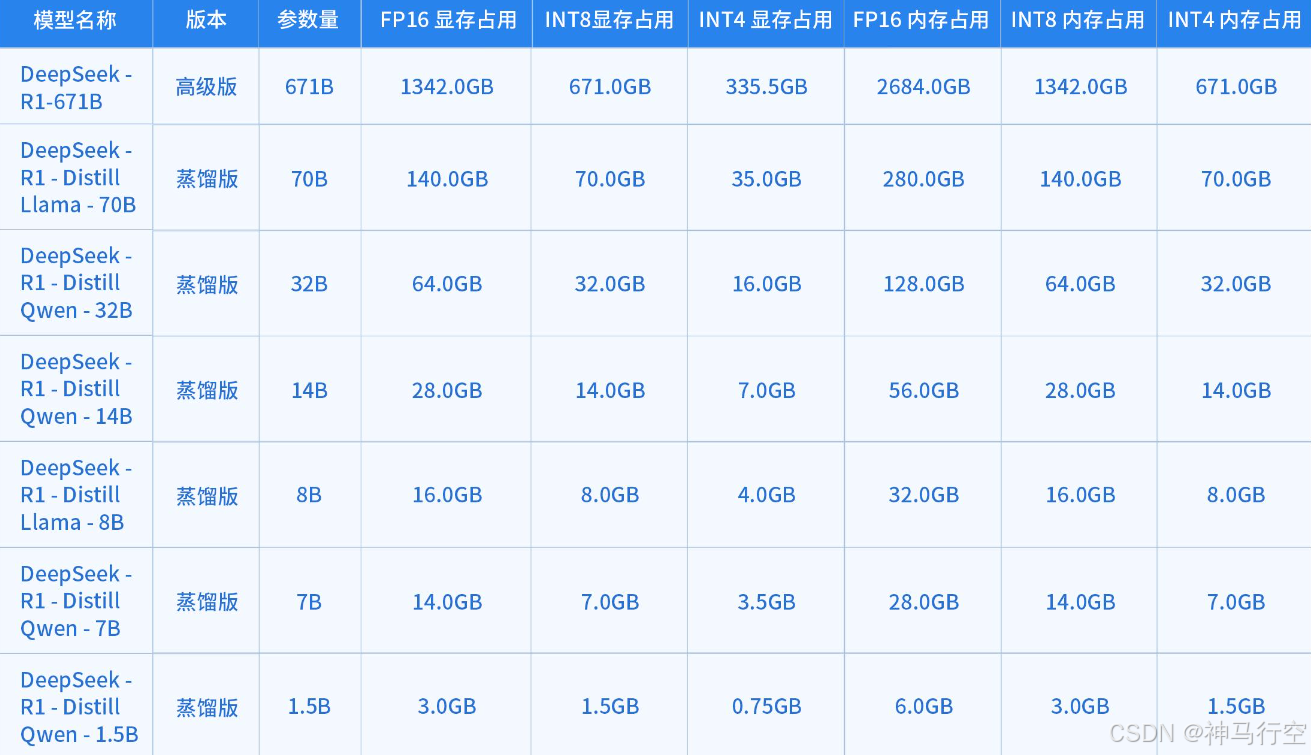
- 显存占用:指模型在 GPU 上运行时所需的显存。
- 内存占用:指模型在 CPU 上运行时所需的内存,通常为显存占用的两倍,用于加载模型和计算缓冲。
Tips
- 实际的显存和内存占用可能因模型架构、批处理大小(batch size)、序列长度(sequence length)以及推理框架等因素而有所变化。
- 采用量化技术(如 INT8 或 INT4)可以显著降低显存和内存占用,但可能会对模型的精度产生一定影响。
- 在 CPU 上运行大型模型可能导致推理速度较慢,建议根据硬件配置选择适当的模型版本。
全尺寸模型的显存与内存占用估算:
DeepSeek-R1系列涵盖了从轻量1.5B 到超大规模 671B 参数的不同层次模型。参数规模越大,对硬件的要求则越高,显存需求也呈指数级增长。1.5B - 14B 参数的版本适用于个人轻量任务,32B - 70B参数的版本面向企业级复杂任务,671B参数的满血版本则为大规模研究专用。
- 小型模型(如 1.5B - 8B):一般情况下,对显卡要求不高,甚至仅使用CPU也可推理;若要使用显卡,推荐16GB 显存的版本,可处理文本摘要、翻译等中等复杂度的自然语言处理任务。
- 中型模型(如 14B - 32B):14B 模型推荐使用28GB显存的显卡;32B模型则至少需要64GB显存的显卡,适用于多模态任务预处理等高精度专业领域。
- 大型模型(如 70B - 671B):70B 模型需多卡并行;671B 模型则需多节点分布式部署,适用于超大规模研究或通用人工智能探索。
2.2、不同规格模型对硬件要求
根据业内测试数据及实验测算,不同规格模型的硬件需求如下:
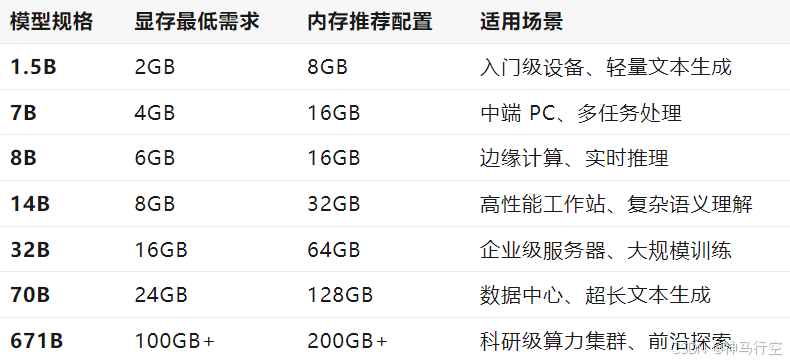
- 显存决定模型能否运行:显存容量需至少覆盖模型参数加载需求(如 FP16 精度下,1B 参数约需 2GB 显存)。
- 内存影响数据处理效率:内存不足会导致频繁的磁盘交换,显著拖慢推理速度。建议内存容量为显存的 2-4 倍。
- 超大规模模型(如 671B)需专业设备:需多卡并行(如 8*A100 80GB)及分布式训练框架支持,非个人用户适用。
3、DeepSeek系列模型与服务器的配置推荐
DeepSeek不同大模型对服务器配置选型的影响因素:模型参数尺寸、激活参数量、计算精度(BF16/FP16/FP8)、输入及输出上下文长度(token)、并发用户数、延迟要求(TTFT/TPOT)、系统层级其他消耗等。下面是一些模型的推荐配置参考,实际落地时可灵活调整;
