DeepSeek核心技术浅谈
DeepSeek三个版本的区别:满血版本:DeepSeek完整的版本,性能强大但计算开销大。量化版本:模型不变,通过降低参数精度,提高推理效率。蒸馏版本:将大模型的知识压缩到更小的模型中,性能稍弱但轻便高效。
DeepSeek三个版本的区别:
满血版本:DeepSeek完整的版本,性能强大但计算开销大。
量化版本:模型不变,通过降低参数精度,提高推理效率。
蒸馏版本:将大模型的知识压缩到更小的模型中,性能稍弱但轻便高效。
一、提前预热:提前需要知道的背景知识
- 传统机器学习理论:模型复杂度增加时,测试误差先下降后上升。
- 现代机器学习实践:在过参数化的深度学习中测试误差会再次下降,形成“双下降“曲线,这成为大模型研究的重要动机之一。
- 大模型的过参数化:参数量远超过了拟合训练数据所需的最小参数量,但学习到的模型可能只存在于一个低本质维度的子空间中。这是Deepseek模型结构创新的重要前提。

机器学习模型:一种映射,在给定输入情况(x)下、输出一定结果的函数f(x)。
机器学习:根据反馈信号调整模型的参数,以使模型的表现符合预期。
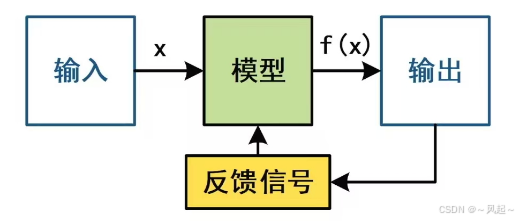
两种常见的机器学习策略:监督学习,强化学习
监督学习:相当于老师手把手教你做题,直接告诉你解题思路
优势:学习目标明确,训练效率高,易收敛
劣势:依赖标注数据,泛化能力受限
强化学习:只告诉你答案是否正确,不指导解题思路
优势:无需标注数据,可处理开放性问题
劣势:需大量试错,训练效率低,难收敛
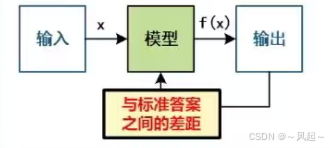
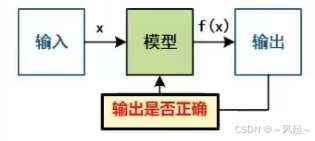
大模型的训练流程:预训练+后训练
预训练:在海量文本数据上进行“下一词预测”的(自)监督学习,用于学习足够多的语言知识。
后训练:监督微调,在少量带有思考过程(思维链)的监督数据上进行“下一词预测”学习,用于激发推理能力。
二、DeepSeek的创新
1.DeepSeek在后训练阶段用强化学习完全代替监督微调(R1-Zero)。采用的GRPO算法放弃了对思维过程进行监督的执念,去除了过程价值评分模型(critic)。
结果:通过一个不需要思维链标注、不需要过程监督、依靠最简单的反馈信号依赖很少的学习循环次数的极其简单的后训练流程,就可大幅提升模型的推理能力。这在结果上是颠覆性的,DeepSeek大胆创新,实现了这方面技术上的突破。
2.DeepSeek首次使用FP8混合精度训练大模型。
浮点数在计算机中的表示方法,FP8的动态范围最小容易引起上溢和下溢问题。
DeepSeek:通过细粒度量化方法减轻由异常值引起的量化误差。
3.使用强化学习,使用更少的数据标注。
4.分布式训练优化,使通讯开销更小。
总结:DeepSeek用不到560万美元训练出了媲美西方国家chatgpt的顶尖ai,用更少的成本做更多的事。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)