DeepSeek 开源周第三弹!DeepGEMM:FP8矩阵计算神器!JIT编译+Hopper架构优化,MoE性能飙升
DeepGEMM 是 DeepSeek 开源的专为 FP8 矩阵乘法设计的高效库,支持普通和混合专家(MoE)分组的 GEMM 操作,基于即时编译技术,动态优化矩阵运算,显著提升计算性能。
❤️ 如果你也关注 AI 的发展现状,且对 AI 应用开发感兴趣,我会每日分享大模型与 AI 领域的开源项目和应用,提供运行实例和实用教程,帮助你快速上手AI技术!
🥦 AI 在线答疑 -> 智能检索历史文章和开源项目 -> 尽在微信公众号 -> 搜一搜:蚝油菜花 🥦
🚀 “矩阵革命!DeepSeek开源FP8计算库:300行代码跑赢专家优化,MoE训练提速3倍”
大家好,我是蚝油菜花。当同行还在为万亿参数模型算力发愁时,一群极客用300行代码改写了游戏规则——
你是否正经历这些至暗时刻?
- 👉 MoE模型分组计算卡在显存瓶颈,batch_size死活上不去
- 👉 FP8精度损失严重,手动调参到凌晨3点仍报NaN警告
- 👉 专家库动辄百万行代码,想优化却找不到切入点…
DeepGEMM 的三大破局利器:
- ✅ JIT即时编译:运行时动态优化,彻底告别安装编译依赖地狱
- ✅ TMA硬件级加速:榨干Hopper架构性能,矩阵搬运效率提升200%+
- ✅ 双级累加黑科技:FP8计算+BF16精度保障,误差率直降80%
现在,百川智能的工程师用它把MoE推理延迟压进毫秒级——点击看如何用5行代码激活这个性能怪兽!
🚀 快速阅读
DeepGEMM 是 DeepSeek 开源的专为 FP8 矩阵乘法设计的高效库,支持普通和混合专家(MoE)分组的 GEMM 操作。
- 核心功能:支持高效 FP8 矩阵乘法,细粒度缩放和即时编译技术,显著提升计算性能。
- 技术原理:基于 NVIDIA Hopper 架构的 Tensor Memory Accelerator(TMA)特性,优化数据传输效率,并通过 CUDA 核心双级累加技术解决 FP8 精度问题。
DeepGEMM 是什么

DeepGEMM 是 DeepSeek 开源的专为 FP8(8 位浮点)矩阵乘法设计的高效库,支持普通和混合专家(MoE)分组的 GEMM 操作。该库基于即时编译(JIT)技术,无需安装时编译,支持在运行时动态优化,显著提升矩阵运算的性能和精度。
DeepGEMM 专为 NVIDIA Hopper 架构设计,充分利用 Tensor Memory Accelerator(TMA)特性,提升数据传输效率。其核心代码仅约 300 行,易于学习和优化,在多种矩阵形状上均达到或超过专家级优化库的性能。
DeepGEMM 的主要功能
- 高效 FP8 矩阵乘法(GEMM):专为 FP8 矩阵乘法设计,支持细粒度缩放,显著提升矩阵运算的性能和精度。