3.1、X86架构服务器DeepSeek业务配置推荐
|
DeepSeek模型 |
显存需求FP16 |
推荐训练GPU卡型号 |
推荐GPU数量 |
推荐推理GPU卡型号 |
推荐GPU卡数量 |
推荐机型和配置 |
场景应用 |
|---|---|---|---|---|---|---|---|
| 671B | ≥1.5TB ≥800GB(FP8) |
H1XX 80GB H20 96GB H20 141GB |
32张 | H1XX 80GB H20 96GB H20 141GB |
16张 | R8868 G13 - CPU≥32核 × 2 - 内存(总容量 2048GB) - 存储: NVMe 3.84TB × 1 - SATA 480GB × 2 - GPU: H/A1XX 80GB 32张/H20 96GB 32张/H20 141GB 24张 (nvlink) - 网络: 400G IB卡 × 8 |
超复杂任务(多步骤推理、跨模态理解) 前沿技术开发 国家级或行业知识引擎 |
| 70B | ≥140GB |
H1XX 80GB>A1XX 80GB/H20 96G/H20 141GB |
8张 | H/A1XX 80GB H/A8XX 80GB/58XX ADA 48GB/LXX 48G | 4-8张 | R8868 G13/R8428 A12/R8428 G13 - CPU≥32核 × 2 - 内存(总容量 2048GB) - 存储: NVMe 3.84TB × 1 - SATA 480GB × 2 - GPU: H/A1XX/H/A8XX 80GB/58XX ADA 48GB/LXX 8张 H20 96GB 8张(nvlink>pcie) - 网络: 25G双光口网卡 × 1 /400G IB卡 x 8 |
复杂逻辑推理(数据问题、因果分析) 专业领域生成(法律合同、医疗报告辅助) 中等规模数据分析与报告撰写 |
| 32B | ≥72GB | H1XX 80GB>A1XX 80GB>LXX 48G>RTX 40XX | 80GB:2张 48GB:4张 24GB:8张 |
H1XX 80GB>A1XX 80GB>LXX 48G>58XX ADA 48GB>RTX 40XX | 80GB:1张 48GB:3张 24GB:4张 |
R8428 A12/R8428 G13 - CPU≥32核 × 2 - 内存(总容量 1024GB) - 存储: NVMe 3.84TB × 1 - SATA 480GB × 2 - GPU: H/A1XX 80GB 1≈4张/58XX ADA 48GB 4≈8张/LXX 4≈8张/40XX 24GB(涡轮版)8张 - 网络: 25G双光口网卡 × 1 - 电源: 3000W铂金冗余电源 x 4 |
