DeepSeek_R1训练FAQ精选
前面通过《快速了解DeepSeek_R1技术报告 》了解到R1的大致训练内容,但是这份报告并没有讲的很细,比如RL是如何进行的?为什么叫做冷启动?冷启动的内容和常规的SFT一样,为什么要另外起一个名字呢?等等细节本文将把重点的问题进行整理,作为FAQ呈现出来。
前言
前面通过《快速了解DeepSeek_R1技术报告 》 了解到R1的大致训练内容,但是这份报告并没有讲的很细,比如RL是如何进行的?为什么叫做冷启动?冷启动的内容和常规的SFT一样,为什么要另外起一个名字呢?等等细节
本文将把重点的问题进行整理,作为FAQ呈现出来。
FAQ
问题1:DeepSeek-R1-Zero如何通过纯强化学习(RL)实现推理能力的突破?
DeepSeek-R1-Zero直接从基础模型(DeepSeek-V3-Base)出发,完全依赖大规模强化学习(RL)提升推理能力,跳过了传统的监督微调(SFT)步骤。其采用GRPO(Group Relative Policy Optimization)算法,通过组内归一化奖励信号优化策略。具体来说,GRPO通过采样一组输出(组大小G=16),计算组内奖励的均值和标准差,生成优势函数(advantage),从而避免传统PPO中需要额外训练价值模型的高成本。这种纯RL训练促使模型自主探索长思维链(CoT)、自我验证和反思等复杂推理行为,最终在数学(AIME 2024 Pass@1从15.6%提升至71.0%)和代码任务中取得显著提升。
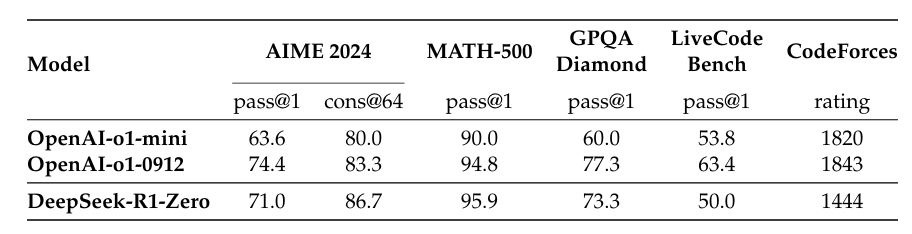
问题2:为何在DeepSeek-R1中引入冷启动数据(cold-start data)?其核心优势是什么?
冷启动数据用于解决DeepSeek-R1-Zero的可读性和语言混合问题。具体来说,冷启动数据包含数千条高质量的长思维链(CoT)示例,通过人工标注和格式过滤(如使用<reasoning>和<summary>标签),强制模型生成结构清晰、语言一致的内容。其核心优势在于:
- 稳定性:为RL训练提供高质量的初始策略,避免早期探索阶段的输出混乱。
- 可读性:通过模板化输出(如总结模块)提升生成内容的用户友好性。
- 加速收敛:减少RL训练所需的步数,实验表明冷启动后AIME Pass@1进一步提升至79.8%(接近OpenAI-o1-1217的79.2%)。
问题3:论文提到“语言混合”(language mixing)问题,具体表现和解决思路是什么?
表现:模型在处理多语言提示时,可能在同一思维链中混合使用中英文(如中文问题用英文推理)。
解决思路:
- 语言一致性奖励:在RL阶段增加奖励项,计算目标语言词汇占比(如中文任务中中文词比例需超过阈值)。
- 数据过滤:冷启动阶段人工筛选单语言示例,强化模型的语言对齐能力。
- 模板约束:强制要求推理和答案部分使用统一语言标签(如
<think>和<answer>)。
问题4:蒸馏技术的核心目标是什么?为何小模型通过蒸馏能超越直接RL训练?
目标:将大模型(如DeepSeek-R1)的推理能力迁移到小模型(如7B参数),使其在有限计算资源下接近大模型性能。
原因:
- 数据效率:蒸馏直接复用大模型生成的800k高质量推理数据,而直接RL需从头探索,计算成本高。
- 知识继承:小模型通过模仿大模型的输出模式(如CoT结构),跳过RL的试错阶段。
- 实验验证:蒸馏后的Qwen-7B在AIME 2024达到55.5%,远超直接RL训练的Qwen-32B(47.0%)。
问题5:为何强调“无监督微调”(SFT)的RL训练?其理论依据是什么?
传统RL流程依赖SFT提供初始策略,但DeepSeek-R1-Zero跳过SFT,直接通过RL探索解空间。其理论依据为:
- 探索自由度:SFT可能限制模型对未知推理路径的探索(如过拟合示例模板)。
- 数据效率:RL通过奖励信号自动筛选有效策略,避免标注成本。
- 实证结果:实验显示纯RL训练的DeepSeek-R1-Zero在AIME任务上超越部分SFT+RL基线模型。
问题6:模型在自我进化过程中是否会出现“局部最优”?如何避免?
风险:RL训练可能收敛到局部最优(如依赖固定推理模板)。
解决方法:
-
组内多样性:GRPO算法每组采样16条输出,强制模型探索多路径。
-
KL散度约束:通过β参数(公式2)限制策略偏离参考模型的程度,保留基础能力。
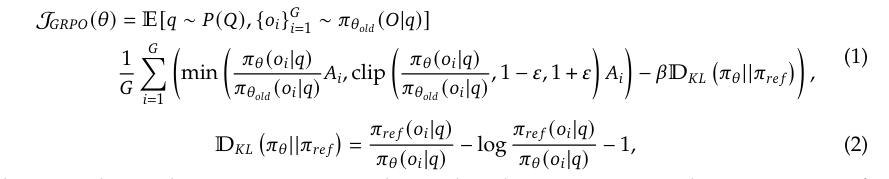
-
动态奖励调整:在后期RL阶段引入多样性提示(如多语言、多领域问题),打破路径依赖。
问题7:论文中提到的“aha moment”具体指什么?对模型训练有何启示?
定义:在RL训练中期,模型突然展现出类人反思行为(如“Wait, let me re-evaluate this step”),主动修正错误推理路径。
启示:
- 涌现能力:复杂推理行为可通过纯RL自主演化,无需显式编程。
- 训练信号设计:规则化奖励(如答案正确性)足以引导高级策略,无需引入人工干预。
- 模型可塑性:表明基模型(DeepSeek-V3)具备未被激发的潜在能力。
问题8:DeepSeek-R1在中文任务中的表现为何低于英文?如何优化?
原因:
- 数据偏差:RL训练侧重STEM任务,中文语料占比低。
- 语言对齐不足:冷启动数据以英文为主,中文模板未充分优化。
- 评测覆盖度:部分中文任务(如C-SimpleQA)涉及文化特定知识,模型未针对性训练。
优化方向:
- 增加中文冷启动数据比例。
- 引入语言特定的格式奖励(如中文标点、术语规范)。
- 扩展中文多任务RL训练(如文言文翻译、本土数学竞赛题)。
问题9:DeepSeek-R1-Zero和DeepSeek-R1的base模型是哪个?这个base模型本身是否具有对话能力或推理能力?
点击DeepSeek_R1训练FAQ精选查看全文。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 26
26 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)