DeepSeek-R1 核心模块 GRPO学习
在LLMs的训练中,强化学习算法一直是提升模型性能的关键。然而,传统算法如PPO面临着计算开销大、策略更新不稳定等问题。今天,我们将深入解析DeepSeek-R1模型中的强化学习算法——GRPO(Group Relative Policy Optimization)。本文将为你详细解读GRPO的原理、实现细节以及在数学推理和代码生成任务中的卓越表现,带你一探究竟,了解这一算法如何革新大语言模型的训
前言:
在LLMs的训练中,强化学习算法一直是提升模型性能的关键。然而,传统算法如PPO面临着计算开销大、策略更新不稳定等问题。今天,我们将深入解析DeepSeek-R1模型中的强化学习算法——GRPO(Group Relative Policy Optimization)。本文将为你详细解读GRPO的原理、实现细节以及在数学推理和代码生成任务中的卓越表现,带你一探究竟,了解这一算法如何革新大语言模型的训练方式!
GRPO和PPO的结构差异: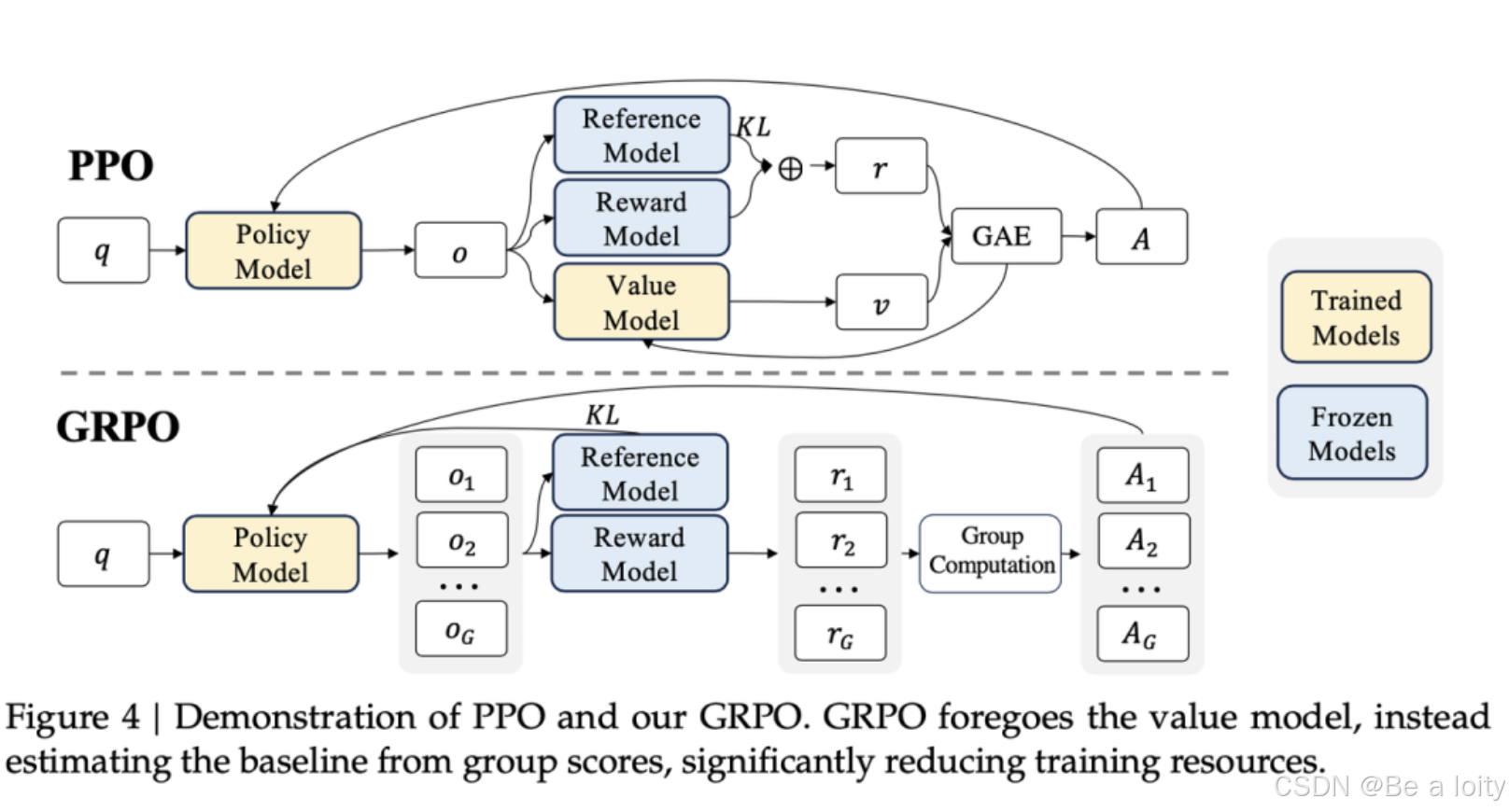
结构上主要差异点:
-
GRPO 会生成多个o从o1-oG,然后reward 进行打分。
-
GRPO 没有 value model模块
-
GRPO 将KL计算移到了前面,同时修改了计算方法,PPO的KL计算在GAE里面。
各模块差异点:
-
价值网络:
-
PPO:依赖于一个与策略模型大小相当的critic model(value model模块)来估计优势函数(advantage function)。这个价值网络需要在每个时间步对状态进行评估,计算复杂度高,内存占用大。
-
GRPO:完全摒弃了价值网络,通过组内相对奖励来估计优势函数,相当于训练参数减半。这种方法通过比较同一状态下的多个动作的奖励值来计算相对优势,显著减少了计算和存储需求。
-
-
奖励计算方式:
-
PPO:使用GAE来计算优势函数,需要对每个动作的即时奖励和未来奖励的折扣总和进行估计。
-
GRPO:通过采样一组动作并计算它们的奖励值,然后对这些奖励值进行归一化,得到相对优势。这种方法更直接,减少了对复杂奖励模型的依赖。
-
-
策略更新机制:
-
PPO:通过裁剪概率比来限制策略更新的幅度,确保策略分布的变化在可控范围内。
-
GRPO:引入了KL散度约束,直接在损失函数中加入KL散度项,从而更精细地控制策略更新的幅度。
-
GRPO的优化
论文认为value function model 占用了额外的显存和计算资源。因此提出以下的改进方法
去除value function , reward 直接对单个q生成的response进行打分,归一化后,作为替代的优势函数。
同时将KL散度抑制,移到了优势函数计算的外面。 KL 散度的计算也进行了改进,保证KL散度为正值。
GRPO移除了 value model,那和DPO有什么区别:

GRPO的计算流程包括:
- 采样一组输出并计算每个输出的奖励。
- 对组内奖励进行归一化处理。
- 使用归一化后的奖励计算优势函数。
- 通过最大化目标函数更新策略模型。
- 迭代训练,逐步优化策略模型。
Deepseek-R1中 Grpo的策略模型的奖励函数:
代码实现:
https://mp.csdn.net/mp_blog/creation/success/146014615
伪代码


欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)