复杂逻辑推理(数据问题、因果分析) 专业领域生成(法律合同、医疗报告辅助) 中等规模数据分析与报告撰写 |
| 14B | ≥35GB | RTX 40XX / LXX 48G | 2-4张 | LXX 48G RTX 40XX |
2-4张 | R8428 A12/R8428 G13 - CPU≥16核 × 2 - 内存(总容量 512GB) - 存储: NVMe 1.92TB × 1 - SATA 480GB × 2 - GPU: RTX40XX 24GB(涡轮版)2≈4张/LXX 1≈2张 - 网络: 25G双光口网卡 × 1 - 电源: 3000W铂金冗余电源 x 4 |
中等复杂文本生成(长篇文章、故事创作) 多轮对话系统(情感分析、个性化交互) 基础代码补全与文档生成 商业文案润色与营销内容生成 |
| 7B | ≥20GB | RTX 40XX / LXX 48G | 1张 | RTX 40XX / LXX /A3X / A4X | 1张 | R8428 A12/R8428 G13 - CPU≥16核 × 2 - 内存(总容量 512GB) - 存储: NVMe 1.92TB × 1 - SATA 480GB × 2 - GPU: RTX40XX 24GB(涡轮版)1≈4张/LXX 1≈2张 - 网络: 25G双光口网卡 × 1 - 电源: 3000W铂金冗余电源 x 4 |
轻量级文本生成(短文本、邮件、摘要) 简单问答与对话(客服机器人、个人助手) 教育场景(知识点解释、语言学习) |
3.2、C86架构(搭配国产卡)服务器DeepSeek业务配置推荐
| DeepSeek模型尺寸 | 计算精度 | 显存需求 | 推荐机型和配置 | 推荐卡数/张 | PCIE GPU推荐 |
|---|---|---|---|---|---|
| 671B | FP16 | ≥1.5TB | 1~4*R3418/R3428 - CPU:7390/7490/7470 × 2 - 内存:总容量 2048GB - 存储: NVMe 3.84TB × 2 - SATA SSD 480GB × 2 - 网络: 200G IB卡 × 2 + 25G网卡 × 1 |
16 | 16*昆仑芯P800 96G 32*海光DCU K100-AI 64G |
| FP8 | ≥800GB | 8 | 8*昆仑芯P800 96G 16*海光DCU K100-AI 64G |
||