- 支持普通和分组 GEMM:适用于常规的矩阵乘法操作,并支持混合专家(MoE)模型中的分组矩阵乘法,优化多专家共享形状的场景。
- 即时编译(JIT)设计:所有内核在运行时动态编译,无需安装时编译,根据矩阵形状、块大小等参数进行优化,节省寄存器提升性能。
- Hopper 架构优化:充分利用 Tensor Memory Accelerator(TMA)特性,包括 TMA 加载、存储、多播和描述符预取,显著提升数据传输效率。
- 细粒度缩放和双级累加:引入细粒度缩放技术,基于 CUDA 核心的双级累加机制,将 FP8 计算结果提升到更高精度的格式(如 BF16),确保计算精度。
- 轻量级设计:核心代码简洁,仅约 300 行,易于理解和扩展,避免复杂模板或代数结构的依赖,降低学习和优化的难度。
DeepGEMM 的技术原理
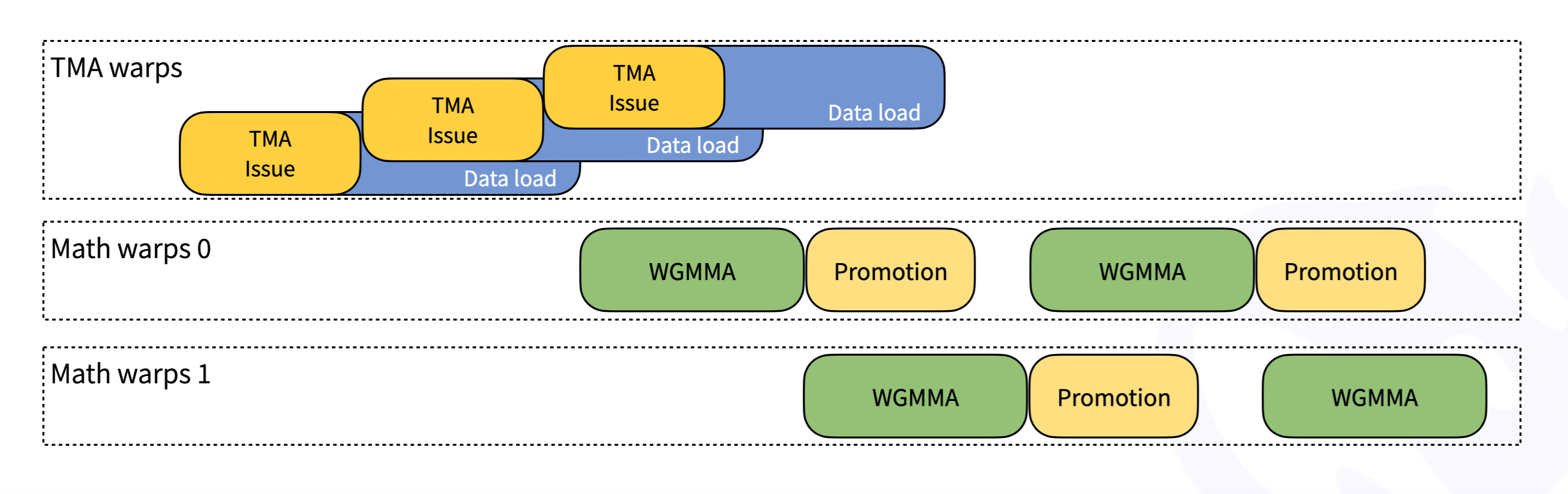
- 即时编译(JIT)技术:所有内核在运行时动态编译,无需安装时编译,根据矩阵形状、块大小等参数进行优化,节省寄存器提升性能。
- Tensor Memory Accelerator(TMA):利用 Hopper 架构的 TMA 特性,提升数据传输效率,包括 TMA 加载、存储、多播和描述符预取。
- 细粒度缩放和双级累加:通过细粒度缩放技术,结合 CUDA 核心的双级累加机制,解决 FP8 精度不足的问题,确保计算精度。
如何运行 DeepGEMM
环境要求
在运行 DeepGEMM 之前,请确保满足以下环境要求:
- 支持 Hopper 架构的 GPU(必须支持
sm_90a) - Python 3.8 或更高版本
- CUDA 12.3 或更高版本(推荐 12.8 或以上以获得最佳性能)
- PyTorch 2.1 或更高版本
- CUTLASS 3.6 或更高版本(可以通过 Git 子模块克隆)
开发环境配置
1. 克隆代码库
DeepGEMM 的代码库包含必要的子模块,因此需要使用 --recursive 参数克隆:
git clone --recursive git@github.com:deepseek-ai/DeepGEMM.git
2. 创建符号链接
运行以下命令以创建第三方库(如 CUTLASS 和 CuTe)的符号链接:
python setup.py develop
3. 测试 JIT 编译
运行以下命令以测试 JIT 编译是否正常工作:
python tests/test_jit.py
4. 测试核心功能
运行以下命令以测试所有 GEMM 实现(包括普通 GEMM 和分组 GEMM):
python tests/test_core.py
5. 安装 DeepGEMM
完成开发环境配置后,可以通过以下命令安装 DeepGEMM:
python setup.py install