| 70B | FP16 | ≥150GB | R3418/R3428 - CPU:7390/7490/7470 × 2 - 内存:总容量 1024GB - 存储: NVMe 3.84TB × 2 - SATA SSD 480GB × 2 - 网络: 25G网卡 × 1 |
8 | 海光DCU K100-AI 64G 天垓150 64G |
| 32B | FP16 | ≥72GB | R3418/R3416 - CPU:7390/7380 × 2 - 内存:总容量 512GB - 存储: NVMe 3.84TB × 1 - SATA SSD 480GB × 2 - 网络: 25G网卡 × 1 |
4 | 昆仑芯RG800 32G 海光DCU K100-AI 64G 天垓150 64G 燧原S60 48G |
| 14B | FP16 | ≥35GB | R3216 - CPU:7360/7375 × 2 - 内存:总容量 256GB - 存储: NVMe 1.92TB × 1 - SATA SSD 480GB × 2 - 网络: 25G双光口网卡 × 1 |
2 | 昆仑芯RG800 32G 海光DCU K100-AI 64G 天垓150 64G 燧原S60 48G |
| 7B | FP16 | ≥20GB | 1 | 昆仑芯RG800 32G 海光DCU K100-AI 64G 天垓150 64G 燧原S60 48G |
4、DeepSeek 模型与配置兼容性检测工具
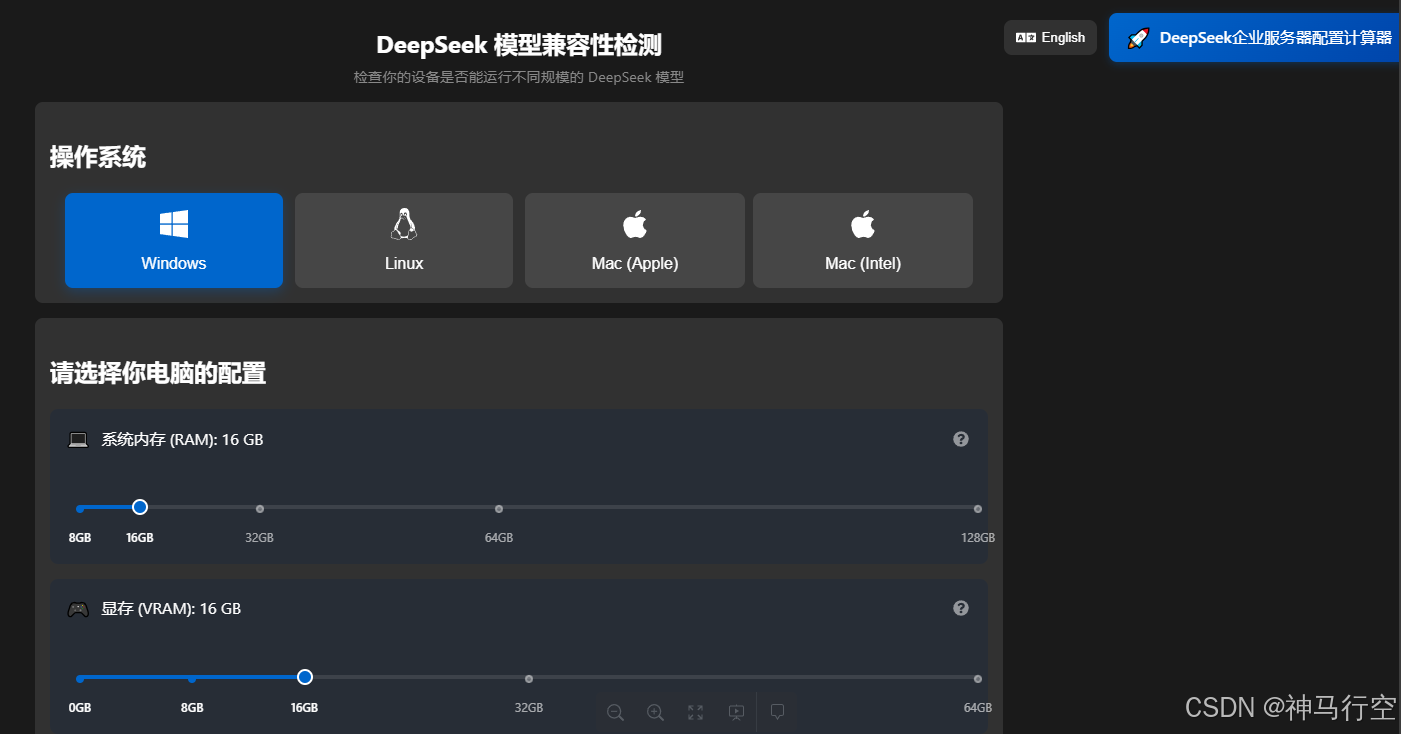
在线检测 DeepSeek 模型与配置兼容性,看看你的配置适合哪款大模型,支持个人配置和企业配置,地址:DeepSeek 模型兼容性检测
5、福利
近期整理了一份DeepSeek前沿资料库【碳基跃动】,包含【技术论文、部署实践、清华大学/北京大学/天津大学/浙江大学/山东大学/厦门大学等高校学术研报、教育/医疗/金融/智能制造等行业场景落地报告、民生证券/开源证券/国金证券/国海证券等各大券商最新投资研报】等等,涵盖了DeepSeek从技术原理到行业应用的各方面知识,不管你是在校学生、还是职场"老炮",都适合参考研习。现在免费开放(开源+共享),欢迎大家扫码加入,同时记得点击本文的【关注】+【收藏】+【点赞】+ 【转发】,以免走丢!同时也欢迎大家转发给有需要的朋友,另外如有好的建议,也欢迎评论区留言讨论。



欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 68
68 2
2- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)