安装完成后,可以在 Python 项目中导入 deep_gemm 模块,开始使用 DeepGEMM。
使用 DeepGEMM 的核心功能
DeepGEMM 提供了多种矩阵乘法接口,支持普通 GEMM 和分组 GEMM(连续布局和掩码布局)。以下是具体的使用方法。
普通 GEMM(非分组)
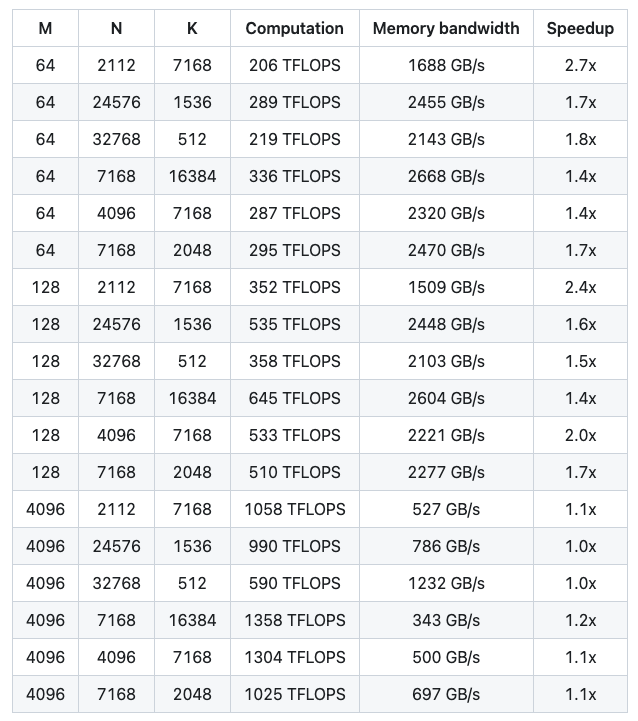
要执行一个基本的非分组 FP8 GEMM,可以调用 deep_gemm.gemm_fp8_fp8_bf16_nt 函数。以下是一个简单的示例代码:
import torch
import deep_gemm
# 创建 FP8 输入矩阵
lhs = torch.randn(64, 7168, dtype=torch.float8_e4m3fn)
rhs = torch.randn(7168, 2112, dtype=torch.float8_e4m3fn)
# 执行 GEMM 操作
output = deep_gemm.gemm_fp8_fp8_bf16_nt(lhs, rhs)
print("Output shape:", output.shape)
代码解释:
lhs和rhs是 FP8 格式的输入矩阵。deep_gemm.gemm_fp8_fp8_bf16_nt函数执行非转置 LHS 和转置 RHS 的矩阵乘法。- 输出结果为 BF16 格式。
分组 GEMM(连续布局)
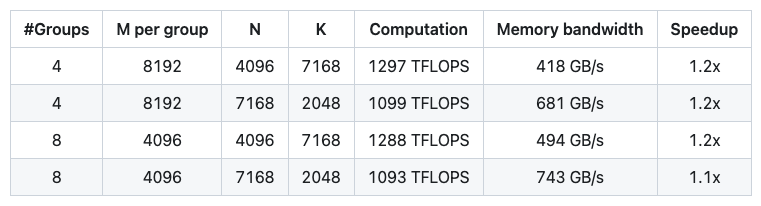
分组 GEMM 适用于 MoE(Mixture of Experts)模型,其中每个专家的输入矩阵形状相同。以下是一个连续布局的分组 GEMM 示例:
import torch
import deep_gemm
# 创建分组输入矩阵
lhs = torch.randn(4, 8192, 7168, dtype=torch.float8_e4m3fn)
rhs = torch.randn(7168, 4096, dtype=torch.float8_e4m3fn)
# 执行分组 GEMM 操作
output = deep_gemm.m_grouped_gemm_fp8_fp8_bf16_nt_contiguous(lhs, rhs)
print("Output shape:", output.shape)
代码解释:
lhs是一个分组矩阵,其中每个组的形状为(8192, 7168)。rhs是一个共享的权重矩阵。- 输出结果为每个组的矩阵乘法结果。
分组 GEMM(掩码布局)
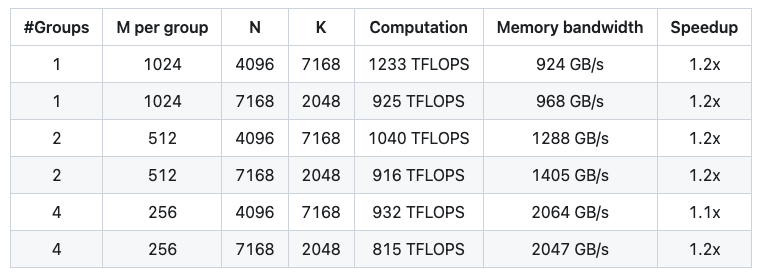
在推理阶段,当使用 CUDA 图形时,可以通过掩码布局支持分组 GEMM。以下是一个示例:
import torch
import deep_gemm
# 创建掩码分组输入矩阵
lhs = torch.randn(4, 1024, 7168, dtype=torch.float8_e4m3fn)
rhs = torch.randn(7168, 4096, dtype=torch.float8_e4m3fn)
mask = torch.randint(0, 2, (4, 1024), dtype=torch.bool)
# 执行掩码分组 GEMM 操作
output = deep_gemm.m_grouped_gemm_fp8_fp8_bf16_nt_masked(lhs, rhs, mask)
print("Output shape:", output.shape)
代码解释:
mask是一个布尔张量,用于指示哪些部分需要计算。deep_gemm.m_grouped_gemm_fp8_fp8_bf16_nt_masked函数仅计算掩码为True的部分。
配置优化选项
DeepGEMM 提供了一些实用工具函数和环境变量,用于优化性能。以下是一些常用配置:
设置最大 SM 数量
deep_gemm.set_num_sms(132) # 设置最大 SM 数量
获取对齐要求
alignment = deep_gemm.get_m_alignment_for_contiguous_layout()
print("Alignment requirement:", alignment)
环境变量
DG_CACHE_DIR:设置编译内核的缓存目录,默认为$HOME/.deep_gemm。DG_DISABLE_FFMA_INTERLEAVE:禁用 FFMA 交错优化。
性能优化
DeepGEMM 在性能优化方面采用了多种技术,包括:
- 持久化线程块专用化:通过线程块专用化实现数据移动、张量核 MMA 指令和 CUDA 核提升的重叠。
- Hopper TMA 特性:利用 Tensor Memory Accelerator(TMA)实现异步数据加载和存储。
- 完全 JIT 设计:在运行时编译内核,优化寄存器使用和指令调度。
- 未对齐块大小支持:针对特定形状优化 SM 利用率。
- FFMA 指令交错:通过修改编译后的二进制文件优化指令级并行性。
资源
- GitHub 仓库:https://github.com/deepseek-ai/DeepGEMM
❤️ 如果你也关注 AI 的发展现状,且对 AI 应用开发感兴趣,我会每日分享大模型与 AI 领域的开源项目和应用,提供运行实例和实用教程,帮助你快速上手AI技术!
🥦 AI 在线答疑 -> 智能检索历史文章和开源项目 -> 尽在微信公众号 -> 搜一搜:蚝油菜花 🥦

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 23
23 0
0- 0



 已为社区贡献32条内容
已为社区贡献32条内容

所有评论(0)